基于局部密度自适应度量的粗糙K-means聚类算法*
2018-01-26马福民逯瑞强张腾飞
马福民,逯瑞强,张腾飞
(1.南京财经大学信息工程学院,江苏 南京 210023;2.南京邮电大学自动化学院,江苏 南京 210023)
1 引言
聚类分析是根据“物以类聚”的原理将物理或者抽象对象所组成的集合进行分类的一种多元统计分析方法,己经成为数据挖掘领域一个非常重要的分支,被广泛应用于机器学习、图像分割等众多领域。按照其特点,聚类算法大致可以分为五类:划分方法、层次方法、密度方法、栅格方法和模型化方法[1]。K-means算法是最常见的划分聚类方法之一,于1967年由Queen[2]首次提出,目前依然是众多数据聚类分析任务首选的经典算法。加拿大学者Lingras[3]在使用K-means算法对Web数据进行挖掘分析时,针对传统算法所存在的问题,引入了粗糙集理论上、下近似的思想,提出了粗糙K-means聚类算法,在计算数据对象的归属关系时,不再是简单地用属于或不属于来表示,而是把确定属于某一簇的对象归属到其相应的下近似集中,不确定是否属于该簇的对象归属到其相应的边界集中,因此,各个簇可以看作是由下近似集和边界集两部分组成。这种对聚类数据对象相对客观的描述方法,在很大程度上提高了K-means聚类算法的精度。
粗糙K-means算法同其它任何的聚类分析算法一样,算法的性能也依然受到初始参数、不确定性数据交叉重叠等因素的影响。为此,已经有很多学者陆续提出了进一步的改进算法,从聚类结构的角度来看,这些算法大致可以分为两类[4]:
(1)粗糙K-means的扩展算法。这类方法没有改变聚类过程中簇内的数据结构,仅仅是在原有算法的基础上,对初始参数、聚类指标等进行优化。Peters[5]使用相对距离代替绝对距离,排除粗糙K-means算法中存在的受离群点干扰的问题,并且结合遗传算法对粗糙K-means算法的初始参数做了优化[6]。
(2)粗糙K-means的衍生算法。这类算法可以认为是对粗糙K-means算法的本质提升,主要是针对均值迭代公式进行修正。聚类对象之间的近似度量得以进一步强化,如结合模糊集理论来构建对象关系。文献[7]发现了在粗糙K-means聚类结果中存在仅有边界集非空的情况,并对粗糙K-means均值公式做了修正,对粗糙权值重新进行了定义。文献[8,9]介绍了粗糙模糊K-means聚类算法,这种方法使用了模糊隶属度来反映簇间的差异性,提高了算法的精度。文献[10]提出一种模糊粗糙K-means算法,对模糊隶属度量进行了修订,将下近似集中数据对象的隶属度设置为1,仅对边界区域不确定的对象采用模糊度量。
现有的粗糙K-means衍生算法在构造近似关系时大多仅关注单个数据对象与多个簇之间的差异性,而忽略了同一簇内对象之间的区别,在同一个近似区域中使用统一的权值来衡量不同对象在均值迭代过程中的影响程度。然而,在一个簇的内部,不同的数据对象点到均值中心的距离不同以及不同数据对象周围的数据分布疏密程度等都将直接影响着聚类的结果。文献[11]提出了一种对象点加权的方法,利用类似于方差统计的权值变形,区别簇内对象的差异。文献[12]利用统计对象点邻域内的距离总和来反映区域密度,提高了粗糙K-means算法的精度。文献[13,14]认为密度是一种空间特征,反映了样本属性的综合趋势和拓扑的不规则构型。文献[15]综合考虑了距离和密度的混合度量,但对于密度的度量方法是采用简单的邻域范围数据对象的数量统计,并没有真正体现数据分布的疏密程度。这些方法利用各个空间特征构建新的近似关系,但是大都缺乏对适应性的考虑,不同的数据聚类可能对不同空间特征的敏感程度不同,基于空间特征的近似关系需要有综合性的合理度量。
本文结合数据对象的不同分布对聚类结果的影响,提出一种局部密度自适应度量的方法,并给出基于局部密度自适应度量的粗糙K-means聚类算法,通过统计数据对象点与均值中心的距离以及邻域内数据分布的疏密程度,来描述簇内数据对象分布的特点,靠近聚类中心且邻域内数据对象聚集程度高的数据点,将得到更高的自适应迭代权值,从而加快聚类的收敛速度,并提高聚类的效果。最后,通过实例计算分析验证算法的有效性。
2 粗糙K-means聚类算法
粗糙K-means聚类算法是将粗糙集理论与K-means算法相结合,将具有不确定归属关系的数据对象划入边界区域,并使用不同的权值度量来降低边界区域数据对象在迭代过程中的影响。算法实际上是将同一簇分为了两个部分,即具有确定归属关系的下近似区域和具有不确定归属关系的边界区域,通过区分下近似集和边界集中数据对象的不同贡献,一定程度上提高了模糊边界的处理精度。
2.1 传统的粗糙K-means聚类算法
根据Lingras所提出的粗糙K-means算法,聚类对象的处理具有以下三个特征[16]:
(1) 聚类对象最多只能确定地属于某一个簇的下近似集;
(2) 聚类对象若不能确定地属于某一个簇的下近似集,可同时属于多个簇的上近似集;
(3) 每个簇的下近似集是它的上近似集的子集。
粗糙K-means算法与传统K-means算法最大的区别主要体现在特征(2)中,将这些不适合硬划分的数据对象,归属到多个簇共有的边界集中。
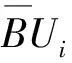
(1)
其中,wlow、wup分别为下近似集和上近似集的粗糙权值。
若每一个数据对象的类簇归属不再发生变化,说明算法已经收敛,算法终止;否则将新的Ci作为初始化中心,重新计算每一个数据对象到各个类簇中心的距离,并根据当前的距离判断到各个类簇的归属关系。
由于数据对象到各个类簇的划分是依据其到类簇的均值中心Ci的距离,因此,均值中心的位置直接关系到聚类对象近似关系的判断。从上述的计算过程不难看出,中心均值的迭代公式是影响最终聚类结果的关键因素。另外,粗糙K-means算法将簇分为下近似集和边界集两个部分,当wup取值较小时,边界对象在均值迭代计算过程中影响较小,降低了边界区域数据对象的不确定性影响。
为评估粗糙K-means算法的收敛性以及聚类质量,Lingras给出了如公式(2)所示的评估函数:
(2)

2.2 粗糙K-means的衍生算法
粗糙K-means聚类的衍生算法很多,其中比较经典的是粗糙模糊K-means算法和模糊粗糙K-means算法。这两种算法结合了模糊理论,以模糊隶属度来表达聚类对象与各簇之间的从属关系,表示对象以多大的程度归入当前簇。模糊隶属度的表达式如下所示[8]:
(3)
其中,μij表达对象Xj关于簇Ui的隶属度,m是模糊指数,dij表示Xj到均值中心Ci的距离,且模糊隶属度满足:
(4)
模糊隶属度是一种簇间关系的表达,通过转化比较簇间距离的比例关系,来反映对象与各簇的关联程度。
粗糙模糊K-means算法将模糊隶属度作为对象聚类的决策标准,将对象归入隶属程度最大的簇的下近似集;或者当对象关于多个簇的隶属程度相近时,则将对象归入多个簇的上近似集。并且,算法对均值中心的迭代计算公式(1)进行了改进,如公式(5)所示[9]:
(5)
从均值计算公式(5)中可以看出,粗糙模糊K-means强调了对象在簇间和簇内的差异度,与采用固定权值的粗糙K-means算法相比,其聚类过程对边界的处理更加平滑。
模糊粗糙K-means算法则从另外一个角度对模糊隶属度量公式进行了改进,即凡是在下近似集中的对象,隶属度全部赋值为1,表示分配在下近似集中的对象绝对属于当前簇。模糊粗糙K-means算法还将均值中心的计算公式进行了简化,省却了粗糙权值,公式如下[10]:
(6)
其中,N′表示第i个簇当中所包含的对象个数。
粗糙模糊K-means和模糊粗糙K-means算法一定程度上体现了不同的数据对象在计算均值中心时的差异性,但更多的是从对整个簇的度量角度出发,针对同一簇内不同数据对象的不同分布及对聚类结果的影响考虑较少[17,18],然而这些距离或局部密度分布却对聚类结果有着不可忽略的影响。
3 基于局部密度自适应度量的聚类算法
3.1 局部密度自适应度量
从粗糙K-means及其衍生算法的实现原理,可以总结出粗糙K-means系列算法处理边界模糊性问题的特点:
(1) 将带有不确定归属关系的聚类对象放在多个簇的共有边界中;
(2) 距离均值中心越远的对象在迭代的过程中其权重越小;
(3) 聚类对象无论是在簇内还是簇间,对聚类迭代过程及结果均有不同的影响。
文献[15]对比分析了粗糙K-means算法、粗糙模糊K-means算法、模糊粗糙K-means算法在一个簇中不同数据分布的权值分配,如图1~图3所示,其中wlow=0.7,wup=0.3,m=2。

Figure 1 Weight distribution of rough K-means图1 粗糙K-means算法的权值分配

Figure 2 Weight distribution of rough fuzzy K-means图2 粗糙模糊K-means算法的权值分配

Figure 3 Weight distribution of fuzzy rough K-means图3 模糊粗糙K-means算法的权值分配
可以看出,粗糙K-means的权值显然比较生硬,只是简单地对同簇的对象权值二值化,并没有体现出下近似集和边界集内部的差异性;粗糙模糊K-means的权值则显得比较平滑,并且在很大程度上降低了边界区域对均值中心的影响,但是,由于照搬模糊隶属度量的原理,使得下近似集当中的对象往往受到虚线部分的簇间影响;模糊粗糙K-means则对下近似集中的对象权重直接赋予1,表示下近似集确定属于当前簇,但是,依然没有考虑下近似集对象因分布不均衡而产生的不同影响。
从上述分析不难看出,数据对象的权重系数应当由均值中心向边界降低,并且越靠近边界,下降应越快。而且,权值的设置除了体现出与距离的关系,还应和簇内数据对象的聚集程度即空间分布有关。为了充分更好地描述数据对象的这种距离与空间分布,给出一种局部密度自适应度量的方法。
局部密度自适应度量的表达式如下:
(7)
其中,‖Xj-Ci‖表示对象Xj到所在簇的中心Ci的欧氏距离;|L(Xj)|ξ表示距离Xj为ξ的邻域范围内数据对象的个数。
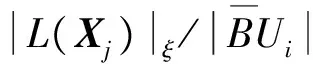
公式(7)的第一部分体现了数据对象点到均值中心的距离对权重系数的影响,可以看做是点到点的不同位置特征分布;第二部分则体现了数据对象点邻域范围内局部的数据空间分布对权重系数的影响,可以看做是点到面的不同空间特征分布。整体而言,上述局部密度自适应度量的表达式较好地体现了簇内数据对象不同分布的空间特征,并较好地刻画了不同空间分布的数据对象之间的差异性。
3.2 基于局部密度自适应度量的聚类算法设计
结合上一节局部密度自适应度量的方法,本节进一步给出一种基于局部密度自适应度量的粗糙K-means聚类算法RKM-LDAM(RoughK-means clustering based on Local Density Adaptive Measure),算法流程如图4所示。

Figure 4 Flow chart of algorithm图4 算法流程图
根据图4所示的流程,RKM-LDAM算法的详细描述如下所示:
算法1RKM-LDAM算法:基于局部密度自适应度量的粗糙K-means聚类。
输入:U:U={Xj|j=1,…,N},对象数为N的数据集;
k:聚类簇的个数。
输出:将数据对象集合U划分为k个簇。
Step1参数设置与初始化,包括:
Ci:聚类均值中心,且i=1,…,k;wlow、wup:分别为下近似集和上近似集的相对粗糙权值系数;Δ:距离判断阈值;ξ:局部密度统计范围阈值。
Step2∀Xj∈U,计算Xj到各均值中心Ci的距离dij(i=1,…,k),统计Xj附近ξ范围内对象个数|L(Xj)|ξ;

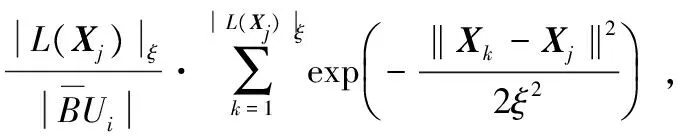
(8)
Step5根据公式(1)检测结果是否收敛,若不收敛,返回Step 2重新进行迭代聚类计算;否则,算法终止,输出k个类簇。
就上述算法的时间复杂度而言,步骤2的复杂度为O(|U|2),步骤3的复杂度为O(k|U|),步骤4在最坏情况下为O(|U|2),因此本文算法单次迭代计算的时间复杂度为O(|U|2)。
4 实验仿真与分析
为了验证算法有效性,采用本文基于密度自适应度量的粗糙K-means算法(RKM-LDAM)对多个UCI数据集进行聚类测试,并与典型的粗糙K-means算法RKM(RoughK-means)、模糊K-means算法FKM(FuzzyK-means)、粗糙模糊K-means算法RFKM(Rough FuzzyK-means)、模糊粗糙K-means算法FRKM(Fuzzy RoughK-means)在聚类精度和运行速度方面进行对比分析。
4.1 实验环境
本文选取了4个UCI数据集作为实验对象,分别是Iris、Wine、Fertility和Ionosphere。这4个UCI数据的一些信息和特征描述如下:
Iris是一个最常用的UCI数据集,包含了一些植物特征和鸢尾花分类之间的信息。该数据集包含150个样本,每个样本有4个条件属性和1个决策属性,其中决策属性将数据分为3类。
Wine数据集主要是对同一区域的意大利葡萄酒的化学成分分析。数据集包含了178个样本,每个样本有13个属性和1个决策属性,其中决策属性将数据分为3类。
Fertility记录了生育能力和一些生理记录之间的联系。数据集包含了100个样本,每个样本有9个条件属性和1个决策属性,其中决策属性将数据分为2类。
Ionosphere数据集通过分析电离层结构来判断电离层的好坏。数据集包含了351个样本,每个样本有34个条件属性和1个决策属性,其中决策属性将数据集分为2类。
实验的计算机平台使用英特尔酷睿i7(2.90 GHz)处理器,4 GB内存,操作系统是Windows 7 SP1。
4.2 聚类效果分析
为了比较算法聚类效果,实验在聚类精度和运行速度两个方面对各个算法进行对比分析。由于所选数据集均有较明确的分类决策,这里聚类精度是指对比原数据集的决策属性值,被正确聚类的数据对象在数据集中所占的百分比,计算公式为:
(9)
为了便于比较不同算法的性能,实验过程中对同一数据集使用统一的初始聚类均值中心,对算法中多个参数的设置采用经验选择,由于个别的算法会涉及不同的参数,经过测试,这些参数均选取较优的组合,这里暂不考虑最优参数的选取过程。
聚类参数的设置如表1所示。
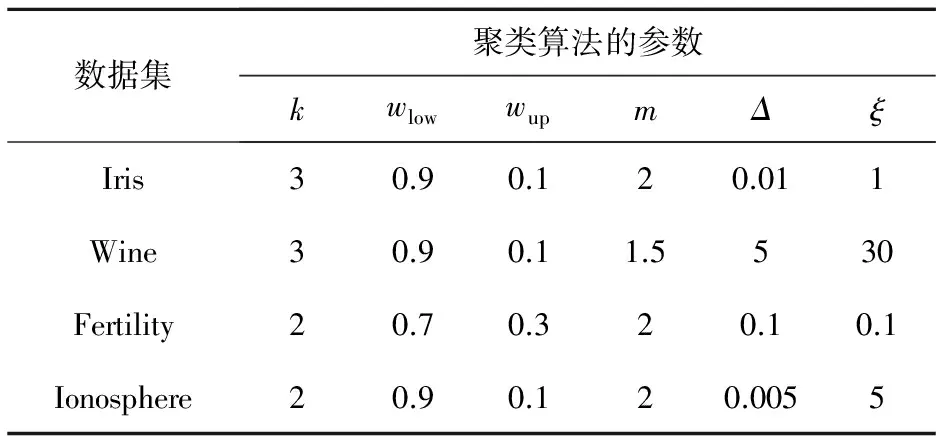
Table 1 Parameter settings for clustering algorithms
为了更为客观地对各算法进行对比分析,针对每一个数据集,每种算法均采用十字交叉验证,表2和表3分别记录了各个聚类算法平均的精度和运行时间,图5和图6直观地反映了不同算法在各数据集中的聚类效果。
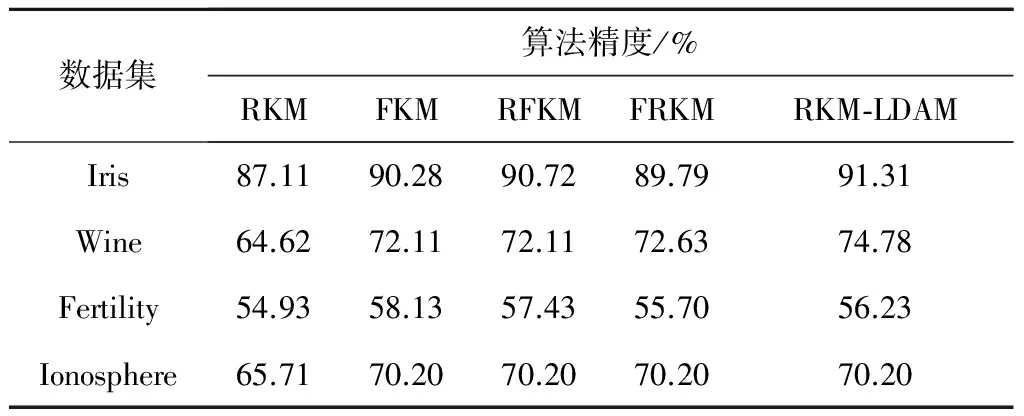
Table 2 Accuracy comparison of differentclustering algorithms on UCI data sets

Table 3 Computational time comparison ofdifferent clustering algorithms on UCI data sets

Figure 5 Accuracy comparison of different algorithms图5 各算法聚类精度

Figure 6 Computational time of different algorithms图6 各聚类算法运行时间
从表2和图5不难看出,本文设计的基于密度自适应度量的粗糙K-means算法(RKM-LDAM),有着不输于其它算法的聚类性能,对Iris、Wine、Ionosphere三个数据集都达到了最高的聚类精度,尤其是对Iris和Wine两个数据集的效果更好;仅仅对Fertility数据集的聚类精度稍低于采用模糊聚类FKM和RFKM方法的聚类结果。而由表3和图6可以看出,除了Fertility数据集,本文所使用的RKM-LDAM算法的运行速度都比较快,其中对Ionosphere数据集的聚类收敛速度更为突出,相对5种算法的平均耗时下降了15.87%。
综合上述结果可以看出,基于局部密度自适应度量的粗糙K-means算法(RKM-LDAM),通过对聚类数据对象的空间特征进行局部密度自适应度量,更有利于提高聚类算法的性能,也验证了数据对象点在簇内的不同分布会对聚类的结果产生一定的影响。
5 结束语
簇内数据对象与均值中心的不同距离、邻近范围内数据分布的疏密程度直接影响着聚类的精度与收敛速度。针对这一问题,本文提出了一种基于局部密度自适应度量的粗糙K-means聚类算法,在聚类的迭代计算过程中,通过对簇内数据对象与均值中心的距离以及局部密度的自适应度量,使得聚类结果簇内相似程度更高、收敛速度更快。通过对多个UCI数据集进行测试计算并与以往的多种算法进行对比分析,说明本文算法具有较好的聚类效果。
[1] Han Jia-wei, Kamber M. Data mining,concepts and techniques [M].3rd Edition. San Francisco:Morgan Kaufmann Publishers,2011.
[2] Queen M. Some methods for classification and analysis of multivariate observation[C]∥Proc of the 5th Berkeley Symposium on Mathematical Statistics and Probability,1967:218-297.
[3] Lingras P,West C.Interval set clustering of web users with roughk-means [J].Journal of Intelligent Information Systems,2004,23(1):5-16.
[4] Peters G,Crespo F,Lingras P,et al.Soft clustering-fuzzy and rough approaches and their extensions and derivatives [J].International Journal of Approximate Reasoning,2013,54(2):307-322.
[5] Peters G.Outliers in roughk-means clustering [C]∥Proc of International Conference on Pattern Recognition and Machine Intelligence,2005:702-707.
[6] Peters G,Lampart M.A partitive rough clustering algorithm [C]∥Proc of International Conference on Rough Sets and Current Trends in Computing,2006:657-666.
[7] Peters G.Some refinements of roughk-means clustering [J].Pattern Recognition,2006,39(8):1481-1491.
[8] Mitra S, Banka H, Pedrycz W.Rough fuzzy collaborative clustering [J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2006,36(4):795-805.
[9] Mitra S,Banka H,Pedrycz W.Collaborative rough clustering [C]∥Proc of International Conference on Pattern Recognition and Machine Intelligence,2005:768-773.
[10] Hu Qing-hua,Yu Da-ren.An improved clustering algorithm for information granulation [C]∥Proc of International Conference on Fuzzy Systems and Knowledge Discovery,2005:494-504.
[11] Liu Bing,Xia Shi-xiong,Zhou Yong,et al.A sample-weighted possibilistic fuzzy clustering algorithm [J].Acta Electronica Sinica,2012,40(2):371-375.(in Chinese)
[12] Zheng Chao,Miao Duo-qian,Wang Rui-zhi.Improved roughK-means clustering algorithm with weight based on density [J].Computer Science,2009,36(3):220-222.(in Chinese)
[13] Liu Qi-liang,Deng Min,Shi Yan,et al.A density-based spatial clustering algorithm considering both spatial proximity and attribute similarity [J].Computers & Geosciences,2012,46:296-309.
[14] Azadeh A,Saberi M,Anvari M,et al.An adaptive network based fuzzy inference system-genetic algorithm clustering ensemble algorithm for performance assessment and improvement of conventional power plants [J].Expert Systems with Applications,2011,38(3):2224-2234.
[15] Zhang Teng-fei,Chen Long,Ma Fu-min.A modified roughc-means clustering algorithm based on hybrid imbalanced measure of distance and density [J].International Journal of Approximate Reasoning,2014,55(8):1805-1818.
[16] Lingras P,Peters G.Rough clustering [J].Data Mining and Knowledge Discovery,2011,1(1):64-72.
[17] Zhang Teng-fei,Chen Long,Li Yun.Roughk-means clustering based on unbalanced degree of cluster [J].Control and Decision,2013,28(10):1479-1484.(in Chinese)
[18] Zhang Teng-fei,Ma Fu-min.Improved rough k-means clustering algorithm based on weighted distance measure with Gaussian function [J].International Journal of Computer Mathematics,2017,94(4):663-675.
附中文参考文献:
[11] 刘兵,夏士雄,周勇,等.基于样本加权的可能性模糊聚类算法[J].电子学报,2012,40(2):371-375.
[12] 郑超,苗夺谦,王睿智.基于密度加权的粗糙K-均值聚类改进算法[J].计算机科学,2009,36(3):220-222.
[17] 张腾飞,陈龙,李云.基于簇内不平衡度量的粗糙K-means聚类算法[J].控制与决策,2013,28(10):1479-1484.
