透明物体的多光源实时光照
2018-04-02余瀚游苟成秋
余瀚游,苟成秋
(1.四川大学视觉合成图形图像技术国防重点学科实验室,成都 610065;2.四川大学计算机学院,成都 610065)
0 引言
随着计算机硬件计算能力的快速发展,工业界针对游戏领域的真实感和实时性要求越来越高。而影响游戏中真实感最重要的因素就是光照。良好的实时光照算法可以改善游戏画面渲染效果和提高用户体验。使用基于物理的光照算法[2]几乎能呈现出现实生活中的光照效果,但是往往不能达到实时性的要求。现在的实时渲染[1]基本使用延迟光照(Deferred Lighting)[4-5]的算法来提高效率,但是延迟光照中不能处理透明物体的光照效果。本文采用光源链表的方式以统一地渲染三维场景中不同透明程度的几何对象。
1 算法概述
随着光源数量和场景复杂度提高,前向渲染(Forward Shading)[9]算法并不能高效进行光照计算。而延迟渲染算法通过解耦几何计算和光照计算,可以大幅度提高渲染效率。但在延迟光照中,几何缓冲区只能保存的是深度值最小片元(Fragment)的信息。如果在同一个像素位置同时存在透明片元和不透明片元,并且透明片元在前,那么几何缓冲区不能同时保存多个片元信息,从而没法同时渲染透明和不透明物体。普通做法不渲染透明物体或者额外的前向渲染透明物
1.1 延迟光照
延迟光照是屏幕空间渲染技术,避免渲染被遮挡的片元。第一个渲染过程(Render Pass)中没有对场景几何体进行光照计算,仅仅是保存几何体表面信息到几何缓冲区(G-Buffer),例如颜色,纹理,法线等。第二阶段在图像采样位置,发现可见性表面后再进行光照计算。不同于前向渲染方法,延迟渲染的光照计算是独立于场景复杂度。前向渲染却会根据场景中所有光源渲染每个几何体,在最差的情况,可能带来的效率O(M×N),其中M代表M个物体,N代表N个光源。而延迟渲染只需要O(M+N)时间效率。
1.2 光源链表
体。光源链表的实时光照算法,具体思想是每个片元构建光源链表,光源加入到当前片元的链表中。接着,通过访问光源链表,如果片元的世界坐标系的位置位于光源影响范围内,从而计算当前片元的光照效果。
虽然延迟光照可以很好渲染动态多光源场景,但是它并不能渲染透明物体和粒子特效。延迟光照算法中,普通做法是不渲染透明物体或者增加额外的前向渲染过程。如果不渲染透明物体,那么场景看起来不真实;额外的前向渲染会增加系统的复杂性和降低渲染效率。本文的光源链表(Light Linked List,LLL)[10]方法仅计算被每个光源影响的片元,不用区分透明物体和不透明物体,因此可以同时渲染透明和不透明几何体。而且,任何没被写深度缓冲区的几何体也能访问光源资源,进而进行光照计算。LLL算法要求显卡支持无序访问视图(Unordered Access Views,UAV)和原子计算器(Atomic Counter)。
2 算法实现
LLL本质是GPU链表[6-8],每个链表元素需要保存光源最小最大深度值,光源索引和Next指针。保存这些信息需要使用三个UAV资源:
(1)LightFragmentLinkedBuffer:光源链表缓存。存放完整的光源链表元素信息,结构体伪代码定义如Algorithm2-1所示。
(2)LightBoundBuffer:光源深度范围缓存。光源几何体最大最小深度值需要两次调用生成,因此要临时保存光源深度值和索引,下次用来匹配填充完整的链表元素信息。
(3)LightStartOffsetBuffer:光源头指针缓存。保存当前屏幕像素光源链表的头指针,需要使用原子计算器作为分配链表指针的工具。
Algorithm 2-1:光源链表结构体struct SLightFragmentLinkedList{
uint m_LightIndex;
float m_LightMinDepth;
float m_LightMaxDepth;
uint m_Next;};
LLL算法步骤主要分为光源链表的构建和访问。首先对所有光源覆盖的片元构建链表,因为场景几何体处于光源几何体(Light Volume)内,会遮挡光源几何体背面,所以需要关闭硬件深度测试。而要保存光源几何体最小最大深度值,需要两遍软件深度测试,第一遍打开背面裁剪,第二遍打开前面裁剪,构建的光源链表信息保存到LightFragmentLinkedBuffer。然后渲染透明和不透明物体,并且遍历当前片元的光源链表,如果几何体的深度值处于最小最大深度值区间内,那么对几何体进行光照渲染。
2.1 构建几何缓冲区
渲染不透明几何体,保存最小深度值片元的几何信息。各个保存的几何信息必须处于同一空间坐标下,本文中保存的是世界坐标系下的位置,材质颜色,以及世界坐标系下的法线。如果想降低GPU内存使用率,可以把世界坐标系下的位置纹理,改变为NDC(Normalized Device Coordinates)空间下只有一个通道的深度纹理,并且深度值映射到[0,1]区间。
世界坐标系位置信息需要三个浮点数通道纹理,而深度信息只需要一个浮点通道纹理。在后期的渲染阶段,可以通过矩阵转换,把深度信息还原为位置信息。因为深度缓冲区的值是非线性,所以需要转换深度值到线性的深度表达。公式(1)中,M代表矩阵,P代表几何体顶点坐标。
三维场景顶点经过投影变换到裁剪空间坐标系,除以齐次坐标系w分量归一化到NDC坐标。经过转换深度值变为公式(2)所示。
相机空间的z值总是投影到近平面,不依靠X,Y坐标的影响,造成M13=M23=M14=M24=0,并且在OpenGL的投影矩阵中M34=-1,M44=0,因此最终转换的相机空间下的z值如公式(3)所示。

2.2 构建光源链表
(1)软件深度测试
在渲染过不透明几何体后,深度缓冲区已经写入不透明物体的深度值。接着渲染光源几何体可能会有图1中的三种情况:光源被场景遮挡、光源与场景几何体相交、光源在场景几何体之前。
第一种情况光源几何体深度测试失败,完全被遮挡意味着看不见光照效果,因此光源几何体不用加入到光源链表。第三种情况时深度测试成功,容易保存光源最大最小深度值。但是第二种情况,因为光源的背面被场景遮挡,造成背面深度测试失败,所以不能取得背面的深度值。为了保证光源结合体的背面被像素着色器处理,需要关闭硬件深度测试,在片元着色器中进行软件深度测试。
(2)分配链表

图1 光源和场景几何体
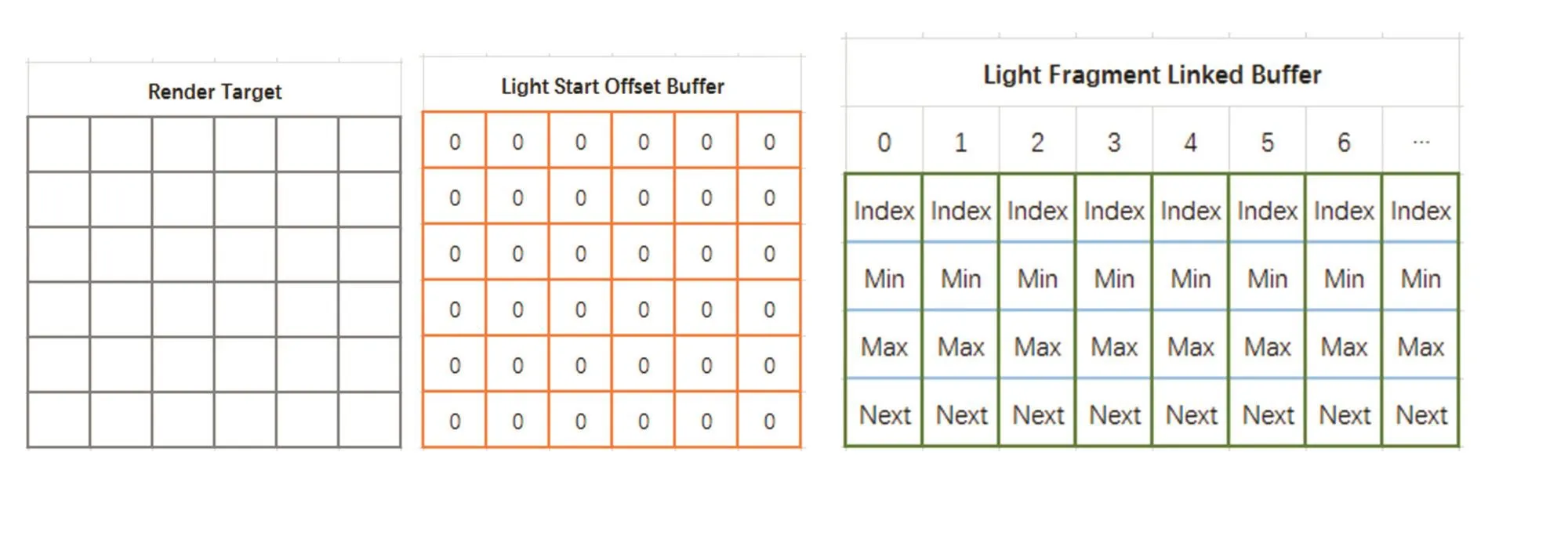
图2 光源链表结构初始图
如图2所示,LightFragmentLinkedBuffer结构存储最大最小深度值,几何体的最小最大深度值被硬件光栅化,却是在不同的时间传送到片元着色器。光源几何体的最小深度值等于光源正面的深度值,最大深度值等于光源背面的深度值。
第一遍Pass打开背面裁剪,仅允许光栅化光源几何体正面。在OpenGL的片元着色器中可以通过gl_FrontFacing判断是否当前三角片元是否为正面。当前片元为正面时执行软件深度测试。并且比较当前光源结合体的深度值和深度缓冲器的深度值,如果深度测试失败,那么提前返回,不必接着做后续计算。光源索引可通过OpenGL原子计算器执行递增操作,每个片元都会得到唯一的正整数值。LightStartOffsetBuffer使用头插法来更新头指针链表。而LightFragmentLinkedBuffer写入光源的索引,最小深度值,以及Next指针。因为现在没法得到光源几何体的背面深度值,所以暂时不写入最大深度值。
第二遍Pass打开正面裁剪,硬件光栅化光源几何体的背面。因为LightStartOffsetBuffer纹理大小和窗口一致,所以可以通过转换的纹理坐标取纹理值得到头指针。根据头指针的索引取出LightFragmentLinked-Buffer的数据,如果当前渲染的光源几何体的索引和缓冲区数据的光源索引一致,那么更新最大深度值,并且提前结束链表循环。
(3)链表访问
前向渲染和延迟渲染访问光源链表都是一样的方式,LightStartOffsetBuffer取出当前片元链表的头指针索引。如果头指针索引有效,那么表明当前片元存在链表数据。根据头指针索引取出LightFragmentLinked-Buffer的数据,包含最小最大深度值,进行简单的深度测试。如果当前场景几何体的深度值在光源几何体的深度值区间,表明会被光源几何体所影响,进而进行光照计算。如果位于区间外,结束本次渲染继续进行链表遍历。最后计算出当前片元被光源链表中光源的光照值,再用 HDR(High-Dynamic Range)[3]把光照结果映射到计算机所表示的颜色区间。
3 实验结果与分析
3.1 实验平台
本文算法的运行环境为:Intel Xeon CPU E3-1230 V2@3.30GHz的处理器,8G内存,显卡为NVIDIA Ge-Force 670和Windows 10的操作系统,编程环境为Visual Studio 2012。
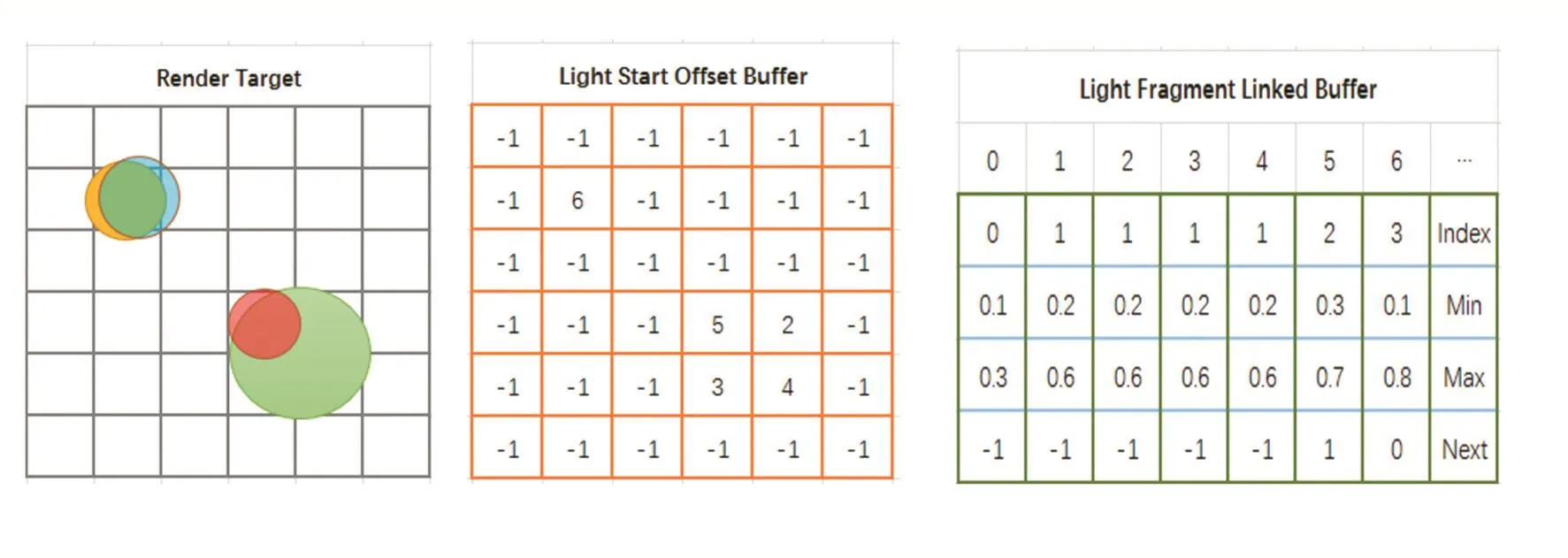
图3 光源链表无序访问视图

图4 延迟光照和LLL算法效果对比
3.2 实验结果分析
(1)效果分析
如图4(a)所示,在传统延迟光照渲染光线中,程序无法处理透明物体天马。但是在图4(b)中,光源链表算法统一了不透明物体和透明的物体的光照过程,使用相同的链表缓存来计算光照,因此图中天马带有平行光和点光源的光照效果。
(2)效率分析

表1 LLL算法和DS+FS效率对比(单位:FPS)
表1可以看出,光源链表算法在多光源场景中可以提高延迟光照的性能。在少量光源时,因为建立光源需要额外花费时间,所以少量光源场景时处理透明物体性能提升不明显。而在多光源场景或者场景中存在多个透明物体时光源链表算法可以更好提升性能。因为延迟渲染管线需要多一个前向渲染绘制过程,其次前向渲染是没有解耦光源和物体,最后对延迟渲染引擎也是一个额外的负担。
光源链表算法统一了透明和不透明物体,光源数据都在显存中,无需从CPU端到GPU端带宽的占用。而且光源链表解耦光源和物体,只需要针对光源几何体内部做深度测试,通过片元就进行光照,进而提高了性能。
4 结语
针对于三维场景中带有透明物体或粒子等特效时,光源链表算法能帮助简化了光照渲染管线。而且光源链表算法能改善延迟渲染的性能。除此之外,光源链表算法的灵活性容易集成传统光照算法,例如材质是皮肤、头发、布料、汽车喷漆等。未来的工作考虑设计缓存并发的光源链表结构体来进一步提高性能。
参考文献:
[1]Tomas Akenine-Moller,Tomas Moller,and Eric Haines.Real-Time Rendering.A.K.Peters,Ltd.,Natick,MA,USA,2nd Edition,2002.
[2]Matt Pharr and Greg Humphreys.Physically Based Rendering,Second Edition:From Theory To Implementation.Morgan Kaufmann Publishers Inc.,San Francisco,CA,USA,2nd Edition,2010.
[3]Greg Ward et al.High Dynamic Range Image Encodings,2006.
[4]KOONCE,R.2008.Deferred Shading in Tabula Rasa.In GPU Gems 3,429-457.
[5]Deering,M;Winner,S;Schediwy,B.;Duffy,C.and Hunt,N.The Triangle Processor and Normal Vector Shader:A VLSI System for High Performance Graphics.In:Proceedings of the 15th Annual Conference on Computer Graphics and Interactive Techniques(SIGGRAPH 88).Vol.22,Issue 4.New York:The ACM Press,1988:21-30.
[6]Holger Gruen and Nicolas Thibieroz.Order Independent Transparency and Indirect Illumination Using Dx11 Linked Lists.Presentation at the Advanced D3D Day Tutorial,Game Developers Conference,San Francisco,CA,March 9-13,2010
[7]Nicolas Thibieroz.Order-Independent Transparency Using Per-Pixel Linked Lists.GPU Pro,2:409-431,2011.
[8]Jason C.Yang,Justin Hensley,Holger Grün,and Nicolas Thibieroz.Real-Time Concurrent Linked List Construction on the GPU.In Proceedings of the 21st Eurographics Conference on Rendering,EGSR'10,pages 1297-1304,Aire-la-Ville,Switzerland,Switzerland,2010.Eurographics Association.
[9]Markus Billeter,Ola Olsson,Ulf Assarsson.Tiled Forward Shading.GPU Pro 4:Advanced Rendering Techniques,4:99,2013
[10]Abdul Bezrati.Real-Time Lighting Via Light Linked List.Presentation at SIGGRAPH2014,2014.
