基于模型和库的处理器伪随机激励生成器设计与实现*
2018-01-26巨鹏锦张晓冬
巨鹏锦,张晓冬,李 辉
(上海高性能集成电路设计中心,上海 201204)
1 引言
随着集成电路技术的飞速发展,高性能处理器设计的复杂度和规模不断增大,同时激烈的行业竞争也促使高性能处理器厂家努力缩短产品研发周期,加快产品更新速度。近些年来,在国家大力发展自主可控信息产业的战略下,国产高性能处理器研发取得长足的发展,产业化应用不断深入。在国产高性能处理器设计技术不断缩小与国外差距的同时,作为研发平台支撑的国产处理器验证技术必须适应处理器研发需要,不断提升处理器验证的核心技术能力。
当今高性能处理器的验证通常综合采用模拟验证[1,2]、硬件仿真加速验证[3,4]、FPGA原型验证[5]、形式验证[4,6]等方法。从各种验证方法发现的设计错误统计来看,模拟验证仍然是主要验证手段,发现错误的比例占总数的九成左右,而处理器模拟验证的最大难点在于如何能够快速编写和生成大量高质量的测试激励。目前业界主要采用伪随机激励生成器来生成高质量的验证程序。Stress Test[7]由基于马尔可夫模型的生成器和活动监测器组成,生成器和监测器构成闭环生成模型,生成器利用用户提供的模板和监测器反馈的信息生成验证程序;Genesys-Pro[8 - 10]通过编写测试模板、单指令建模、处理器结构建模,使用约束求解CSP(Constraint Satisfaction Problem)来生成测试激励;文献[11]提出一种基于分层思想的受限随机激励产生方法,通过测试层、场景层、功能层和指令层的多层约束,实现随机激励生成。以上激励生成器的设计方法主要是针对如何高效生成伪随机测试激励、加快覆盖率收敛速度方面的研究。但是,面对当今处理器不断发展的架构设计,如多核、多线程、众核等等,处理器伪随机激励生成器设计不仅需要考虑如何高效生成高覆盖率的测试激励,而且需要考虑当处理器架构变化时,如何能够利用已有的测试激励集合重构新架构处理器的测试激励集合,从而最大限度重用已有的测试库,以高起点开始新架构处理器的验证工作,只有这样才能满足越来越短的处理器产品研发周期要求。
本文提出一种基于模型和库的伪随机激励生成器实现方法,该方法能够较好地解决处理器设计变化对已有测试激励集合的影响,可以避免因设计变化而导致激励生成器生成的测试激励失效问题。本文设计实现的激励生成器不但能够适应处理器关键微结构的变化,还可以适应处理器指令集和地址空间的变化,而且在多核Cache一致性测试方面还可以适应多核处理器核心数量的改变。
2 需求分析
建立一个高效的处理器伪随机激励生成器,需要充分考虑处理器功能验证中的需求,包括:(1)指令流测试,用户能够选择指令集合进行测试激励生成;(2)异常控制,用户可以控制测试激励中每种异常发生的频度;(3)资源共享,用户可以控制指令序列对CPU资源的共享情况,如寄存器、访存地址等等;(4)循环,用户可以定义各种类型的循环结构,用于特定情况的验证;(5)数据类型,用户调用这些数据类型可以方便随机各种数据边界情况,如整数最大、最小值数据、全零、浮点无穷大、非数等等;(6)伪随机约束控制,伪随机约束用于控制激励生成器产生某些情况的概率,用户既可以对激励中的特定条目施加“局部约束”,也可以对激励中某一类结构施加“全局约束”。
另外,还需要考虑模拟仿真环境对随机激励生成器的开发需求:(1)灵活方便地对内存空间进行划分。内存空间的分配和使用是模拟仿真环境的一个重要方面,项目不同使用方式也可能不同,同一个项目也会发生变化,以此要求随机激励生成器应能够根据仿真环境灵活方便地对内存空间进行划分。(2)应满足处理器的复杂初始化需求。这包括页表的创建、寄存器的初始化、核心内部控制寄存器的初始化,甚至芯片内部的I/O寄存器初始化等等。(3)生成的激励目标文件最好为二进制格式,应该包含激励中要运行的配置、指令和各种数据信息。(4)能够方便查看生成的激励的反汇编结果。
除了首先要满足以上这些通用需求外,本文在开发随机激励生成器的时候要还重点考虑生成器以及在其上开发的测试库的通用性和继承性,力求使其能够适用于多种不同架构处理器的开发,使得已开发测试库能直接或经过重构后用于多款不同处理器的研发,从而能够充分继承之前的验证成果,缩短处理器验证周期,提高验证效率。
3 设计实现
3.1 设计思想和方法
本文激励生成器KIG(Knowledgeable Instruction Generator)是一款基于约束求解的处理器伪随机激励生成器,采用Specman E语言设计实现。Specman E提供了强大的约束分析引擎和伪随机发生器,称为“IntelliGen”,能够分析复杂约束条件,产生各种伪随机数据类型和数据结构。SystemVerilog语言也是各家EDA公司都支持的成熟语言,与Specman E属于同一类语言,也可以用于建立伪随机激励生成器。
为了适应处理器设计变化的需求,本文激励生成器采用了基于模型和测试库的、自底向上的层次化设计方法。如图1所示,共分6个层次,自底向上分别为基础结构层、单元模型层、单元树层、测试知识库、测试序列库和测试情景。
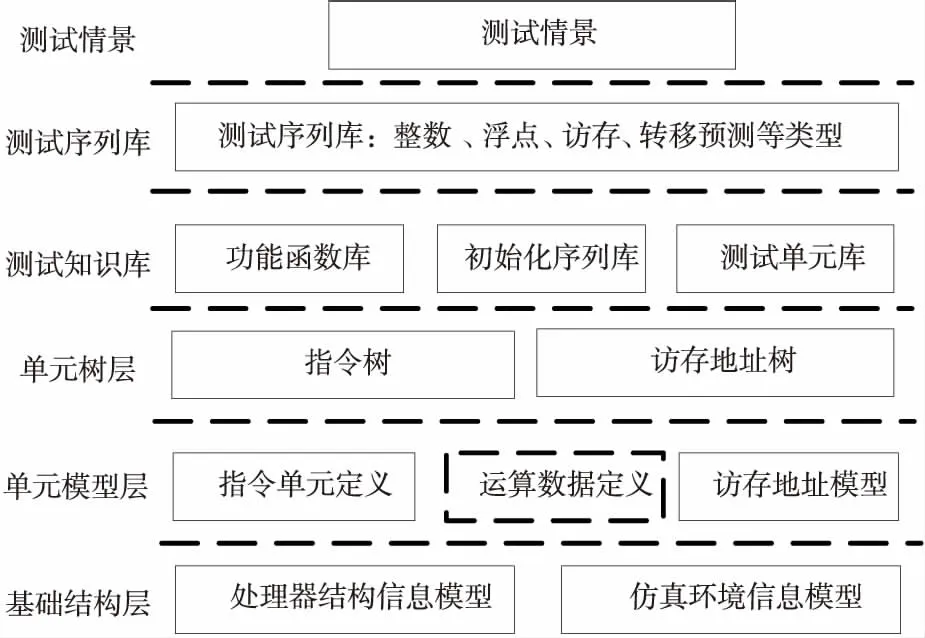
Figure 1 Bottom-up design method of processor test generator development图1 自底向上的处理器激励生成器设计方法
激励生成器的层次化设计遵循以下原则:(1)基础结构层和单元模型层是激励生成器的底层定义,由开发人员维护,不允许用户修改;(2)“单元树”层是激励生成器的中间层,是生成器与用户的交界面,也由开发人员维护,但为验证测试人员提供了对单元树的组织结构进行变更的接口;(3)测试知识库主要由经验丰富的验证工程师开发和维护;(4)测试序列库是完全开放的,所有验证工程师都可以根据需求定义自己的库,通常会按照验证侧重点分类,但这个分类是指导性的,因为处理器验证的复杂性往往使得很多测试序列是综合类型的;(5)测试情景中定义了全局约束和各个处理器核心与序列库的调用关系。
为了保证测试程序的可重用性,测试情景只调用测试序列,不在测试情景中编写具体的用户程序。全局约束是指对激励生成器内全局结构的约束,可以施加于测试情景之下的各个层次。如对基础结构层的处理器结构信息模型和仿真环境模型的全局约束,通常会为每款处理器定义一个单独的配置文件。在多核Cache一致性的测试情景中,可通过定义全局的共享规则约束来控制不同核心对Cache的共享情况,在本文的3.6节会具体展开说明。测试情景与测试序列库的不同之处在于,测试情景区分单核测试和多核测试,而测试序列库则不区分单多核测试。图2是KIG的图形界面,用户可以使用该界面配置激励生成约束,并自动生成测试情景。

Figure 2 GUI of KIG processor pseudo-random test generator图2 KIG伪随机激励生成器界面
这种层次化设计方法使得当处理器设计或者仿真环境变化时,我们只需要修改基础结构层、单元模型层或者是单元树层的定义,就可以保证上层的测试知识库、测试序列库保持不变。而由于测试情景与设计的密切相关性,比如参与测试的处理器核心数发生变化,测试情景也必须随之变化,但由于测试情景仅仅包含核心对序列库调用关系和全局约束,并不包含用户编写的测试代码,容易修改和继承,甚至于在用户指导下进行批量转换。同理,基于所有已开发的测试序列库,还可以定义各类全局约束组合,批量重构新的测试情景,大批量产生伪随机测试激励,使已有测试序列库发挥更大作用。
3.2 单核心结构建模
处理器单核心结构模型中描述了部分处理器内核的结构和微结构信息,例如Cache组成结构、结构寄存器、地址代换缓冲TLB(Translation Lookaside Buffer)、内部控制和状态寄存器信息等等。本文在处理器单核结构模型的建模中主要采用了以下三种建模方法:
(1)结构信息参数化建模法。如Cache的组成结构建模就只需要建立各级Cache的信息档案,包括容量、相联度、Cache块大小等。有了这些信息,后续编写测试激励时可以调用这些变量控制激励的生成,当处理器设计改变时,只需要根据新的处理器结构对这些参数重新配置即可。本文在对处理器结构建模时,Cache结构、TLB结构、物理寄存器资源数量等都采用了这种建模方法。
(2)资源池建模法,典型的如寄存器资源。在处理器验证中,指令序列的寄存器相关性测试是处理器流水线验证中的一种必测情形;另一种情形是某些寄存器在一段时间内用于保存特定数据,比如访存地址,而在序列随机混合时不希望这个寄存器内容被其它随机生成的指令冲掉。以上两种情形需要激励生成器提供一种机制对寄存器资源的使用进行控制。本文采用资源池建模法,在激励生成器中设置全局的free和lock的寄存器资源列表,free列表中存放着待分配的空闲寄存器,lock列表中存放着已分配的寄存器,free列表中的寄存器允许随机读写,而lock列表中的寄存器不允许被随机读写。如果不希望指令序列的某些寄存器被其它指令序列更改,可以申请寄存器分配,分配成功后,该寄存器会被放入lock列表,并且从free列表中删除,其他随机产生的指令应该避免使用lock列表中的寄存器作为目标寄存器。这种建模方法不但解决了硬件资源的使用冲突问题,而且还便于控制指令序列在使用硬件资源时的相关性,如下伪代码所示:
allocated_reg_list=int_reg.reg_alloc(参数:寄存器个数);
do add inst keeping {
.src0 inint_reg.free_list();
.src1 inint_reg.lock_list();
.desinallocated_reg_list; /*目标寄存器指定为分配的寄存器*/
};
do sub inst keeping {
.src0 inallocated_reg_list; /*源寄存器使用add指令的目标寄存器*/
.src1 inint_reg.free_list();
.desinint_reg.free_list(); /*这个约束保证了lock寄存器不会被冲掉*/
};
add指令目标寄存器使用分配得到的寄存器资源,sub指令源寄存器也使用分配得到的寄存器资源,则sub与add指令之间建立了一种先写后读的相关性关系,sub指令作为一种随机指令将目标寄存器约束为free列表,同时也避免冲掉其它序列已经分配使用的寄存器。
(3)行为模型建模法。对处理器某些结构的建模必须实现该结构的行为功能才能控制特定激励序列的生成,比如地址代换缓冲TLB的建模,生成TLB测试激励时,TLB的模型必须支持用户对TLB页表条目的约束控制,如页面权限设置、页面粒度等,但用户不能控制物理页面的分配,这部分功能必须由激励生成器实现。
3.3 仿真环境结构建模
处理器仿真环境的一般构成如图3所示,主要由被测设计DUT(Design Under Test)、内存模型(Memory Model)、指令集模拟器ISS(Instruction Set Simulator)、设计监测(Monitor)及结果检查模块(Checker)组成。仿真环境主要有三大功能:支持DUT的引导和运行、支持测试激励的加载和内存空间管理,以及支持运行结果的检查比较。
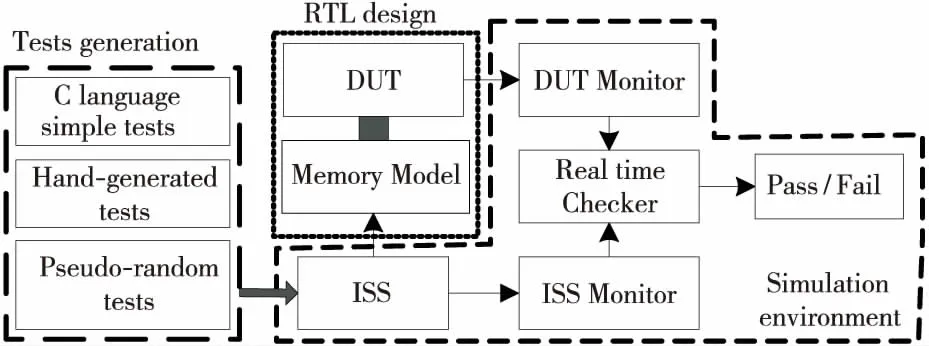
Figure 3 Simulation environment of processor verification图3 处理器仿真验证环境构成图
由于处理器设计不同,仿真环境也可能不同,尤其是指令集模拟器的内存空间管理发生变化时,必然会影响原有测试程序的重用,另外程序的运行初始化也会因设计功能改变而变化,处理器的架构改变,比如从单核到多核或者众核,测试激励的组成形式也必然发生变化,这些都会影响到激励生成器的可重用性。因此,在激励生成器设计时应该综合考虑以上需求,将这些数据信息建模到仿真环境模型中,使得仿真环境与激励生成器之间的接口协议规范化和参数化,从而实现伪随机激励生成器跨芯片设计环境的可重用。
为适应处理器设计和仿真环境的变化,对仿真环境的建模主要针对测试激励加载、内存空间管理和程序运行初始化功能。
(1)测试激励加载建模。伪随机激励生成器生成的测试激励既可以选择生成汇编源代码,也可以选择直接生成目标码。为了方便随机生成指令字段中的各个域,简化仿真环境,伪随机激励生成器通常会直接生成目标码。为了适应不同处理器架构下测试激励的生成和加载模式,同时从伪随机测试的需求分析,伪随机激励生成器生成的目标码格式可以自由定义,不需要与编译器生成的目标码格式一致。这样做的好处是,当处理器架构或指令集改变时,伪随机验证不需要依赖于编译器、汇编器等软件开发的进度,伪随机激励生成器与指令集模拟器接口一致,自成一体。自定义目标码的格式只需要包含一些基础段即可,如页表段、指令正文段、伪随机数据段、用户数据段等等,如图4所示。
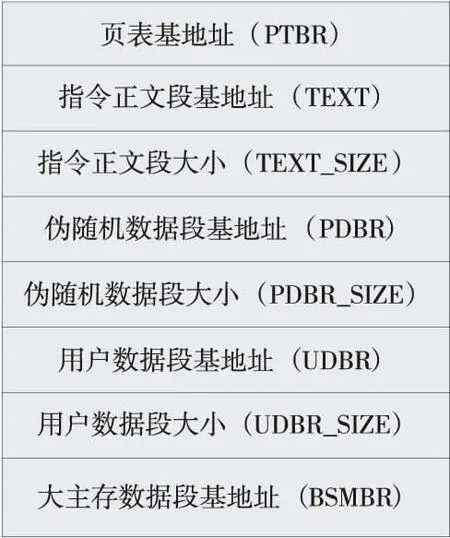
Figure 4 File head of a customized pseudo-random test object图4 自定义激励目标码文件头信息
(2)内存空间管理建模。在无操作系统的仿真环境下,内存空间的管理主要通过指令集模拟器实现,通过定义不同类型的内存空间来实现一个满足验证要求的裸机运行环境。内存空间的类型包括:①测试程序数据段,其内存空间划分与伪随机目标码的功能段划分相对应。②页表数据。页表是一类特殊的数据,在有操作系统管理的环境下,页表数据是动态产生的,而在伪随机测试环境下,页表数据则是由激励生成器在激励生成过程中生成的。③特权程序。特权程序是处理器在特定情况下执行的固件代码,这部分数据一般不会修改,但也可以根据测试需要做修改。④特殊功能的地址空间,比如锁测试程序中定义的锁和临界资源的内存地址。伪随机激励生成器应该使用参数定义上述内存空间,当指令集模拟器内存空间管理发生变化时,根据新的内存空间定义、修改激励生成器的对应参数,即可使原有测试库符合新的仿真环境内存空间定义。
(3)程序运行初始化功能建模。由于处理器设计的需要,通常在启动运行阶段,处理器会执行一段特定程序完成对设计的必要初始化。通常在伪随机验证中,为了测试处理器的各种运行模式和参数配置,也需要对这段程序进行约束和随机。因此,激励生成器应该定义初始化程序段以满足处理器设计变化时对初始化程序的变更需求。
3.4 可配置多核处理器建模
单核心和仿真环境的结构建模是可配置多核处理器建模的基础。本文在实现中采用了UVM(Universal Verification Methodology)方法学[12],将与单核心相关的设计结构和环境信息独立封装,可根据多核处理器核心数量配置单核模型实例化的个数,并通过采用Virtual Sequence[12]技术将N个核心的Sequence Driver集中控制,如图5所示。
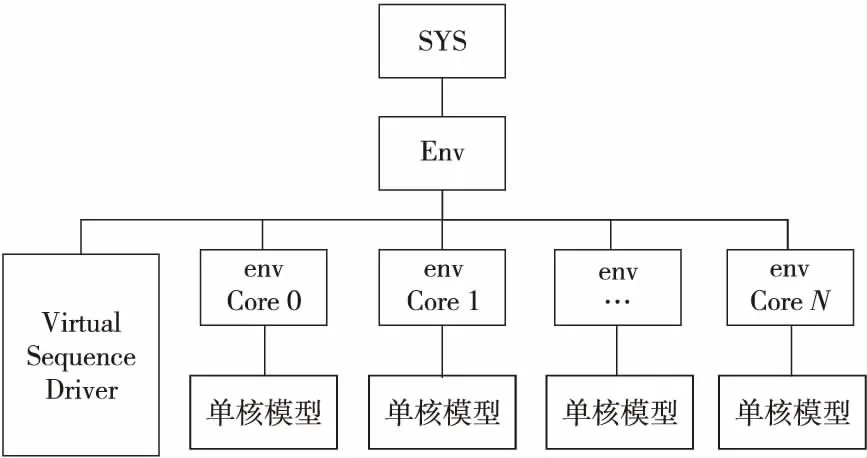
Figure 5 Scalability of multi-core processor model composed of single-core models图5 可配置多核处理器模型结构图
多核处理器执行程序的指令空间可以分为共享空间和私有空间,所谓共享空间即各个核心共享内存的一份指令数据,私有空间即各个核心的指令数据是地址分开的。这两种方式在实际软件应用中都是存在的,从验证功能的完备性考虑,激励生成器理论上应该支持这两种实现方式。但是,激励生成器的设计应该从功能验证的需求出发,在满足验证需求的前提下尽量简化测试激励模型,以提高激励生成效率。就这点而言,验证需求的本质是如何满足不同的核执行指令序列的相关性要求。这里的相关性要求包括两个方面:一是指令空间上的地址相关性,二是指令序列中访存操作的地址相关性。访存操作的地址相关性验证,即多核处理器Cache一致性实现的功能验证,其重要性不言而喻,必须提供高效的测试机制。而指令空间上的地址相关性,当程序段多核共享时,不同核心指令Cache中有共享指令数据的只读副本,由于指令空间通常是只读的,因此这种指令相关性功能比较简单。验证环境中的固件程序通常采用这种实现方式,即可满足这部分的功能验证。特殊情况下也存在某一核心生产指令,其它核心消费指令的使用模式,这是一种特殊的编程模式,本质上也是访存操作地址的相关性,可以转换成数据地址空间上的相关性来实现。
基于上述分析,多核版本的激励生成器采用了私有空间方式实现每个核心的指令空间,主要考虑到指令空间地址相关性并非处理器功能验证的重点难点,且有其他测试手段补充验证,而私有空间实现方式可以为每个核心提供差异化的测试序列,更具有灵活性。由于每个核心的测试序列不同,测试激励的大小各不相同,为了解决这个问题,在实现多核版本时,采用不同核心串行生成测试激励的方法,每个核心所需要占用的内存空间通过动态计算得到,每个核心的测试激励单独控制。在多核测试时,指令序列中访存操作的地址相关性更为重要,因为涉及到不同核心之间内存共享如何实现。本文通过建立访存地址模型和定义全局的共享规则,约束底层指令序列中访存地址的生成来实现,详见3.6节。
3.5 指令集建模
指令集是激励生成器的用户接口,指令集的定义方式直接关系到伪随机激励的编写效率,本文提出了一种“指令树”建模方法,实践中取得了良好效果。
指令树建模方法,顾名思义,就是将指令集看作是一棵树,如图7所示。“树叶”为指令单元,如图中的“SUBW”和“SUBL”。指令单元主要定义了指令的格式和各种属性信息,“树枝”为指令组,由一组特定分类的指令单元组成,如图中的“减法指令”;“树枝”可以分为支干和主干,低级指令组“支干”可以组成更高一级的指令组“主干”;最顶级的就是“树根”,树根包含了所有指令定义。“树干”节点代表的就是指令单元的各类属性,指令单元的属性定义越多,则“指令树”的层次划分越多,伪随机控制就越精细。

Figure 6 Organization of instruction set tree图6 指令树组织结构图
指令树建模法有以下优点:(1)能有效避免指令集调整对原有测试序列的影响,实现原有测试知识库、测试序列不做修改地继承;(2)“树形结构”有效地组织了随机元素,使得在激励编写中能够灵活地指定随机方向——“树枝”“树干”,并且控制不同方向上的权重;(3)“树形结构”能够在Excel表中清楚地表达指令集的随机元素,使得激励编写人员能够快速地掌握激励编写技术,提高了激励开发效率,并且文档具有很强的继承性。
3.6 访存地址建模
随着半导体工艺的发展,高性能处理器集成的核心数量越来越多,运算性能不断提升,而存储器带宽的提升相对较慢,为了解决“存储器墙”问题,高性能处理器通常采用多层次存储器、多条访存流水线、硬件预取等设计[13],再加上复杂的片上Cache一致性协议,这些都对处理器访存验证提出了很高的要求。本文提出一种面向多核处理器验证的多维访存地址建模方法,可降低多核访存激励编写的难度,同时便于控制测试激励的随机度,提高多核处理器的验证效率。
一般的访存激励中仅仅把访存地址看作一个一维的数据,而如何选择一个合适的访存地址以达到测试目的,则需要激励编程人员不仅对处理器的访存流水线设计非常的清楚,而且还需要对仿真环境的内存模型空间限制很清楚,一旦编写多核Cache一致性测试激励,还必须仔细考虑多个核心对内存地址的共享方式。传统的访存激励编写模式费时费力,对编程人员要求很高,而一旦处理器设计变化,原有的测试激励很可能失效。
通过对处理器的访存测试情景进行分析,可以看出,访存地址的重要性在于处理器中各种访存资源的使用均与访存地址相关,例如:(1)对Cache资源的使用。现代处理器的Cache设计一般采用虚索引虚标识VIVT(Virtual-Indexed,Virtual-Tagged)、虚索引物理标识地址VIPT(Virtual-Indexed,Physical-Tagged),或者物理索引物理标识PIPT(Physical-Indexed,Physical-Tagged)[14,15],无论采用哪种方式,内存副本在Cache中的状态转换都与地址序列有关,如Cache的命中、淘汰、预取、装填、不同核心共享读写等等。(2)对地址代换缓冲TLB资源的使用。TLB的装填、命中、淘汰、刷新等操作均是通过页面索引不同、页面粒度不同的虚地址序列实现的。(3)对I/O寄存器的资源使用。(4)多核共享存储资源。狭义的共享是指不同的核心访问的存储器地址有交叠,而在处理器的硬件设计中,Cache数据是以Cache块为单位管理的,也就是说,只要不同核心访问的地址在同一Cache块内,即使地址没有交叠也是共享,这里称为“伪共享”,实际在验证当中为了避免参考模型与设计行为不一致,一般采用“伪共享”的测试方法。
通过上述分析,可以根据访存地址与访存资源使用的对应关系建立多种类型的多维访存地址模型。图7是多核共享访存地址模型的定义示例,“块内索引”是指一个Cache块内的地址索引,“行索引”对应Cache行的索引地址,“共享规则”域实际上是从TAG标志地址分离出来的几位,用于定义多核共享Cache块的各种情况。

Figure 7 Bit field definition of multidimensional memory address
图7 多维访存地址位域定义
例如编写一个四核处理器的存储共享程序,如下所示代码中定义了两个共享规则全局约束
R
0和
R
1。
R
0规则定义:TAG标志随机8个,行索引随机1个,这些Cache块由核心0、1、2共享,如果Cache是4路组相联结构,指定行索引1个,不同的TAG有8个,那么在测试中既可以产生多核共享,又可以产生本核心的Cache挤占淘汰。
//在全局测试情景中定义共享规则名称:
extendshare_rule_t[R0,R1];
/*R0规则定义:TAG标志随机8个,行索引随机1个,核心0、1、2共享;*/
add_global_share_rules(R0,TagNum=8,IndexInum=1,core_list=(0, 1, 2));
/*R1规则定义:TAG标志随机4个,行索引随机2个,核心0、1、2、3共享*/
add_global_share_rules(R1,TagNum=4,IndexInum=2,core_list=(0, 1, 2,3));
/*在序列库中的使用方式如下,序列库中的序列无需知道在哪个核运行、有哪些共享规则*/
gen MEM addr_var keeping {
.ruleinenv.global_share_rules[my_core_name]; /*随机从本核相关的共享规则中生成共享地址*/
};
这种实现方式将关键访存流水线结构信息,通过对访存地址的多维建模施加到测试激励中,不但大大降低了测试激励的编写难度,而且便于测试序列库跨处理器结构重用。
3.7 测试库实现
设置测试库的目的是为了对测试程序进行分层和分类管理,方便测试程序的查找、共享和维护,测试库分为两个层次:测试知识库和测试序列库。
测试知识库的概念就是由对处理器结构和功能非常了解的资深验证工程师开发出针对处理器各个测试方面的测试序列和约束条件,并内置于激励生成器,测试知识库的约束会默认施加给测试情景序列,验证人员也可以根据需要,在自己的测试情景序列中重载某些测试约束,例如加大某类指令的权重,或是控制边界数据的比例;测试知识库的序列一般是短小精悍,具有完全的可重用性,能覆盖处理器测试中的特定测试情况。测试知识库还具有开放性的特点,能够在处理器验证过程中,不断地添加、完善,逐渐累积,从而有效缓解了处理器测试空间巨大与测试激励编写效率之间的矛盾。
测试序列库的层次在测试知识库之上,由一般测试人员编写和维护,可以调用测试知识库的程序,也可以使用地址树、指令树以及处理器模型和环境模型的接口编写测试程序,测试序列库的开发由处理器验证需求驱动,在处理器功能验证过程中不断积累完善。为了便于使用管理,测试序列库通常会按照验证侧重点分类,如访存类、运算类、转移预测类、异常故障类等等。
4 应用效果
本文实现的伪随机激励生成器KIG目前已成功应用于5款不同型号处理器的研发,这些处理器的芯片架构不同,指令集也有差异。为了说明应用效果,我们选取了两款应用了KIG激励生成器的处理器验证和一款采用一般方法实现的激励生成器的处理器验证进行对比分析。这三款处理器分别是:(1)16核处理器A,一款较早开发的多核处理器,处理器核心指令集和芯片架构有较大变动,核心微结构变化较小,采用了一般的指令级建模伪随机激励生成器完成验证;(2)4核处理器B,处理器核心微结构和指令集均有较大变化,核心由原来的2译码3发射变为4译码7发射,性能和复杂度均有较大提高,采用了本文开发的KIG激励生成器验证;(3)16核处理器C,处理器核心微结构和指令集相对B均有部分变化,芯片架构变动较大,也采用本文开发的KIG激励生成器验证。
对这三款处理器验证效果进行对比分析的主要指标为覆盖率验证周期和错误收敛趋势。这里的“覆盖率验证周期”是指在处理器全片代码合拢,验证环境创建完成,达到基本功能正确性后,开始启动代码和功能覆盖率验证到双覆盖率达100%的验证阶段。
从图8中可以看到,16核处理器A由于指令集和芯片架构有较大变化,而之前用的激励生成器虽然采用了基于库的分层设计方法,但是由于不是同时采用基于模型和库的方法建模实现,导致了之前积累测试激励大部分都无法使用,修改的工作量巨大,因此覆盖率验证花了近6个月才完成。4核处理器B虽然核心微结构和指令集变化非常大,KIG激励生成器也是第一次投入使用,但是基于模型和库的设计方法提高了测试激励编写效率,尤其是基于模型的实现方法降低了对验证人员工作经验的要求,许多新入职验证人员也可以开发出高质量测试激励,从而使得覆盖率收敛速度大幅提高,达到100%覆盖率用了不到4个月时间,相比之前周期缩短了30%以上。16核处理器C同样采用了KIG激励生成器,虽然微结构、指令集和芯片架构都有调整,但是由于KIG激励生成器可以迅速重用和重构之前的1 500多个测试序列,处理器C在保证基本正确性后用了仅一个月覆盖率就已经接近80%,充分体现了KIG测试库跨芯片重用带来的验证效率提升。

Figure 8 Coverage growth trend of the three processors图8 三款处理器的覆盖率收敛趋势图
图9是这三款处理器的错误收率趋势图。从图中可以看到:采用KIG验证的4核处理器B错误收敛速度明显快于基于普通激励生成器的16核处理器A,16核处理器C继承了4核处理器B的KIG测试库,在开始2个月的验证中错误收敛速度更快;从错误发现总数看,处理器核心指令集和微结构的大变化对处理器正确性验证会带来更大的挑战,而KIG激励生成器在这方面的验证效率非常高;从错误收敛周期看,采用KIG激励生成器的激励发现错误效率高,测试激励库的可继承性强,这两方面都能够有效缩短错误收敛周期;另外,16核处理器C中后期的错误收敛趋势变得比较平缓,从具体错误类型分析,主要是针对造错流程和芯片设备外接口的验证错误收敛相对较慢,后期KIG激励生成器还可以针对这方面的验证开展进一步工作。
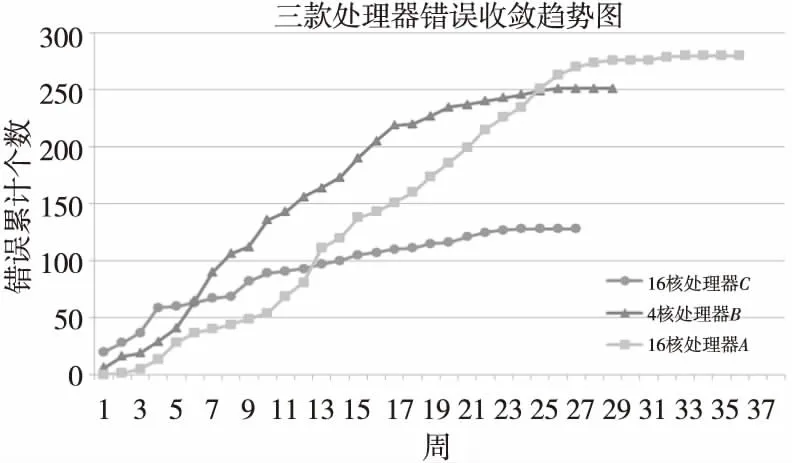
Figure 9 Sum of bugs growth trend in the three processors’ verification图9 三款处理器验证中的错误收敛趋势
综上对比分析,本文激励生成器的设计方法能够高效地根据处理器芯片架构、微结构和指令集对激励生成器进行配置,快速部署应用,尤其是测试集合能够重用和重构,大大减少了测试激励的开发量,在芯片开发初期就能够快速发现将近一半的错误,从而为FPGA原型验证和硬件仿真器验证的提早展开创造了有利条件,不仅提高了处理器芯片的验证效率,而且缩短了软硬件协同验证和软件的研发周期。
5 结束语
本文通过对处理器设计和验证的需求进行深入分析,提出了基于模型和库的六层激励生成器结构,并详细阐述了激励生成器设计中有关模型和库的实现方法,其中指令树建模方法和多维访存地址建模方法是解决处理器研发中测试集合失效问题的关键技术。基于此方法,本文设计实现了基于模型和库的国产处理器伪随机激励生成器KIG,现已经成功应用于多款不同架构的处理器验证,完全实现了测试集合的继承和持续丰富,达到良好的验证效果。
[1] Bryant R E.A methodology for hardware verification based on logic simulation[J].Journal of the ACM (JACM),1991,38(2):299-328.
[2] Taylor S,Quinn M,Brown D,et al.Functional verification of a multiple-issue,out-of-order,superscalar alpha processor—the DEC Alpha 21264 microprocessor[C]∥Proc of the 35th Design Automation Conference(DAC’98),1998: 638-643.
[3] Zhang Hang, Shen Hai-hua.Function verification of Godson2 processor[J].Journal of Computer Research and Development,2006,43(6):974-979.(in Chinese)
[4] Schubert K-D,Roesner W,Ludden J M,et al.Functional verication of the IBM POWER7 microprocessor and POWER7 multiprocessor systems[J].IBM Journal of Research .& Development,2011,55(3): 10-17.
[5] Zhu Ying, Chen Cheng,Li Yan-zhe,et al.Creation of FPGA verification platform for a high performance multiple-core microprocessor[J].Journal of Computer Research and Development,2014,51(6): 1295-1303.(in Chinese)
[6] Ludden J M,Roesner W,Heiling G M,et al.Functional verification of the POWER4 microprocessor and POWER4 multiprocessor systems[J].IBM Journal of Research .& Development,2002,46(1):53-76.
[7] Wagner I, Bertacco V, Austin T. StressTest: An automatic approach to test generation via activity monitors [C]∥Proc of the 42nd Design Automation Conference,2005:783-788.
[8] Fournier L,Arbetman Y,Levinger M.Functional verification methodology for microprocessors using the genesys test program generator: Application to the x86 microprocessors family[C]∥Proc of Design Automation and Test in Europe (DATE 99),1999:434-441.
[9] Aharon A,Dave G,Levinger M,et al.Test program generationfor functional verification of power PC processors in IBM[C]∥Proc of ACM/IEEE 32nd Design Automation Conference,1995:279-285.
[10] Lichtenstein Y,Malka Y,Aharon A.Model-based test generation for processor design verification[C]∥Proc of Innovative Applications of Artificial Intelligence (IAAI),1994:83-94.
[11] Zhang Xin, Huang Kai, Meng Jian-yi, et al.Multi-layer random stimulus strategy for microprocessor verification[J].Application Research of Computers,2010,27(4): 1284-1288.(in Chinese)
[12] Accellera. Universal verification methodology 1.1 user’s guide[M].California:Cadence Design Systems Inc,Mentor Graphics Corp.,Synopsys Inc.,2011.
[13] Hu Xiang-dong, Yang Jian-xin,Zhu Ying.Shenwei-1600: A high-performance multi-core microprocessor[J].Scientia Sinica Informationis,2015,45(4):513-522.(in Chinese)
[14] Zhang Chen-xi, Wang Zhi-ying, Zhang Chun-yuan, et al.Computer architecture[M].3rd Edition. Beijing: High Education Press,2006.(in Chinese)
[15] David P,John H.Computer architecture: A quantitative approach[M].4th Edition.San Francisco: Morgan Kaufmann Publishers,2006.
附中文参考文献:
[3] 张珩,沈海华.龙芯2号微处理器的功能验证[J].计算机研究与发展,2006,43(6):974-979.
[5] 朱英,陈诚,李彦哲,等.一款高性能多核处理器FPGA验证
平台的创建[J].计算机研究与发展,2014,51(6):1295-1303.
[11] 张欣,黄凯,孟建熠,等.一种面向微处理器验证的分层随机激励方法[J].计算机应用研究,2010,27(4):1284-1288.
[13] 胡向东,杨剑新,朱英.高性能多核处理器申威1600[J].中国科学:信息科学,2015,45(4):513-522.
[14] 张晨曦,王志英,张春元,等.计算机系统结构[M].第三版.北京:高等教育出版社,2006.
