Native XML 数据库在电子病历存储中的应用分析
2017-11-16田昊宇
田昊宇,马 义
(1. 沈阳市20中学,沈阳 110003;2. 沈阳市回民中学,沈阳 110016)
Native XML 数据库在电子病历存储中的应用分析
田昊宇1,马 义2
(1. 沈阳市20中学,沈阳 110003;2. 沈阳市回民中学,沈阳 110016)
针对使用传统关系型数据库进行电子病历存储所存在的数据建模复杂、扩展性差、查询性能低等问题,提出了使用Native XML数据库来存储XML格式的电子病历,并以DB2 Pure XML数据库为例,在实验环境下模拟构造XML电子病历数据,分别就数据建模、查询语言、客户端开发和性能四个方面进行验证与分析。验证结果显示使用DB2进行XML数据建模结构简单、扩展性好,优于使用传统对象关系模型建模;使用基于XQuery和XPath的查询语言以及客户端开发成本不高;在性能方面,基于10.6 k的病历文件、100000数据量及有索引的情况下,查询性能可以达到0.046秒。表明Native XML数据库适合于构建电子病历的存储。
电子病历;XML;XQuery;XPath;DB2;Native XML数据库
0 引言
电子病历(EMR,Electronic Medical Record)也叫计算机化的病案系统或称基于计算机的病人记录。它是用电子设备(计算机、健康卡等)保存、管理、传输和重现的数字化的病人的医疗记录,取代手写纸张病历。它的内容包括纸张病历的所有信息[1-3]。
电子病历具有数据量大、数据类型多样、多层次结构、数据结构因人而异等特点。这种结构的灵活性和对不同类型数据要求的多样性,对基于传统关系模型的数据库管理系统软件提出很大挑战。
而XML(extensible markup language)作为一种可扩展的结构化标记语言,在描述电子病历内容方面具有以下优势:(1)XML采用了层次化面向对象的结构描述方法,非常适合于描述病历这样复杂的内容,在表达能力上优于关系数据库。(2)XML是一种元语言,可以定义描述对象的结构。这适合于病历中不同内容结构的变化,适合于保持病历的历史。(3)XML将内容与样式关联在一起,这不仅可以保留病历内容,也可保留病历外观。(4)XML作为电子商务时代的“标准语言”,拥有大量的开发和应用工具,有利于对病历内容的处理[5]。
目前各类商业数据库以及开源数据库陆续推出了支持 XML存储的功能特性,按照存储方式的不同,可以分为三类:1)以CLOB为存储单元的XML数据库;2)以对象关系表为存储单元的XML数据库;3)以XML原始文档为存储单元的XML数据库(Native XML数据库)[4]。而其中Native XML数据库以一种比较自然的方式来处理 XML数据,能够从各方面很好的支持XML数据的存储和查询,在多数场景下更具优势。为了验证对电子病历支持的有效性,本文首先介绍了Native XML数据库的特点,并选用比较有代表性的DB2 Pure XML数据库来构建电子病历实验数据集,然后分别从数据建模、查询语言、客户端开发、性能四个方面进行验证分析,从而来证明Native XML数据库支持电子病历系统的有效性。
1 Native XML数据库的特点
Native XML数据库是以原始的XML格式存储XML文档,由于保证了XML数据的层次结构,可以根据XPath路径直接定位到XML的节点,无须解析成DOM,所以查询的效率比较高。同时这种方式也消除了对 Schema的格式依赖,在相同的数据列可以保存不同类型的XML文档,灵活性比较高。Native XML数据库也具有一般数据库的特征,如:支持事务、并发控制、查询语言、安全机制、应用程序接口等[9-13]。
1.1 查询语言
XPath[7-8]和XQuery[6]是W3C推荐的针对XML文档的查询语言。目前大部分Native XML数据库产品都支持XPath,另外还有一些Native XML数据库提供专有的查询语言。XPath基于XML文档树形模型,给出从某个节点起的查询路径来搜索文档。目前,XPath作为数据库查询语言还有不少缺陷,如不能执行分组、排序、连接等操作。而 XQuery更像一种编程语言,支持循环等逻辑,支持分组、排序、连接等操作。相对于传统数据库的标准SQL语言,XQuery是一种针对XML数据查询的功能强大、易于编程的语言。
1.2 更新和删除
Native XML数据库对XML文档的更新和删除方式有许多,如:简单的替换或删除现有 XML文档,修改当前的 DOM树,以及用于指定如何修改XML文档片断的语言。
1.3 事务、锁定和并发
大多数的 Native XML数据库都支持事务,然而锁定操作通常是对整个 XML文档进行,而非对文档片断,所以对多用户并发性的支持相对较低。
1.4 应用程序接口
几乎所有的 Native XML数据库都提供编程接口,包括连接到数据库、浏览与搜索元数据、执行查询和返回结果等方法。返回结果可能是 XML字符串、DOM tree或文档的 SAX Parser(或 XML Reader)。当返回结果是多个文档时,数据库还会提供列举(iterating)这些结果的方法。
1.5 Round-Tripping
Native XML数据库的一个重要特性是为XML文档提供round-T,即用户将XML文档存人数据库后,可以再取回“同样的”文档。这对于以文档为中心的应用来说非常重要,因为 CDATA部分、实体应用、注释和处理指令是这些文档不可缺少的组成部分。
2 数据建模
使用DB2 Pure XML为电子病历数据建模比较简单,只需要建立如下数据库表,该表记录了来某医院就诊的病人详细历史信息记录,共2个字段,其中Patient_detail字段表示患者的电子病历信息,字段类型为XML,表结构如下。
表1 患者就诊信息表Tab.1 The Table of patient medical information
Patient_detail字段是以XML格式表示的患者电子病历信息,样例如下(由于 XML文件较大,此处只截取关键片段):
……
+
+
+
XML样例各节点含义说明如下:

表2 样例XML格式说明Tab.2 Sample XML format specification
从以上建模方式来看,将患者的就诊记录组织成XML层次结构保存到数据库的XML字段中,只需要建立一张数据库表。
而如果采用对象关系表来建模,通常可以采用纵向设计或横向设计。纵向的设计,即对于不同的检查项目内容保存到相同的字段中,如果明细内容差异较大,需要不断扩展表的字段来容纳就诊信息,造成对表结构的不断调整以及语义不清和数据冗余;如果采用横向设计,即对于每种检查项目明细用一张表来表示,同样需要对就诊项目明细的扩展预留字段,而且对于查询将造成多表关联,对性能产生影响。
因此关系型建模比较适合数据内容比较固定,层次结构不高的情况,而 XML的建模比较适合数据内容比较灵活,层次结构较高的情况。
3 查询语言
DB2 Pure XML使用XQuery来检索XML中的数据信息,使用XPath来定位数据节点,以下定义了几种常用操作场景来体现XQuery的特点。
场景1:根据ID号查询某位患者的病例信息。
XQUERY db2-fn:xmlcolumn('ADMINISTRATO R.PATIENT.PATIENT_DETAIL')/patient[@id='00002 94067']
场景2:查询某位患者的就诊项目编码
XQUERY db2-fn:xmlcolumn('ADMINISTRAT
场景 3:查询某位患者在某个时间段就诊过的病例信息
XQUERY db2-fn:xmlcolumn('ADMINISTRATO R.PATIENT.PATIENT_DETAIL')/patient[@id='00002 94067']/inpatient/date_of_admission[.OR.PATIENT.P ATIENT_DETAIL']/patient[@id='0000294067']/inpati ent/test_result/test/code/text() > xs:dateTime ("2011-03-10T15:04:57+08:00") and . < xs:dateTime("2017-03-30T15:04:57+08:00")] /../..;
场景4:查询得过某种疾病的所有患者列表(例如:乙肝表面抗原为阳性的病人)
XQUERY db2-fn:xmlcolumn('ADMINISTRATO R.PATIENT.PATIENT_DETAIL')/patient/inpatient/test_result/test/test_items/test_item[name="乙肝病毒表面抗原" and value="阳性"]/../../../../../name/text()
场景 5:查询进行过某项检查的患者信息(例如两对半项目)
XQUERY db2-fn:xmlcolumn('ADMINISTRATO R.PATIENT.PATIENT_DETAIL')/patient/inpatient/test_result/test[name='两对半']/../../../name/text()
场景 6:统计检查出某种疾病的患者数量(例如乙肝病毒表面抗原为阳性的患者数量)
XQUERY count(db2-fn:xmlcolumn('ADMINIST RATOR.PATIENT.PATIENT_DETAIL')/patient/inpati ent/test_result/test/test_items/test_item[name="乙肝病毒表面抗原"and value="阳性"])
XQuery汲取了其它多种查询语言的优点,适用于各种类型的 XML数据源的查询,不仅查询功能强大,而且简洁灵活且易于实现。从以上使用XQuery查询语言的各类场景可以看出,XQuery完全可以完成查询指定患者的信息、获得某种疾病的患者信息、各类统计信息的查询等各类模式匹配、过滤选择和结果构造等操作,基本可以满足电子病历各类操作的基本需求。数据库业界的三大主流厂商Oracle、IBM、Microsoft都已经在各自的产品中提供了对XQuery规范的支持。
4 客户端开发
客户端开发主要验证了使用DB2 Pure XML对客户端开发所带来的影响与改变,软件开发工具使用Eclipse 4.4,JDBC版本使用JDBC4.1,JDBC驱动程序使用 Com.ibm.db2.jcc.DB2Driver。以下代码片段实现了查询所有乙肝病毒表面抗原为阳性的所有病人信息,以列表形式返回,java验证代码片段如下:
Connection con = null;try{
Class.forName("com.ibm.db2.jcc.DB2Drive r").newInstance();
con = DriverManager.getConnection ("jdbc:db2:// IP:port/ins","user","pwd");
String query="select x.* from
administrator.patient, xmltable('$i/patient' passing patient_detail as "i" columns id varchar(40) path'@id', name varchar(40) path 'name') as x where xmlexists('$i/patient/inpatient/test_result/test/test_ite ms /test_item[name="乙肝病毒表面抗原" and value="阳性"]' passing patient_detail as "i") ";
PreparedStatement
stmt=con.prepareStatement(query);
ResultSet rs=stmt.executeQuery();
while(rs.next())
System.out.println(rs.getString(1) + " " +rs.getString(2));
}catch (SQLException e) {
……
}
}
程序执行结果如下:
0000393374 杨飞
0000392367 陈丽如
0000397648 杨文军
0000491349 李飞龙
0000283340 赵丽香
……
从以上示例代码可以看出,使用 JDBC4.1对XML进行查询开发与对关系型数据表操作差别不大,对于XML的处理在JDBC中可以将查询的XML文档以字符串的形式返回,然后在客户端可以使用dom4j等软件包进行字符串与dom的转换,也可以使用xmltable函数直接以关系表的形式返回,查询效果与关系表的查询效果一致。
5 性能
在性能验证方面,主要针对DB2 Pure XML插入数据和查询数据两方面做性能测试。
插入数据:为真实验证数据库的插入性能,我们直接采用编写存储过程,随机构造了10万条XML数据,循环插入。文件大小分别为3 K和11.6 K,目的是为了验证 XML文件的大小对插入数据的性能影响。测试时分别针对是否解析、是否有索引等情况进行。
查询数据:查询条件设置为 XML不同层级的节点,分别为2、3、4、6层级,先在没有索引的情况下进行测试,然后在有索引的情况进行测试,以此来验证索引对XML查询性能的影响。
基础环境:服务器采用2*Intel(R) Xeon(R) CPU 5130 @2.00GHz,8 GB MEM;操作系统采用Microsoft Windows Server 2008 Enterprise Edition
验证结果如表3所示。
对于插入操作,可以看出是否在插入的同时建立索引对性能影响较大,这是因为DB2使用的B树索引在插入过程中不断调整树形结构,对性能产生很大影响;而是否解析则对插入的性能影响不大,说明DB2的解析效率较高。
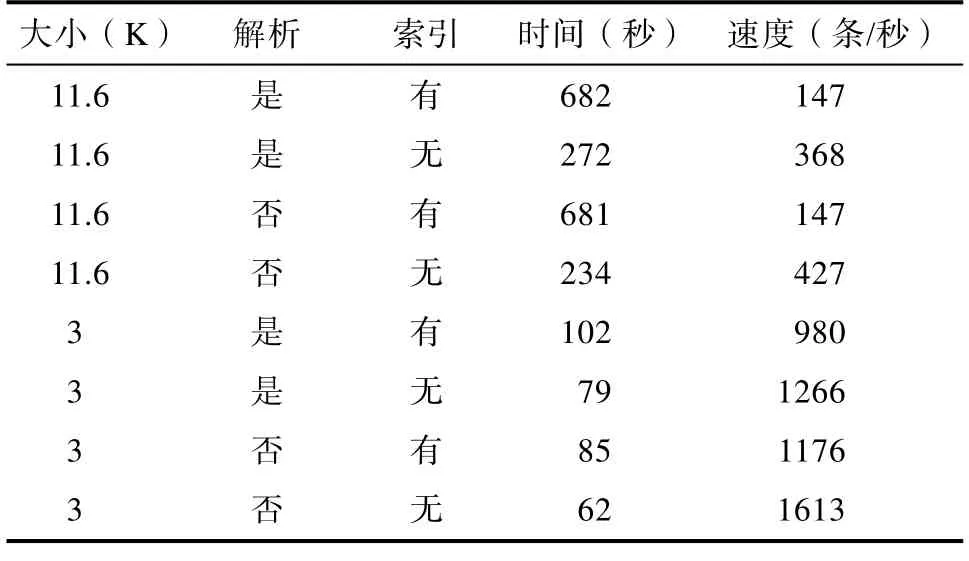
表3 100000条数据插入验证结果Tab.3 Insert validation results of 100,000 data

表4 100000条数据查询验证结果Tab.4 Query validation results of 100,000 Data
对于查询操作,可以看出有无索引的差别很大,说明建立索引对性能的提升起到很大作用;而节点的层次深度对查询时间的影响不大,体现了DB2层次型存储的优势。
6 结束语
通过以上基于DB2 Pure XML数据库进行的一系列验证可以看出,在数据建模方面,支持 Native XML的数据库结构简单、扩展性好,比基于传统对象关系表有明显的优势;查询语言方面需要了解XQuery和XPath的的相关语法后,可以实现与传统SQL一样的查询效果,学习成本不高;在客户端开发方面也比较简单,可以迅速上手;而在性能方面也拥有较好的表现。因此,在构建电子病历存储方面,使用Native XML数据库具有较好的应用前景。目前应用比较广泛的Native XML数据库除了DB2 Pure XML外,还有Oracle DB XML、Berkeley XML DB、Tamino、eXist、Xindice等都可以作为选型参考,由于各个数据库系统在具体表现上会存在差异,在实际应用前需要做进一步验证。
[1] 吴旻峰. 基于XML的电子病历系统及其院际信息共享技术研究[J]. 软件, 2013, 34(01): 106-107.
[2] 孟尹. 中医电子病历的设计与实现[D]. 山东: 山东中医药大学, 2013.
[3] 董国华, 朱习军. 中医肺病科电子病历系统设计与实现[J].软件, 2014, 35(3): 17-19.
[4] 谭照峰. XML原生数据库索引研究与实现[D]. 吉林大学,2010.
[5] 谢娜, 戚晓明, 朱洪浩, 郭有强. 半结构化多文本数据挖掘的研究[J]. 齐齐哈尔大学学报自然科学版, 2015, 31(02):75-78.
[6] 李小青, 廖湖声, 张晓博. XQuery实现技术研究综述[J].计算机科学, 2012, 39(03): 9-13.
[7] 阮娟. 基于XPath的新闻信息抽取系统设计与实现[J]. 智能计算机与应用, 2015, 5(02): 58-61.
[8] 干峰, 李超峰, 胡珊. XML数据库技术及其在医院信息系统中的应用[J]. 医学信息, 2009, 22(04): 463-465.
[9] 王鑫. 原生XML数据库存储与索引关键技术研究[D]. 南开大学, 2009.
[10] 王庆福. 网站建设中数据库技术与WEB技术的应用对比研究[J]. 软件, 2013, 34(2): 86-87.
[11] 胡芳, 沈绍武. 医疗数据集成平台的研究与设计[J]. 世界科学技术-中医药现代化, 2015, 17(04): 916-921.
[12] 张婷婷. 原生XML数据库存储模型的研究[D]. 山西大学,2012.
[13] 姚树春. Oracle数据库应用中安全问题研究[J]. 软件, 2014,35(1): 94-95.
The Application Analysis of Native XML Database in Electronic Medical Record Storage
TIAN Hao-yu1, MA Yi2
(1. Shenyang 20 middle school, Shenyang 110003,China; 2. The Huis' middle school of Shenyang, Shenyang 110016, China)
Based on the problem of traditional relational database for electronic medical records, such as data modeling of complicated, poor scalability, low query performance, put forward the use of Native XML database to store the XML format of electronic medical records, and with DB2 Pure XML database, for example, in the experimental environment simulation data of XML structure, data model, query language and client development and performance of four aspects for validation and analysis. The results show that using DB2 for XML data modeling structure is simple and extensible, which is better than modeling with traditional object relational model. Using query languages based on XQuery and XPath and client development costs are not high; In terms of performance,the query performance can reach 0.046 seconds based on 10.6 k of medical records, 100,000 data and indexes. It is shown that the use of Native XML database is applicable to the storage of electronic medical records.
: Electronic medical record; XML; XQuery; XPath; DB2; Native XML database
TP392
A
10.3969/j.issn.1003-6970.2017.10.041
本文著录格式:田昊宇,马义. Native XML数据库在电子病历存储中的应用分析[J]. 软件,2017,38(10):202-206
田昊宇(2000-),男,学生;马义,男,高级教师,研究方向:数据库系统、网络安全。
