基于深度信念网络和线性单分类SVM的高维异常检测
2018-02-01李昊奇应娜郭春生王金华
李昊奇,应娜,郭春生,王金华
基于深度信念网络和线性单分类SVM的高维异常检测
李昊奇,应娜,郭春生,王金华
(杭州电子科技大学,浙江 杭州 310018)
针对目前高维数据异常检测存在的困难,提出一种基于深度信念网络和线性单分类支持向量机的高维异常检测算法。该算法首先利用深度信念网络具有良好的特征提取功能,实现高维数据的降维,然后基于线性核函数的单分类支持向量机实现异常检测。选取UCI机器学习库中的高维数据集进行实验,结果表明,该算法在检测正确率和计算复杂度上均有明显优势。与PCA-SVDD算法相比,检测正确率有4.65%的提升。与自动编码器算法相比,其训练和测试时间均有显著下降。
异常检测;高维数据;深度信念网络;单分类支持向量机
1 引言
异常检测是数据挖掘中的重要组成部分。异常数据是指在数据集中偏离大部分数据或者与数据集中其他大部分数据不服从相同统计模型的小部分数据[1]。而异常检测就是要识别出异常数据从而消除不符合预期行为的模式问题。异常检测在信用卡欺诈、网络入侵、健康医疗监控等诸多生活领域中均有重要应用[2]。
在异常检测中,单分类支持向量机(one-class support vector machine,OCSVM)是常用的有效手段[3]。OCSVM是对二分类支持向量机的一种细化,是在异常检测领域中的重要经典算法。当确定合适的参数配置时,OCSVM对于异常数据的检测可以提供良好的泛化能力。在OCSVM中,有两种经典算法用于异常检测,分别为基于超平面支持向量机(plane based support vector machine,PSVM)和基于超球面的支持向量描述(support vector data description,SVDD)法。相比较而言,利用超球面分类的SVDD算法性能优于基于PSVM算法。因此,通常采用SVDD算法进行异常检测。
然而,随着互联网的快速发展和物联网的逐渐普及,数据的收集更加容易。这导致数据库的规模和数据的复杂性急剧增加,从而产生大量的高维数据。如证券交易数据、Web用户数据、网络多媒体数据等。维度的迅速增长,使得传统的OCSVM方法对高维数据的异常检测效率逐渐下降,从而导致高维数据的异常检测成为数据挖掘的难点[4]。
高维数据存在的普遍性使得对高维数据挖掘的研究有着非常重要的意义。但“维度灾难”问题导致对高维数据挖掘变得异常困难。即在分析高维数据时,所需的空间样本数会随维数的增加而呈指数倍增长。对于高维数据的处理,传统的多元统计分析方法存在很多的局限性,同时高维数据空间中的稀疏性使得采用非参数方法的大样本理论也并不适用。因此,采用数据降维是处理高维数据的最主要的高效手段。
在机器学习领域中,所谓降维就是指采用某种映射方法,将原高维空间中的点映射到新的低维空间中[5]。经典的数据降维方法如主成分分析[6](principle component analysis,PCA)法、局部线性嵌入[7](locally linear embedding,LLE)法和典型相关分析[8](canonical correlation analysis,CCA)法等在特征提取和数据降维方面有着广泛的应用。但这些降维方法均属于线性降维,只能提取数据间的线性关系,从而导致在处理高维数据时存在着统计特性的渐进性难以实现、算法顽健性低等问题。尽管对PCA和CCA基于核函数改进后的核主成分分析(kernel principle component analysis,KPCA)法和核典型相关分析[9](kernel canonical correlation analysis,KCCA)法可以解决非线性降维的问题,但算法的复杂度较高、效率较低。
对于解决高维的异常检测问题,近几年有多种经典的方法被提出。参考文献[10]直接提出了OCSVM中的经典算法,即基于超球面的支持向量数据描述法。该算法虽然对当时的高维数据异常检测起了很大的推动作用,但算法的正确率偏低。参考文献[11]将PCA算法和OCSVM相结合,将数据利用经典的线性降维方法PCA进行降维,在OCSVM中采用非线性核函数进行异常检测。由于线性降维的局限性,其结果并没有很大的提升。参考文献[12]利用改进后的KPCA算法和OCSVM进行异常检测。检测结果虽有所提升,但由于非线性核函数计算量大,对数据进行训练和测试所需要的时间较长,导致该算法的效率不高。参考文献[13]利用自动编码器(autoencoder,AE),通过对比不同数据间的重构误差进行异常检测。其识别率虽有所提升,但测试效率依然不高。
本文提出利用深度信念网络(deep belief network,DBN)进行数据降维,再利用基于线性核函数的单分类支持向量机这种组合模型实现异常检测。深度信念网络本质上是一种概率生成模型,通过无监督的训练方法由底层至顶层逐层训练而成。与其他传统的线性降维方法相比,深度信念网络最大的特点就是利用其自身非线性的结构进行特征提取,将数据从高维空间映射至低维空间,从而降低数据的维度。这种非线性降维方法可以在最大程度上保留原始数据的高维特征,并且算法的复杂度较低,相比于其他算法可以更有效地解决高维数据的异常检测问题。实验结果表明,本文提出的混合算法模型,即将深度信念网络和线性单分类支持向量机组合在一起解决高维数据的异常检测问题,在检测正确率和测试效率上都有很大提升。
2 算法设计
本文所提出的算法(DBN-OCSVM)模型如图1所示,该模型由两部分组成,即底层的DBN和顶层的OCSVM。DBN由2个限制玻尔兹曼机(restricted Boltzmann machine,RBM)堆叠而成。将原始数据首先输入DBN的输入层,经RBM1训练后,输入层数据被映射至隐藏层1。隐藏层1的输出作为RBM2的输入继续训练后得到隐藏层2。隐藏层2的数据即DBN的输出,并将其输入OCSVM中进行异常检测。

图1 DBN-OCSVM结构

图2 OCSVM-SVDD算法示意
在OCSVM中,使用SVDD算法进行异常检测。SVDD为无监督训练算法,与有监督的二分类SVM相比,它并不是要寻找能够区分数据的最优超平面,而是寻找能够包含大多数正常数据的最优超球面。如图2所示,当输入空间的数据不可分时,构造一个映射函数,将输入空间中的数据映射到特征空间中。在特征空间中,寻找支持向量构造一个将绝大多数点包围在其中并具有最小半径的最优超球面。由支持向量确定的超球面即正常数据类的描述模型,超球面外的点被判断为离群类数据点,即异常数据。
在SVDD的核函数选取中,选择线性函数代替传统方法中的径向基函数(radical basis function,RBF)。在SVM中,核函数的选择对算法的性能起着重要的作用,利用核函数可以将线性不可分的输入空间映射到更高维的特征空间,从而将正常数据和异常数据进行完全分离。通常,相比较线性核函数而言,RBF等非线性核函数可以将数据映射到更适于线性分类的特征空间,从而提高SVM的分类性能。但利用本文提出的模型,经DBN进行降维以及特征提取后的数据通过线性核函数依然可以进行优秀的分类,从而规避了线性核函数的缺点,反而突出了其优点。即降低了算法的时间复杂度和空间复杂度,提高了系统的运行速率。
3 算法原理
3.1 基于深度信念网络的高度降维
DBN的实质是由一个高斯—伯努利型RBM作为底层,上层接有多个伯努利—伯努利型RBM,这样将多个RBM堆叠起来便得到了所需要的生成模型DBN。将第一个RBM训练后得到的输出作为下一个RBM的输入继续训练,如此往复,经过训练后的各个RBM参数就是DBN的初始化参数。



其等价于:


根据该能量配置函数,设定可见层和隐藏层的联合概率密度为:




在RBM中负对数似然度对于任意一个模型参数的导数为:



3.2 基于单分类支持向量机的异常检测



则上述问题便可以转化为:


4 实验与分析
实验中将DBN-SVDD算法与SVDD算法、PCA-SVDD算法和AE算法进行比较,从检测正确率和训练以及测试时间方面对比3种算法的性能。本实验采用的数据集来自UCI机器学习库,数据均采集于真实的生活。共选取4个高维数据集进行训练和测试,其分别为:森林覆盖集(forest covertype,FC)、基于传感器检测的气体种类集(gas senor array drift,GAS)、日常活动集(daily and sport activity,DSA)和基于智能设备穿戴的人类活动集(human activity recognition using smartphone,HAR)。其维数分别为:54、128、315和561维。采用不同维度的数据集进行测试,从而更好地评估本文算法性能。


表1 3种算法在RBF核函数下的异常检测正确率

表2 3种算法在线性核函数下的异常检测正确率
在以下实验中,用DBN后所加的数字表示DBN的层数。例如:DBN1和DBN3分别表示为具有1层和3层隐藏层的深度信念网络。在实验一和实验二中,默认的DBN为具有2层隐藏层的深度信念网络。对于DBN的每个隐藏层神经元个数,根据参考文献[18]的方法在最优性能下确定。
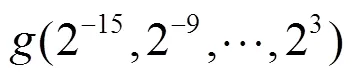
(1)实验一
将DBN-SVDD算法与SVDD、PCA-SVDD 两种经典算法分别在线性(linear)核函数和径向基函数(radical basis function,RBF)下进行实验对比。通过对以上4个数据集进行异常检测,其识别率见表1、表2(识别率保留百分号前小数点后两位),并将表1、表2的数据绘制成图3、图4的折线。

图3 RBF函数下3种算法对4个数据集的异常检测正确率

图4 DBN-SVDD算法下两种核函数的异常检测正确率对比
通过观察表1、表2中的数据以及图3、图4,可以得出以下结论。

• 对于PCA方法降维,当使用线性核函数时,对于低维数据集如FC、GAS,异常检测的正确率有一定提升;当数据维度较高时,如DSA、HAR,利用PCA降维相比于SVDD算法其测试结果几乎没有提升。
•对于SVDD和PCA-SVDD这两种算法,无论使用线性核函数或者径向基函数,随着数据维度的增加,其异常检测的正确率逐渐下降。而使用DBN-SVDD算法其异常检测结果基本不受数据维度的影响,在各种维度的数据中,其检测结果都要优于另外两种算法。
•对于DBN-SVDD算法,当使用线性核函数和径向基函数时,对实验结果基本不产生影响。这说明利用DBN更好地提取了高维数据中的特征,即使用线性核函数也有很好的检测结果。
(2)实验二
将AE算法与DBN-SVDD算法分别在检测正确率和检测效率上进行比较。对于DBN-SVDD混合模型,训练和测试的时间包括数据降维部分和降维后异常检测两部分的总和,训练和测试的时间为SVDD平均迭代1 000次的时间值。
首先将DBN-SVDD分别在线性和RBF两种核函数下的异常检测率与AE算法进行比较,实验结果见表3。
由表3可以看出,AE算法的平均异常检测正确率为97.24%,与DBN-SVDD算法在RBF核下的97.63%以及线性核下的97.65%几乎没有差别。说明AE算法通过对比数据间的重构误差,在异常检测正确率上也可以达到很好的效果。再将两种算法的训练和测试时间进行对比,实验结果分别见表4和表5。

表3 DBN-SVDD与AE算法的异常检测正确率对比

表4 DBN-SVDD与AE算法的训练时间对比(单位:s)
由表4可以看出,DBN-SVDD算法下两种核函数分别进行训练的时间基本一致,这也进一步表明DBN对高维数据进行特征提取的优良特性。对于AE算法,其训练时间平均为0.772 1 s,分别为线性核DBN-SVDD的5.5倍和RBF核的4.4倍,进一步说明了DBN-SVDD算法的高效性。
由表5可以看出,AE算法的测试时间平均时间为3.993 0 ms,均大于线性核DBN-SVDD和RBF核SVDD算法。与AE算法相比,线性核函数的测试平均时间为0.281 3 ms,时间缩短了近13.2倍;RBF核函数的测试平均时间为0.473 1 ms,时间缩短了近7.4倍。对于DBN-SVDD算法,其采用线性核函数所测试的时间小于采用RBF核函数进行测试的时间。这是由于RBF核函数具有更高的计算复杂度,因此需要花费更多的时间。由于采用线性核函数和RBF核函数,异常检测正确率几乎一致,而采用线性核函数进行测试的平均时间为0.281 3 ms,相比于采用核函数的0.473 1 ms,时间降低了40.54%。因此,采用线性核函数在很大程度上缩短了进行数据测试的时间,提高异常检测效率。

表5 DBN-SVDD与AE算法的测试时间对比(单位:ms)

表6 线性核函数下不同DBN隐藏层数对实验结果的影响
(3)实验三
在确定DBN-SVDD混合模型为最优算法的前提下,探究DBN隐藏层的层数对实验结果的影响。由于过多的层数会增加模型的复杂性和算法计算量,因此只讨论最多3层隐藏层对实验结果的影响。在实验1中,进行了具有2层隐藏层的DBN测试。接下再分别对DBN1和DBN3在线性核函数下进行实验测试,实验结果见表6。
将表5中的实验结果绘制成图5后可以看出,具有1层隐藏层的DBN1属于“浅层模型”,导致其最终实验测试结果除了在GAS数据集为97.02%,略高于其他两种算法外,在其余数据集的测试结果均低于另外两种“深层模型”。对于DBN3,其实验结果与DBN2相比除了在FC数据集上有较大波动外(检测率降低了0.90%),在其他数据集上的检测结果相差甚微,只在0.18%~0.35%范围波动,基本相同。而对于DBN3而言,其网络模型的复杂度以及计算量均高于DBN2。因此,确定具有2层隐藏层的DBN2为最佳网络模型。
5 结束语
本文通过将深度信念网络和单分类支持向量机组合到一起,提出DBN-SVDD算法模型。通过数据降维的方式,该算法很好地解决了高维数据的异常检测问题。利用DBN的非线性特性以及逐层递进的特征提取方式来获得高维数据中的低维特征,良好地解决了“维数灾难”问题。通过实验,确定了DBN2为最佳的降维网络模型。采用线性核的DBN-SVDD算法在测试时间上相比RBF核可以降低34.9%。对比PCA-SVDD算法,其检测正确率最高提升了4.65%;对比AE算法,其测试时间缩短到1/13。

图5 不同DBN隐藏层数下的异常检测正确率
[1] 王忠伟, 陈叶芳, 肖四友, 等. 一种高维大数据全近邻查询算法[J]. 电信科学, 2015, 31(7): 52-62.
WANG Z W, CHEN Y F, XIAO S Y, et al. An AkNN algorithm for high-dimensional big data[J]. Telecommunications Science, 2015, 31(7): 52-62.
[2] CHANDOLA V, BANERJEE A, KUMAR V. Anomaly detection:A survey[J]. ACM Computing Surveys, 2009, 41(3): 1-58.
[3] SHIN H J, EOM D H, KIM S S. One-class support vector machines—an application in machine fault detection and classification[J]. Computers & Industrial Engineering, 2005, 48(2): 395-408.
[4] 李昕, 钱旭, 王自强. 一种高效的高维异常数据挖掘算法[J]. 计算机工程, 2010, 36(21): 34-36.
LI X, QIAN X, WANG Z Q. Efficient data mining algorithm for high-dimensional outlier data[J]. Computer Engineering, 2010, 36(21): 34-36.
[5] TENENBAUM J B, DE S V, LANGFORD J C. A global geometric framework for nonlinear dimensionality reduction[J]. Science, 2000, 290(5500): 2319.
[6] POMERANTSEV A L. Principal component analysis(PCA)[M]. New York: John Wiley & Sons, Inc., 2014: 4229-4233.
[7] ROWEIS S T, SAUL L K. Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290(5500): 2323.
[8] GONZALEZ I, DÉJEAN S, MARTIN P G P, et al. CCA: an R package to extend canonical correlation analysis[J]. Journal of Statistical Software, 2008, 23(12).
[9] CHENOURI S, LIANG J, SMALL C G. Robust dimension reduction[J]. Wiley Interdisciplinary Reviews Computational Statistics, 2015, 7(1): 63-69.
[10] 程辉, 方景龙, 王大全, 等. 超平面支持向量机简化性能分析[J]. 电信科学, 2015, 31(8): 78-83.
CHENG H, FANG J L, WANG D Q, et al. Performance analysis of simplification of hyperplane support vector machine[J]. Telecommunications Science, 2015, 31(8): 78-83.
[11] GEORGE A. Anomaly detection based on machine learning dimensionality reduction using PCA and classification using SVM[J]. International Journal of Computer Applications, 2012, 47(21): 5-8.
[12] BAO S, ZHANG L, YANG G. Trajectory outlier detection method based on kernel principal component analysis[J]. Journal of Computer Applications, 2014, 34(7): 2107-2110.
[13] SAKURADA M, YAIRI T. Anomaly detection using autoencoders with nonlinear dimensionality reduction[C]//Mlsda Workshop on Machine Learning for Sensory Data Analysis, December 2, 2014, Gold Coast, Australia QLD, Australia. New York: ACM Press, 2014: 4-11.
[14] HINTON G E. Training products of experts by minimizing contrastive divergence[J]. Neural Computation, 2002, 14(8): 1771-1800.
[15] SUBRAMANIAM S, PALPANAS T, PAPADOPOULOS D, et al. Online outlier detection in sensor data using non-parametric models[C]//International Conference on Very Large Data Bases, September 12-15, 2006, Seoul, Korea. New York: ACM Press, 2006: 187-198.
[16] MOORE B. Principal component analysis in linear systems: controllability, observability, and model reduction[J]. IEEE Transactions on Automatic Control, 2003, 26(1): 17-32.
[17] HU C, HOU X, LU Y. Improving the architecture of an autoencoder for dimension reduction[C]//Ubiquitous Intelligence and omputing, 2014 IEEE, Intl Conf on and IEEE, Intl Conf on and Autonomic and Trusted Computing, and IEEE, Intl Conf on Scalable Computing and Communications and ITS Associated Workshops, Dec 9-12, 2014, Bali, Indonesia. Piscataway: IEEE Press, 2014: 855-858.
[18] HINTON G E. A practical guide to training restricted Boltzmann machines[M]. Berlin: Springer Berlin Heidelberg, 2012: 599-619.
[19] YANG J, DENG T, SUI R. An adaptive weighted one-class svm for robust outlier detection[M]. Berlin: Springer Berlin Heidelberg, 2016.
[20] LIN C J. A practical guide to support vector classification[EB/OL]. (2003-01-31)[2017-06-21]. http://www.researchgate.net/publication/ 200085999_A_Practical_Guide_to_Support_Vector_Classication.
High-dimensional outlier detection based on deepbelief network and linear one-class SVM
LI Haoqi, YING Na, GUO Chunsheng, WANG Jinhua
Hangzhou Dianzi University, Hangzhou 310018, China
Aiming at the difficulties in high-dimensional outlier detection at present, an algorithm of high-dimensional outlier detection based on deep belief network and linear one-class SVM was proposed. The algorithm firstly used the deep belief network which had a good performance in the feature extraction to realize the dimensionality reduction of high-dimensional data, and then the outlier detection was achieved based on a one-class SVM with the linear kernel function. High-dimensional data sets in UCI machine learning repository were selected to experiment, result shows that the algorithm has obvious advantages in detection accuracy and computational complexity. Compared with the PCA-SVDD algorithm, the detection accuracy is improved by 4.65%. Compared with the automatic encoder algorithm, its training time and testing time decrease significantly.
outlier detection, high-dimensional data, deep belief network, one-class SVM
TP183
A
10.11959/j.issn.1000−0801.2018006
2017−06−21;
2017−09−26
国家自然科学基金资助项目(No.61372157);“电子科学与技术”浙江省一流学科A类基金资助项目(No.GK178800207001)
The National Natural Science Foundation of China(No.61372157), Zhejiang Provincial First Class Disciplines: Class A-Electronic Science and Technology (No.GK178800207001)
李昊奇(1992−),男,杭州电子科技大学硕士生,主要研究方向为深度学习与数据挖掘。

应娜(1978−),女,博士,杭州电子科技大学副教授、硕士生导师,主要研究方向为信号处理与人工智能。
郭春生(1971−),男,博士,杭州电子科技大学副教授、硕士生导师,主要研究方向为模式识别与人工智能。

王金华(1992−),女,杭州电子科技大学硕士生,主要研究方向为深度学习与自然语言处理。
