基于深度学习特征的图像检索方法
2018-03-16任夏荔陈光喜曹建收蔡天任
任夏荔,陈光喜,曹建收,蔡天任
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
0 引 言
基于内容的图像检索(content-based image retrieval,CBIR)是指,在给定查询图像的前提下,无需人工对图像进行注释,依据图像本身包含的像素信息、颜色、纹理、形状、空间关系等客观视觉特征,在图像数据库中搜索并查找出符合查询条件的相应图像。其中最基本的问题之一就是如何实现对图像的有效表达,正因为如此,关于特征的提取和表达一直得到了广泛关注。传统的特征表示往往需要根据先验知识手工来提取,工作量大,效果不尽人意,同时也不符合智能化的要求。出现以上结果的一个关键原因在于可被计算机识别的低水平的图像像素和人类感知的高水平语义概念之间存在语义鸿沟。如何缩小甚至跨越这一鸿沟,便成为了当前特征表示的研究重点。Hinton等[1]采用深度学习赢得了ImageNet图像分类的比赛,验证了深度学习特征是比传统的人工特征更具优势的特征表示方法。如今,基于深度学习的特征表示在很多方面都有广泛的应用,具有代表性的包括声音、文本信息的处理[2-4],以及图像分类[1]、图像识别[5,6]、目标检测[7-10]。
在图像处理领域,被广泛使用的基于深度学习的特征是通过卷积神经网络(convolutional neural network,CNN)提取的,CNN的设计是受大脑工作模式的启发,将多个神经元组织成一层层的神经网络,通过组合低层单一的特征形成抽象的高层特征,模仿人脑的机制来解释数据。通过CNN提取的图像特征往往高达几千维,而且其中一些特征之间存在高度的相关性。
本文针对CNN特征的这一特点,采用一种特殊的方式——主成分分析(principal components analysis,PCA)来处理提取的CNN特征。PCA主要用于数据的降维,但它并不是盲目删除一部分特征,而是通过组合那些存在相关性的特征来达到降维的目的,即在减少图像特征数量的同时,尽量降低信息的损失;然后,对经过主成分分析后的特征进行哈希编码,通过比较目标图像编码与图像库中图像编码的海明距离,判断两幅图像是否相似,从而实现图像检索。通过实验,在一定程度上说明了采用本文的方法,比直接使用所有特征进行编码检索,其检索性能更好。
1 相关工作
近些年来,在计算机视觉领域,人们使用人工特征提取的方式,例如SIFT、HOG,作为特征提取的主流方法,取得了一定的成果,但其效果依然不能令人满意。在2012年ImageNet比赛中,Krizhevsky等[1]用CNN将120万张带标签的图片进行分类,且取得了很高的准确率,获得了当年的冠军。从此以后,基于CNN的研究进行得如火如荼。
CNN对图像中的目标检测也带来了大幅度的提升,目标检测需要确定每个物体的位置和类别。被广泛采用的基于深度学习物体检测流程是在RCNN[10]中提出的。首先采
用selective search的方法提出候选区域,利用深度卷积网络从候选区域取特征,然后利用支持向量机等线性分类器进行分类。structObj+FGS[8]是着重于准确定位方面的研究,两个改进之处相互补充,mAP在原来的基础上有了更进一步的提升。
在图像理解方面,CNN也被广泛使用。Oriol Vinyals等[11]提出一种基于CNN并结合计算机视觉和机器翻译的方法生成可以描述图像的句子。Andrej Karpathy等[12]采用一种RCNN的方法,即对图像的局部提取CNN特征,生成局部的描述词,最终根据一定的规则,将词汇合成句子。
在图像检索中,Kongkai Xia等[13]提出了一种可以同时学习图像特征表示和哈希函数的监督哈希方法,该方法首先将成对的语义相似度矩阵因式分解成近似哈希编码,然后使用近似哈希编码以及图像标签来训练深度卷积神经网络,取得了不错的性能。然而,由于采取了矩阵分解算法,当数据量很大时,会消耗大量的存储和计算时间。Kevin Lin等[14]通过增加一个隐藏层来同时学习图像特征和哈希编码,在数据集MNIST和CIFAR-10上取得了很好的检索性能。
2 研究方法
本文结合基于深度学习的特征提取方法,主成分分析方法和哈希方法,综合三者优势,提出了基于深度学习特征的主成分分析的图像检索方法,模型如图1所示。

图1 本文方法模型
将224×224大小的图片输入CNN网络,经过卷积层和全连接层,训练、提取出4096维的特征向量。由于高维度的特征要占用较大的存储空间,与此同时,后续的步骤中计算两张图片的相似度时也会花费较多的时间,并且,我们发现,4096维的特征存在冗余。基于以上3点,我们利用PCA方法,将线性相关的特征进行组合,降低特征之间的线性相关性,降低特征冗余,同时达到降维的目的,且在减少特征数量的同时,尽可能减少特征携带信息的损失。然后,将经过PCA降维的特征,进行哈希编码,用较短的编码来代表一张图片。
当输入一张要查询的图片,同样将其经过上述一番处理,直至得到哈希编码。然后,用这个编码与图像库里面的图片的哈希编码计算其海明距离,距离越小表明哈希编码越接近,那么可认为这两张图片也越相似。
2.1 基于深度学习的特征提取方法
基于深度学习的特征提取方法是通过卷积神经网络实现的,本文的网络模型结构及参数如图2所示。
本文的使用的CNN-M网络模型是在ILSRC-2012数据集上训练学习得到的。CNN-M网络模型包含5个卷积层(conv1-5),conv1、conv2和conv5后面连接着池化层(pooling),卷积层和池化层都使用了滤波器,因此,为了简化表示,这些池化层被视为卷积层的一部分。最后是3个全连接层(full6-8)。
各层的具体参数见表1。
表1中,卷积层的第一行参数表示卷积滤波器的数量和局部感受野的大小;“st.”表示卷积的步幅,“pad”表示空间填充;LRN[1]表示局部反应正则化;“x2 pooling”表示max-pooling下采样。full6和full7使用dropout[1]方法来调整某些隐含层节点的权重不工作,本网络结构的dro-pout概率为50%。最后的full8是softmax分类器。其中,激活函数使用矫正线性单元(rectification linear unit,ReLU)[1],ReLU可以缩短深度卷积神经网络的训练时间。本文提取的是full7层的4096维特征。

图2 CNN-M网络模型结构

conv1conv2conv3conv496x7x7st.2,pad0LRNx2pooling256x5x5st.2,pad1LRNx2pooling512x3x3st.1,pad1512x3x3st.1,pad1conv5full6full7full8512x3x3st.1,pad1x2pooling4096dropout4096dropout1000softmax
网络的训练过程如下:
首先,从256×256的图片中随机提取224×224的子块作为输入。利用在ILSRC-2012数据集上训练学习得到的CNN-M网络模型进行训练。CNN-M网络模型的训练过程同文献[1]一致:采用随机梯度下降(stochastic gradient descent,SGD)对整个网络的参数进行调整。在训练过程中,各参数的设置如下:输入的图像数量为256,动量为0.9,权重衰减系数为0.0005。对于所有层,激活函数使用矫正线性单元(rectification linear unit,ReLU)[1]。由于整个网络的参数较多,为防止过拟合,在训练过程中,将dropout概率设为0.5,学习速率设置为0.01,而学习率在验证误差停止减小的时候下降10倍。
具体来说,卷积层的主要目的是通过引入卷积运算,使原信号增强,并且降低噪音。根据图像局部相关性的原理,对图像进行下采样,可以减少计算量。引入下采样的作用是为了混淆特征的具体所在位置,只需要知道这个特征的相对位置即可,因为在提取出一个特征后它的具体位置已经不重要了。再者,同一特征映射层的神经元共享权值,从而通过权值共享,使得网络的参数数量大大减少,降低了网络的复杂性。
2.2 主成分分析
PCA是一种非常常用的数据分析方法。PCA算法的思想是:通过线性变换将原始数据变换为一组各维度线性无关的表示。PCA算法用于提取数据的主要特征分量,常被用于高维数据的降维。降维意味着信息的丢失,而PCA利用数据本身存在相关性的特点,在降维的同时将信息的损失尽量降低。利用PCA的这种特性,本文将4096维的CNN特征降维至2048,1024,512,256,128,64,32,16,8个不同维数,来寻求最佳性能。
PCA算法描述[15]:
输入:样本集
D={x1,x2,…,xn}∈Rm×d;低维空间维数d′。
过程:
(1)对所有样本进行中心化
(1)
(2)计算样本的协方差矩阵
∑=XXT
(2)
(3)对协方差矩阵∑做特征值分解;
(4)取最大的d′个特征值所对应的特征向量w1,w2,…,wd′。
输出:投影矩阵
W=(w1,w2,…,wd′)
一般而言,设λ1,λ2,…,λm表示协方差矩阵∑的特征值(按由大到小顺序排列),使得λj为对应于特征向量wj的特征值。那么如果保留前d′个成分,则保留的方差百分比可计算为
(3)
式(3)又称为主成分累计贡献率。
本文中d′=2084,1024,512,256,128,64,32,16=2048,1024,512,256,128,64,32,16。
2.3 哈希方法
哈希方法是一种常用的近似最近邻搜索(approximatenearestneighborsearch,ANNS)方法,它将高维的特征映射到低维空间,随之产生二进制编码,再计算海明距离,这样一来就大幅度的降低了计算代价。为了证明PCA方法的有效性,我们采用3种经典的哈希方法对经过PCA降维的特征进行编码。3种哈希方法分别是:局部敏感哈希(locality-sensitivehashing,LSH)、基于转换不变性核的局部敏感哈希(shift-invariantkernelslocality-sensitivehashing,SKLSH)、密度敏感哈希(densitysensitivehashing,DSH)[16]。
LSH的基本思想是:将原始空间中的相邻的数据点通过相同的映射后,这两个数据点在新的空间中仍然相邻的概率很大,而原始空间中不相邻的数据点映射到新空间后相邻的概率很小。具体过程如下:
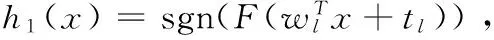
(4)
则L-bits的哈希编码H(x)=[h1(x),h2(x),…,hL(x)]。本文中L=16,32,64,128,256。
SKLSH方法的步骤如下:首先运用
Φw,b(x)
(5)
得到原始数据的随机傅里叶特征,然后,将随机傅里叶特征进行二值量化
Qt(u)sgn(u+t)
(6)
即得到哈希编码。
DSH方法首先通过K均值算法产生各个分组的中心点,基于这些中心点生成r近邻分组,最后,对每一个r近邻分组产生映射和截距,根据哈希映射函数生成最终的哈希编码。
3 实验结果与分析
3.1 数据集
3.1.1Caltech-101
Caltech-101数据集包括总共9038个图像,101类,以及一个另外的背景或遮挡类别。例如家具、车辆、运动器材、动物等,每一类图像的数量最少是31张,最多是800张,示例如图3所示。

图3 Caltech-101示例
3.1.2Caltech-256
Caltech-256数据集比Caltech-101包含的类别更多,由256个普通类和一个背景或遮挡类组成,每类图像至少包含80张图像,共30 607张图像,和Caltech-101不同,由于类与类之间和每类中图像主体位置变化明显,因此关于它的识别更有难度,其示例如图4所示。

图4 Caltech-256示例
实验中,测试集是随机抽取的1000张图像,其余图像作为训练集,10次实验取平均值。
3.2 评估标准
本文使用图像检索中常用的两种评估标准评价实验结果:平均精度均值(meanaverageprecision,MAP)、精度-召回率(precision-recall,P-R)。
MAP是反映检索方法在全部相关图像上性能的单值指标。检索出来的相关图像越靠前,MAP就可能越高。如果结果没有返回相关图像,则MAP默认为0。
精度和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中,精度是检索出的正确信息条数与检索出的信息条数的比率;召回率是检索出的正确信息条数与样本中信息条数的比率。在进行比较时,若一个方法的P-R曲线被另一个方法的P-R曲线完全“包住”,则可断言后者的性能优于前者。
3.3 实验结果
为了寻找相对最优的特征维数,本实验将用CNN提取的4096维特征经过主成分分析产生维数分别为16、32、64、128、256、512、1024、2048的特征。
3.3.1Caltech-101数据集实验结果
Caltech-101数据集的PCA特征维数的累计贡献率及压缩率见表2。其中,压缩率=数据压缩后的大小/压缩前的大小。
经过主成分分析后,将特征值从大到小排列,选择排序靠前的特征值所对应的特征,即主成分贡献率较高的特征。观察表2,发现将原始的4096维特征经过PCA降维至2048维,数据量压缩了50%,而主成分的累计贡献率仍旧高达97.24%。表明,对于此数据集来说,有很大一部分特征携带了较少的信息量,或者说用这部分特征来鉴别图像数据,其贡献并不大。当数据量压缩至25%,特征的主成分累计贡献率为92.16%,仍较高。继续压缩数据至12.5%、6.25%、3.125%、1.56%、0.78%、0.39%。对应的主成分累计贡献率见表2。
下面,针对8种不同PCA特征维数和原始的4096维的特征进行哈希编码。使用3种哈希编码方式均分别得到4种不同长度(32bits、64bits、128bits、256bits)的编码。实验结果如下:
基于MAP评估标准的实验结果如图5所示。(注:每张图的纵轴最高点并不是1,图5(a)~图5(d)分别为0.7、0.8、0.9、0.95)。图5中4096表示没有运用PCA的原始CNN特征。

表2 Caltech-101数据集PCA特征参数

图5 4种不同bits的MAP
综合来看,在3种不同哈希方法及4种不同长度哈希编码的情况下,使用PCA处理后的特征其MAP都有显著提升(DSH编码的MAP提升不稳定),验证了PCA方法的有效性。对比发现,当编码长度为256,哈希方法为LSH,PCA处理后特征尺寸为32和64时,MAP达到最大值91.85%,相对于未经PCA处理256 bits LSH哈希编码的4096维特征其MAP提升了将近7.2%。
图6显示的是MAP值取到最高的PCA-LSH方法的P-R曲线,我们看到,当PCA尺寸为32时,其P-R性能也达到最好。
3.3.2 Caltech-256数据集实验结果
Caltech-256数据集的PCA特征维数的累计贡献率及压缩率见表3。
同Caltech-101数据集一样,经过主成分分析后,将特征值从大到小排列,选择主成分贡献率较高的特征。从表3可以看出,将原始的4096维特征经过PCA降维至2048维,主成分的累计贡献率为95.21%,数据量却压缩了50%。可以得出同样的结论:对于此数据集来说,有很大一部分特征携带了较少的信息量,或者说用这部分特征来鉴别图像数据,其贡献并不大。
对比两个数据集上的实验结果,在数据量同样压缩了50%的情况下,Caltech-101数据集的主成分累计贡献率为97.24%,而Caltech-256数据集为95.21%,这是由于后者包含更多的图像数据,需要相对较多的特征来区分彼此。对比压缩率为25%、12.5%、6.25%、3.125%、1.56%、0.78%、0.39%的情况,均发现此规律。
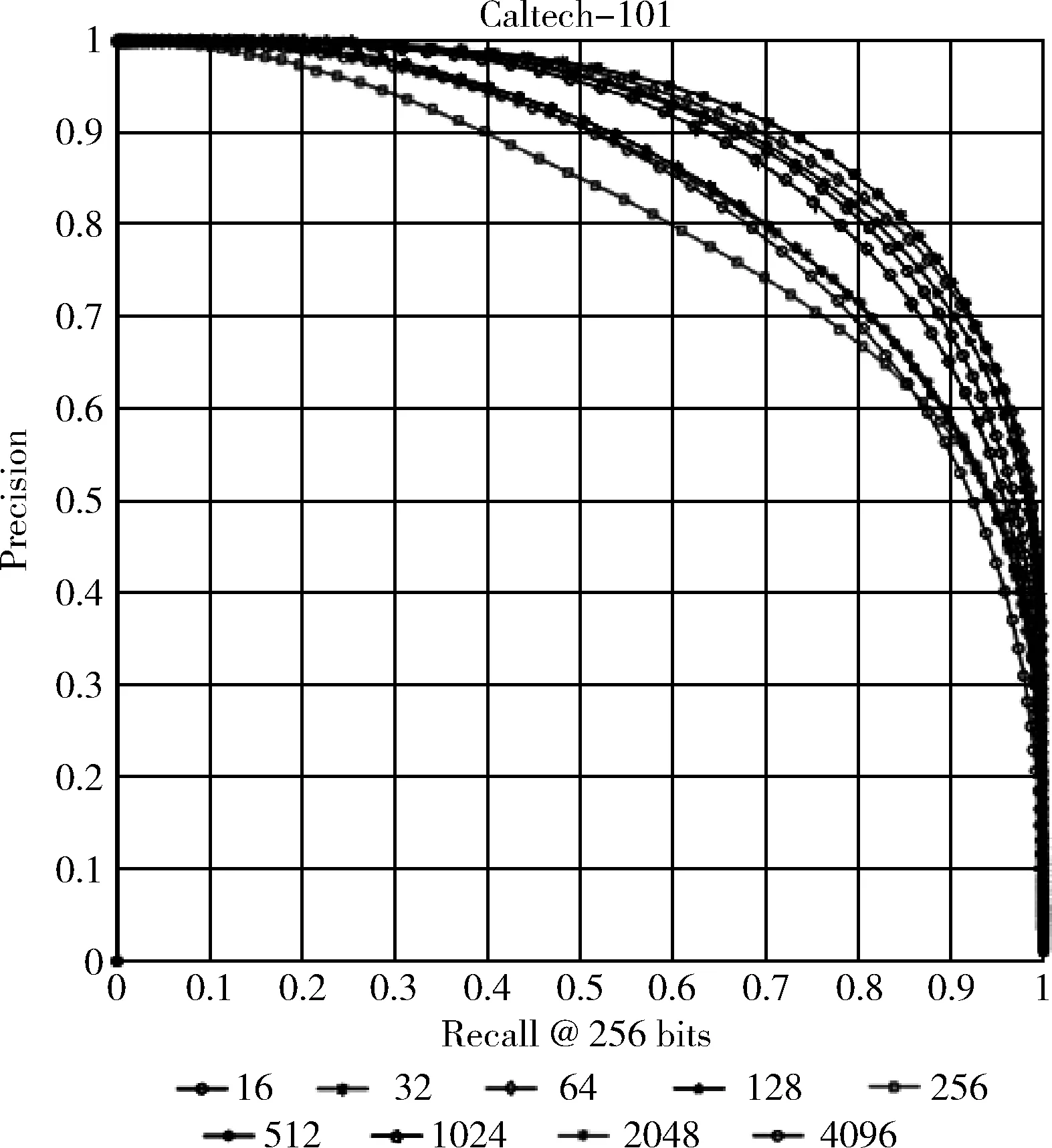
图6 256bits P-R
下面,同样针对8种不同PCA特征维数和原始的4096维的特征进行哈希编码。使用3种哈希编码方式均分别得到4种不同长度(32 bits、64 bits、128 bits、25 6 bits)的编码。

表3 Caltech-256数据集PCA特征参数
基于MAP评估标准的实验结果如图7所示。(注:每张图的纵轴最高点并不是1,图7(a)~图7(d)分别为0.3、0.6、0.7、0.9)。同数据集Caltech-101一样,图7中4096表示没有运用PCA的原始CNN特征。
从4种不同长度编码的结果来看,在更复杂的Caltech-256数据集上,使用PCA处理后的特征其MAP也有明显的提升,同样验证了PCA方法的有效性。其中,采用PCA-LSH方法得到的256 bits哈希编码获得了最高的MAP值82.74%(PCA尺寸为64)和82.82%(PCA尺寸为128)。
图8显示的是MAP值取到最高的PCA-LSH方法的P-R曲线,我们看到,当PCA尺寸为64时,其P-R性能也达到最好。而不使用PCA处理的4096维特征的P-R性能相对来说是最坏的。
从两个数据集的实验结果发现,在4种不同编码长度下,用经过主成分分析的特征进行哈希编码后再进行检索,比直接使用原始的4096维高维特征进行检索,其MAP都有所提高。
我们还发现,数据集Caltech-101,在编码长度为256,哈希方法为LSH,PCA处理后特征尺寸为32和64时,MAP达到最大值,而包含图片数量更多的Caltech-256数据集,在编码长度为256,哈希方法为LSH,PCA处理后特征尺寸为64时,MAP和P-R性能达到最好。这是由于包含图片数量更多的数据集需要更多的特征来区分彼此。
从实验结果可以看出,对于一个数据集,有很大一部分特征携带了较少的信息量。基于深度学习特征的图像检索只需用一定数量的相对主要的特征分量进行编码,就可以达到甚至超过使用全部特征编码的效果。特征分量的大幅度减少减轻了存储的压力,尤其在如今的大数据时代,与此同时,检索效率也会有相应的提升。

图7 4种不同bits的MAP

图8 256 bits P-R
4 结束语
通过将常用于原始数据处理的PCA方法应用于高维度的CNN特征的处理上,并对处理后的特征进行哈希编码,然后做图像检索,实验结果表明该方法的确有效。采用PCA方法合并具有高度相关性的特征,在保证信息损失最低的情况下,达到特征降维的效果,取得了不错的结果。分析实验结果发现,高维度的CNN特征存在数据冗余的可能。对提取的高维度特征做主成分分析,不仅适用于图像检索领域,图像分类、识别以及检测同样适用。我们未来的工作将进一步研究特征维数与数据集复杂程度的内在联系,并尝试做一些理论上的推导工作。
[1]Krizhevsky A,Sutskever I,Hinton GE.ImageNet classification with deep convolutional neural networks[J].Advances in Neural Information Processing Systems,2012,25(2):2012.
[2]Sarikaya R,Hinton GE,Deoras A.Application of deep belief networks for natural language understanding[J].IEEE/ACM Transactions on Audio Speech & Language Processing,2014,22(4):778-784.
[3]Yu D,Seltzer ML,Li J,et al.Feature learning in deep neural networks-a study on speech recognition tasks[C]//Computer Science,2013.
[4]Graves A,Mohamed A,Hinton GE.Speech recognition with deep recurrent neural networks[C]//IEEE International Conference on Acoustic Speech and Signal Processing,2013:6645-6649.
[5]He K,Zhang X,Ren S,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Tran-sactions on Pattern Analysis & Machine Intelligence,2015,8691(1):1904-1916.
[6]Uijlings JRR,Sande KEA,Gevers T,et al.Selective search for object recognition[J].International Journal of Computer Vision,2013,104(2):154-171.
[7]Zhang Y,Sohn K,Villegas R,et al.Improving object detection with deep convolutional networks via Bayesian optimization and structured prediction[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2015:249-258.
[8]Gong Yunchao,Wang Liwei,Guo Ruiqi,et al.Multi-scale orderless pooling of deep convolutional activation features[G].LNCS 8695:European Conference on Computer Vision.Springer International Publishing,2014:392-407.
[9]Maxime Oquab,Leon Bottou,Ivan Laptev,et al.Learning and transferring mid-level image representations using convolutional neural networks[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2014:1717-1724.
[10]Girshick R,Donahue J,Darrell T,et al.Rich feature hie-rarchies for accurate object detection and semantic segmentation[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2014:580-587.
[11]Oriol Vinyals,Alexander Toshev,Samy Bengio,et al.Show and tell:A neural image caption generator[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2015:3156-3164.
[12]Andrej Karpathy,Li Fei-Fei.Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2015:3128-3137.
[13]Xia Rongkai,Pan Yan,Lai Hanjiang,et al.Supervised hashing for image retrieval via image representation learning[C]//Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence,2014:2156-2162.
[14]Kevin Lin,Huei-Fang Yang,Jen-Hao Hsiao,et al.Deep lear-ning of binary hash codes for fast image retrieval[C]//Computer Vision and Pattern Recognition.USA,2015:27-35.
[15]ZHOU Zhihua.Machine learning[M].Beijing:Tsinghua University Press,2016:229-232(in Chinese).[周志华.机器学习[M].北京:清华大学出版社,2016:229-232.]
[16]Lin Yue,Cai Deng.Density sensitive hashing[J].IEEE Transactions on Cybernetics,2014,44(8):1362-1371.
