基于等距映射的非线性系统集员参数估计
2018-03-26纪镐南
柴 伟,纪镐南
(北京工业大学信息学部 北京 朝阳区 100124;计算智能与智能系统北京市重点实验室 北京 朝阳区 100124)
参数估计是系统辨识中的一个重要内容,已有很多方法被提出。传统的方法基于随机误差假设,如最小二乘法或极大似然法,它们假设误差是统计特性已知的随机变量。然而,当观测数据不足或误差是确定性时,采用随机误差假设不合适。
集员参数估计采用了更符合实际需要的误差描述,即假定误差是统计特性未知的有界变量。该方法的目的是给出所有与观测数据、模型结构和误差有界假设相一致的参数向量所组成的集合,称这个集合为参数可行集。当参数为线性时,可行集为凸多面体。但是在很多实际应用场合,系统是参数非线性的,此时,可行集为非凸甚至非连通的。精确描述可行集十分困难,因此非线性系统集员参数估计的关键是找到一个既容易表达又能在计算成本与精度之间取得较好折中的可行集近似描述结果。
现有的非线性系统参数可行集近似描述方法可以粗略地分为以下4类:1)计算一个能包含可行集的集合,该集合称为可行集的外界。外界可以是一个单一的凸集合,如盒子[1]、椭球[2]或多面体[3-4],也可以是多个盒子的并集[5]。2)计算一个能包含于可行集的集合,该集合称为可行集的内界。内界一般由可行集内的采样点构成[2,6]。采用一个凸集合[1-4]作为可行集外界或在可行集内采样[2,6]所得结果可能过于保守。3)用若干个盒子的并集[7-10]以任意精度从内外两个方向逼近可行集的边界,但是它的计算复杂度与参数的维数成指数关系。另外,复杂模型的最小包含函数很难构建,导致盒子过度保守使算法的收敛速度很慢。4)直接给出可行集的近似边界[11-14]。这种方法可以处理针对复杂模型较难构建最小包含函数的问题。
本文给出一种新的非线性系统集员参数估计方法。该方法从流形学习的角度出发,视可行集边界与n维空间中的单位球面(n-1-sphere)(n是参数的个数)为同胚,构造二者之间的同胚映射的近似。这个映射被建立后就可以用来将n-1-sphere映射为可行集近似边界。构造该映射采用如下技术:首先,将等距映射(Isomap)[15]与数据归一化结合,把在可行集边界上均匀采样得到的数据集映射为包含于n-1-sphere的数据集;然后,基于非参数方法得到可行集边界与n-1-sphere的同胚映射的近似。本文方法的性能通过两个例子加以说明。
1 问题的提出
定义非线性系统模型为:


式中,εk是已知正数。

集合PN称为参数可行集。式(3)可改写为:
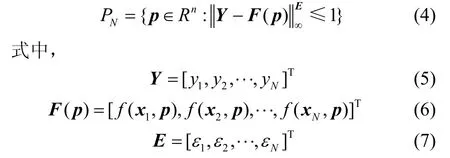

ek包含建模误差和测量噪声等,随机方法假设误差ek的统计特性已知或部分已知。但是该假设在实际应用中可能会出现问题,原因有:当观测数据十分有限时,不易确定误差ek的统计特性;在某些情况下误差ek可能是确定性的。集员参数估计采用了更接近实际的有界误差假设式(2),该方法的目的是有效描述参数可行集PN。当系统是参数非线性时,可行集PN比较复杂,一般很难精确描述。近似描述可行集的方法有4种,已经在前面介绍。需要说明的是,这里假设可行集PN是有界且连通的。可行集是否连通涉及到可辨识性问题,该内容已超出本文的讨论范围,关于可辨识性请参考文献[16]及其引用文献。在假设可行集PN是有界且连通的前提下,下面给出一种逼近可行集边界的方法。
2 基于Isomap的集员参数估计
2.1 可行集边界的近似

图1 映射(⋅)的构造
2.2 构造映射(⋅)的步骤1)和步骤2)
Isomap是一种概念上简单但是很实用的流形学习方法,它可以将输入数据映射到低维空间,并且在低维空间里数据的本征几何属性得到很好地保留。Isomap的优点在于较高的计算效率、较少的自由参数和非迭代全局优化。
1)通过先验知识或者最优化方法得到一个包含可行集的盒子;
2)定义一个均匀的网格以覆盖这个盒子;
3)用无导数线搜索方法找到可行集边界与网格中盒子的边的交点。

图2 可行集边界采样
Isomap将数据对θi与θj之间的欧式距离d(i,j)作为输入。用Isomap将数据集映射为数据集包含以下步骤:
1)构建邻域图G。当θi是θj的K个最邻近点中的一个时,则将θi和θj相连,从而构成一个图G,设定路径的长度为d(i,j)。
2)计算最短路径。若θi与θj相连,则初始化最短路径否则,令,对,更新所有元素为更新过程完成之后,可以得到最短距离矩阵
3)计算嵌入。令λs是矩阵的第s个特征值(降序),算子τ定义为其中矩阵L是距离的平方H是中心矩阵δij是Kroneckerδ函数。是第s个特征向量的第i个分量,然后令向量ρi的第s个分量为
运行Isomap所获得的嵌入保持了流形的本征几何属性,但是它的形状是不规则的。不难发现嵌入数据具有零均值和对角协方差。为了得到有规则形状的数据集,需将数据集映射为数据集
2.3 构造映射(⋅)的步骤3)
2)通过最小化代价函数σ(w)=(约束条件为:且若ηi不是向量η的最近邻,则wi= 0)计算最优线性重构权重wi;
2.4 近邻个数K的确定

σ(K)越小,边界近似效果越好。因此,最优近邻个数K∗应该是。最后,所构造的映射定为
3 数值仿真
3.1 例子1
考虑如下非线性系统模型[2]:

式中,yk和uk分别是系统输出和输入;p1和p2是参数。可以看出,回归向量实验过程中,设定并且设计输入假设误差ek在区间上服从均匀分布,因而,误差界为1.5。实验获得数据集误差序列−0.213 3,−0.586 1,−0.931 0,−0.919 7,0.546 7,−0.591 7,0.125 0,−1.047 4,0.593 7,−0.364 9,1.080 0,1.061 0,0.280 7,−0.010 3,1.199 3,0.964 9,0.434 7, 0.953 9,0.480 7,−0.474 1,−0.630 8,−0.476 4,0.102 2,0.681 3,−0.572 1,1.015 5,0.204 2,−0.388 8,0.608 2,0.139 7,−0.165 4,0.583 7,0.363 9,0.884 5,1.370 5,0.067 8,1.140 4,−0.981 1,1.439 2,−0.685 7,−0.743 0,1.127 2,0.711 9}。

图3 可行集边界采样
借鉴文献[1]的思想,采用最优化方法得到一个包含可行集的盒子,定义一个尺寸为41× 31的均匀网格以覆盖这个盒子。计算可行集边界与网格中盒子的与p2轴平行的边的交点,共获取76个。图3显示了这些可行集边界采样点,参数K′设定为2。在1-sphereS1上均匀取400个点代入式(9)和式(10),以确定最优近邻个数K。由于则设定K为28。图4所示为σ与K的对应关系。图5a和图5b分别表示用本文方法和SVM方法[12]得到的可行集近似边界。对于后者,使用了在上均匀采样得到的130个点,及RBF核宽度为的LS-SVM来获得最优结果。图中实线和虚线分别表示精确边界和近似边界,加号表示参数向量的真值。从图中可以看出,本文方法比SVM方法具有更好的逼近精度。同时也可以看出,用单一凸集合作为可行集外界的方法所得结果要比本文方法保守性高。

图4 σ与K的对应关系

图5 可行集近似边界
3.2 例子2
考虑经典的单室开放一级吸收模型[11]:

式中,yk是在xk时刻观察到的药物浓度;Ka是吸收速率常数;Ke是消除速率常数;Dose是药物剂量;V是分布容积。假设常数Ka和Ke是待估计量,实验过程中,设定V=60 L。口服药物1 100 mg后,分别在0.25、0.5、1、1.5、2、4、6、8、10、12、18、24 h后测量血浆中的药物浓度,从而获得一个输入输出数据集。假设误差ek服从均值为0 mg/L和标准差为0.25/3 mg/L的截断正态分布,误差序列−0.004 9,−0.084 2,0.051 2,0.042 3,0.141 0,0.049 3,−0.053 6,0.031 7,−0.084 1,−0.001 6,−0.004 0}。因而,误差界为0.25 mg/L。

图6 可行集边界采样

图7 σ与K的对应关系
借鉴文献[1]的思想,采用最优化方法得到一个包含可行集的盒子[1.54,1.66]×[0.355,0.395]。定义一个尺寸为31× 21的均匀网格以覆盖这个盒子。计算可行集边界与网格中盒子的边的交点,共获取84个。图6显示了这些可行集边界采样点。参数K′设定为6。在上均匀取400个点代入式(9)和式(10),以确定最优近邻个数K。由于,则设定K为25。图7示出了σ与K的对应关系。图8a和8b分别为用本文方法和SVM方法[12]得到的可行集近似边界。对于后者,使用了在[1.54,1.66]×[0.355,0.395]上均匀采样得到的147个点,及RBF核宽度为的LS-SVM来获得最优结果。图中实线和虚线分别表示精确边界和近似边界,加号表示参数向量的真值。从图中可以看出,本文方法比SVM方法具有更好的逼近精度。

图8 可行集近似边界
4 结束语
本文给出一种新的非线性系统集员参数估计方法,可以处理针对复杂模型较难构建最小包含函数的问题。该方法假设可行集是有界且连通的,寻找可行集边界与n-1-sphere之间同胚映射的近似。映射构造成功后,就可以将n-1-sphere映射为可行集的近似边界。本文通过两个例子说明该方法的优势。接下来的工作将研究如何将方法延伸到用于有界非连通可行集的边界逼近。
[1]MILANESE M, VICINO A.Estimation theory for nonlinear models and set membership uncertainty[J].Automatica,1991, 27(2): 403-408.
[2]BAI E W, ISHII H, TEMPO R.A Markov chain Monte Carlo approach to nonlinear parametric system identification[J].IEEE Transactions on Automatic Control,2015, 60(9): 2542-2546.
[3]CHAI W, SUN X F, QIAO J F.Set membership state estimation with improved zonotopic description of feasible solution set[J].International Journal of Robust and Nonlinear Control, 2013, 23(14): 1642-1654.
[4]BRAVO J M, ALAMO T, REDONDO M J, et al.An algorithm for bounded-error identification of nonlinear systems based on DC functions[J].Automatica, 2008, 44(2):437-444.
[5]BORCHERS S, FREUND S, RATH A, et al.Identification of growth phases and influencing factors in cultivations with AGE1.HN cells using set-based methods[J].PLoS ONE,2013, 8(8): e68124.
[6]NURULHUDA K, STRUIK P C, KEESMAN K J.Set-membership estimation from poor quality data sets:Modelling ammonia volatilisation in flooded rice systems[J].Environmental Modelling & Software, 2017, 88: 138-150.
[7]JAULIN L, WALTER E.Set inversion via interval analysis for nonlinear bounded-error estimation[J].Automatica, 1993,29(4): 1053-1064.
[8]RAÏSSI T, RAMDANI N, CANDAU Y.Set membership state and parameter estimation for systems described by nonlinear differential equations[J].Automatica, 2004, 40(10):1771-1777.
[9]HERRERO P, DELAUNAY B, JAULIN L, et al.Robust set-membership parameter estimation of the glucose minimal model[J].International Journal of Adaptive Control and Signal Processing, 2016, 30(2): 173-185.
[10]PAULEN R, VILLANUEVA M E, CHACHUAT B.Guaranteed parameter estimation of non-linear dynamic systems using high-order bounding techniques with domain and CPU-time reduction strategies[J].IMA Journal of Mathematical Control and Information, 2016, 33(3):563-587.
[11]LAHANIER H, WALTER E, GOMENI R.OMNE: a new robust membership-set estimator for the parameters of nonlinear models[J].Journal of Pharmacokinetics and Biopharmaceutics, 1987, 15(2): 203-219.
[12]KEESMAN K J, STAPPERS R.Nonlinear set-membership estimation: a support vector machine approach[J].Journal of Inverse and Ill-Posed Problems, 2004, 12(1): 27-41.
[13]HERRERO J M, BLASCO X, MARTINEZ M, et al.Non-linear robust identification using evolutionary algorithms: Application to a biomedical process[J].Engineering Applications of Artificial Intelligence, 2008,21(8): 1397-1480.
[14]CHAI W, SUN X F.Set membership estimation by weighted least squares support vector machines[J].Electric Machines and Control, 2009, 13(3): 431-435.
[15]TENENBAUM J B, de SILVA V, LANGFORD J C.A global geometric framework for nonlinear dimensionality reduction[J].Science, 2000, 290(5500): 2319-2323.
[16]JAUBERTHIE C, TRAVE-MASSUYES L, VERDIERE N.Set-membership identifiability of nonlinear models and related parameter estimation properties[J].International Journal of Applied Mathematics and Computer Science,2016, 26(4): 803-813.
[17]LEE J A, VERLEYSEN M.Nonlinear dimensionality reduction of data manifolds with essential loops[J].Neurocomputing, 2005, 67: 29-53.
[18]CHAI W.Nonlinear set membership identification by locally linear embedding[J].International Journal of Innovative Computing, Information and Control, 2014,10(6): 2193-2207.
[19]SAUL L K, ROWEIS S T.Think globally, fit locally:Unsupervised learning of low dimensional manifolds[J].Journal of Machine Learning Research, 2003, 4(2):119-155.
