基于Python的校园网搜索引擎研究
2018-05-08左卫刚
左卫刚


摘要 随着数字化校园的发展,校园网数据量呈几何倍增长,信息的查找和定位变得更为困难。本文以大学校园网为研究对象,在分析了网络搜索引擎的原理、核心模块的基础上,采用基于Python的Scrapy爬虫和Whoosh索引库等技术,完成了linux平台下校园网搜索引擎原型系统的构建。实验结果显示,本文所提出的搜索引擎原型系统,有效解决了使用通用搜索引擎所产生的校园网信息收录不完全及索引更新不及时等问题。
【关键词】校园搜索引擎 网络爬虫 ScrapyWhoosh URL去重 布隆过滤器 中文分词
1 引言
大数据时代的来临意味着将产生海量的数据信息,这些信息被广泛分布在互联网的不同节点上,如何从中获取到我们真正需要的信息成为难题。目前用户获取信息的主要方式是使用传统的互联网搜索引擎,但因不用领域和不同背景的用户的检索目的和需求往往不同,使得通用搜索引擎返回的查询结果不是我们真正所关心和需要的。
近年来,校园信息化建设不断推进,校园网络信息呈现爆发式增长,校园内信息的查找和定位面临同样的困境。校园网有其特殊性,比如校园内有些站点使用二级或三级域名,甚至不绑定域名直接使用IP访问等特点。用户在使用通用搜索引擎来进行全域搜索或站内搜索就存在信息无法被通用搜索引擎收录和收录时间严重滞后等问题,显然通用搜索引擎的在面对校园网的这些特殊性,效果并不理想。
本文以大学校园网为研究对象,介绍搜索引擎中的一些关键技术,通过使用基于Python语言的S crapy开源爬虫框架,对搜索引擎的爬虫模块进行开发,指出Scrapy框架原有的URL去重方法存在的缺陷,提出了一种使用布隆过滤器对S crapy爬虫框架的URL去重功能进行改进的方案。同时,根据实际经验,提出了兩种防止爬虫被ban的策略。利用基于Python语言的Whoosh索引检索库,对本系统索引检索模块进行开发。针对Whoosh对中文分词效果不好的问题,提出了使用jieba开源分词组件来对Whoosh的中文分词功能进行改进。探索性地研究Linux平台下面向校园网的搜索引擎。
2 网络爬虫
互联网就像一张大的蜘蛛网,网络爬虫通过各种遍历算法从互联网上下载用户需要的信息,我们通常把互联网看做一张无限大的蜘蛛网,而蜘蛛网中每一个交叉点就是互联网上的一个节点,各个节点之间通过超链接连在一起。网络爬虫可以以互联网中的任何一个节点出发,使用遍历算法,到达互联网中的任何其他节点,被访问到的节点根据用户需求对节点内信息进行比对判断,把需要的信息从网页中下载下来,并进行格式化呈现给用户。
2.1 爬取策略
针对海量的网络信息,搜索引擎常用的网络爬虫策略主要有以下几种:
2.1.1 宽度优先策略
宽度优先算法(Breadth First Search),又称为广度优先。它的主体思想是:从V顶点出发,依次访问V顶点没有被访问过的相邻点,然后再从这些相邻点依次访问它们的相邻点,并遵循先被顶点访问的相邻点先于其他被访问的相邻点,这些相邻点继续访问其所有的相邻点,如此反复直到所有的顶点都被访问到。
下面以图l为例,来说明宽度优先搜索过程。
图1以VI为起点,首先访问V3、V4、V6。V3、V4、V6被访问过之后,再依次访问V3、V4、V6的相邻点。访问V3的相邻点V2,V4没有相邻点,访问V6的相邻点V7。访问完V2河V7后,再访问V7的相邻点V5。如此以来,整个的访问序列为:VI→ V3→ V4→ V6→ V2→V7→ V5
2.1.2 深度优先策略
深度优先搜索(Depth First Search)和广度优先搜索不同,深度优先搜索是一个递归的过程,比较类似于树的先序遍历。它的主体思想是:
深度优先算法类似于“一条路走到黑”。对于一个从未被访问过的图,假设从其V点出发开始访问,第一步是访问与V顶点直接相连的所有顶点,待其所有的顶点均被访问过以后,再从刚才被访问过的顶点开始依次访问与它们直接相连的顶点,重复上述访问过程,直到图中的所有顶点均被访问到为止。图2为深度优先搜索过程。
图2中首先访问V1,然后访问VI的相邻点V3、V4、V6。假设图中的顶点是按照VI、V2、V3、V4、V5、V6的顺序存储的,因为在存储时V3在V4和V6的前面,所以先访问V3,接下来应该访问V3的相邻点V2和V4,因为V2在V4之前存储,所以先访问V2。V2被访问过之后,访问V2未被访问过后的相邻点,但是V2没有,返回访问V4也是没有。于是返回起始点VI,继续访问Vl的另一个相邻点V6。访问V6的相邻点V7,访问V7的相邻点V5所以整个的访问序列为:V1→ V3→ V2→ V4→V6→V7→V5。
在互联网中,每一个网页都是一个节点,宽度优先搜索引擎和深度优先搜索都可以访问到所有节点。但是实际中每个网页都有不同的重要性,这两种算法只是可以抓取页面并排入队列,无法有效判定页面的优先级。
2.1.3 非完全PageRank策略
PageRank算法借鉴了学术界评判学术论文的通用方法。如何评价网络中海量信息的重要性,假如一个网站被很多的其他网站做了链接,则我们认为此网站很重要。这就是SEO中通常所说的PR值,我们在衡量某个网站的重要性时通常会看其PR值,网站在做外链时喜欢与比其PR值高的网站做交换链接,这样以来,搜索引擎就会认为这个网站也是可信赖的,就会赋予其较高的PR值,这样在相关的搜索结果中排名就会比较靠前。图3为非完全PageRank策略图。
在此我们假设PR值的计算以3为基数单位,初始状态中已经有{P1、P2、P3}3各页面被下载到了本地,它们的指向链接有{P4, P5,P6),这3页面也是等待爬虫爬取的集合。如何判断其爬行的次序,我们通常将已经下载的和待爬取的这6个页面形成一个新的集合,计算这个集合的PR值,按照PR值得大小次序进行爬取。这里假设待爬行的次序为P4,P5,P6,p4下载完毕后,下载P5,P5被爬取后获取P5的链接Ps,此时赋予P8 一个临时的PR值,如果P8的PR值大于P6,就优先下载P8。如此往复,不断循环,直到上图中所有页面都被爬取到。这就是非完全PageRank策略的计算思路。
2.2 Scrapy应用
Scrapy是一个高效的WEB爬虫框架,它完全基于Python开发而来,常被用于抓取网站信息,并从中提取出结构化数据。Scrapy框架简单而强大,可用于数据挖掘和自动化测试等。我们将使用Scrapy框架来编写本文构建的校园网搜索引擎的爬虫模块。
2.2.1 Scrapy中URL去重问题
Scrapy自带的去重方法是通过RFPDupeFilter类来实现的,在抓取小型网站数据时完全够用,但在面对大型网站时存在内存消耗大等问题,这时采用布隆过滤器( BloomFilter)来改善内存消耗过大的问题。布隆过滤器在开源社区已经有相应的类库pybloom。
2.2.2 Scrapy爬虫防止被禁止策略
爬蟲模块设计完成后,爬虫将对网站进行爬取。因大部分网站都有防止爬虫的策略,为了防止被ban,可采取以下两种策略:
(1)在爬虫的配置文件中将参数downloaddelay的值设置为1秒以上,鉴于校园网信息的更新并不是很频繁,随这样会致使抓取的频率降低,但不受大的影响。
(2)根据实际需求编写user agent中间件,替换掉原来的中间件。
3 索引与检索
网络爬虫爬过的网站数据,经过处理后将其添加进索引。索引就像是我们日常生活中书籍的目录,有了目录我们就可以更快的找到想要看的内容。索引的基础其实是集合论中的布尔运算,都是建立在布尔运算的基础之上的。
3.1 正反向索引
搜索引擎索引有正向索引和反向索引。正向索引简而言之就是将所爬取的信息汇总成关键词集合,爬虫爬取信息的同时需要保存与关键词相关的很多信息,比如关键词的具体位置、关键词在信息中出现的次数等。用户在搜索某个关键词时,首先通过遍历算法查找包含了此关键词的信息,这在一定程度上致使效率低下。
反向索引常用于搜索引擎中,与正向索引完全不同,它是通常意义下索引的倒置。反向索引能够较好地实现从关键词到文档的映射,通过反向索引可以很快地根据关键词获取到需要查询的数据信息。
3.2 Whoosh
索引与检索模块可通过开源社区的Whoosh实现。Whoosh是完全基于Python的全文索引与检索编程库。Whoosh构架良好,其包含的诸多模块都可以根据用户的实际需求进行替换,因其没有二进制包,不存在繁琐的编译,程序也就不会无故崩溃。
在使用Whoosh时要先建立索引对象,索引中包含索引模式,并以字段的形式存在:
上述代码建立了索引的模式,title,url,content字段对应索引查找目标文件的一部分信息,索引内容包括每个字段。字段建立索引后,就能被搜索和保存。索引模式建立之后,再建立索引存储目录。便可供用户搜索查询。
3.3 中文分词
Whoosh本身的分词功能是针对英文的,对中文的分词支持不友好,在本系统的开发中我们使用jieba中文分词,它是目前开源社区中比较活跃的项目,其采用了动态规划查找最大概率路径,基于前缀词典实现了高效的词图扫描。jieba分词可将句子最精确的切开,适合文本分析,在此基础上,对长词再次切分,提高召回率,适合于搜索引擎分词。通过与Whoosh的结合来提高系统对中文进行分词的能力。
4 实验分析
搜索质量的好坏需要进行科学的搜索质量评估。用户输入关键词到获取到需要的准确信息,整个过程速度越快,结果越准确,说明搜索引擎的质量越高。本节将进行相关测试,以验证搜索系统各方面的性能。
4.1 相关性量化评价
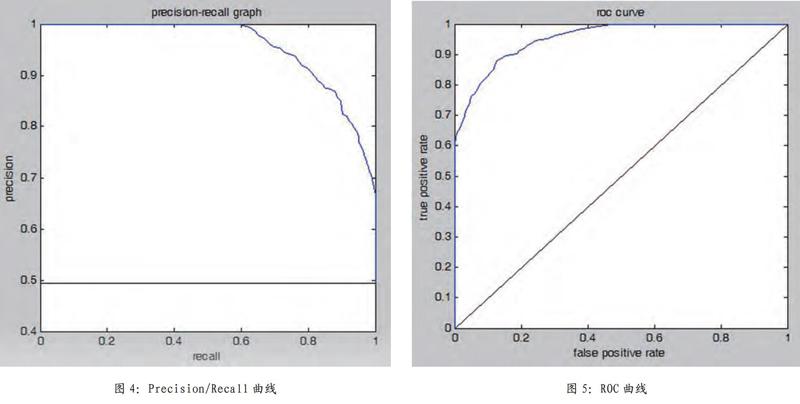
搜索引擎结果的好坏与否,体现在结果的相关性( Relevance)上。查准率(Precisionratio,简称为P)和查全率(Recall ratio,简称为R)是信息检索效率评价的两个重要定量指标。要评价搜索引擎的性能水平,就必须进行多次检索。每进行一次检索,都计算其查准率和查全率,并将其在平面坐标图上标示出来。通过大量的检索,就可以得到检索系统的性能曲线。Precision/Recall曲线以每一次计算的查全率为横坐标,每一次计算的查准率为纵坐标。经过100次检索得到,由图4可得出:我们所研究的校园网搜索引擎在查全率和查准率之间达到了较好的动态平衡。
通常情况下,我们也使用ROC曲线来定量评价搜索引擎。ROC曲线的横坐标为不相关信息量(false positive rate),纵坐标为相关信息量(true positive rate)。图5曲线也是由100次检索得到,由图5可知,在ROC空间绘制的ROC曲线凸向西北方向,效果较好。
4.2 收录及时性评价
大学校园中有海量的信息资源,搜索引擎收录的及时性和完整性非常重要。通过30余个关键字的测试发现:通用搜索引擎的收录滞后在7-15天,使用IP访问的四个站点的信息没有被通用搜索引擎收录。而我们构建的搜索引擎可按照需求更改爬行频率,信息收录非常及时。我们亦可随时将网站添加到系统的爬虫待爬队列中,IP访问的网站信息也得到较好的收录。
实验证明,本文所构建的搜索引擎原型系统,解决了使用通用搜索引擎索引更新频率无法控制,对校园网消息收录不完全的问题。更适合校园网搜索的个性化需求。
5 结语
本文研究的校园网搜索引擎,有效解决了校园网内信息不能被通用搜索引擎有效收录或收录不及时等问题,并完成了以下工作:针对S crapy网络爬虫框架自带的网页去重功能存在的缺陷,从理论上提出了使用布隆过滤器解决问题的方案;根据校园网特点,提出两种防止爬虫被禁止的方案;使用开源的jieba技术与Whoosh索引库相结合,有效提高了中文分词能力。
参考文献
[1]史宝明,贺元香,吴崇正,主题搜索引擎中爬虫搜索策略的研究[J].计算机工程与应用,2013 (08):56-58.
[2]黄荣怀,张进宝,胡永斌,智慧校园:数字校园发展的必然趋势[J].开放教育研究,2012,18 (04):12-17.
[3]李志义,网络爬虫的优化策略探略[J].现代情报,2011,31 (10):31-34.
[4]王燕,智慧校园建设总体架构模型及典型应用分析[J].中国电化教育,2014 (09):88-92.
[5]于娟,刘强,主题网络爬虫研究综述[J].计算机工程与科学,2015 (02):36-39.
