基于综合相似度和社交标签的推荐算法①
2017-10-20时念云
时念云,张 芸,马 力
(中国石油大学(华东)计算机与通信工程学院,青岛 266580)
基于综合相似度和社交标签的推荐算法①
时念云,张 芸,马 力
(中国石油大学(华东)计算机与通信工程学院,青岛 266580)
针对传统个性化推荐方法所面临的冷启动、数据稀疏等问题,本论文结合了项目组的前期研究,在综合考虑用户特征和用户信任度的基础上,引入了用户兴趣,形成综合相似度.针对目前推荐系统中评分数据较少的问题,论文结合了社交标签,丰富了推荐数据.首先利用综合相似度,找到用户的相似近邻,并将相似近邻所标注的标签形成一个标签集.其次利用基于标签的推荐算法,产生最终的推荐列表.实验结果表明,该算法能够有效提高推荐的准确率和召回率.
用户特征; 信任度; 冷启动; 用户兴趣; 社交标签
随着互联网与信息技术的高速发展,人们已逐渐从信息匮乏时代进入到信息过载时代[1].推荐系统[2]的出现使人们能够快速找到自己感兴趣的资源.然而目前的推荐系统多是根据用户对资源或商品的评分进行相关推荐.研究显示在商业推荐系统中,用户的评分密度小于1%,造成可用于推荐的数据较稀疏,致使推荐的准确率大大降低[3].同时,大部分推荐系统需要通过分析用户历史数据,预测用户兴趣进行相关推荐,而对于新用户,推荐系统没有其历史数据,因此无法预测其兴趣,即推荐系统存在冷启动问题[4,5].可以说数据稀疏和冷启动是影响当前推荐系统准确率的两个重要因素[6].
随着Web2.0的发展,社交网站进入人们的生活,如微博和QQ等,同时也产生了丰富的标签数据和其他特征信息数据,将标签应用到推荐系统已成为新的研究方向.标签可以作为联系用户兴趣和物品的重要媒介,通过将标签集这个含有大量特征信息的数据应用到推荐系统中,在一定程度上缓解了用户物品评分矩阵的数据稀疏问题,提高了推荐质量[7].
近些年,为了解决目前推荐系统面临的上述问题,学者们提出了各种解决方法如:混合推荐、信任机制等.文献[8,9]中,利用了社交标签、信任关系等来做社会化推荐,以缓解目前推荐系统所面临的数据稀疏问题.文献[10-12]中,针对推荐系统中存在的冷启动问题,利用了简单的用户和项目的属性信息,为新用户和新项目进行预测推荐.文献[13,14]只考虑了用户或项目间的相似性,忽略了用户的兴趣相似性.文献[15]针对用户评分数据较少的问题,提出了利用协同过滤与社交网络相结合的混合推荐算法,充分利用了标注书签和朋友关系信息,在一定程度上解决了数据稀疏问题.在文献[16]提出的算法中,利用用户已声明的信任用户来构建信任网络,并结合用户评分相似度产生推荐,提高了推荐的准确率.文献[17]针对传统基于标签的推荐存在的覆盖率不足问题,提出了利用用户信任度和社交用户标注动机相结合的推荐算法.该算法考虑了用户标注动机,在一定程度上提高了推荐的覆盖率.文献[18]针对传统协同过滤算法存在的冷启动问题,提出了引入人口统计特征和信任机制的协同过滤推荐算法.该算法充分利用了用户的人口统计特征信息和信任关系,在一定程度上缓解了冷启动问题.
这些算法虽然在一定程度上缓解了数据稀疏和冷启动问题,但仍存在一定的不足,如文献[15]没有考虑用户间信任关系,准确率不高.文献[16]和文献[18]仍然存在评分数据稀疏问题.文献[17]没有考虑冷启动问题和用户兴趣相似问题.而且这些算法没有充分利用含有丰富特征信息的标签数据,同时,缺乏对用户兴趣和用户信任度等的综合考虑.事实上,在现实生活中,来自朋友的推荐有时会具有更高可信度,并且与自己背景相同的人兴趣相似的可能性更大,而这种现实关系通常也体现在社交网络中.
用户特征含有丰富的用户信息,且社交标签数据较为丰富,增大了用于推荐的数据量,本文提出的算法将两者合理结合,有效缓解了冷启动和数据稀疏问题.同时,将用户信任关系和用户兴趣考虑进来,有助于准确找到用户信任且与其兴趣相同的用户,提高推荐的准确率,减少盲目性.
1 基于综合相似度和社交标签的推荐算法
基于综合相似度和社交标签的推荐算法步骤如下.(1)计算用户特征、用户信任度和用户兴趣相似度,作为综合相似度.(2)根据综合相似度找到相似近邻,并利用相似近邻的标签形成标签集.(3)与社交标签相结合,利用基于标签的推荐算法产生推荐列表.
1.1 用户特征
用户特征即指人的年龄、性别、工作、学历、居住地和国籍等,即一般情况下用户注册时需要填写的信息[19].而这些特征对预测用户兴趣有很重要的作用,比如男性和女性的兴趣不同,不同年龄的人兴趣不同.Krulwhich设计了一个AB实验,其中一组利用用户特征推荐,而另一对照组则是利用完全随机推荐.实验结果显示,前者的用户点击率为89%,而随机算法的点击率只有27%.实验证明,利用用户特征推荐相对随机推荐能够获得更好的推荐效果[20].
本文中用到的Last.fm数据集包含了较多的用户特征,包括用户的性别、年龄和国籍等.据统计该数据集中男性用户约占3/4.数据集中用户年龄分布主要集中在20~25岁,而在0~13岁和60~100的用户相加不足1%,为提高推荐效率,我们暂不考虑.该数据集中用户主要集中在美国、德国和英国.
本文只对Last.fm数据集中用户的年龄、性别和国家等用户特征进行用户相似度度量.由于数据集中用户信息大多不是数值型,因此要对用户特征进行量化或转化为数值型,以方便计算[19].其中对国籍量化方法如下.
数据集中用户分布较多的有30个国家.这30个国家约占了用户的98%.将这30个国家分为30类,并利用1-30的数字作为量化值.
通过以上对数据集中用户的用户特征进行量化,形成了用户-特征矩阵,如表1所示.

表1 用户-特征矩阵
其中Ui为第i个用户,Fj为第j个用户特征.Pij表示第i个用户的第j个用户特征值.用户特征相似度计算方法公式如下.

因为不同用户特征对用户兴趣的影响程度不同,所以本文赋予特征相似度不同权值.公式如下:

其中SFp(a,b)为用户a与用户b的性别特征相似度,SFq(a,b)为用户a与用户b的年龄特征相似度,SFr(a,b)为用户a与用户b的国家特征相似度.其中,α∈[0,1],β∈[0,1],θ∈[0,1],且α+β+θ=1.
1.2 用户兴趣相似度
在社交网络中,用户兴趣相似度对推荐准确率影响较大.例如,我们每个人大都和自己的父母很熟悉,但是很多时候我们发现自己和父母的兴趣却极不相似,那么他们喜欢的物品就与我们有很大不同.因此在度量用户的综合相似度时还需要考虑用户兴趣相似度,而用户兴趣相似度跟两个用户喜欢物品集合的重合度有关.物品集合的重合度越高,则说明两个用户的兴趣相似度越高.
传统的用户兴趣相似度算法对于热门物品的影响没有处理.为了减小热门物品对推荐的影响,以减小用户u和用户v共同兴趣以及列表中热门物品对他们相似度的影响.本文采用了John S.Breese[21]提出的用户兴趣相似度计算公式,公式如下:
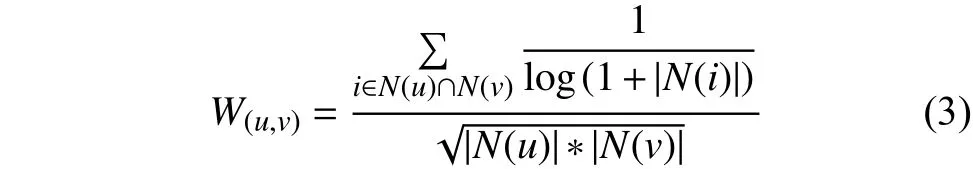
N(u)为用户u喜欢的物品集,N(v)为用户v喜欢的物品集,N(i)为用户u和用户v共同喜欢的物品集.
本文将以上用户特征相似度与用户兴趣相似度相结合,计算公式如下:
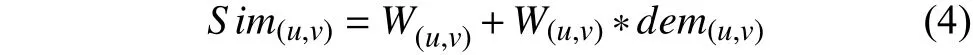
1.3 信任度度量
信任关系指在社交网站中,用户通过综合考虑自身与其他目标用户的历史记录及表现,主观判断其他目标用户在网络上所推荐信息和分享的资源是否真实安全,为用户自身购物提供一定的实际参考价值.用户对不同目标用户这种信任程度即信任度.信任度也是信任关系的量化.信任度又分为全局信任度和局部信任度[22].
全局信任度即指在整个系统中所有其他用户对某一用户的总体信任程度.在推荐系统中,用户越活跃且信任他的用户越多即信誉值越高,那么他在系统中的全局信任度则越高.本文将用户活跃度和用户信誉值作为全局信任度.
在社交标签系统中,用户活跃度与用户所标注标签个数成正相关,用户在系统中,所标注标签越多则其活跃度越高[23].用户活跃度公式如下:

其中,Act∈[0,1],q为用户对所有项目所标注标签数量,阈值Q为小于最活跃用户的标签数量和.
用户信誉值即用户在社交网络中,其他用户对该用户的整体信任值表现为用户节点的度[24].

其中,fi为节点i的度,fmax为信任网络中节点的最大度,且 Ucti∈[0,1].
用户活跃度Act和用户信誉值Ucti综合计算公式如下:

本文采用基于节点相似性方法中的Jaccard系数作为局部信任度度量方法[25].基于节点相似性方法大部分来源于复杂网络的链接预测,该类方法把共同邻居或两端节点度作为考虑属性,其中较著名的有共同邻居法和Jaccard系数法,共同邻居方法(CN)公式如下:
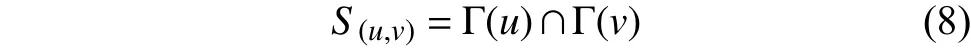
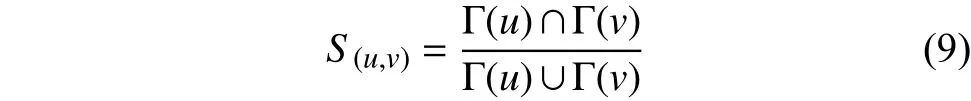
Jaccard系数方法通过对两个用户物品集进行操作,消除了物品集大小程度对用户相似性的影响.
用户在系统中的信任度是其全局信任度和局部信任度加权之和,公式如下:

将上述得到的用户相似度和用户信任度进行融合[18],公式如下:
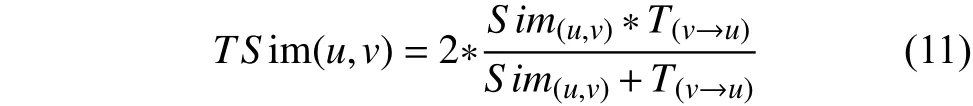
1.4 组合推荐模型
通过利用以上方法计算出综合相似度后,找到目标用户的相似近邻,并利用他们所使用的标签形成标签集,其次利用TF-IDF公式进行推荐.TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术,这个公式利用用户的标签向量对用户兴趣进行建模,其中每个标签都被用户使用过,而标签权重是用户使用该标签的次数[26].这种建模方法的缺点是给热门标签过大的权重,从而不能反映用户的个性化兴趣.因此,为了减小热门标签的权重,对热门物品进行了惩罚,推荐公式如下:
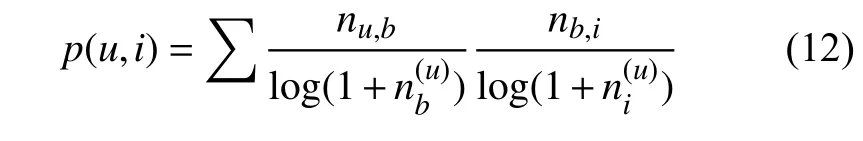
其中nu,b是用户u打过标签b的次数,nb,i是物品i被打过标签b的次数,记录了物品i被多少个不同用户打过标签.本文算法记为TFI-TP.
本文总的算法思想为:通过计算综合相似度找到目标用户信任且用户特征和兴趣相同的相似近邻,并利用他们对歌唱艺术家所打标签形成标签集,通过利用标签推荐方法将目标用户可能喜欢的歌手形成最终推荐列表,推荐给目标用户.
2 实验结果及其分析
2.1 数据集
本文使用的数据来源于Last.fm数据集,该数据集包含了2100个用户的18万条信息,18745名歌手,11947个标签.平均每个用户有12.5个朋友,有13个标签.Last.fm是一个著名的音乐网站.为了更好地服务用户,在不进行复杂音频分析的情况下获取音乐内容,并为用户快速找到其可能喜欢的歌手,Last.fm引入了UGC标签系统,方便用户利用标签标记歌手.实验将随机选取数据集的90%作为训练集,10%作为测试集.
2.2 度量标准
本文采用推荐系统常用的评测指标即准确率和召回率[27].准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率.召回率是指检索出的相关文档数和文档库中所有相关文档数的比率,衡量的是检索系统的查全率.
2.3 参数实验及结果分析
因为以上公式含有未知参数,所以应先确定未知参数的值.在计算用户特征相似度时即公式(2),出现了α,β,θ等三个未知参数,用来衡量特征权重.因为α+β+θ=1,所以只需确定α、β的值.取邻居用户 N 为5时,λ为0.6时,α以步长为0.1,β步长为0.2进行实验.实验结果如下.
由图1可知,当α为0.1,β为0.3时准确率最高.从α、β值可以得出,当预测用户对音乐的兴趣时,用户性别对用户的喜好影响较小,而用户年龄对用户影响稍大,用户国籍对用户的影响比用户年龄和性别特征影响都大.这也证实了语言不同,文化背景不同,用户对音乐的喜好不同.例如中国的年轻人和美国的年轻人所喜爱的音乐有很大差异.
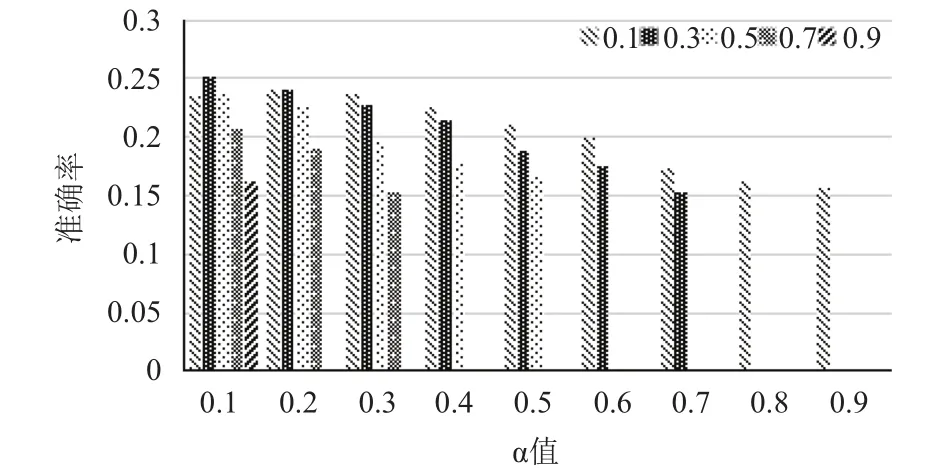
图1 不同α、β值下的准确率
全局信任度和局部信任度对用户信任度的影响程度确定即λ的确定,其中λ的取值为[0,1].本文将λ的值以步长0.1进行取值,实验结果如图2.

图2 λ取不同值时的准确率和召回率
由图2可知当λ取0.6时,准确率达到最高,而此时的召回率比λ取0.5时有所下降.为了提高准确率,本文选取λ为0.6.其中λ为0时为没有考虑全局信任度得情况,而λ为1时为没有考虑局部信任度的情况.
由于向目标用户推荐的标签集是由用户近邻标签所组成,因此近邻的个数也将影响推荐效率.为此我们取近邻个数N为不同值,实验结果如图3.

图3 近邻数量N取不同值时的实验结果
由图3可知,当N小于5时准确率和召回率都在逐渐升高,而当近邻数量大于5时准确率和召回率,则越来越低.这是由于标签集数量过大,使得准确找到能够预测用户兴趣的标签的难度也随之增大.
为了对比改进前后算法的效率,将基于用户特征相似度的社交标签推荐算法标记为F-TP,将基于用户信任度的社交标签推荐算法标记为T-TP,将基于兴趣相似度的社交标签推荐算法标记记为I-TP,将基于用户信任度和用户特征的社交标签推荐算法标记为TFTP,本文算法记为TFI-TP.算法效果对比图如下.
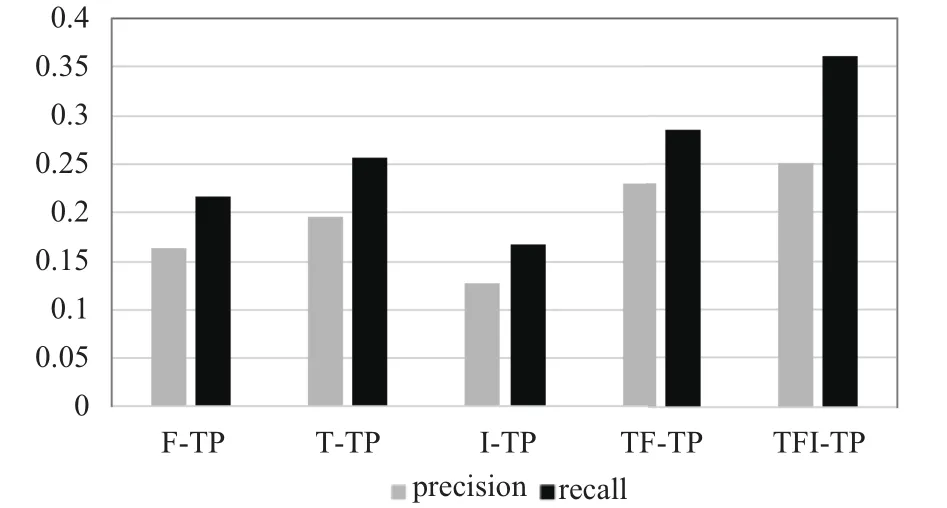
图4 不同算法的实验结果对比图
通过对以上实验结果分析可以得出以下结论:传统只考虑用户兴趣的I-TP算法准确率较低.而考虑用户特征的F-TP推荐算法准确率和召回率都较I-TP有了提高,这是因为特征相同的用户,所喜爱的音乐相似性较大.而考虑用户信任度的T-TP算法相较于前两个算法有了提高,这与日常生活中人们比较相信有较好信誉的人有关,这也体现在网络中[28].而融合了用户特征和用户信任度的TF-TP算法,在准确率和召回率上比前三个算法都有所提高,这是因为用户比较信任那些来自与自己特征相似度和信任度都较高的用户的推荐.同时,实验结果显示,本文提出的TFI-TP推荐算法较其他算法推荐效果更佳.
本文提出的TFI-TP算法其准确率和召回率都有所提高的原因在于同时考虑了用户特征信息和社交标签,使得冷启动问题和数据稀疏问题得到了缓解.由于传统推荐系统对无任何历史记录的新用户的推荐是盲目的,这大大降低了推荐准确率,而冷启动问题的解决将有效提高推荐准确率.丰富的社交标签数据为推荐系统提供了足够的数据集用于分析用户兴趣,解决了由于评分数据稀疏而带来的准确率低的问题.同时,TFI-TP算法将用户信任度考虑进来,提高了用户对推荐资源的信任度,而将用户兴趣考虑进来,减少了推荐的盲目性,提高了推荐召回率.
3 结语
本文提出的TFI-TP算法引入了用户特征信息、用户信任度和用户兴趣,利用用户特征和用户兴趣所形成的相似度,并结合信任度形成综合相似度确定邻居用户,利用邻居用户的标签集结合标签推荐方法,进而产生最终的推荐结果.实验结果表明,用户特征和用户信任度的引入过滤掉了不符合用户兴趣且用户不太信任的资源,缓解了冷启动问题,提高了推荐的质量.将用户兴趣考虑进来,使得目标用户的兴趣更加明确,提高推荐准确率.将社交标签引入到TFI-TP算法中来,充分地利用了丰富的标签数据,缓解了数据稀疏问题.实验结果说明,本文提出的TFI-TP能够有效缓解冷启动问题和数据稀疏问题.
社会的进步发展,人们对于推荐系统的要求更高.如根据用户情感变化、地理位置、时间因素等进行相关推荐,这也是以后研究的方向.另外,本文没有考虑用户标注标签时间,希望以后有机会能在这方面继续学习和探索.
1易明,邓卫华.基于标签的个性化信息推荐研究综述.情报理论与实践,2011,34(3):126–128.
2Resnick P,Iacovou N,Suchak M,et al.GroupLens:An open architecture for collaborative filtering of netnews.Proc.of the 1994 ACM Conference on Computer Supported Cooperative Work.New York,NY,USA.1994.175–186.
3Gunawardana A,Meek C.Tied boltzmann machines for cold start recommendations.Proc.of the 2008 ACM Conference on Recommender Systems.New York,NY,USA.2008.19–26.
4Gunawardana A,Meek C.A unified approach to building hybrid recommender systems.Proc.of the 3rd ACM Conference on Recommender Systems.New York,NY,USA.2009.117–124.
5Park ST,Chu W.Pairwise preference regression for coldstart recommendation.Proc.of the 3rd ACM conference on Recommender systems.New York,NY,USA.2009.21–28.
6李春,朱珍民,叶剑,等.个性化服务研究综述.计算机应用研究,2009,26(11):4001–4005,4009.[doi:10.3969/j.issn.1001-3695.2009.11.001]
7Kim HN,Ji AT,Ha I,et al.Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation.Electronic Commerce Research and Applications,2010,9(1):73–83.[doi:10.1016/j.elerap.2009.08.004]
8Wang D,Ma J,Lian T,et al.Recommendation based on weighted social trusts and item relationships.Proc.of the 29th Annual ACM Symposium on Applied Computing.New York,NY,USA.2014.254–259.
9Wu L,Chen EH,Liu Q,et al.Leveraging tagging for neighborhood-aware probabilistic matrix factorization.Proc.of the 21st ACM International Conference on Information and Knowledge Management.New York,NY,USA.2012.1854–1858.
10Agarwal D,Chen BC.Regression-based latent factor models.Proc.of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Paris,France.2009.19–28.
11Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms.Proc.of the 10th International Conference on World Wide Web.New York,NY,USA.2001.285–295.
12Kim BM,Li Q,Kim JW,et al.A new collaborative recommender system addressing three problems.Proc.of the 8th Pacific Rim International Conference on Artificial Intelligence.Auckland,New Zealand.2004.495–504.
13李聪,梁昌勇,董珂.基于项目类别相似性的协同过滤推荐算法.合肥工业大学学报(自然科学版),2008,31(3):360–363.
14Xia WW,He L,Ren L,et al.A new collaborative filtering approach utilizing item’s popularity.Proc.of IEEE International Conference on Industrial Engineering and Engineering Management.Singapore.2008.1480–1484.
15李琦.基于社交网络好友信任度的个性化推荐系统研究[硕士学位论文].哈尔滨:哈尔滨工业大学,2014.
16任磊.推荐系统关键技术研究[博士学位论文].上海:华东师范大学,2012.
17何波.基于社交用户信任度和标注动机的标签推荐系统研究[硕士学位论文].重庆:重庆大学,2015.
18时念云,葛晓伟,马力.基于用户人口统计特征与信任机制的协同推荐.计算机工程,2016,42(6):180–184.
19布海乔.基于用户评分和用户特征的混合协同过滤算法研究[硕士学位论文].天津:天津师范大学,2015.
20项亮.推荐系统实践.北京:人民邮电出版社,2015:44–60.
21Breese JS,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering.Proc.of the 14th Conference on Uncertainty in Artificial Intelligence.Madison,Wisconsin,USA.1998.43–52.
22Ziegler CN,Lausen G.Spreading activation models for trust propagation.Proc.of the 2004 IEEE International Conference on e-Technology,e-Commerce and e-Service.Washington,DC,USA.2004.83–97.
23吴慧,卞艺杰,赵喆,等.基于信任的协同过滤算法.计算机系统应用,2014,23(7):131–135.
24刘迎春,郑小林,陈德人.信任网络中基于角色信誉的信任预测.北京邮电大学报,2013,36(1):72–76.
25张富国.基于社交网络的个性化推荐技术.小型微型计算机系统,2014,35(7):1470–1476.
26Social Media.Social media accounts for 22% of time spent online.http://www.webpronews.com/social-networks-blogsaccount-for-22-of-time-spent-online-2010-06/.[2016-05-10].
27Herlocker JL,Konstan JA,Terveen LG,et al.Evaluating collaborative filtering recommender systems.ACM Trans.on Information Systems,2004,22(1):5–53.[doi:10.1145/963770]
28Sinha R,Swearingen K.Comparing recommendations made by online systems and friends.Proc.of the DELOS-NSF Workshop on Personalization and Recommender Systems in Digital Libraries.Dublin,Ireland.2001.1–6.
Recommendation Algorithm Based on Synthetic Similarity and Social Tag
SHI Nian-Yun,Zhang Yun,MA Li
(College of Computer and Communication Engineering,China University of Petroleum,Qingdao 266580,China)
The traditional methods of personalized recommendation are faced with the problems of sparse data and cold start.This paper combines the previous research of the project team and introduces the user interest to form the comprehensive similarity,based on the comprehensive consideration of user characteristics and user trust degree.At the same time,this paper uses the social tags which enrich the recommendation data to solve the problem of sparse data in current recommendation system.Firstly,the similarity degree is used to find the similar neighbors of the users and form a tag set by labeling the similar neighbors.Secondly,a tag-based recommendation algorithm is used to generate the final recommendation list.The experimental results show that the proposed algorithm can effectively improve the accuracy of recommendation and the recall rate.
user characteristics; trust degree; cold start; user interest; social tag
时念云,张芸,马力.基于综合相似度和社交标签的推荐算法.计算机系统应用,2017,26(10):178–183.http://www.c-s-a.org.cn/1003-3254/6025.html
2017-01-16; 采用时间:2017-02-26
