敦煌文献多模态语料库建设初探
2018-03-01康宁陈冰云
康宁 陈冰云
[摘 要]基于敦煌文献电子化、数字化所取得的成果,提出将敦煌文献的转录文本和相关图像资料以数字化手段按照统一的标准和格式整合成数据库,即建设包含文献文本数据及相关图像的敦煌文献多模态语料库。据此探讨敦煌文献多模态语料库的设计目标与原则,以及语料库维护、检索和输出多功能系统的开发。该语料库的开发和建设既有利于研究人员从多个角度开展敦煌文献语言文字研究,也可以应用于中古汉语文献的语言教学,帮助学生进行相关的数据驱动学习。
[关键词]敦煌文献;多模态语料库;语料库设计;语料库多功能系统
[中图分类号]TP391 [文献标识码]A [文章编号]1671-8372(2018)04-0110-05
On the construction of multi-modal corpus of Dunhuang literature
KANG Ning1, CHEN Bing-yun2
(1. School of Foreign Languages, Qingdao University of Science and Technology, Qingdao 266061, China; 2. Library, Qingdao University of Science and Technology, Qingdao 266061, China)
Abstract:Based on the electronic and digital achievements of Dunhuang literature, it is proposed to integrate the transcripts and relevant image data of Dunhuang literature into a database by means of digitization in accordance with the unified standard and format, that is to construct a multi-modal corpus of Dunhuang literature, which includes the transcribed texts of Dunhuang literature and the relevant images. And accordingly, the design principles and objectives of the corpus have been discussed, as well as the development of corpus multi-functional system, including corpus maintenance, corpus query and the output of analysis results. The development and construction of this corpus can be used not only in the linguistic study of Dunhuang literature, but also in the teaching of ancient Chinese, by which students can use the corpus data to carry out data-driven study.
Key words:Dunhuang literature; multi-modal corpus; corpus design; corpus multi-functional system
随着计算机科学与技术和多媒体技术的发展,以及人们对语言活动本质的认识不断加深,多模态语料库作为新一代语料库应运而生。多模态语料库包含了经过扫描、转录、加工、标注的文本语料,以及与该文本语料密切相关的图像、音视频等数据文件,建设多模态语料库是为了采用实证的方法,对语言符号与非语言符号之间的相互作用进行系统的研究[1]。严格来讲,多模态语料库已不再是传统意义上的语料库,传统的语料库一般只包含文本语料,而多模态语料库则既包含文本语料又包含与其相关联的多媒体文件。与其说它是语料库(corpus),不如说是数据库(Database)。事实上,许多国外多模态语料库的命名并未采用传统的“语料库”一词,而采用了“数据库”的概念[2]。基于本文是对特定类别的敦煌石窟文献资料的语言文字进行研究,因此仍使用“语料库”一词,旨在对敦煌石窟文獻多模态语料库建设提出一些建议和思考。同时,基于樊锦诗教授提出的“把佛教文献的研究与通过解读石窟图像来研究佛教信仰及思想的学者联合起来,把两个方向研究的成果结合起来,发挥各自的特长和优势”的倡议[3],也希望该敦煌文献多模态语料库的建设能够对此起到一定的推动作用。
一、敦煌文献数据库的建设现状
敦煌文献又称敦煌遗书、敦煌文书、敦煌写本,是对1900年发现于敦煌莫高窟一批书籍的总称。该批文献均为公元2—14世纪的古写本和刻印本,蕴藏着大量的政治、经济、文学、语言、音乐、舞蹈、宗教、民俗、军事、科技以及中西交通等方面的信息,总数6万余卷,目前由于历史原因散落在世界各地。敦煌遗书兼具文物、文献、文字三方面的研究价值,蕴藏的研究信息量极为庞大[4],是研究我国中古时期社会全貌不可多得的一手资料。因此敦煌文献数据库建设一直以来受到国内外学者、研究机构及国际组织的高度重视,特别是进入信息化时代以来,数字技术得到快速发展,建设高质量的敦煌文献数据库成为可能,并且发展迅速。
韩春平教授将当前涉及敦煌文献的数据库分为三种:单一型、复合型和智能型。单一型数据库建设的时间较早,建成的数量较多,一般为目录库、影像库或录文库,如上海师范大学方广锠教授个人创建的“诸经起讫”“英国敦煌遗书人名索引”,台湾成功大学创建的《老子化胡经》等特定敦煌文献全文录文数据库,以及兰州大学青年教师创建的“敦煌文献中的佛教人物数据库系统”等。单一型数据库规模较小,结构简单,功能较少,一般为个人研究者开发。复合型数据库规模较大,数据类型多样,结构复杂,功能大幅增多。最早的复合型数据库被认为是“国际敦煌项目”(IDP)专属数据库[5]。国际敦煌项目(IDP)创立于1994年,是一个国际合作组织,其目的在于在联合各国共同建立网上数据库,以促进敦煌文献资料和藏品的保护与研究。该项目由英国国家图书馆主持,中国、俄罗斯、法国、德国等国家图书馆和科研机构共同参与。目前该数据库收录了5万余件中亚刻本和印本以及3万余件中国国家图书馆馆藏敦煌文献资源数据。用户可以登录中国国家图书馆的IDP主页和英国国家图书馆IDP主页,输入题名、关键词等信息进行检索查看。兰州大学约于2000年推出综合型敦煌学资料数据库“敦煌学数字图书馆”,其中的敦煌文献子库由文献目录和影像两部分构成,入库数据包括国家图书馆的馆藏敦煌文献、甘肃省内藏品,以及英国、法国的部分藏品。
由陕西师范大学主持创建、陕西师范大学出版总社出版运营的“敦煌文献库”于2016年8月正式上线,该库是《汉籍数字图书馆》2.0版专库之一,内含两个子库,即目录库和图版库。目前已收录7万余条敦煌文献,50多万个图版。该库最显著的特色是图版清晰,有的彩色图版能够充分展现敦煌文献的原貌,为研究者提供详尽的文献信息。不足之处是目录库的信息过于简略,且由于没有文献的录文,不能进行全文检索,从而限制了文献的利用价值。
智能型数据库的代表成果当属北京爱如生数字化技术研究中心研制的“敦煌文献库”。该库由北京大学教授刘俊文总纂,收录了中国大陆和台湾地区以及英、法、俄、德、日等国收藏的敦煌汉文文献30000余件,分为佛书编(佛教经卷)、遗书编(经史子集四部典籍写本)、文书编(官文书、私文书及寺院文书残卷),以及根据原件照片或影本制成的高精度数码影像。该数据库配备了强大的检索系统和完备的功能平台,图文对照逐行可勘,而且可以进行全文检索。该库于2006年启动,计划分5集上线,初集包含四部经籍写本、官私和寺院文书,共2882件,已于2009年上线;2—5集为佛经写本,共27000件,定于2020—2025年上线。此外,在2012年,由敦煌研究院和上海师范大学共同申报的国家社科基金重大招标项目—“敦煌遗书数据库建设”中标。敦煌研究院项目组联合浙江大学和兰州大学,重点集成和优化各种类型的数据。该数据库建设的目标是向用户提供高质量的敦煌文献的全文录文,实现用户与文献的高清图版进行对照阅读,同时提供详细的目录数据和大量的相关研究的文献数据。上海师范大学的项目组旨在打造高端学术平台,从文物、文献、文字三个层面采集所有敦煌文献的各种知识点,从不同角度展示平台内在的网状知识结构。数据库的第一期工程已经完成。
综上可见,敦煌文献数据库的建设随着计算机技术和数字化技术的发展而方兴未艾,但已取得了显著的成绩,在文献保护和研究方面做出了巨大贡献。但通过调研也发现,敦煌数据库的建设尚缺乏系统理论语言学原则指导下建立的、面向敦煌文献语言文字研究而创建的深加工研究型语料库。现有的敦煌文献电子化、数字化工作取得的显著成果,为建设这种深加工多模态语料库提供了有利条件。
二、敦煌文献多模态语料库的设计目标与原则
敦煌文獻出自于莫高窟,大部分为东晋至北宋初年的写本,也包含少量的刻印本。写本以汉文为主,也有以古代少数民族文字和西域文字如吐蕃文、回鹘文、于阗文、龟兹文、梵文等写成的文本。因此敦煌文献除了具有极高的史料价值外,还具有极为丰富的语言学价值。
敦煌文献多模态语料库的根本目标是通过服务于敦煌文献语言文字的研究,促进中古汉语①的语音、词汇、语法、句法、方言学、语用学及社会语言学方面的研究。因此,敦煌文献多模态语料库的建设目标包括:
1.语料库能够提供典型、有代表性并且经过权威校勘的敦煌文献纯文本语料,从而为中古汉语的语言学研究提供真实鲜活的语言实例。
2.语料库能够提供与敦煌文献纯文本语料相对应的全文影像,便于研究者实时对照开展研究。通过使用扫描仪将入库文献扫描成图像,使研究者在研究过程中可以快速定位到文献的原版图像,实现文本与图像合二为一。
3.语料库中的语料数据经过元信息(包括文献编目、馆藏地、成书年代等)标记、切词、词性与句法标注等精细加工处理,提高研究的深度和广度。
4.编制语料库多功能检索系统,能够根据研究目的导入所需要的文本语料和相应图像,按元数据标记信息和词性标注信息进行全文检索,并能够输出统计和分析结果。
敦煌文献可以用“浩如烟海”来形容,佛教文献约占90%,涉及经、律、论;非佛教文献涵盖面更广,涉及经、史、子、集和大量的官私文书等。要想实现上述目标确实存在相当大的难度,需要敦煌石窟文献研究专家、中古汉语研究专家、语料库语言学专家、计算语言学专家等各方面的共同努力。因此,在开发建设敦煌文献多模态语料库时应遵循以下原则:
1.语料库的设计和建设必须在现代语言学理论的指导下进行,尤其是要充分利用语料库语言学方面的最新理论和前沿技术。近年来,国外语料库语言学理论和技术都得到了长足发展,这些都为本项目的顺利实施奠定了一定的基础。国内也相继建成了多个中古汉语文献语料库,如“中古汉语研究型语料库”[6]、《论语》与其注疏文献对齐语料库[7]、“汉语史语料库”[8]等,这些语料库的建成为敦煌文献多模态语料库建设提供了宝贵的经验。
2.入库文献的选择必须遵循完整性原则。不采用传统语料库建设中随机择句或择段的方式选择语料,不论文献长短都进行全文收录,确保古籍文献的全貌;不要求语料库规模和入库语料追求“大而全”,反对不加选择地简单堆砌罗列所有文献。
3.入库文献必须准确,努力做到文献“保真”。首先,入库文献须是经过权威校勘过的文献,例如《敦煌社邑文书辑校》[9]、《敦煌契约文书辑校》[10]等。其次,入库文献须配有相对应的高清图像,便于研究者随时比对。由于敦煌文献大多为写本,年代久远,转录时会遇到异体字、生僻字、俗体字等特殊情况,高清图像可以帮助研究者进行辨识和分析,而这也正是本项目的优势所在。
4.语料库设计须遵循开放性原则。敦煌文献多模态语料库应该是一个开放的资源平台,它可以与其他系统、软件关联和配合,并可由其他软件对其进行修改、升级、组装[6]4-5。因此应采用国际统一的编码体系和通用置标语言。
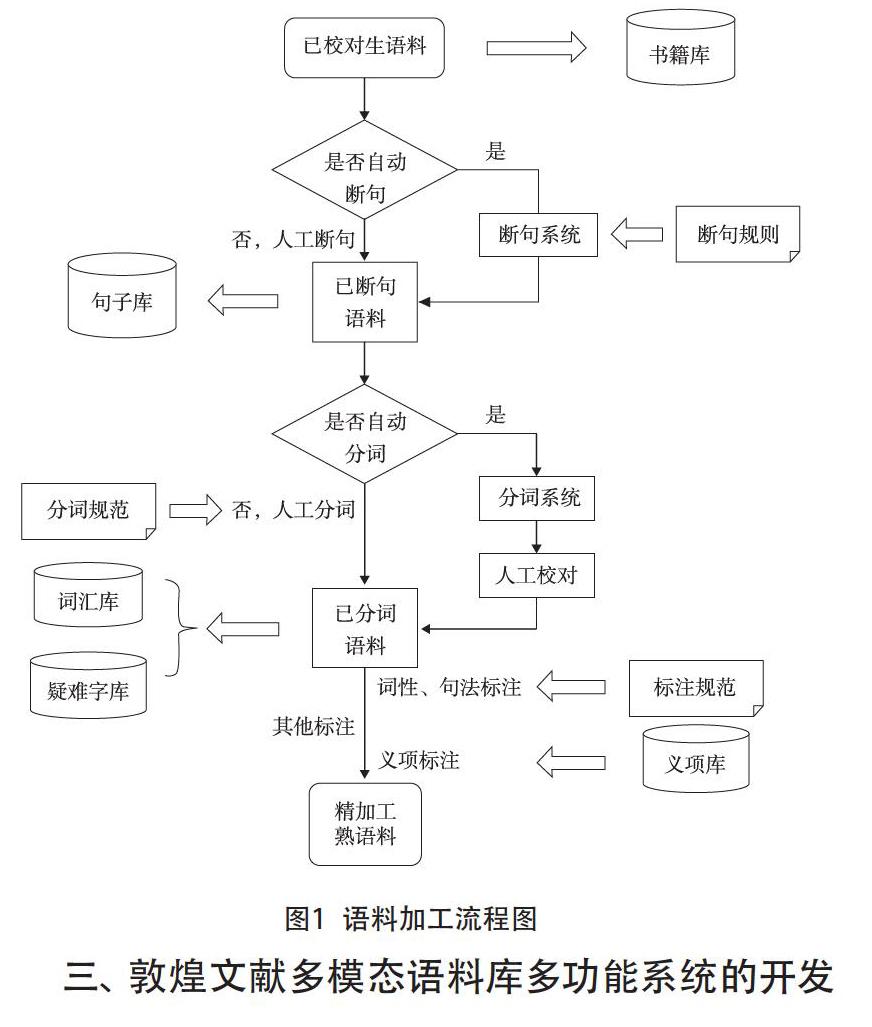
5.入库语料必须经过深加工处理。由于当前建立的中古汉语语料库多没有进行分词、标注等深层加工,所以语料库的整体使用价值难以充分体现。为使敦煌文献的研究走向纵深,建设深加工的敦煌文献语料库十分必要。在这方面,我们可以参考南京师范大学承担的国家社科基金重大课题“汉语史语料库建设研究”所构建的“信息处理用中古汉语分词规范”的整体框架[11],详见图1[12]21。
三、敦煌文献多模态语料库多功能系统的开发
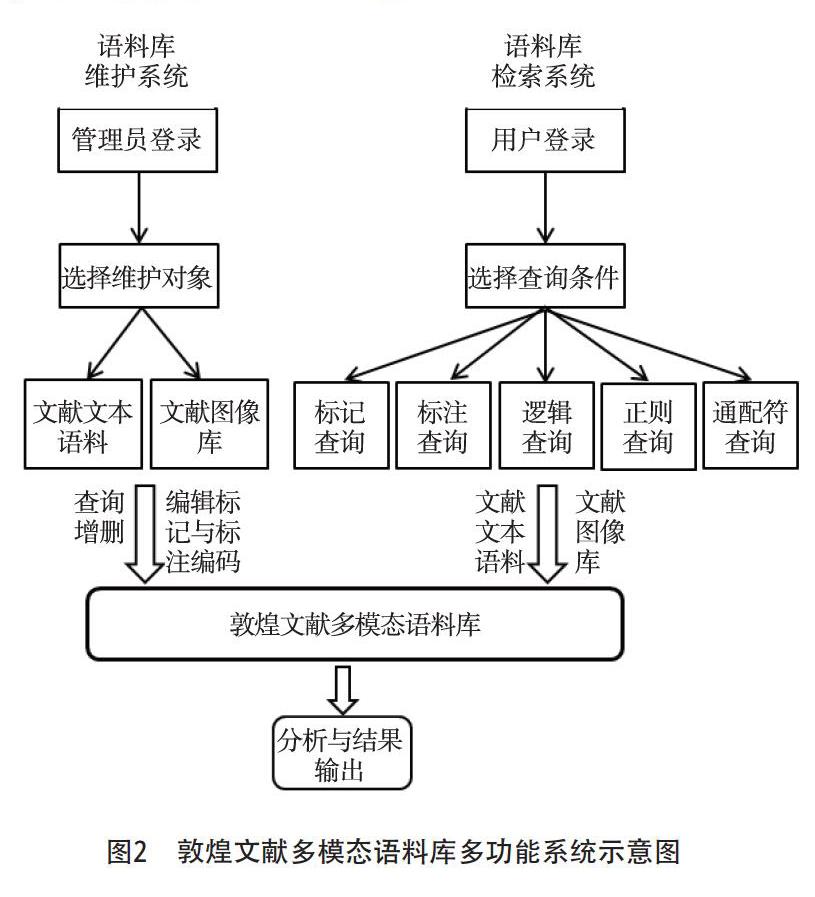
本文所倡导建立的敦煌文献多模态语料库并非单纯文本和图像的集合,我们还将开发该语料库的检索、维护和管理多功能系统,使其具备良好的存储、反馈、修正、检索、统计、分析、结果输出等性能,以便各领域研究人员都能从语料库中获取自己所需要的信息。其主要功能如图 2[12]24所示。
多功能系统主要由三个模块组成:语料库维护、语料库检索、分析与结果输出。
(一)语料库维护系统
维护系统是面向管理员(通常是语料库建设团队的技术人员,也可以是具有一定语料库技术水平的用户,即科研人员)的系统,以便于维护和管理整个语料库的内容。主要功能有文献文本和图像的查询、增删,文献和图像元信息及语法标注的编辑等。此外,该语料库维护系统还拟实现对敦煌文献文本语料的部分自动勘校功能。由于语料库创建时遵循开放性原则,从而增强了该语料库的数据维护性。用户在使用检索系统和输出系统时,可将其使用体验反馈给语料库管理员,以实现语料库的即时维护和管理。
(二)语料库检索系统
检索系统是面向各领域研究者(语料库的最终用户)的系统,是为了研究者能顺利访问语料库内容,对其感兴趣的语言现象进行分析研究。为发挥语料库的应有价值,不管什么类型的语料库都必须实现全文检索,语料库检索功能越完备,语料库的价值也就越高。多样化的查询条件能够提升检索系统的使用体验。敦煌文献多模态语料库的检索系统具有五种主要的查询方式(见图2):。
1.按元信息标记查询。查询条件为预设的文献文本和图像的元信息编码。
2.按语法标注信息查询。查询条件为预设的词性、语义等语法信息编码。
3.按逻辑查询。查询条件可选择“和”“或” “是”“否”等逻辑语句,对元信息编码和语法标注信息编码进行组合查询。
4.按正则表达式(regex)查询。这是目前大多数语料库检索系统都支持的检索方式,具有非常强的灵活性、逻辑性和功能性。
5.按通配符(wildcard)查询。这是一种基于词的底层模糊查询,可结合正则查询使用,使用户快速定位自己感兴趣的语言信息。
(三)分析与结果输出系统
分析与结果输出系统也是面向语料库用户的系统,能帮助研究人员统计分析检索结果,并能够将结果输出到单独文件,保存备用。敦煌文献多模态语料库系统可将输出结果以网页形式(HTML)加以呈现,并可保存为文本格式。
四、敦煌文献多模态语料库的应用展望
时至今日,围绕敦煌石窟和出土遗书的敦煌学研究早已发展成为一门国际性的显学。经过演变发展,敦煌学的研究范围和内容已经拓展到五个分支领域:敦煌石窟考古、敦煌石窟文物保护、敦煌艺术(敦煌彩塑、壁画、书法、音乐、舞蹈和建筑艺术等)、出土敦煌文献(各种写本和刻印本)和敦煌学理论。其中敦煌文献的研究领域最大,涉及天文、地理、政治、哲学、宗教、文学、语言、文字、艺术等诸多方面,其研究方法多样,成果也最多。敦煌文献时间跨度较长、覆盖领域广,蕴含了丰富的知识内容,以往对敦煌文献语言学方面的研究多基于文本细读这种古籍利用方法,对文献中知识内容的理解有较为深刻的把握。若能借助语料库语言学的方法与技术,则可以将文献所蕴含的各种语言知识与使用规律变得更加清晰、直观。然而,基于语料库方法的研究尚不多见。
本文倡导建立的敦煌文献多模态语料库可通过服务于敦煌文献语言文字的研究,来促进中古汉语的语音、词汇、语法、句法、方言学、语用学及社会语言学方面的研究。
首先,由于入库文献的转录文本和实物图像都经过精加工处理,并支持多种检索方式,所以研究人员可以利用检索结果进行多角度的语言学研究。例如对文献中典型的句法、特定词汇的研究,对不同类别文献、不同时期文献或不同作者文献的语言风格进行对比研究等。
其次,该语料库在中古汉语文献的语言教学方面也可以发挥作用。譬如,教师可以利用语料库向学生展示某些特定语法范畴、词汇在敦煌文献中的使用实例,而学生也可以利用该语料库进行数据驱动学习,因为语料库本身就是一个真实的语境。
再次,有學者设想能将古籍语料库中耗时、耗力的校勘工作,对比语料库中的字、词汇及语法等对古籍文献进行部分辑校[13],提高古籍文献的校勘效率。这个想法有实现的可能。敦煌文献多模态语料库维护系统的开发设计中已考虑这一功能,但技术上需要计算语言学技术、计算机技术,甚至人工智能技术的支持。
五、结语
中古汉语语料库的建设在我国大陆及港台地区都积累了不少经验,古汉分词规范得到进一步细化,分词一致性和自动分词的正确率也在逐步提高,尤其在中古时期专书、词汇、语法等方面的研究产生了一批优秀成果。然而由转录文本与相应的高清影像集合而成的多模态语料库尚不多见,这种语料库无疑对于研究中国古籍文献具有更重要的意义。本文尝试探讨建设敦煌文献多模态语料库,开发语料库检索、维护系统,可以预见在建库和开发过程中,还有很多技术上以及对文献本身理解上的难题需要克服。但随着计算机、计算语言学、语料库语言学、语言智能等方面技术的不断发展,加上各方面专家的共同努力,一定能够建成一个数据完整、图文对照、检索功能完善的多模态敦煌文献语料库。
[参考文献]
[1]Valentini C. Forlixt 1 - The Forlì corpus of screen translation: exploring microstructures [M]// Chiaro D, Heiss C, Bucaria C. Between Text and Image: Updating Research in Screen Translation. Amsterdam/Philadelphia: John Benjamins, 2008: 37-50.
[2]刘剑.国外多模态语料库建设及相关研究述评[J].外语教学,2017(4):40-45.
[3]樊锦诗.关于敦煌石窟研究的一些思考[J].中国史研究,2009(3):91-94.
[4]方广锠,朱雷.谈敦煌遗书数据库[J].敦煌研究,2010(5):119-124
[5]韩春平.敦煌遗书数字化演进史[N].中国社会科学报,2017-06-28(007).
[6]董志翘.为中古汉语研究夯实基础—“中古汉语研究型语料库”建设琐议[J].燕山大学学报(哲学社会科学版),2011(1):1-6.
[7]马创新,陈小荷.基于XML的《论语》与其注疏文献对齐语料库的知识表示[J].图书情报知识,2013(1):107-113.
[8]赵红.吐鲁番文献与汉语语料库建设的若干思考[J].南京师范大学文学院学报,2014(3):155-158.
[9]宁可.敦煌社邑文书辑校[M].南京:江苏古籍出版社出版,1997.
[10]沙知.敦煌契约文书辑校[M].南京:江苏古籍出版社出版,1998.
[11]化振红.深加工中古汉语语料库建设的若干问题[J].西南大学学报(社会科学版),2014(3):136-142,184.
[12]王晓玉.中古汉语语料库的设计与实现[J].辞书研究,2017(3):17-26.
[13] 杨贤林.古籍整理中数字化技术的应用实践与展望[J].图书馆学刊,2014(3):51-53.
