基于回归分析的早期预警和失效预测技术
2017-12-08田从根吴长泽
田从根 吴长泽
(重庆大学计算机学院 重庆 400030)
基于回归分析的早期预警和失效预测技术
田从根 吴长泽
(重庆大学计算机学院 重庆 400030)
提前预测运行时期失效的发生对于实现系统弹性和避免失效的严重后果有重要的意义。为了能对系统失效过程预测以及实现早期预警,进而降低失效率,提高系统可靠性,提出采用回归分析法。基于错误日志记录构造错误传播签名演绎失效发生的趋势,然后通过回归分析法构造针对失效事件(是否发生)和失效时间(何时发生)的预测器,充分展现了提前预警的作用,而且在失效模式已知和未知的情况下都能正确预测失效的发生。实验结果表明其预测精度在81.4%~93.0%,平均精度高达87%,失效避免率在70%以上,有很强的优越性。
失效预测 失效模式 回归分析法 早期预警
0 引 言
预测失效是基于运行时系统的当前状态预测未来失效的发生,可以预先避免失效,或至少减轻失效的影响,把损失降到最低,(例如通过建议重新启动特定系统模块,保存数据等),因此可以提高系统的可靠性。
当前在线故障预测技术是基于在线实时观察目标系统,通过观察内部状态特定变量(例如,页面每秒的故障,I / O请求队列大小等)来收集信息,尤其是,有的故障预测算法使用过去时间里故障事件发生的信息以及现在运行状态下实时监测的系统失效前瞬间的系统变量,两者一起作为故障预测的数据。 故障预测的输出结果可以是判断即将是否会发生失效或者描绘失效发展的趋势。
现在的故障预测技术会预测故障发生的数量、产生的影响、是否失效、失效的模式,但是都没有在运行期间根据某一失效模式推演失效趋势的过程中针对某一关键状态提前做出及时预警,而且在故障模式贫瘠、不完备或者新的故障模式是未知的情况下不能很好地预测故障的发生。
本文提出的方法可以预测系统运行期间故障是否发生、何时发生以及发生的模式,而且在故障模式是否已知的情况下,都能做出很好的预测。本文利用错误历史记录构造错误传播签名,每一条日志记录对应一个时刻的签名,也代表了该系统当时的状态和发展的趋势。利用错误日志记录可以训练得到预测器,该预测器结合当前系统状态参数评估现在系统所处的健康状态,处于何种失效趋势模式下,在系统处于危险边缘时可以及时危险警告。实验证明,在故障模式库越来越完备的情况下可以更准确地预测失效的发生,在模式库贫瘠的情况下,同样可以保持优秀的预测精度。
本文的贡献在于以下三点:1) 通过错误历史记录和失效事件构造出预测器,该构造器可以预测失效发展的趋势,以及在某一关键时刻做出有效预警避免最终失效的发生;2) 在未知失效模式下也可以较准确地预测失效地发生;3) 通过逐渐完备的失效模式库可以达到更好的预测精度。
1 相关工作
一些关于故障、错误、失效的预测技术已经被很多学者所研究[1-5],失效发生时一个服务偏离其正确行为,一个错误是直接导致故障的损坏的系统状态, 故障是系统损坏的根本原因[6]。而在最近30年,对失效预测的研究比重一直在增加。
Pizza等[7]和Hamerly等[8]都使用了基于分类技术的失效预测。他们基于历史数据,把系统状态分为失效趋势状态和非失效趋势状态两类,在系统运行过程中,监视当前系统状态判断为失效或者非失效状态。该方法可以精确判断失效,但对于失效时间范围很难确定,而且失效的过程也不能推演。本文通过每个以往的错误日志文件和失效记录作为输入,使用回归分析可以模拟出失效模式,对于失效的恶化趋势可以有很直观的把控,而且建立数量充足且质量高效的模式库对于以后的失效预测有很好的提升效果。
Teerat Pitakrat[9]为了提高基于组件的软件系统可靠性,系统的组件依赖图和内部构造信息需要被描述出来。郑从环[10]使用人工神经网络模型得到预测器,文中用到的变量需要从需求文档中获得,这些变量需要专业人士识别并提取出来,此类型的数据采集和整理的过程比较复杂,最后的数据不准确或者稀少会导致预测的精度。而本文采用错误历史日志作为数据,提取简单而且数据量充足,减少了很多时间成本和经济成本,并且对预测的精度有很大帮助。
一些研究预测失效的文章基本都可以对失效的预测做出判断,但是忽略了对失效时间的研究,从而不能在合适的时刻提前预警,采取有效的措施拦截错误、避免失效。例如Pang[11]在基于计算机网络的基础上使用马尔科夫模型对软件系统的可靠性和失效预测做了一些工作,其目的是为了预测,但是却没有给出明确的时间范围来表示系统失效时刻。
2 背景知识
2.1 软件可靠性的定义
1983年美国IEEE计算机学会对“软件可靠性”作出了明确定义,该定义包括两方面的含义[13]:
(1) 在规定的条件下,在规定的时间内,软件不引起系统失效的概率;
(2) 在规定的时间周期内,在所述条件下程序执行所要求的功能的能力。
其中的概率是系统输入和系统使用的函数,也是软件中存在的故障的函数,系统输入将确定是否会遇到已存在的故障(如果故障存在的话)。
2.2 软件失效的原理
软件容错率越高,说明对失效的免疫力越强,如果失效不间断发生而且软件不能抵御失效带来的危害,那么不但对软硬件本身是一种耗损,对社会、政治、经济文化也是一种摧残。图1描述了软件失效的产生原理[14]。

图1 软件失效原理
错误(error)是指软件开发人员在软件开发阶段出现的失误、漏洞和错误。
缺陷(defect)是指产品代码中固有的错误编码,如果不修正,会引发各种失效。
故障(fault)是指软件在运行过程中出现的预料之外或者不被接受的内部错误状态,通常是由内部固有缺陷引起的。
失效(failure)是指软件运行过程中偏移了正常的需求输出,其结果是不可用的。
从以上的描述中可以看到,从各个阶段处理都可以尽量避免失效的发生,但是失效状态作为软件系统发生失效中最后的关键一环,采取合理的预测技术避免失效的发生是极其重要的。
3 早期预警以及失效预测
本节介绍预测框架的构建过程,比如如何构建错误传播签名。每个签名状态下对应的失效概率及危险系数的数理统计。如何把控合理的预警时间来避免失效。如何利用回归分析法构建失效预测器。在已知模式和未知模式两种情况下分别如何预测系统失效,以及及时预警。
3.1 构建错误传播签名
在系统运行期间,很多数据可以表明系统的性能状况,比如 CPU和内存的利用率、读写速度、网速、响应时间、栈、错误信息、错误计数等。在发生错误时,一条日志记录可以由这些信息表述,记录当时系统的状况,其中最主要的是错误分布情况,连续时间段内的几条日志记录就可以共同表示当时系统在一段期间内的健康动态,也可以表示为失效趋势。
每一条日志记录就对应一个错误传播签名,每一条日志记录可以由一个或多个错误日志变量来表示,错误日志变量表示为对系统日志中一种特定错误类型、信息或者参数的计数。
由此错误传播签名可以表示为多个错误日志变量组成的一维向量。
(1)
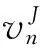
(2)
所以:
(3)
3.2 危险系数
每一个错误传播签名都对应一个失效概率,表示在该状态下运行系统发生失效的概率即危险系数,在[0,1]区间,0表示该状态下不可能会发生失效,1表示已经发生失效。
(4)
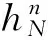
所以,在系统从开始运行产生错误日志记录1到n的过程中,错误传播签名一直在表征系统当时的运行状态,失效模式概率表示其失效严重性。
3.3 预警时间
失效模型概率可以表示系统当前失效状态的严重性,那么失效时间表示系统距离发生失效所剩余的时间,可以表示为:
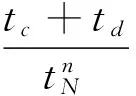
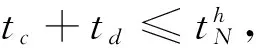

图2 预警时间图
3.4 回归分析构造预测器
回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。本文使用系统历史日志建立错误日志和失效模式之间的关系从而构造出预测器,在系统运行期间基于运行时错误日志可以分析出对应的失效模式。
设想从系统运行期间{t1,t2,…,tn}开始产生错误日志{log1,log2,…,logn},以及对应的失效状态,这些数据存储在数据库中。利用该数据实施回归分析需要以下几步:
第一,构建已知失效模式库{m1,m2,…,mM},每种模式都在系统历史中至少发生了一次。

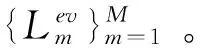

(5)

(6)

(7)
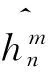
(8)
3.5 预测并预警
系统在运行期间发生失效会根据某种失效模式逐渐恶化或者好转,如果系统逐渐恶化,最终的模式趋势概率为1,会发生失效,如果逐渐好转,趋近的概率值为0,系统为正常。通过监测系统错误日志,在日志记录签名中使用累积错误计数器,可以更直观地表示系统状态。在最终状态,系统会趋于失效或者正常。在系统失效之前,必须精确地预测失效的时间,及时发出预警通知系统管理员做出处理操作或者系统本身自适应改善错误。
3.5.1 已知模式
失效模式概率可以表达系统处于失效状态的严重系数,当某一个sn状态下概率高于某阈值π∈[0,1]时,表示系统处于危险阶段,沿着该失效趋势发展下去系统被判定为失效,反之成功。该阈值可以根据特定系统实际情况自适应调整。
在系统发生失效之前,预测器判定的是系统沿着某一条失效模式发展,该过程是预测推理过程,当系统发生失效之后就可以清楚判定导致其失效的模式具体是已知模式中的某一个。

3.5.2 未知模式
基于正在发生的失效模式是已知的情况下,预测器可以有规划地进行失效预测和预警,但是当出现未知的失效模式时,必须采取其他手段处理。当系统处于sn状态时,没有可以遵从的失效模式,那么采取概率统计的方法评估系统会发生失效的概率。

当F(sn)超过一定的阈值ϑ时,即可判定系统有可能会发生失效,同时发出失效预警。失效发生后,把错误日志记录和错误事件整理训练,新的失效模式被记录下来加入已知模式库。
4 实验评估
本节主要在实际环境中进行实验对本文理论的验证,探索该论文各方面的优势和不足,主要验证失效预测精度、预测失效模型准确性、预警的效率,以及在未知模式下该预测器的性能是否保持同样优势。
初始阶段要对目标系统的历史错误日志数据采集和整理,对数据的整理要降低噪声、降维、归一化等操作可以保证错误日志和失效时间更清晰、更准确的匹配,通过回归分析法构造的预测器性能会更好。
为了保持预测器保持在很高的准确度,我们在目标系统上运行监测器捕捉运行时间段内的错误日志记录,作为预测器的输入进行预测,然后比对已发生的故障有没有被预测器正确地预测到,多报、误报、漏报都会被记录下来。所以我们通过在实际中捕捉到的失效和预测器的预测结果进行量化对比测试预测器的准确度。
如图3所示,在目标系统上运行该模型100个工作日,其预测精度在81.4%和93.0%之间。初始阶段失效模式库比较贫瘠,更多的预测是在未知模式下进行。虽然如此,依然能保持很理想的预测精度,而且随着预测器对模式的积累,失效模式库逐渐完备,后期主要依赖于已知模式对失效事件的预测。已知模式下预测精度很高,从1~100天实验期间内整体上看预测精度的趋势在逐渐上升。从图4可以看出随着时间的增长,平均预测精度逐渐增高。由此可知建立逐渐完备的模式库对于失效预测的重要性。

图3 本文模型预测精度
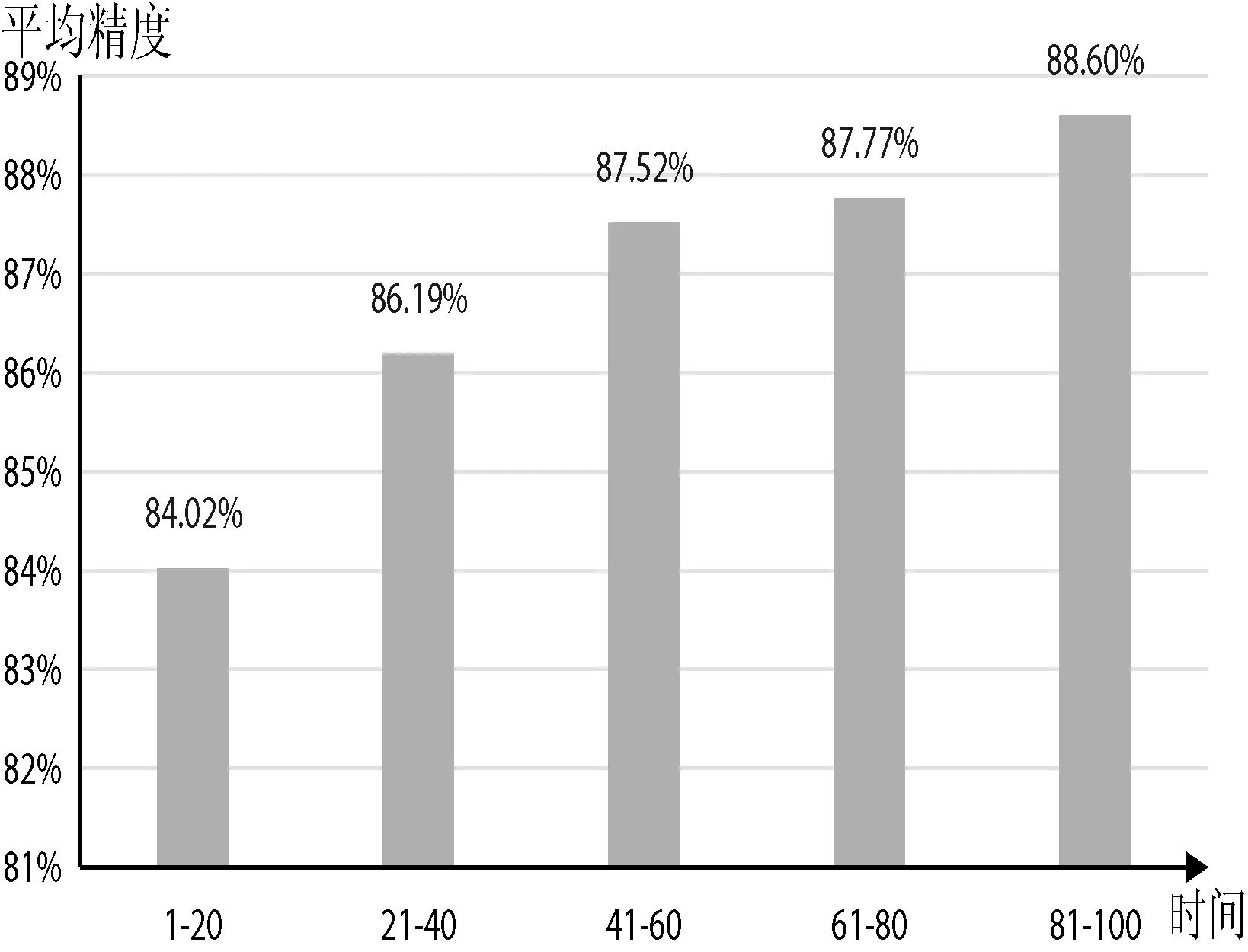
图4 随时间增长平均精度的趋势
由表1所示,1~4周时间内,预测失效计数和在无预警情况下真实发生的失效计数基本相当,表明了很高的预测精度。当真实值高于预测值,说明预测器存在漏报。当预测值高于真实值,说明存在一定的多报。当然中间也会有错报的情况,不过总体看预测精度在84%~90%之间,在4~8周,有预警系统参与的情况下,平均失效从91.25次/周降低为25.50次/周,失效避免率为72.1%,效果还是比较明显。当预警发生时,管理员或者系统本身自适应改善系统错误非常重要,而且更高效精确的预测器是对预警工作不可获取的一环。
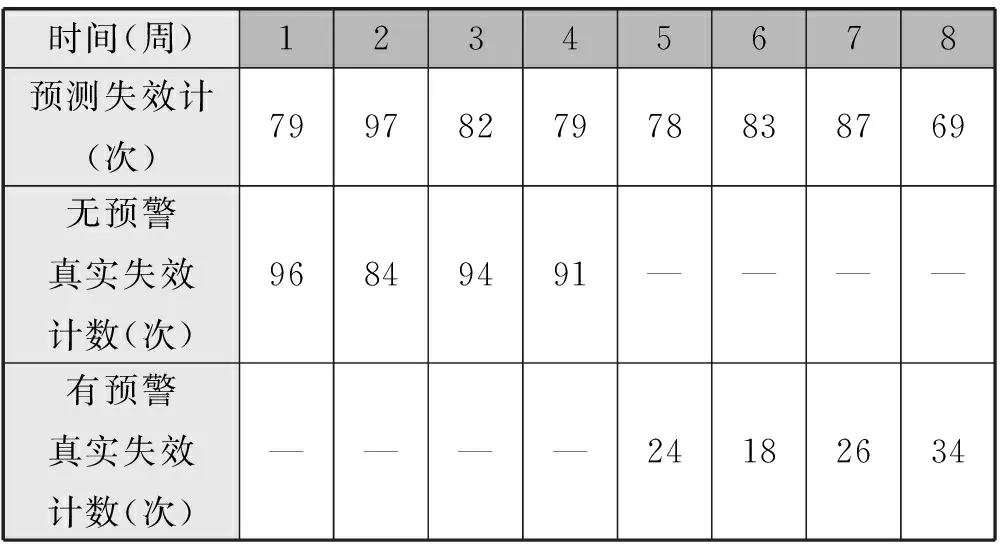
表1 有预警与无预警真实失效计数对比图
5 结 语
本文基于错误日志记录构造错误传播签名演绎失效发生的趋势,然后通过回归分析法构造针对失效事件和失效时间的预测器,充分展现了提前预警的作用,在失效模式已知和未知的情况下都能正确预测失效的发生。实验证明在失效模式库贫瘠的情况下对失效的预测精度高于84.02%,随着对模式的积累,后期平均预测精度可以达到88.60%,最高可以达到93%。已知模式和未知模式下对失效的预测达到了预期的要求,而且在预警工作方面,预警时间的把控很准,对于大部分的失效都可以有效的预警,提前避免失效发生,避免失效事件70%以上。如果合理地调控预警时间阈值,可以提升预警效果,但是会增加系统开销,浪费一些资源,所以要根据系统的具体情况合理预警。
本文的研究是基于单模式导致失效的情况,没有考虑实际中可能会存在多种模式混合导致系统失效的情况。而且错误传播签名是基于错误计数构造成一个错误状态实体,当多个错误计数稍有差别时要判断是否类属于同一种错误传播状态还需要进一步加强认知,如果判断不准确会被认为是新的未知模式发生,导致最终预测精度降低。进一步提高预测精度、精确把控预警时间、自适应改善错误是后期需要进一步补充和完善的工作。
[1] Berenji H R,Ametha J,Vengerov D.Inductive learning for fault diagnosis[C]//The 12th IEEE International Conference on Fuzzy Systems,2003,1:726-731.
[2] Ning M H,Yong Q,Di H,et al.Software Aging Prediction Model Based on Fuzzy Wavelet Network with Adaptive Genetic Algorithm[C]//2012 IEEE 24th International Conference on Tools with Artificial Intelligence (2006),2006:659-666.
[3] Pfefferman J D.A nonparametric nonstationary procedure for failure prediction[J].IEEE Transactions on Reliability,2002,51(4):434-442.
[4] Salfner F,Malek M.Using Hidden Semi-Markov Models for Effective Online Failure Prediction[C]//IEEE International Symposium on Reliable Distributed Systems.IEEE,2007:161-174.
[5] Wong K C P,Ryan H M,Tindle J.Early Warning Fault Detection Using Artificial Intelligent Methods[C]//Proceedings:31st Universities power engineering conference,Technological Educational Institute of Iraklion,Hereklion,Crete,1996:949-952.
[6] Avizienis A,Laprie J C,Randell B.Fundamental Concepts of Dependability[J].Third Information Survivability Workshop,2001,404(1-2):112-126.
[7] Pizza M,Strigini L,Bondavalli A,et al.Optimal Discrimination between Transient and Permanent Faults[C]//High-Assurance Systems Engineering Symposium,1998.Proceedings.Third IEEE International,1998:214-214.
[8] Hamerly G,Elkan C.Bayesian approaches to failure prediction for disk drives[C]//ICML ’01 Proceedings of the Eighteenth International Conference on Machine Learning,2001:202-209.
[9] Pitakrat T.Hora:Online Failure Prediction Framework for Component-based Software Systems Based on Kieker and Palladio[D].Germany:University of Stuttgart,2013.
[10] 郑从环.在线软件系统的失效预测[D].浙江:浙江理工大学,2014.
[11] Pang J.A new Markov model of reliability assurance and failure prediction using network technology[C]//International Conference on Computer Science and Network Technology.IEEE,2015.
[12] Salfner F,Lenk M,Malek M.A survey of online failure prediction methods[J].Acm Computing Surveys,2010,42(3):1283-1310.
[13] Standard I.610.12-1990 - IEEE Standard Glossary of Software Engineering Terminology[M]//IEEE standard glossary of software engineering terminology.Institute of Electrical and Electronics Engineers,1983:112-118.
[14] 乔辉.软件缺陷预测技术研究[D].解放军信息工程大学,2013.
EARLYWARNINGANDFAILUREPREDICTIONTECHNIQUESBASED
ONREGRESSIONANALYSIS
Tian Conggen Wu Changze
(CollegeofComputerScience,ChongqingUniversity,Chongqing400030,China)
It’s much important to predict the occurrence of potential failure during runtime for achieving system resilience and avoiding the dangerous consequences of failure. In order to predict the system failure process and realize early warning, and then reduce the failure rate and improve the system reliability, such that the regression analysis is proposed. In this paper, our methodology utilizes system error log records to craft runtime error-spread signature and determine a predictive function (estimator) for each failure mode based on these signatures by regression analysis method to predict the failure possibility and failure time, which fully highlight the role of early warning. And it plays with highly accurate prediction no matter in known or non-known mode. The prediction accuracy of the experimental results is stable between 81.4% and 93.0%, the average accuracy up to 87%, which show the superiority of the model is good.
Failure prediction Failure mode Regression analysis Early warning
2016-12-29。田从根,硕士,主研领域:软件可靠性,失效预测。吴长泽,讲师。
TP311
A
10.3969/j.issn.1000-386x.2017.11.010
