基于有偏向的重启随机游走链路预测算法
2018-03-26吕亚楠贾承丰瞿倩倩
吕亚楠,韩 华,贾承丰,瞿倩倩
(武汉理工大学理学院,武汉 430070)
0 引言
近年来,随着复杂网络在各领域的渗透,许多相关工作对复杂网络的拓扑结构、网络演化进行研究,以期能全面理解复杂网络的本质特征[1]。其中链路预测作为研究网络演化的一个分支,受到越来越多学者的关注。链路预测是根据静态或动态的网络数据来预测网络中两个不相连的节点之间产生连边的可能性,并观察给定的方法对新链路出现的预测效果。链路预测方法在大多数领域中都有相关应用,如生物系统中,探索蛋白质之间的相互作用[2];在线社交网络中,推荐可能认识的朋友[3];航空网络中,推断影响网络演化的重要因素[4]等。
当前,基于网络结构相似性的链路预测因其方法简单且实际操作性强而引起大量研究。利用节点间相似性的方法假设:在网络中,根据节点之间的拓扑特征,两个节点之间的相似性越大,它们之间存在连边的可能性就越大[5]。而且主要依赖于网络结构,像节点的度、聚集系数[6]、节点之间的路径[7]、社团结构[8]等。根据所用结构信息的不同,基于网络结构的相似性预测算法可以分为如下三类:基于局部信息的相似性指标、基于路径的相似性指标、基于随机游走过程的相似性指标。基于局部信息的相似性指标是指只通过节点局部信息,像节点的度、最近邻居,计算得到的相似性指标。这类指标的优势在于计算复杂度低,适用大规模的网络。基于路径的相似性指标是利用要预测的两个节点之间的路径信息,像节点之间路径数量,路径中间节点的信息,计算得到的相似性指标。这类指标既有基于全局信息的路径指标,也有基于局部信息的路径指标,当考虑多阶路径信息的贡献时,计算复杂度相对较高。基于随机游走的相似性指标是基于随机游走过程定义的,包括平均通勤时间指标(ACT)[9]、有重启的随机游走指标(RWR)[10]、SimRank指标(SimR)[11]等。这类指标大多数是基于全局信息的指标,且这些指标不仅仅在链路预测中应用,在推荐系统[12]、排名[13]、社团划分[14]等也有应用。
随机游走作为研究网络结构和特性的一种方法,在基于网络结构的相似性方法中得到广泛关注。网络中的随机游走是指粒子从初始节点出发,以一定的概率随机游走到它的邻居节点,然后再以一定的概率随机游走到邻居节点的邻居节点,这样一直游走下去,直到达到平稳状态。基于随机游走的特性,Li Rong-Hua等人[15]认为在真实网络中,网络中的节点不仅倾向于连接度小的节点,而且也倾向于连接中心节点,提出一种最大熵随机游走的链路预测算法,其中最大熵随机游走包括了网络节点的中心性。刘思等人[16]考虑到网络结构上不同邻居节点间的相似性对转移概率的作用,利用网络表示学习算法的DeepWalk学习网络节点的潜在结构特征,提出一种基于网络表示学习与随机游走的链路预测算法。Jin Woojeong等人[17]发现有重启的随机游走对所有节点使用相同的重启概率,限制了随机游走的表现性,且重启概率需要人为选择,于是提出一种有监督和拓展重新启动的随机游走用于排序和链路预测,使得每个节点都对应一个重启概率。
在大多数的随机游走过程中,粒子由当前节点游走到下个节点的转移概率都是相等的。但由网络的度度相关性[18]可以看出,节点之间的连接不是随机产生的,粒子在游走过程中会受到节点度值的影响。且现实网络结构复杂多样,粒子在游走过程中不一定是等概率的移动,而是会以某种偏向进行游走。基于上述问题,本文提出一种有偏向的重启随机游走方法用于链路预测,使粒子在游走的过程中偏向于移动到与初始节点相似的节点上,进而提高预测精度。本文主要工作如下:第一部分介绍链路预测的基本概念、经典指标及评价指标;第二部分定义一种新的链路预测算法,即有偏向的重启随机游走算法;第三部分介绍数据集及相关参数,然后进行实验,并对结果进行分析;第四部分总结全文及进一步工作。
1 基本概念
1.1 问题描述
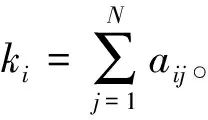
图1为一个简单的无权无向网络。根据上面的描述,可以看出网络的节点集为V=(v1,v2,v3,v4,v5,v6),连边集为E=(e1,e2,e3,e4,e5,e6,e7)。若网络用邻接矩阵A表示,则为

图1 一个简单无权无向网络示例
且各节点的度值为k1=k2=k3=3,k4=k6=2,k5=1。那么链路预测就是根据目前网络的连边信息,运用给定的预测方法计算出网络中尚未产生连边的节点对v1和v4、v1和v6、v2和v5、v2和v6、v3和v4等产生连边的可能性。
1.2 典型的链路预测算法
基于相似性的链路预测算法是根据网络的拓扑结构所定义,且常被作为基准算法与所提出的新算法作对比。基于相似性的指标一般可以分为基于局部信息和全局信息两类。其中基于局部信息的预测算法有共同邻居指标(CN指标)、Salton指标、Jaccard指标、大度节点有利指标(HPI指标)、大度节点不利指标(HDI指标)、Adamic-Adar指标(AA指标)、资源分配指标(RA指标)等等。基于全局信息的预测算法,一般考虑网络的所有路径或者节点之间的所有结构,其中包括Katz指标、LHN-II指标、平均通勤时间(ACT指标)、余弦相似性(Cos+指标)、有重启的随机游走(RWR指标)、SimRank指标等等[5]。从上述类别中,分别选取以下6种经典的链路预测算法作为基准算法。
1)共同邻居(CN)
共同邻居指标是最基础的相似性指标,对于未连边的两个节点x和y的相似性定义为它们共同邻居节点的个数。用式(1)表示为
Sxy=|Γ(x)∩Γ(y)|
(1)
其中,Γ(x)为节点x的邻居节点集合,显然,这里的Sxy就等于两节点之间长度为2的路径数目。
2)资源分配(RA)
资源分配指标考虑网络中没有直接相连的两个节点x和y,从节点x可以传递一些资源到节点y,在这个过程中,它们的共同邻居成为传递的媒介,且每个媒介都将资源平均分配传给它的邻居,则节点x和y的相似度定义为
(2)
其中,kz为节点z的度值。
3)Katz指标
Katz指标考虑了网络的所有路径,其定义为
(3)

4)平均通勤时间(ACT)

(4)
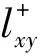
5)有重启的随机游走(RWR)
假设随机游走粒子在每走一步时都以一定概率返回初始位置。设粒子返回概率为1-c,P为网络的马尔科夫概率转移矩阵,其元素为Pxy=1/kx表示节点x处的粒子下一步走到相邻节点y的概率。某一粒子初始时刻在节点x处,则t+1时刻该粒子到达网络各个节点的概率向量为
πx(t+1)=c·PTπx(t)+(1-c)qx
(5)
其中,qx为初始状态,它是一个N维列向量且仅有第x个元素为1,其他元素都为0。式(5)的稳态解为πx=(1-c)(I-cPT)-1qx,其中元素πxy为从节点x出发的粒子最终有多少概率达到节点y,则RWR相似性定义为
Sxy=πxy+πyx
(6)
6)SimRank指标(SimR)
SimRank指标的基本假设是如果两节点所连接的节点相似,那么这两个节点就相似。用式(7)表示为
(7)
其中,假定Sxx=1,C∈[0,1]为相似性传递时的衰减参数。
1.3 评价指标
为了测试算法的准确性,一般将已知的连边E分为两部分:训练集ET和测试集EP。训练集ET作为实验时可观察到的网络信息,用于计算节点的相似性得分。测试集EP作为实验时要预测的网络信息,用于对比实验预测的结果。这里,E=ET∪EP,且ET∩EP=Ø,令U为N(N-1)/2个节点对组成的全集,那么将属于U但不属于E的边称为不存在的边,属于U但不属于ET的边为未知边。
文中使用链路预测中评价准确性认可度高的指标——AUC指标。AUC指标是从整体上衡量指标的精确度,它是指在测试集中随机选择一条边的分数值比随机选择的一条不存在的边的分数值高的概率[19]。实验时,每次随机从测试集中选取一条边,再从不存在的边中随机选择一条,如果测试集中的边分数值大于不存在的边的分数值,那么就加1分,如果两个分数值相等就加0.5分。这样独立比较n次,如果有n′次测试集中的边分数值大于不存在的边分数,有n″次两分数值相等,那么AUC指标的定义为
(8)
显然,如果所有分数都是随机产生的,AUC=0.5。
2 基于有偏向的重启随机游走链路预测
借鉴相关的有偏向随机游走过程[20],改变粒子在节点之间的转移概率,使其在游走过程中具有一定的度偏向性,再利用有重启的随机游走过程,对网络中未连边的节点对进行相似性计算,找到每个网络最佳的度偏向调节系数值,以达到提高预测精度的目的。
2.1 有偏向的重启随机游走
有偏向随机游走是指随机游走粒子由当前节点x以偏向转移概率wxy游走到其邻居节点y,然后再从节点y以偏向转移概率wyz游走到节点y的其中一个邻居节点z,重复这个过程,直至到达平稳状态。重启随机游走是指粒子在每一步游走的时候都以概率α移动到下一个节点,或者以概率1-α跳回初始节点,这个过程类似于网页排序算法PageRank。有偏向的重启随机游走是将这两个过程进行融合,即当游走粒子从网络中的某一个节点出发,每一步面临两个选择,以概率α移动到相邻节点,或以概率1-α返回初始节点。当以概率α移动到相邻节点的时候,此时会以偏向概率w选择其中一个邻居节点作为下一步移动到的节点,然后重复以上过程,直至达到平稳状态。有偏向的重启随机游走既避免了有偏向随机游走在未达到平稳状态时游走粒子发生终止现象,即游走粒子进入死角,又解决了有重启的随机游走过程中节点之间等概率转移的问题。
定义1度偏向转移概率
根据马尔科夫链过程[21]可知,下一时刻节点的游走只与当前节点的状态有关。基于度有偏向随机游走过程中,当前节点移动到下一节点时,与当前节点的邻居节点度值成比例,即kβ,其中β是度偏向调节参数,从β值的大小可以看出游走粒子在网络中是偏向于度大的节点游走还是度小的节点游走以及偏向的程度。
网络中基于度有偏向随机游走的转移概率定义[20]为
(9)

定义2有偏向的重启随机游走指标
将定义1中每个节点的度偏向转移概率用于有重启随机游走中,改变节点之间的等概率转移矩阵,进而得到有偏向的重启随机游走指标(Biased random walk with restart,简称BRWR指标)。某一粒子初始时刻在节点x处,则t+1时刻该粒子到达网络各个节点的概率向量为
πx(t+1)=α·WTπx(t)+(1-α)qx
(10)
其中,W为式(9)的度偏向转移概率矩阵,1-α为重启概率,qx表示初始状态,它是一个N维列向量且仅有第x个元素为1,其他元素都为0。当t→∞时,由马尔科夫链的平稳状态[21]可知即使再经过一步状态转移,其状态概率仍保持不变,即Π=WTΠ,因此得到式(10)稳态解为
πx=(1-α)(I-αWT)-1qx
(11)
那么BRWR相似性指标为
(12)
其中,元素πxy为从节点x出发的粒子最终有多少概率达到节点y。
2.2 算法流程
本算法首先通过设定β的一个取值范围,将范围内各个不同的β值代入算法中,经过循环计算,观察β取值对预测结果的影响(具体情况参见3.2),找到最佳度偏向调节参数βopt,再将βopt值代入BRWR算法中,得到节点之间的相似性得分。在最佳的βopt值下,BRWR算法主要流程如下:
算法 BRWR
输入 网络的邻接矩阵A=[aij],重启概率1-α,最佳度偏向调节参数βopt。
输出 节点的相似性得分矩阵S=[sij]。
1)初始化偏向转移矩阵W←0N×N,节点相似性得分矩阵S←IN×N;
2)利用式(9)计算网络中各节点间的偏向转移概率并更新归一化的偏向转移矩阵W;
3) Fori= 1 toNdo
4) WhileS不收敛do
5)πx=(1-α)(I-αWT)-1qx; //计算节点x与其余各节点的相似性值
6) End While;
7) End for;
8) ReturnS。
2.3 算法收敛性
定理1BRWR算法是收敛的。

2)当随机游走过程遍历到某一节点后,因为随机游走过程中存在重启概率,所以再次遍历到这个节点时,所需的步数是不确定的,故整个随机游走过程是非周期的。
3)当图中任意一个节点被遍历后,都可能在一定步数内再次遍历这个节点,且再次遍历之前经过的步数是不完全相同的。
由以上3点,可得出BRWR算法是各态历经的[22],故此算法是收敛的。
2.4 复杂度分析
定理2BRWR算法的时间复杂度为O(N3)。
证明:因为在t→∞时,BRWR算法会达到稳态,此时借助稳态解πx=(1-α)(I-αWT)-1qx,可以看出要求出矩阵I-αWT的逆,那么一般求一个N×N矩阵的逆或伪逆的时间复杂度为O(N3)[23],故此算法的时间复杂度为O(N3)。
3 实验结果与分析
本文将实验分为两大部分,一是利用AUC评价指标,观察β值的变化对预测结果的影响,进而确定最佳βopt的值;二是在最佳βopt值下,BRWR指标与6个经典链路预测指标作对比,观察BRWR指标的预测效果。实验借助Matlab 2014作为实验工具,平均进行30次独立实验,实验时随机划分训练集和测试集,其中训练集所占比例为90%。
3.1 数据集及相关参数
为了测试提出算法的有效性,采用6个具有代表性的真实网络数据集[24],忽略网络连边的权重与方向,数据集包括:美国航空网络(USAir)、爵士乐手网络(Jazz)、线虫新陈代谢网络(Metabolic)、佛罗里达生态系统食物链网络(FWFW)、线虫神经网络(C.elegans)、美国政治博客网络(P-Blogs)。数据集的网络结构特征如表1,其中N为节点数,M为连边数,〈K〉为平均度,〈C〉为平均聚集系数,R为匹配系数。

表1 各数据集的网络结构特征
3.2 不同β值下BRWR指标的AUC值变化
针对6个实际网络数据,首先分析了不同网络中度偏向调节参数β对BRWR指标预测结果的影响,这里固定α=0.85,β步长取0.01,测试集与训练集的比例为1:9。图2显示了不同β值下所有网络的AUC值变化曲线。相比β=0(即无偏向随机游走),指标都有不同程度地提高其预测精度,且在合适的参数下均可以取得最大预测精度,说明基于度有偏向的随机游走过程对链路预测有影响。在取得最大精度值后AUC值变化曲线都会呈现不同程度的下降,其中USAir、Jazz、Metabolic、C.elegans网络在取得最大精度值后曲线下降较快,在一定程度上说明粒子在这些网络中游走时,偏向游走到度大节点的程度越大,预测的准确度越低。
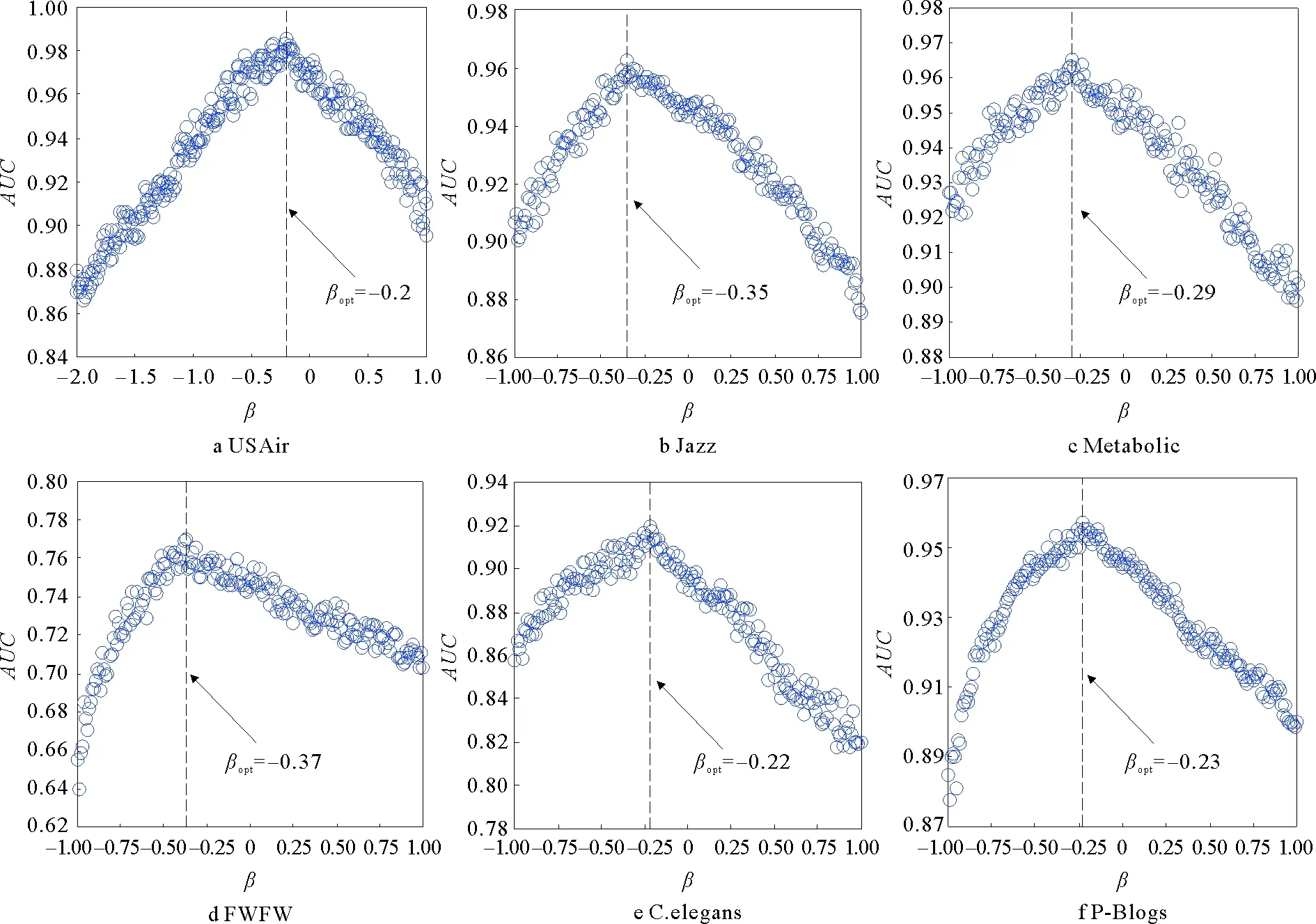
图2 不同β值下BRWR指标的预测结果
BRWR指标的AUC最大值均高于β=0时的预测值,这表明有偏向性的随机游走确实能够提高链路预测的预测精度。同样,相比β=1时,即类似于优先连接[25],最大的AUC值也明显更高,侧面表达出粒子在这些网路中不偏向于游走到度大的节点。而且在这6个网络中,从每个网络的最优β值可以看出,β值在(-1,0)之间,表明粒子偏向于游走到度小的节点,正如Adamic-Adar指标[26]的思想,度小的共同邻居节点的贡献大于度大的共同邻居节点。这里β<0也相当于对网络中度大节点进行惩罚。实际应用中可在一定范围内调节β值,可以提高预测精度。
3.3 与其他典型相似性指标对比
为了进一步说明有偏向随机游走过程的可行性及BRWR指标的有效性,以下将与经典的相似性指标进行对比性分析,各个相似性指标的AUC结果对比如表2所示。可以看出,6个实际网络中,相比CN、RA、Katz、ACT、SimR、RWR指标,BRWR指标对预测精度都有一定程度的提高。CN、RA指标属于局部相似性指标,由于RA指标在共同邻居节点的基础上为每个节点赋予一个权重值,所以在局部相似性指标中RA指标的预测精确相对好。Katz、ACT、SimR、RWR指标属于全局指标,其中Katz指标是考虑节点之间的所有路径,ACT、SimR、RWR指标都是基于随机游走过程,且RWR指标在这些全局指标中表现最好。若以RWR指标为基准,由表2观察到BRWR指标相较RWR指标,其预测精确度平均提升了2.24%,且C.elegans网络的AUC值提高了3.97%。由定理2可知BRWR指标的时间复杂度为O(N3),和RWR指标的时间复杂度一样,那么在时间复杂度相同的情况下,可以看出BRWR指标的预测准确度比RWR指标更好,说明有偏向性的重启随机游走对链路预测是有效和可行的。

表2 不同指标下AUC值对比
4 结论
本文在有重启的随机游走算法的基础上,考虑了网络节点度值对转移概率的影响,提出一种基于有偏向的重启随机游走链路预测算法。首先利用有偏向性的随机游走过程得到节点之间的度偏向转移概率,然后将度偏向转移概率融合到有重启的随机游走过程中,最后通过对AUC值的多次计算找到最佳的度偏向调节参数,从而得到最优的AUC值。实验结果表明,有偏向性的游走能够提高连边的预测精度,且相比其他经典算法,有偏向的重启随机游走链路预测算法的预测效果更加准确。在下一步的研究中,可以尝试一种同时调节度偏向调节参数和重启概率的随机游走在链路预测问题上的应用,在各个网络中找出最佳的度偏向调节参数和重启概率,使预测精度有进一步的提升。且链路预测中对网络随机游走过程有影响的因素不止节点度值,那么在能提高预测精度的前提下,可进一步探究出还有哪些因素影响随机游走过程。
