基于缺失数据BN参数学习的电信流失客户预测算法
2018-02-01赵宇翔卢光跃王航龙李四维
赵宇翔,卢光跃,王航龙,李四维
基于缺失数据BN参数学习的电信流失客户预测算法
赵宇翔,卢光跃,王航龙,李四维
(西安邮电大学陕西省信息通信网络及安全重点实验室,陕西 西安 710121)
针对电信客户流失预测问题,在数据缺失情况下,基于贝叶斯网络(Bayesian network,BN),用最近邻算法填补缺失数据,并将两类定性约束融入贝叶斯网络参数学习过程,用以提高流失客户预测精度。仿真及实际数据分析结果表明,所提算法较经典的期望最大化(expectation maximization,EM)算法有明显优势,在牺牲代价较小的忠诚客户预测精度的情况下,得到了更高的流失客户预测精度。
贝叶斯网络;参数学习;数据缺失;最近邻算法;定性约束
1 引言
随着移动网络的快速发展,手机成为人与人沟通的重要方式。与此同时,未入网的新用户数量也在急剧下降。据估计,吸引一个新用户所花费的成本是挽留一个老客户所花费成本的5~6倍。所以,为了获取更大的利润,电信企业越来越重视潜在流失客户[1]。企业希望尽早发现这部分人群,及时做出有针对性的调整并成功挽留这部分客户。为了准确预测流失客户,很多学者采用贝叶斯网络(Bayesian network,BN)进行分类。
贝叶斯网络由有向无环图和条件概率表两部分组成[2],经过大约30年的发展,BN已经广泛应用于人工智能与数据挖掘等热门领域[3-5]。本文在电信客户流失网络结构已知情况下,研究离散贝叶斯网络参数学习的问题。
传统电信客户流失参数学习采用最大似然估计(maximum likelihood estimation,MLE)方法,但由于电信数据时常伴随有信息缺失,无法直接利用MLE方法逼近BN真实参数。对缺失数据进行参数估计的经典算法是期望最大化(expectation maximization,EM)算法[6],但EM算法对初始点的选取较为敏感、容易陷入局部最优解,而且在数据量较小时参数学习精度低。目前,很多学者通过引入先验知识来提高含缺失数据的BN参数学习精度。例如,参考文献[7]提出将EM算法与定性约束相结合,用定性的先验知识构造惩罚函数、用样本数据构造似然函数;然后将惩罚函数与似然函数结合构造出目标函数;最后利用CEM(constrained EM)算法求解BN参数。参考文献[8]则将保序回归算法融入EM算法每次迭代的步中,并在此基础上,提出一种复杂度更低的快速保序最大期望(qirEM)算法。参考文献[9]将参数学习问题视为凸优化模型,把最大熵函数与EM算法相结合构造凸优化问题。通过分析上述参考文献发现:参考文献[7]方法中惩罚函数随约束类型的变化而改变,并且其权重是人为赋予的,故该方法结果受人为影响;参考文献[8]的方法并不能保证在有限的参数空间中收敛到局部最优解;参考文献[9]方法可行域比较精确,但估计参数大多分布在可行域边缘位置,这样便浪费了不等式约束中所包含的信息。因此,如何在有缺失数据的样本中进行参数学习,仍然值得探讨。
本文首先用改进的近邻算法解决缺失数据的填充问题,然后在此基础上将先验知识融入BN参数学习过程中,用两类定性约束来调整估计参数。实验结果表明:在样本缺失率不同时,与传统的EM算法相比,本文算法学习得到精度更高的BN参数。
2 相关理论
2.1 贝叶斯网络
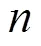




本文将网络中的所有参数分为两类:第一类是父节点组合状态相同而子节点状态不同的参数;第二类是子节点状态相同而父节点组合状态不同的参数,如图1所示。
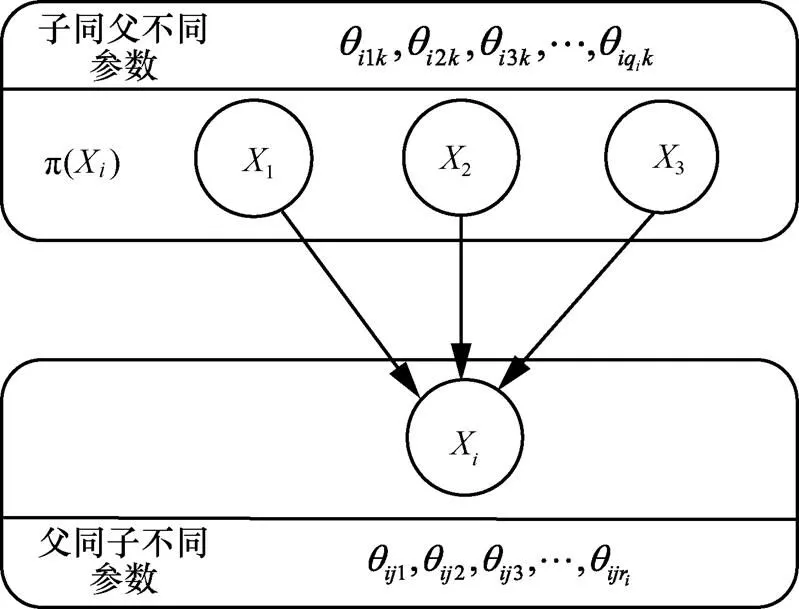
图1 BN节点参数分类示意
2.2 定性约束
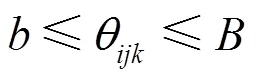
根据被约束参数父节点的不同状态,参数约束可以分为内部约束和外部约束[11]。内部约束是限制父节点组合状态相同而子节点状态不同时参数之间的关系;外部约束则是限制子节点状态相同而父节点组合状态不同时参数之间的关系。

图2 两节点贝叶斯网络结构
3 含缺失数据的BN参数学习算法
在电信数据中,由于机械或人为原因会造成部分属性缺失,若直接用这类数据集进行BN参数学习将难以保证参数的精度。为此,本节首先利用最近邻(-nearest neighbor,NN)算法填补缺失数据;接着用贝叶斯MAP思想进行参数的内部约束学习;最后用保序回归模型[12]进行参数的外部约束学习。
3.1 缺失数据填充
NN算法起初是用于解决分类问题,它为了找到与目标样本相似度最高的个样本,也就是距离目标样本最近的个样本,因此距离的表示形式很重要。当属性之间具有联系或量纲不同时,马氏距离比欧氏距离更适合度量邻近性,所以本文选取马氏距离作为NN算法中的距离度量形式[13]。
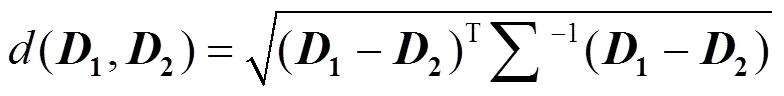

下面给出NN算法填补缺失数据步骤。
步骤1 数据预处理,将初始数据分为完整数据与缺失数据两部分,同时把缺失数据作为目标数据。
步骤2 根据式(4)计算目标数据与完整数据中每个样本的马氏距离。
步骤3 对所有进行排序,选取其中个马氏距离最小的样本作为目标数据的近邻。
步骤4 取个近邻中对应缺失属性出现最多的值来填补缺失处。
步骤5 重复步骤2~4,直到所有数据完整。
3.2 内部约束学习

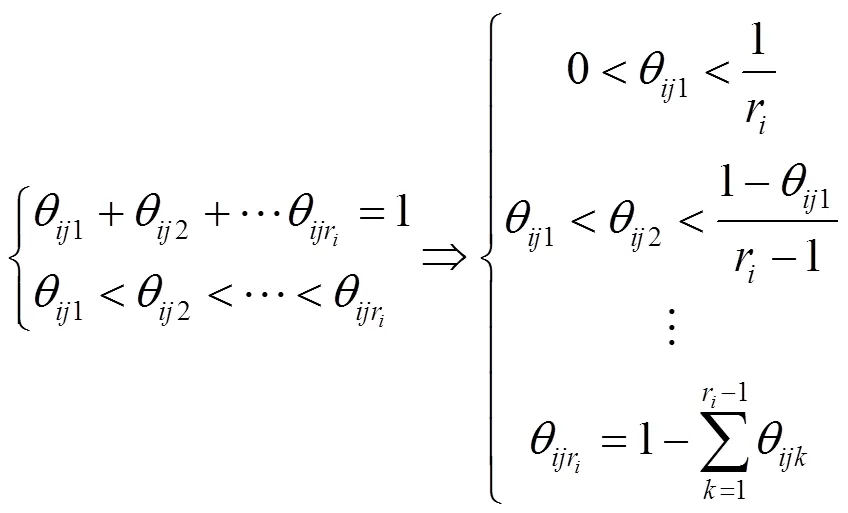

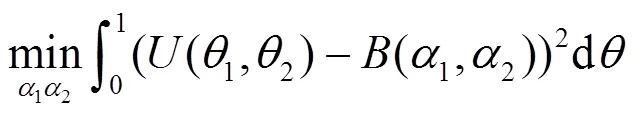
采用二阶矩法拟合,计算过程如下:
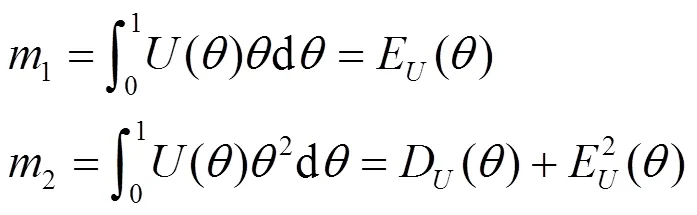



获得修正后的参数。内部约束学习方法步骤如下。
步骤1 根据先验知识判断是否内部约束满足单调性,如果满足单调性,则转入步骤2。
步骤2 根据依据式(6)求出各个参数取值的上下界,然后用Monte Carlo法基于均匀分布进行抽样。
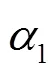
步骤4 利用式(12)得到校正后的参数。
3.3 外部约束学习
当明确父节点对子节点的定性影响时,即知道网络中不同父节点组合状态值优先顺序满足:

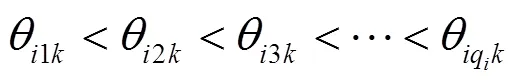



然后删除所有下限集合中与集合相交的部分,并从节点的全部父节点组合状态中删除集合中的组合状态,即:

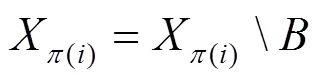
步骤1 根据先验知识确定不同父节点组合状态值的优先顺序并构造出所有的下限集合。
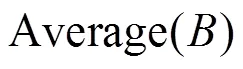
步骤3 依据式(17)和式(18)进行处理。
3.4 新算法流程
鉴于新算法用到了最近邻算法以及内、外部约束条件,本文称之为基于最近邻—双重约束的参数估计(-nearest neighbor-dual constrained estimation,NN-DCE)方法。总结前文的参数求解过程,新算法的总流程如下。
步骤1 将样本数据分为完整数据和缺失数据两部分。
步骤2 应用最近邻算法找出与缺失数据相似度高的完整数据,并填补对应的缺失属性。
步骤3 统计样本,获得样本统计值并根据式(3)求出初始参数。
步骤4 用内部约束学习方法修正父节点组合状态相同而子节点状态不同的参数。
步骤5 用外部约束学习方法方法校正父节点组合状态不同而子节点组合状态相同的参数。
4 算法仿真
本次仿真试验平台为MATLAB R2010b,运行环境为Windows 7。仿真实验由2部分组成:第4.1节从理论层面验证本文算法的优势;第4.2节将该参数学习算法应用到电信客户流失预测中,用真实数据证实算法的可行性。
4.1 经典模型仿真
采用草坪湿润模型(如图3所示),该模型已被广泛应用于BN参数学习算法的评估[14],先验知识见表1。

图3 草坪湿润BN模型
首先依原始网络真实参数随机生成一个数据集;然后使完整样本数据随机缺失,分别构造样本缺失率为20%、30%、40% 3种情况;最后采用KL散度[15]衡量算法准确性。KL散度值越小,表明估计参数与真实参数越接近,其计算式如下:


表1 试验约束
实验结果如图4~图6所示,图4~图6中给出了KL散度值随样本大小的变化情况。从结果可以看出:在样本量相同时,传统的EM算法KL散度小于NN-MLE算法,qirEM算法KL散度小于传统的EM算法,NN-DCE算法KL散度小于qirEM算法。反映出数据缺失情况下EM算法比简单地进行数据填补然后求参数的最大似然估计要更加优越,融入单一约束的qirEM算法比EM算法性能更好,而融入双重约束的NN-DCE算法性能最好。综上所述,应用NN-DCE算法可以很好地将先验知识融入参数学习,获得精度更高的参数。

图4 样本缺失20%时算法KL散度
4.2 电信客户流失预测
4.2.1 前期工作


图5 样本缺失30%时算法KL散度

图6 样本缺失40%时算法KL散度

图7 电信客户流失预测贝叶斯网络结构
4.2.2 预测结果
试验用550个样本构成训练集,样本缺失率(missing completely at random,MCAR)为25%,应用NN-DCE算法学习电信客户流失预测网络的参数。为了验证算法的有效性,用561个测试样本来检验该网络的预测精度,贝叶斯网络推理采用联合树算法[16]。电信客户流失预测是一个不平衡数据集分类问题,一般定义少数类为,多数类为,FP是指将多数类错分成少数类的样本总数,FN是指将少数类错分成多数类总数,TN表示分类正确的多数类样本数,TP表示分类正确的少数类样本数。用以下指标来评价预测精度:
少数类预测精度:

多数类预测精度:

总体分类精度:


表4 客户流失预测参数约束条件
仿真结果由表5给出。从表5中可以看出,应用本文算法总体的预测精度略高于EM算法和qirEM算法,最为关注的潜在流失客户的预测精度明显高于EM算法及qirEM算法,所以本文算法能够很好地应用到电信数据贝叶斯网络中进行参数学习。

表5 电信客户流失预测仿真结果
5 结束语
围绕电信流失客户预测中BN参数学习问题,本文提出NN-DCE参数学习算法。本文采用改进的NN算法填充缺失数据,然后在完整的数据基础上融入两类约束条件完成BN参数学习。仿真结果表明:所提算法性能优于EM算法,能有效提高电信流失客户预测精度。由于先验知识是否可靠会直接影响约束的正确性,进而影响参数学习的结果。在今后的工作中,将考虑先验知识的不确定性,研究如何缓解错误的先验知识对参数学习结果造成的负面影响。
[1] JAMIL S, KHAN A. Churn comprehension analysis for telecommunication industry using ALBA[C]//International Conference on Emerging Technologies(ICET 2016), Oct 1, 2016, Islamabad, Pakistan. Piscataway: IEEE Press, 2016.
[2] PEARL J. Probabilistic reasoning in intelligent systems: networks of plausible inference[J]. Computer Science Artificial Intelligence, 1988, 70(2): 1022-1027.
[3] WAGNER S. A Bayesian network approach to assess and predict software quality using activity-based quality models[J]. Information and Software Technology, 2016, 52(11): 1230-1241.
[4] PENDHARKAR P C, KHOSROWPOUR M, RODGER J A. Application of Bayesian network classifiers and data envelopment analysis for mining breast cancer patterns[J]. Journal of Computer Information Systems, 2016, 40(4): 127-131.
[5] COOK J, LEWANDOWSKY S. Rational irrationality: modeling climate change belief polarization using Bayesian networks[J]. Topics in Cognitive Science, 2016, 8(1): 160-179.
[6] LAURITZEN S L. The EM algorithm for graphical association models with missing data[J]. Computational Statistics & Data Analysis, 1995, 19(2): 191-201.
[7] LIAO W, JI Q. Learning Bayesian network parameters under incomplete data with domain knowledge[J]. Pattern Recognition, 2009, 42(11): 3046-3056.
[8] MASEGOSA A R, FEELDERS A J, GAAG L C V D. Learning from incomplete data in Bayesian networks with qualitative influences[J]. International Journal of Approximate Reasoning, 2015, 69(C): 18-34.
[9] CORANI G, CAMPOS C P D. A maximum entropy approach to learn Bayesian networks from incomplete data[M]// Interdisciplinary Bayesian Statistics. Berlin: Springer International Publishing, 2015: 69-82.
[10] 张连文. 贝叶斯网引论[M]. 北京: 科学出版社, 2006.
Zhang L W. Introduction of Bayesian network[M]. Beijing: Science Press, 2006.
[11] ZHOU Y, FENTON N, ZHU C. An empirical study of Bayesian network parameter learning with monotonic influence constraints[J]. Decision Support Systems, 2016, 87(C): 69-79.
[12] FEELDERS A, VAN D G L C. Learning Bayesian network parameters under order constraints[J]. International Journal of Approximate Reasoning, 2005, 42(1-2): 37-53.
[13] 刘星毅. 基于马氏距离和灰色分析的缺失值填充算法[J]. 计算机应用, 2009, 29(9): 2502-2504.
LIU X Y. ImprovedNN algorithm based on Mahalanobis distance and gray analysis[J]. Journal of Computer Applications, 2009, 29(9): 2502-2504.
[14] 杨宇, 高晓光, 郭志高. 小数据集条件下基于数据再利用的BN参数学习[J]. 自动化学报, 2015, 41(12): 2058-2071.
YANG Y, GAO X G, GUO Z G. Learning BN parameters with small data sets based reutilization[J]. Acta Automatica Sinica, 2015, 41(12): 2058-2071.
[15] KULLBACK S, LEIBLER R A. On Information and Sufficiency[J]. Annals of Mathematical Statistics, 1951, 22(22): 79-86.
[16] HU X J, YANG S L, MA X J. Inference structure and construction algorithms of Bayesian network based on junction tree[J]. Acta Simulata Systematica Sinica, 2004, 16(11): 2559-2558.
A prediction algorithm of telecom customer churn based on Bayesian network parameters learning under incomplete data
ZHAO Yuxiang, LU Guangyue, WANG Hanglong, LI Siwei
Shaanxi Key Laboratory of Information Communication Network and Security, Xi’an University of Posts and Telecommunications, Xi’an 710121,China
Aiming at prediction of telecom customer churn, a novel method was proposed to increase the prediction accuracy with the missing data based on the Bayesian network. This method used-nearest neighbor algorithm to fill the missing data and adds two types of monotonic influence constraints into the process of learning Bayesian network parameter. Simulations and actual data analysis demonstrate that the proposed algorithm obtains higher prediction accuracy of churn customers with the loss of less cost prediction accuracy of loyal customers, outperforms the classic expectation maximization algorithm.
Bayesian network, parameter learning, data missing, nearest neighbor algorithm, qualitative constraint
TP181
A
10.11959/j.issn.1000−0801.2018018
2017−07−11;
2017−09−26
陕西省工业科技攻关项目(No.2015GY-013);陕西省工业科技攻关项目(No.2016GY-113)
Industrial Research Project of Science and Technology Department of Shaanxi Province(No.2015GY-013), Industrial Research Project of Science and Technology Department of Shaanxi Province (No.2016GY-113)
赵宇翔(1993−),男,西安邮电大学陕西省信息通信网络及安全重点实验室硕士生,主要研究方向为数据挖掘。

卢光跃(1971−),男,博士,西安邮电大学陕西省信息通信网络及安全重点实验室教授,主要研究方向为信号与信息处理、认知无线电和大数据分析。
王航龙(1989−),男,西安邮电大学陕西省信息通信网络及安全重点实验室硕士生,主要研究方向为数据挖掘。

李四维(1989−),男,西安邮电大学陕西省信息通信网络及安全重点实验室硕士生,主要研究方向为数据挖掘。
