关联挖掘算法及发展趋势
2017-11-08李忠安建琴刘海军宋奕瑶
李忠+安建琴+刘海军+宋奕瑶

摘要: 本文对关联挖掘算法进行了分析总结。首先提出了关联挖掘问题,阐述了关联规则的有关概念,然后从静态数据、动态数据和大数据等3个方面分别介绍了关联挖掘及其优化算法,指出目前關联挖掘算法存在的不足,认为弱关联分析和大数据环境下的关联算法研究将是未来的发展趋势。
关键词: 数据挖掘; 频繁项集; 关联规则; 大数据
中图分类号:TP311
文献标志码:A
文章编号: 2095-2163(2017)05-0022-04
Association mining algorithm and its development trend
Abstract:
This paper summarizes the association mining algorithms to obtain some insights on its analysis. The correlation analysis problem is put forward first before setting forth association analysis as well as its optimization algorithms from static data, dynamic data and big data. An indepth analysis on what is considered to be defect of correlation analysis mining algorithms is made, which shows the weak correlation analysis and correlation algorithm study under big data environment will be the developing trend in the future.
Keywords: data mining; frequent item set; association rules; big data
基金项目:河北省科技支撑计划项目(13210122);中央高校基本科研业务费专项资金(ZY20160106)。
收稿日期: 2017-08-19
0引言
“啤酒与尿布”的故事是关联分析中引用最多、最经典的例子,也有人提出“猪肉炖粉条”能更好地说明关联分析,无论哪个案例都旨在说明关联分析的目的是挖掘数据集中不同项之间的联系。随着电商时代和大数据时代的到来,数据挖掘技术由于能从众多数据中有效地挖掘出对人类社会有用的信息,越来越受到各行各业的青睐。关联分析方法是数据挖掘中最活跃的算法之一,被各领域用于挖掘事务之间隐含的关联性。
1关联分析问题
关联分析也称关联挖掘,是一种简单、实用的数据分析方法。从严格数学理论角度看,关联分析技术并不复杂,只要把大量数据放一起,经过运算就可以发现数据间的关联性和相关联的物理量,表明一个参数或者一组参数与事件的关系。
Agrawal等人[1]针对购物篮分析问题,在1993年提出了关联规则概念,目的是为了发现交易数据库中不同商品之间的关联性,藉此获得顾客购买商品的一般规则,从而科学地指导商家合理安排进货、管理库存、布置货架、制定商品营销策略等[2]。
其中, σ(X)表示X出现的频次,σ(X∪Y)表示X和Y同时出现的频次。
强关联规则支持度表明规则的普遍性,而置信度表示规则的可靠性。如果某个蕴含规则的支持度和置信度都满足分别给定的阈值,则称该蕴含规则为强关联规则。
Apriori定理[WT5”BZ]如果项集X是频繁项集,那么X的任一非空子集都是频繁项集。
根据上述定理,其逆否命题也成立,即:如果某个项集X不是频繁项集,那么以该项集X作为子集的任何集合都不是频繁项集。
]2静态数据关联分析挖掘算法
目前,研究关联分析挖掘算法的主要研究即是对静态数据集进行处理,这类方法可以称为静态关联分析。
2.1经典Apriori及其优化
2.1.1经典Apriori算法
Apriori算法是Agrawal和Strikant于1994年提出的第一个关联规则挖掘算法[3],能够较好地发现规则。Apriori算法的基本思想是采用从上至下逐层搜索迭代的方法,先逐次扫描数据库计算每一项出现的个数,将大于最小支持度的项作为频繁1-项集L1,在频繁1-项集L1基础上按照大于最小支持度原则生成频繁2-项集L2,依次找寻下去,直至找不到频繁k-项集Lk为止。
Apriori算法的过程包括连接和剪枝两个过程。连接指频繁(k-1)-项集集合Lk-1中每个项集中的元素按照字典排序。如果任意2个(k-1)-项集包含的前(k-2)项相同,则连接成一个候选k-项集;剪枝指将不满足最小支持度的候选项集剪去,生成频繁项集。
2.1.2Apriori算法的改进
Apriori算法不需要复杂的数学公式推导,算法实现相对简单,并且,Apriori算法在产生候选项集的时候自动进行了剪枝处理,缩小了部分冗余的候选项集,为之后的剪枝降低了开销。但是,在生成频繁项集的过程中需要多次扫描数据库,产生大量不必要的候选项集,其计算消耗的时间和内存很大。另外,对于在线数据集,项集数目边界不确定,Apriori算法已不再适用。
针对传统Apriori算法存在的不足,Park等[4]采用散列技术改进Apriori算法,提出了DHP(direct hashing and pruning)算法,主要是减少候选2-项集C2的个数,很大程度上提高了关联挖掘效率。AprioriTid_Hash算法针对DHP算法中出现的频繁项目hash地址不唯一的缺点做了优化[5];将矩阵思想引入算法中利用矩阵的优势可以减少扫描数据库的次数[6-7],但是这些改进仍需要多次扫描数据库,存在压缩矩阵不彻底、矩阵数据结构不合理等缺点。学者们在此基础上又做了进一步的优化,例如:减少了连接和剪枝过程的FIMM算法及其改进[8-9],基于矩阵压缩的改进算法[10-11],基于矩阵的数据流Top-k频繁项集挖掘算法,避免了冗余项集的产生[12];基于划分的优化是从数据库、数据预处理的角度出发,将大量的数据从逻辑上分成相互独立的集合来挖掘频繁项集[13-14];划分算法虽然支持并行挖掘计算,但是运行在单处理器上的串行算法,无法满足海量数据的挖掘性能需求,关联规则挖掘并行算法实现了多台处理器同时计算候选项集,通过有效的负载均衡提高了算法效率[15-16]。endprint
2.2FP-growth关联分析算法
2.2.1FP-growth分析算法
Apriori及其改进算法将产生大量的候选项集,并需要多次扫描数据库,导致计算量庞大,因此Han等人对Apriori算法做了改进,提出了一种发现频繁项集而不产生候选频繁项集的FP-growth算法[17]。
FP-growth算法采用分而治之策略。首先构造一颗FP树,第一次扫描数据库,找到频繁项列表L1,将其按照支持度计数递减排序;再次扫描数据库,将根节点设为null,每个事务按照频繁项列表L1中的顺序将事务中的频繁项添加到FP树的分支,并同时记录下每个项的支持度,完成该过程就可构建一颗FP树。然后在FP树上挖掘频繁模式,从频繁度最低的项开始,到频繁度最高的项挖掘频繁模式。该算法将最不频繁的项作为后缀,大大降低了搜索的开销。
2.2.2FP-growth算法改进
传统的FP-growth算法虽不需要产生候选项集,但是在挖掘频繁模式的时候需要生成条件模式和子FP树,会消耗大量的时间和空间。Li等[18]提出了一种自上而下的FP增长算法,该算法在减少搜索空間方面非常有效。将矩阵的思想引入FP-growth算法[19],只需要扫描一次数据库就可以生成关联挖掘规则,在大数据集下,降低了挖掘的时间复杂度。随着数据量的增加,串行方式已满足不了大数据集的运算需求,而且单机环境的存储能力有限,为此研究者们将FP-growth算法转移到并行计算环境中。文献[20]中提出了采用多核处理器的无锁并行方法来构建FP树的方法;文献[21]中没有像传统的FP-growth算法一样构建FP树,而是通过投影方法找到频繁项集的条件模式基础,这样避免了内存的溢出;在文献[22]中,Chen 提出了“Gridify FP-Growth”并行算法,该算法将任务分配给PC集群中的每个节点执行,缩短挖掘时间,合理利用了每台PC机的内存。
3动态数据关联分析挖掘算法
商场交易是一个动态过程,尤其是今天的电子商务,交易数据在持续不断变化中,数据量持续增加,因此在线关联分析挖掘更有意义。
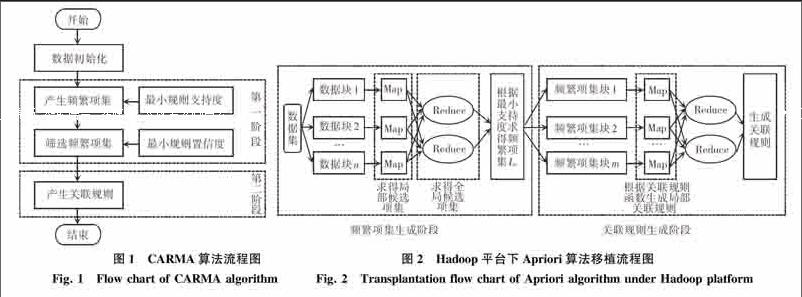
在1999年,美国Berkeley 大学的Hidber 教授提出了一种在线关联规则数据挖掘算法CARMA,具有占用内存少、在线挖掘关联规则、根据用户需要控制算法进度、保证结果精度等特点[23]。CARMA算法最多需要2次对事务序列的扫描:第一阶段扫描得到所有项集的一个超集和每个项集支持度的上下边界,第二阶段扫描通过计算每个大项集的精确支持度,并利用“前向剪枝”技术对所有的非大项集进行修剪。用户在挖掘过程中可以根据实时得到的关联规则对支持度和置信度阈值进行调整,当获得的规则满足要求,可提前停止算法[24]。左映华等人分析发现,在第一阶段元素较多的子集满足了条件,则元素较少的子集也满足条件,故在计算时只需检查元素最多的子集即可。据此,提出了一种改进的CARMA算法,计算更为快速[25],该算法流程图如图1所示。
[BT4]4大数据环境下关联分析挖掘算法
2005年,由Apache基金会所开发的分布式系统基础架构Hadoop为Apriori算法的优化提供了新的思路,许多学者对高效的单机Apriori算法如何移植到MapReduce框架下进行了相应的研究[26-27]。移植的主要思路是:将数据库划分为N个相互独立、规模相当的数据库,并将其分给M个Slave节点,执行Map任务,采用相应的改进方法得到各分块数据库的局部频繁项集;然后执行Reduce任务,得到全局候选项集,以此生成全局频繁项集;最后通过调用规则函数生成关联规则。Hadoop平台下Apriori算法移植流程则如图2所示。
Hadoop平台下的Map和Reduce任务是独立运行的,这保证了算法的高度并行化,大大提高了Apriori算法的性能。但是Hadoop平台上的Map-Reduce框架不能实现有效的迭代计算和基于内存的计算。2011年,由加州伯克利大学AMP实验室开发的Spark是一个基于内存计算的开源集群计算系统,为大规模的数据挖掘提供了理想的平台。近年来,如何在Spark平台下实现Apriori算法并行化已成为国内外学者们的研究热点[28-30],如Qiu等人[28]提出了基于Spark平台的Apriori并行算法——YAFIM算法;Rathee等人[29]在Spark平台上实现了R-Apriori并行算法,该算法消除了候选项集生成的步骤,大大降低了算法的复杂度。
虽然FP-Growth算法相对Apriori算法显著降低了时间和空间复杂度,但是对海量数据集,时空复杂度仍很高。分布式系统基础架构Hadoop的产生为FP-Growth的并行化实现提供了很好的平台,其HDFS可以部署在低廉的硬件上,适合拥有超大数据集的应用程序。而MapReduce为海量数据提供了快速的计算,将FP-Growth移植到Hadoop平台上,无疑会提高挖掘计算的速度,降低海量数据的挖掘成本。近年来学者们也致力于FP-Growth算法在云计算平台下的移植[31-33]。Spark分布式计算框架是基于内存计算的,适合超大规模数据集的挖掘,将FP-Growth算法移植到Spark平台下,会大幅度提高挖掘效率[34-35]。
5结束语
关联规则挖掘算法经过二十多年的研究与发展,经历了从单机模式到集群,从串行到并行的实现以及在云计算平台下算法的改进和移植。数据处理也从最初的事务数据库到矢量空间数据库、时间序列数据等多维数据,从静态数据分析到动态在线数据分析等,关联分析的应用领域也从最初的商业领域扩展开来,在图书推送、医疗服务、人才发现、广告的精准投放、自然灾害成因分析等领域也获得成功运用。但是,关联分析挖掘研究也存在一些问题。其一,目前关联规则的挖掘强调的是强关联性,需要大支持度和高置信度,但是在实际应用中不容易找到这种强关联规则,因此需要重新定义关联规则的形式,这样相互之间的弱关联性也许是用户感兴趣的;其二,目前基于大数据的关联分析研究和应用还处在初级阶段,而大数据发展迅猛,因此相关研究迫在眉睫,这也是关联挖掘研究的发展趋势。endprint
参考文献:
AGRAWAL R, IMIELINSKI T, SWAMI A. Mining association rules between sets of items in lagre database[C] Proc. 1993 ACM SIGMOD Int. Conf. on Management of Data. Washington DC, USA:ACM,1993:207-216.
[2] HAN Jiawei, KAMBER M. Data mining concepts and techniques [M]. 2nd ed. San Francisco: Morgan Kaufmann, 2006.
[3] AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules[C]Proc of International Conference on Very Large Databases.Santiago de Chile:[s.n.],1994: 487-499.
[4] PARK J S, CHEN M S, YU P S. Using a hash-based method with transaction trimming for mining association rules[J]. IEEE Transactions on Knowledge & Data Engineering, 1997, 9(5):813-825.
[5] 俞燕燕, 李紹滋. 基于散列的关联规则AprioriTid改进算法[J]. 计算机工程, 2008, 34(5):60-62.
[6] 李超,余昭平. 基于矩阵的Apriori算法改进[J]. 计算机工程,2006,32(23):68-69.
[7] 王柏盛,刘寒冰,靳书和,等. 基于矩阵的关联规则挖掘算法[J]. 微计算机信息,2007,24(5-3):144-145,143.
[8] 张忠平,李岩,杨静. 基于矩阵的频繁项集挖掘算法[J]. 计算机工程,2009,35(1):84-86.
[9] 张笑达,徐立臻. 一种改进的基于矩阵的频繁项集挖掘算法[J]. 计算机技术与发展,2010, 20(4):93-96 .
[10]罗丹,李陶深. 一种基于压缩矩阵的Apriori算法改进研究[J]. 计算机科学,2013,40(12):75-80.
[11]SHU S H, LIN Z Z. Algorithms of mining maximum frequent itemsets based on compression matrix[J]. Applied Mechanics & Materials, 2014, 571-572:57-62.
[12]尹绍宏,范桂丹. 基于矩阵的数据流Top-k频繁项集挖掘算法[J]. 计算机工程,2014,40(3):55-58,75.
[13]OMIECINSKI E, SAVASERE A. Efficient mining of association rules in large dynamic databases[C] BNCOD 16 Proceedings of the 16th British National Conferenc on Databases: Advances in Databases. LONDON, UK:ACM, 1998:49-63.
[14] NGUYEN S N, ORLOWSKA M E. A further study in the data partitioning approach for frequent itemsets mining[C] ADC '06 Proceedings of the 17th Australasian Database Conference . Hobart, Australia:ACM, 2006:31-37.
[15]AGRAWAL R,SHAFER J C. Parallel mining of association rules[J]. IEEE Trans on Knowledge and Data Engeering,1996,8(6) : 962-969.
[16]SHAH K, MAHAJAN S. Maximizing the efficiency of parallel Apriori algorithm[C] International Conference on Advances in Recent Technologies in Communication and Computing. Washington, DC, USA:IEEE, 2009:107-109.
[17]HAN J, PEI J. YIN Yiwen. Mining frequent patterns without candidate generation[J]. ACM Sigmod Record, 2000, 29(2):1-12.
[18]LI Haoyuan, WANG Yi, ZHABG Dong, et al. Pfp: Parallel fpgrowth for query recommendation[C] ACM Conference on Recommender Systems. Lausanne, Switzerland:ACM, 2008:107-114.endprint
[19]邓丰义, 刘震宇. 基于模式矩阵的FP—growth改进算法[J]. 厦门大学学报(自然科学版), 2005, 44(5):629-633.
[20]LIU Li, LI E, ZHANG Yimin, et al. Optimization of frequent itemset mining on multiplecore processor[C] VLDB '07 Proceedings of the 33rd international conference on Very large data bases. Vienna, Austria:ACM, 2007:1275-1285.
[21]CHEN Min, GAO Xuedong, LI Huifeng. An efficient parallel FP-Growth algorithm[C] International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery. Zhangjiajie, China: IEEE, 2009:283-286.
[22]CHEN Min. Parallel FPGrowth algorithm on PC cluster[J]. China Management Informationization, 2009,12(15):36-38.
[23]楊海廷. CARMA 算法挖掘技术在图书流通中的实证研究[J]. 图书馆杂志,2012,31(1):70-75,24.
[24]崔建,李强,杨龙坡. 基于垂直数据分布的大型稠密数据库快速关联规则挖掘算法[J]. 计算机科学,2011,38(4):216-220.
[25]左映华,高居泰,李晋宏. Carma关联规则算法的一种改进[J]. 韶关学院学报(自然科学版),2004,25(3):51-55.
[26]OTHMAN Y, OSMAN H, EHAB E. An effcient implementation of Apriori algorithm based on Hadoop—Mapreduce model[J]. International Journal of Reviews in Computing, 2012,12:59.
[27]EZHILVATHANI A, RAJA K. Implementation of parallel Apriori algorithm on Hadoop cluster[J]. International Journal of Computer Science & Mobile Computing, 2013, 2(4):513-516.
[28]QIU Hongjian, GU Rong, YUAN Chunfeng, et al. YAFIM: A parallel frequent itemset mining algorithm with Spark[C] IEEE International Parallel & Distributed Processing Symposium Workshops. Phoenix, AZ, USA:IEEE, 2014:1664-1671.
[29]RATHEE S, KAUL M, KASHYAP A. RApriori: An efficient Apriori based algorithm on Spark[C] Proceedings of the 8th Workshop on Ph.D. Workshop in Information and Knowledge Management. Melbourne, Australia :ACM,2015:27-34.
[30]牛海玲, 鲁慧民, 刘振杰. 基于Spark的Apriori算法的改进[J]. 东北师大学报(自然科学版), 2016,48(1):84-89.
[31]YANG Yong, WANG Wei. A parallel FP-growth algorithm based on Mapreduce[J]. Journal of Chongqing University of Posts & Telecommunications, 2013,25(5):651-657,670.
[32]陈兴蜀, 张帅, 童浩,等. 基于布尔矩阵和MapReduce的FPGrowth算法[J]. 华南理工大学学报 (自然科学版), 2014,42(1):135-141.
[33]ZHANG Zhenyou, SUN Yan, DING Tiefan, et al. A novel distributed parallel FPGrowth algorithm based on Hadoop framework[J]. Hebei Journal of Industrial Science & Technology, 2016,33(2):169-177.
[34]付永刚. 基于Spark的FpGrowth算法的并行化实现与优化[D]. 武汉:华中科技大学,2015.
[35]DENG Lingling, LOU Yuansheng, YE Feng. Improvement and research of FP-growth algorithm based on distributed Spark[J]. Microcomputer Applications, 2016,32(5):9-11,19.
5结束语
通过本文的研究,建立了一套比较客观的对风险进行分析和评估的方法。通过本文方法的应用,将有利于IP网络的广大从业人员更好地应对变更中的风险分析与评估,提升变更质量。
在此基础上,不但可使IP网络从业人员掌握分析评估风险的方法,更能够树立正确的风险观念,认识到风险虽然无所不在,但却可以引入研发控制的理念。通过应用正确的风险分析方法,对风险作出正确的评价。同时对风险中的主要因素实施有目的性的控制,从而有效降低整体风险水平。
参考文献:
SAATY T L. 层次分析法—在资源分配、管理和冲突分析中的应用[M]. 许树柏,等译. 北京:煤炭工业出版社,1988.
[2] 邓聚龙. 灰色系统基本方法[M]. 武汉:华中科技大学出版社,2005.
[3] ZADEH L A. Fuzzy sets[J]. Information and Control, 1965,8(3): 338-353.
[4] 王浩伦,徐翔斌,甘卫华. 基于三角模糊软集的FMEA风险评估方法[J]. 计算机集成制造系统,2015,21(11):3054-3062.
[5] 张吉军. 模糊层次分析法[J]. 模糊系统与数学, 2000,14(2):80-88.endprint
