特定事件意见领袖挖掘
2018-03-16阙文晖黄永峰
阙文晖,黄永峰,李 星
(清华大学 电子工程系,北京 100084)
0 引 言
意见领袖在信息传播和舆情控制中起着重要作用,吸引了国内外学者的广泛关注,并相应地提出了结合不同互联网内容进行意见领袖挖掘的方法,如微博[1]、论坛[2]、新闻报道[3]、新闻评论[4]等。然而,目前这些方法多集中在通用意见领袖的挖掘上,对于所需要分析的不同的特定事件的适用性并不好,对此本文提出一种采用特定事件相关的新闻文本构建人物关系网络,结合社会网络分析方法挖掘意见领袖的方法。该方法的整体框架如图1所示。不同于微博、论坛回复等显式存在的人物关系网络,本文使用新闻文本的人物共现关系构建人物关系网络,即认为存在共现关系的人物之间存在隐式的互相影响的关系,文献[3]中意见领袖的挖掘工作正是基于此开展。同时,新闻文本内容丰富,表述规范,便于判断和事件的相关程度,和事件相关的新闻文本的数据集较易获取。因此,相比于微博、论坛等更适合特定事件的意见领袖挖掘。基于上述构建的人物关系网络,本文采用改进的LeaderRank算法计算人物的影响力排名,充分考虑相邻人物节点之间关于特定事件的影响强弱信息以及人物节点受非邻居人物节点的影响强弱信息,提高意见领袖识别的准确性。

图1 特定事件意见领袖挖掘框架
1 相关研究
现有意见领袖的挖掘方法主要分为两类:用户属性分析法和社会网络分析法。
用户属性分析法主要基于用户的各种特征属性来衡量用户的影响力,如文献[1]从用户影响力和用户活跃度两个方面考虑构建了微博意见领袖指标体系。同时,使用用户属性结合聚类的方法也被使用于意见领袖的挖掘[5]。但这类方法只考虑了用户自身的属性,并没有使用用户之间的关系信息。
社会网络分析法基于人物关系网络,使用节点在网络中的位置和结构信息,量化节点在网络中的重要性。相比于用户属性分析法,该方法得到了意见领袖挖掘研究者的更多关注。如Bai等[6]指出网络中的意见领袖可以是度最大的节点,通过对其施加影响可以控制网络中信息的传播。Aral等[7]的研究证明意见领袖在网络信息传播中起着核心作用。文献[8-10]将社会网络分析法应用到了多种复杂网络的意见领袖挖掘工作中。此外,大量的衡量节点在网络中传播能力和影响力的其它指标不断被提出用于挖掘网络中的意见领袖[11-13]。
目前,在网络节点影响力排序上,常见的衡量方法有度中心性,介数中心性[14],紧密度中心性[15],局部中心性[16],K-Shell[17],LeaderRank[18]等方法。度中心性方法实现简单,但仅使用了较少的局部信息来衡量节点的重要性,因此其效果并不是很好。介数中心性和紧密度中心性使用了网络的全局信息,效果较好,但是计算复杂度太高。局部中心性在计算复杂度和效果上进行了综合考虑,使用更多的局部信息获得了更好的效果。K-Shell方法能够有效地找到核心的节点集合,但是可能存在多个节点都属于一个集合,集合内节点影响力无法区分。LeaderRank作为一种PageRank[19]的改进算法,在网络中加入ground节点的方式对节点跳转信息进行控制,有效地提高了排序准确性,并且其迭代收敛性较好。Xu等[20]针对LeaderRank算法进行改进,提出加入用户间情感倾向和用户活跃度的改进LeaderRank算法,并通过实验验证了改进算法的准确性和抗干扰能力都得到了提升。但此改进方法仅适用于微博等少数场景,对于其它如新闻文本等场景并不能适用。
本文从特定事件的意见领袖挖掘的需求出发,对Lea-derRank算法进行了改进,加入了人物之间关于特定事件的影响强弱信息,并且在ground节点进行影响力分配的过程中考虑接收节点的邻居节点和二度邻居节点的局部结构信息,来计算人物节点的影响力排名,突出排名靠前的人物节点的区分度,提高意见领袖识别的有效性和准确性。
2 特定事件人物关系网络构建
本文分别实现了使用中文新闻文本和英文新闻文本构建特定事件人物关系网络。中文新闻文本的特定事件人物关系网络构建过程将结合“天津爆炸”事件进行介绍,而英文新闻文本对应的构建过程则将在中文新闻文本的特定事件人物关系网络构建过程的基础上进行补充介绍。
2.1 使用中文新闻文本构建人物关系网络
2.1.1 特定事件相关新闻文本获取
从中文新闻网站爬取一段时间内的大量的新闻文本,然后通过关键词过滤的方式得到和特定事件相关的新闻文本集合。比如“天津爆炸”事件中,我们爬取了大量从2015年8月13日至2015年9月13日内的新闻文本,通过关键词“天津”和“爆炸”对爬取的新闻文本进行过滤,得到1599篇和“天津爆炸”事件相关的新闻文本。
2.1.2 新闻文本和特定事件的相关性计算
考虑到特定事件相关的新闻文本集合中各篇新闻文本和事件的相关性并不相同,我们计算每一篇新闻文本和特定事件的相关度来表征新闻文本和事件相关性的强弱。首先,使用ICTCLAS工具[21]将特定事件相关的新闻文本集合D={D1,D2,…}进行分词,去除停用词后统计词频。取词频排序靠前的VN个词作为特定事件的描述词,构成事件描述向量V={v1,v2,…vVN},其中vi均为对应描述词归一化后的词频。则一篇文档和事件的相关度可以采用以下公式进行计算
(1)
其中,vEp对应事件的描述向量,而vip对应新闻文本Di的表示向量。
2.1.3 新闻文本人名识别及优化
采用ICTCLAS工具对中文新闻文本进行人名识别,但识别结果并不完全准确。为构建更为准确的人物关系网络,我们采用人工校正和规则的方式对人名识别结果进行优化。
人工校正主要是为了解决人名切分错误、人名拼写错误、以人名打头的地名企业名误识为人名等情况。如“天津爆炸”事件中,人名“邵俊强”被切分为“邵俊”,人名“杨刚”错写为“杨钢”,“万科”、“安监”、“黄烟”等识别为人名。
规则主要包括单篇新闻文档中的人名消歧和多篇文档中的人名消歧。单篇新闻文档中的文档消歧我们主要考虑两种情况,一是人物的姓名和名共同出现的情况,如“黄艳荣”和“艳荣”,这种情况我们把姓名和名统一合并到姓名进行处理;二是姓名和“姓+先生”或“姓+女士”同时出现的情况,如“董社轩”和“董先生”,这种情况我们首先找到离“姓+先生”或者“姓+女士”最近的相同姓的姓名,然后合并到对应的姓名。多篇新闻文档中的人名消歧主要是解决人物的姓名和名出现在不同新闻文本中的问题。这种情况我们把姓名和名统一合并到姓名进行处理。
2.1.4 特定事件人物共现关系网络构建
对事件相关的每一篇新闻文本按段落进行人名识别和优化,每个段落对应一个人名序列Sp={name1,name2,…},每篇新闻文本对应一个人名序列的顺序集合Sd={Sp1,Sp2,…}。事件相关的所有新闻文本对应的人名序列集合中的所有人名构成了人物关系网络的节点集合。对于一篇新闻文本中出现的任意两个人名,并不一定存在互相影响的关系,即在人物关系网络中并不是一定存在边。本文考虑人名在文中的位置关系,采用以下两个规则确定人物之间的是否存在影响关系,构建人物关系网络中的边,使得所构建的人物关系网络更为精准。
规则一:给定滑动窗口大小WS,序列Sd中任意WS大小窗口内的人名之间存在边。
规则二:同一个段落内任意两个人名之间存在边。
规则一考虑了新闻文本中出现位置相近的人名之间关系较强,相隔太远的人名之间的关系较弱而忽略置为零。规则二考虑了新闻文本段落的内容聚合性,新闻作者往往会把相关的内容放在一个段落,因此我们认为同一个段落内的人物之间具有较强的影响关系。
每一条边的权值,即由此条边相连的两个人物关于特定事件的互相影响的强弱程度,由边相连的两个人物所共同出现的新闻文本集合决定
(2)
其中,Гi,j表示人物i和j所共同出现的新闻文本集合,R(d)表示新闻文本d和特定事件的相关度。
2.1.5 最大连通子图获取
考虑到实验中采用SI(susceptible-infected)[24]模型进行结果评估,我们从上述构建的网络中获取最大连通子图,作为下文计算人物节点影响力得分的网络。
2.2 使用英文新闻文本构建人物关系网络
使用英文新闻文本构建特定事件人物关系网络的过程和使用中文文本的流程很类似,为避免描述过多重复的内容,以下主要描述两者的不同之处。
在特定事件新闻文本数据的获取上,我们从英文新闻网站进行数据采集。在新闻文本和特定事件相关度的计算上,首先将英文文本的大写字母转换为小写字母,采用空格和标点符号等分隔符对文本进行切分,去除停用词,然后采用Porter Stemmer[22]进行词干提取,之后的计算步骤和中文新闻文本的处理方式类似。人名识别和优化上,英文文本的人名识别我们采用的是Stanford Named Entity Recognizer[23],在优化方面与中文新闻文本的处理方式类似。在网络构建和最大子图获取上与中文新闻文本的处理方式类似,在此不再赘述。
3 改进LeaderRank算法
3.1 LeaderRank算法
LeaderRank算法是Lv等[18]提出的一种PageRank的改进算法。记无向网络为G=
(3)
(4)

3.2 改进LeaderRank算法
Lv等[18]通过实验证明LeaderRank算法相比PageRank算法具有更高的准确性和更强的稳定性。但是在特定事件的意见领袖挖掘中,构建的人物关系网络中人物之间影响强弱不同,或是某一人物节点受非相邻人物节点的影响各不相同,都会影响意见领袖排名的准确性,而LeaderRank算法会受到这两方面因素的影响。因此,改进的LeaderRank算法对上述两方面因素进行了考察优化。
3.2.1 人物之间关于特定事件的影响强弱
在人物关系网络中,LeaderRank算法认为任意两个人物节点之间的影响关系强弱是相同的,即网络中所有边的权值相同,人物节点的影响力在传播过程中是均匀地向邻居节点传播的。LeaderRank算法没有考虑到人物之间关于特定事件的影响关系强弱是各不相同的,影响关系强的人物之间受到彼此的影响更强,而关系弱的人物之间受到彼此的影响更弱。针对上述问题,改进的LeaderRank算法加入了人物关系网路中人物之间关于特定事件的影响强弱信息,具体体现在考虑了网路中边的权值信息。网络中任意两个普通节点之间的权值如式(2)所述。
3.2.2 人物节点受非邻居人物节点的影响
人物关系网络中,人物节点不仅受到邻居节点的影响,还受到非邻居节点影响,表现在PageRank算法中是一个用户访问一个网页时,除了可以通过点击节点网页中的链接跳转到其它网页外,还会以一个跳转概率c通过地址栏随机跳转到其它网页。对应到LeaderRank算法中,一个节点收到的影响不仅来自其邻居节点,还来自其它非邻居节点,而非邻居节点的影响力是通过ground节点传递实现的。但是LeaderRank算法认为某一节点受到非邻居节点的影响强弱相同,没有考虑到影响力强的节点相比于影响力弱的节点对其非邻居节点的具有更强的影响力。针对上述问题,改进的LeaderRank算法加入了人物节点受到非邻居节点的影响强弱信息。从节点的局部结构信息出发,考虑两个因素:节点的邻居节点局部结构信息和节点的二度邻居节点局部结构信息。如果一个节点的邻居节点的加权信息和二度邻居节点的加权信息越丰富,则这个节点对其非邻居节点产生的影响越大。之所以考虑二度邻居节点局部结构信息,是为了能够更多地使用节点的局部结构信息,避免将一些邻居节点较多但又不是真正位于网络核心位置的节点识别为重要节点,如图2所示,节点14的邻居节点较多,但是其二度邻居节点很少,并不处于网络的核心位置,因此不能将其识别为重要节点。具体改进体现在对LeaderRank算法中ground节点到普通节点的边的权值ωgi进行了优化,即
ωgi=α·WDi+(1-α)∑j∈ΓiWDj
(5)
其中,WDi=∑j∈Гiωij,Гi表示节点i的所有相邻普通节点的个数,α是一个取值于[0,1]的一个可调参数。
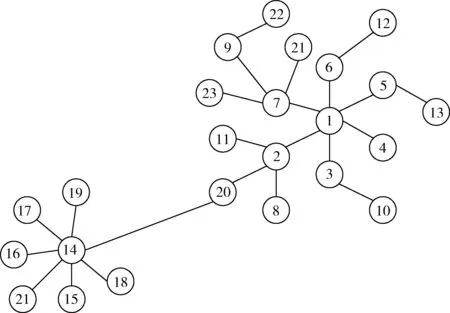
图2 网络节点影响力分析样例
3.2.3 算法的改进
从上述的人物之间关于特定事件的影响强弱和人物节点受非邻居人物节点的影响两个因素出发,对LeaderRank算法进行改进,改进的LeaderRank算法核心公式如式(6)、式(7)所示
(6)
(7)
其中,ωji的取值规则为:若j为ground节点,则ωgi=1/SZi·∑j∈Гiωij,其中ωij表示任意一对普通节点的边的权重,Гi表示节点i的所有相邻普通节点,SZi表示Гi集合的大小,ωgi如式(5)所述;若j为普通节点,则ωgi如式(2)所述;其它变量含义同式(3)、式(4)。
4 实验结果及分析
4.1 实验数据
为验证文本提出的方法,我们在两个数据集上进行了实验。一个是“天津爆炸”数据集。我们采集了2015年8月13日至2015年9月13日之间大量的中文新闻文本,通过关键词过滤得到和“天津爆炸“事件相关的新闻文本1599篇,以此数据集构建“天津爆炸”事件的人物关系网络,记为PCNTEE。另一个是“巴黎袭击”数据集。我们采集了2015年11月13日至2015年12月3日之间大量的英文新闻文本,通过关键词过滤得到和“巴黎袭击“事件相关的新闻文本1083篇,以此数据集构建“巴黎袭击”事件的人物关系网络,记为PCNPAE。两个数据集的基本统计情况如表1所示。其中,N表示网络中节点个数,M为边的个数,节点平均度为

表1 两个真实数据集的基本统计情况
4.2 实验结果
4.2.1 有效性评估
SI模型[24]作为网络节点影响力度量的一种方式被广泛使用。在上述两个数据集上分别采用SI模型计算节点的标准影响力得分。SI模型中,所有节点仅有两种状态:Susceptible(S)和Infected(I)。初始时刻,网络中某一节点置为I状态而其它节点都为S状态。每一次迭代过程中,处于I状态的节点以概率β感染相邻的处于S状态的节点。实验过程中发现,将感染概率设置为0.1时,效果较好。定义F(t)代表时刻t网络中处于I状态的节点个数,随着t的增加,F(t)不断增大,最后收敛到一个稳定的值,此时网络中几乎所有的节点都处于I状态。定义F(tc)作为节点的标准影响力得分,其中tc为使得F(tc)和F(tc)的斜率均较大的某一时刻。对F(tc)重复计算100次取平均,平均值越大,代表此节点影响力越大越可能是意见领袖。根据具体实验情况,天津爆炸实验中,设定tc=9;巴黎袭击实验中,设定tc=10。采用本文提出的改进LeaderRank(local weighted LeaderRank,LWLR)算法,以及度中心性(degree centrality,DC)、介数中心性(betweenness centrality,BC)[14]、紧密度中心性(closeness centrality,CC)[15]、局部中心性(local centrality,LC)[16]、K-Shell(KS)算法[17]、LeaderRank(LR)算法[18]、人物在特定事件相关的新闻文本中被提及次数(Mentions)等各个对比方法计算节点影响力得分。图3和图4为两个数据集上节点标准影响力得分和采用上述方法计算的节点影响力得分的相关性。

图3 “天津爆炸”数据集上8种方法对应的相关性结果

图4 “巴黎袭击”数据集上8种方法对应的相关性结果
从图3中我们观察到,在PCNTEE中,采用DC、BC、KS和Mentions方法得到的排名和采用SI得到的标准影响力排名之间的相关性较差,而CC、LC、LR和LWLR方法相关性较好,并且LWLR取得了最好的相关性,尤其是在影响力得分较低的那部分节点。这是因为LWLR考虑了更多的局部信息,提高了区分得分在中后位置的那部分节点的排名的能力。由图4可知,在PCNPAE中,DC、BC、KS以及Mentions方法和其在PCNTEE中的表现相似,都较差,而LC和LWLR比其它方法的表现都好。可见LC和LWLR方法是本文中所考虑的最好的两种方法。因此,可以说本文提出的LWLR方法可以有效地找到网络中的最具影响力的人物。
为了定量地评估采用各种方法计算得到网络节点影响力得分的准确性,我们采用Kendall’sτ系数进行衡量,其定义详见文献[25]。表2为两个数据集上采用8种方法计算得到的节点影响力排名对应的Kendall’sτ的值。在PCNTEE,我们的方法取得了最好的τ值,即我们的方法得到的节点影响力排名比其它方法的得到的排名要更为接近标准排名。在PCNPAE中,LC方法取得了最好的τ值,但本文方法的τ值很接近LC的τ值,并且比其它方法的τ值要好许多,即本文方法在这个网络中表现也很好。结合两个数据集的实验结果,可知本文方法要比除LC之外的方法都好,并且和LC的效果相当,但是在不同网络中效果要比LC更为稳定。

表2 8种不同方法对应的Kendall’s τ值
4.2.2 Top-L节点影响力排名分析
Kendall’sτ衡量的是所有节点影响力排名的准确性,并不能衡量排名靠前的节点影响力排名的准确性。考虑到意见领袖挖掘中最为重要的是准确获得排名靠前的人物,我们采用一个新的指标——排名靠前的L个节点的影响力得分的平均值,来衡量方法获得的Top-L节点的影响力排名的准确性,记为。在PCNTEE和PCNPAE两个数据集上,我们采用本文提出的方法和对比方法计算其,结果如图5所示。理论上一个效果好的方法,其对应的曲线应该向右下递减。由图5可知,本文方法在整个L区间内比其它方法的效果都好。在4.2.1中的分析可知,LC方法在所有节点的排序上取得了很好的效果。但由图5可知,LC在Top-L节点的排序上效果并不好,原因在于LC考虑了过多的局部信息,而排名靠前的节点之间很可能紧密连接,其局部结构和权重信息可能很类似。通过对比τ值和值,可知本文提出的方法相比于其它方法,能够得到一个更加接近标准影响力排名的节点排序,并且能够更好地识别出排名靠前的重要节点。

图5 两个数据集上8种方法Top-L节点的平均影响力
4.2.3 Top-10节点影响力传播分析
从上述实验结果分析中,可知LWLR方法相比其它方法能够更好的识别出影响力排名靠前的节点。但上述结论仅仅考虑了节点在tc时刻的影响力。为了更好地分析所得到的排名靠前的节点在影响力传播过程中的表现,本文对采用LWLR和采用LR得到的Top-10节点的影响力进行对比分析。选择LR作为对比方法主要考虑到采用LR所得到的Top-10节点相比于其它方法要更为接近LWLR。实验中,首先取LWLR的Top-10节点集合SLWLR,LR Top-10节点集合SLR,再分别将单独出现在SLWLR和SLR中的节点初始化为I(infected)状态,记录传播过程中到达I状态的节点数。重复上述过程100次取平均值。实验中没有使用共同出现在SLWLR和SLR中的节点,因此得到的实验结果更有利于区分两种方法的效果。实验结果如图6所示。从图中可知,在两个数据集上,LWLR对应的曲线整体均在LR对应的曲线上方,并且在整个传播过程中,LWLR的曲线方差都比LR的要小。这表明LWLR识别的Top-10节点具有更强的影响力传播能力,验证了本文方法的确能够有效识别出最具影响力的节点。

图6 LR和LWLR Top-10节点影响力传播过程
5 结束语
针对特定事件的意见领袖挖掘,本文提出了一种采用新闻文本进行意见领袖挖掘的方法。该方法采用新闻文本构建特定事件的人物关系网络,充分考虑了新闻文本与事件的相关度和新闻文本内不同位置人物之间影响关系的强弱。在改进的LeaderRank算法中,加入了人物之间关于特定事件的影响强弱信息,以及人物节点受非邻居人物节点的影响强弱信息,提高了网络中节点影响力度量的准确度和区分度。实验分析结果表明,本文方法能够有效识别特定事件的意见领袖,特别是排名靠前的意见领袖,而且相比LeaderRank等方法具有更好的效果。
[1]LIU Zhiming,LIU Lu.Identification and analysis of opinion leaders in micro-blogging network public opinion[J].Systems Engineering,2011(6):8-16(in Chinese).[刘志明,刘鲁.微博网络舆情中的意见领袖识别及分析[J].系统工程,2011(6):8-16.]
[2]Zhou Xueyan,Yang Jing,Zhang Jianpei,et al.A BBS opi-nion leader mining algorithm based on topic model[J].Journal of Computational Information Systems,2014,10(6):2571-2578.
[3]Jonnalagadda S,Peeler R,Topham P.Discovering opinion leaders for medical topics using news articles[J].Journal of Biomedical Semantics,2012,3(1):1-13.
[4]Song Kaisong,Wang Daling,Feng Shi,et al.Detecting opi-nion leader dynamically in Chinese news comments[M]//Web-Age Information Management.Berlin Heidelberg:Springer,2012:197-209.
[5]WANG Jue,ZENG Jianping,ZHOU Baohua,et al.Online forum opinion leaders discovering method[J].Computer Engineering,2011,37(5):44-46(in Chinese).[王珏,曾剑平,周葆华,等.基于聚类分析的网络论坛意见领袖发现方法[J].计算机工程,2011,37(5):44-46.]
[6]Bai Wenjie,Zhou Tao,Wang Binghong.Immunization of susceptible-infected model on scale-free networks[J].Physica A Statistical Mechanics & Its Applications,2007,384(2):656-662.
[7]Aral S,Walker D.Identifying influential and susceptible members of social networks[J].Science,2012,337(6092):337-341.
[8]Zhou Yanbo,Lyu Linyuan,Li Menghui.Quantifying the influence of scientists and their publications:Distinguish prestige from popularity[J].New Journal of Physics,2012,14(3):33033-33049(17).
[9]Salesses P,Schechtner K,Hidalgo CA.The collaborative image of the city:Mapping the inequality of urban perception[J].Plos One,2013,8(7):e68400.
[10]Hou Bonan,Yao Yiping,Liao Dongsheng.Identifying all-around nodes for spreading dynamics in complex networks[J].Physica A Statistical Mechanics & Its Applications,2012,391(15):4012-4017.
[11]Liu YY,Slotine JJ,Barabási A.Control centrality and hie-rarchical structure in complex networks[J].Plos One,2012,7(9):e44459.
[12]Mui L.Computational models of trust and reputation:Agents,evolutionary games,and social networks[J].Acta Paulista De Enfermagem,2014,20(4):452-457.
[13]Bakó I,Bencsura A,Hermannson K,et al.Hydrogen bond network topology in liquid water and methanol:A graph theory approach[J].Physical Chemistry Chemical Physics,2013,15(36):15163-15171.
[14]Katona Z,Zubcsek PP,Sarvary M.Network effects and personal influences:Diffusion of an online social network[J].Journal of Marketing Research,2013,48(48):425-443.
[15]Csermely P,London A,Wu LY,et al.Structure and dynamics of core/periphery networks[J].Journal of Complex Networks,2013,1(2):93-123.
[16]Chen Duanbing,Lyu Linyuan,Shang Mingsheng,et al.Identifying influential nodes in complex networks[J].Physica A Statistical Mechanics & Its Applications,2012,391(4):1777-1787.
[17]Kitsak M,Gallos LK,Havlin S,et al.Identification of influential spreaders in complex networks[J].Nature Physics,2010,6(11):888-893.
[18]Lyu Linyuan,Zhang Yicheng,Chi Hoyeung,et al.Leaders in social networks,the delicious case[J].Plos One,2011,6(6):e21202.
[20]XU Junming,ZHU Fuxi,LIU Shichao,et al.Identifying opinion leaders by improved algorithm based on LeaderRank[J].Computer Engineering & Applications,2015,51(1):110-114(in Chinese).[徐郡明,朱福喜,刘世超,等.改进LeaderRank算法的意见领袖挖掘[J].计算机工程与应用,2015,51(1):110-114.]
[21]Wang Changbo.SentiView:Sentiment analysis and visualization for internet popular topics[J].IEEE Transactions on Human-Machine Systems,2013,43(43):620-630.
[22]Cao S,Snavely N.Graph-based discriminative learning for location recognition[J].International Journal of Computer Vision,2015,112(2):239-254.
[23]Manning CD,Surdeanu M,Bauer J,et al.The stanford CoreNLP natural language processing toolkit[C]//Meeting of the Association for Computational Linguistics:System Demonstrations. Baltimore,2014.
[24]Sienkiewicz A,Gubiec T,Kutner R,et al.Dynamic structural and topological phase transitions on the Warsaw stock exchange:A phenomenological approach[J].Acta Physica Polonica,2013,123(3):615-620.
[25]Gao Shuai,Ma Jun,Chen Zhumin,et al.Ranking the spreading ability of nodes in complex networks based on local structure[J].Physica A Statistical Mechanics & Its Applications,2014,403(6):130-147.
