一种自适应变换在图像编码上的应用
2017-09-29林文浩
林文浩


摘 要:为节省有限的存储资源及传输带宽,高效的图像编码方案尤为重要。KLT是Karhunen-Loeve Transform的缩写,具有最理想的能量聚集特性,变换核基于源数据统计特性计算得出,可以适应图像多样性。JPEG 全称Joint Photographic Experts Group(联合图像专家小组),是第一个国际图像压缩标准,因其高效的编码性能且易于实现而被广泛应用。JPEG图像变换编码采用DCT(Discrete Cosine Transform)。DCT是固定核,不适应图像的多样性,在图像编码上有一定局限性。为此,提出了一种更为有效的变换方法——KLT与DCT自适应变换,有效利用了图像的统计特性,提高了编码性能。经验证,该方法比主流的JPEG图像编码标准性能提高3.1%。
关键词:JPEG;变换编码;DCT;KLT;编码性能
DOI:10.11907/rjdk.171268
中图分类号:TP317.4 文献标识码:A 文章编号:1672-7800(2017)009-0192-03
Abstract:In order to save limited storage resources and transmission bandwidth, efficient image coding method is very important. KLT is the abbreviation of Karhunen-Loeve Transform, which has the best energy compaction characteristics. The transform kernel of KLT is calculated based on the statistical properties of the source data and can be adapted to the image diversity. JPEG (Joint Photographic Experts Group), is the first international image compression standard.Because of its efficient coding performance,easy to implement and widely used,JPEG image transform coding using DCT (Discrete Cosine Transform). DCT is a fixed kernel, not to adapt to the diversity of images, which has some limitations on image coding. A more effective transformation method-KLT and DCT adaptive transform is proposed, which effectively utilizes the statistical characteristics of the image and improves the coding performance. It is proven that the performance of this method is 3.1% higher than that of the mainstream JPEG image coding standard.
Key Words:JPEG; transform coding; DCT; KLT; coding performance
0 引言
变化编码是图像视频编码的重要步骤,原理是把图像数据从时域转换到频域,使图像的大部分信息聚集在低频,也就是能量聚集性[1]。经过后续量化处理,去除高频少量信息,设置合适的量化参数,熵编码后数据比原始数据大大减少,经解码后觉察不到信息损失,与原图像差别不大。KLT具有理想的能量聚集特性,是其它变换编码性能的评判标准[2],在变换编码应用上一直是研究热点。一般来说,KLT要在编码时变换核,开销较大,且没有快速算法,所以使用受到限制。DCT是固定变换核,有相应的快速算法,且能在Markov-1模型下接近KLT[3],成为目前应用最广泛的变换编码。并非所有图像符合Markov-1模型,现实世界中符合Markov-1模型的图像大概只有50%[4]。
如何将KLT应用在图像视频编码系统是众多研究者致力解决的问题[3-9]。茅一民、高西奇[5]用一类典型的指纹图像样本训练KLT矩阵;方凌江等[6]对高光谱图像进行无监督分类,针对波段对每一类进行KLT;牛万红等[7]根据KLT在多光谱遥感图像中的应用原理,分别设计了大分块KLT算法和小分块KLT算法;Matthias Kramm[8]基于分类KLT在群体图像编码上的应用,Miaohui Wang等[9]在H.264中对采样训练KLT矩阵,使编解码端计算出一致结果,避免了KLT变换核的编码传送而造成的额外开销;Moyuresh Biswas等[10]采用运动补偿块平移,旋转计算KLT变换核,同样避免了KLT变换核的编码。
本文提出了一种在图像上应用KLT自适应变换编码方法,有效运用KLT特性,避免了编码KL变换核带来的额外开销,显著提高了图像编码性能。
编码流程:首先采集大量樣本图像,然后对图像的每个块分类,把相同类的块聚集,训练KLT变换核。在图像编码系统中,编码块自适应选择相应类的KLT或DCT进行变换编码。图1是编码系统流程。
1 分类方法
本文采用的分类方法是一种类H.264帧内预测简化方案。H.264的帧内预测是根据当前块的左邻块与上邻块预测方向[11],而JPEG没有帧间预测。KLT是一种基于数据统计特性的变换,本文利用块的自身数据进行分类,能有效应用于KLT。endprint
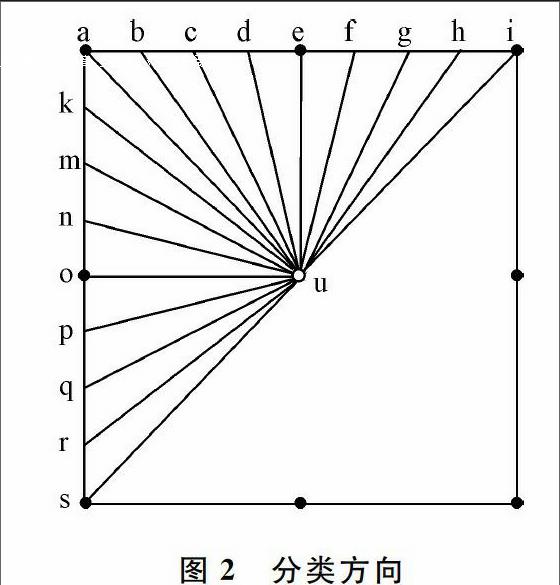
如图2所示,中间的白色点是当前像素点,四周8个黑色点是其邻近点,对于边缘块,不存在的邻近点用像素值的量级平均值,即128代替。按照图示的16个方向分类。用邻域点及邻域插值点(也就是不在整像素上的点,如b、c、d)来估算当前点u的值。估算方法:如s-i方向,u′ = (s+i)/2。为了方便,本文将这种估算称作预测。插值点(如b、c、d)像素值用相邻整像素a、e插值计算得出,离整像素越近权值越大。
c = 1/2a + 1/2e;
d = 3/4a + 1/4e;
d = 1/4a + 3/4e。
其它非整像素值f、g、h、k、m、n、p、q、r用相同方法算出。在某个方向上预测块的所有像素点,16个方向都预测之后,使用MSE(Mean squared error)算法选择最接近原始块的方向作为块的类。
2 KLT变换核训练
2.1 KLT原理
KLT是对向量x做的一个正交变换:y=ΦTx,目的是变换到y后去除数据相关性。其中,ΦT是x特征向量组成的矩阵,满足ΦTΦ=I。当x都是实数时,ΦT是正交矩阵[12-14]。
用mx、my分别表示向量x、y的平均值,x、y的协方差矩阵分别记为∑x,∑y,y的协方差计算方法见式(1):∑y=E(yyT)-mymTy
(1) 将y=ΦTx带入式(1),推导得:∑y=E[(ΦTx)(ΦTx)T]-(ΦTmx)(ΦTmx)T
=E[ΦT(xxT)Φ]-ΦTmxmTxΦ
=ΦT[E(xxT)-mxmTx]Φ
=ΦT∑xΦ
(2) 要使∑x对角化,矩阵ΦT由∑x的特征矢量组成,接下来求∑x特征值及特征向量。完成KLT变换后,∑y成为对角阵,也就是对于任意i≠j,有cov(xi,yj)=0;当i=j时,有cov(xi,yj)=λi,去除数据相关性。yi的方差σ2i与x协方差矩阵的第i个特征值相等,即σ2i=λi。
2.2 KLT训练
本文利用块的方向特性训练KL变换核。训练样本的每个块分类之后,每个类都是含有若干块的集合,每个集合都看作相同维度的矩阵,按照KLT原理,计算矩阵协方差,使协方差对角化,即去除了编码块各个像素之间的相关性。根据矩阵理论,矩阵对角化就是求矩阵的特征值和特征向量,为了变换域能量分布量化方便,这些特征值按从大到小顺序排列,特征向量按照特征值顺序排列,得到一个正交矩阵T,这个矩阵就是KL变换核。使用相同方法,计算出所有类的KL变换核。KLT计算复杂,但整个训练过程并不在编解码过程中,所以不会对编解码速度产生影响。这样得到的是浮点KLT,将其缩放取整,可在变换编码时保证精度,提高运算速度。
3 自适应变换编码
在JPEG标准中,DCT采用可分离变换,即先进行(列)变换,再进行列(行)变换。Y=M·X·MT,M·MT=I
(3) Y为变换系数,X为源数据,M为可分离DCT矩阵,MT为M的转置,I为单位矩阵。本文KLT采用不可分离变换:Y=KX
(4) K为不可分离的KLT。但是不可分离的变换矩阵要比可分离矩阵大很多。比方说一个大小为N×N的可分离矩阵,对应的不可分離矩阵大小会达到N2×N2 。
按照常规方法使用KLT时,先计算块的分类,用相应的KLT变换核进行变换编码。这种方法弊端很大,块的分类信息需要编码,总共有16个类,每个块的分类需要4比特编码,以便解码端用相应的KLT变换核解码。相对固定核DCT来说,每个块多编码4比特,很可能使结果产生负增益。
图像的相邻块往往相关性很高,完全可以考虑从相邻块获取分类信息。编码时不能直接从相邻块获取分类信息,因为解码出的图像与原始图像存在误差。为了保持编解码端的一致性,在编码一个块后继而重构这个块,作为下一个块的分类依据。用预测分类相应的KL变换核对下一块进行变换编码,但这样预测得到的分类比较粗略,不能保证是否最适合KL变换核,也不能保证比DCT有更好的编码性能。考虑到这一点,利用RDO(Rate Distortion Optimization)从KLT和DCT中选择表现最佳者进行变换编码。RDO公式见式(5): J=D+λ·R
(5) J为率失真代价,D为块失真,R为块编码比特数,λ为拉格朗日系数。失真就是重构图像与原始图像的偏差,用MSE计算,见式(6):D=1N∑Ni=1(xi-x′i)2
(6) N为像素数,xi为原始数据,x′i为重构数据。失真越小,重构图像与原始图像偏差越小, D值就越小。较小的失真往往需要更多比特,RDO权衡了失真和比特率,是一种评价图像视频编码性能的主流方法。比较失真代价,如果JKLT 4 重构 图像解码是编码的反过程,也可以称作图像重构。图像编码后的大小及解码后对原图像的复原度是评价图像编码性能的重要指标,两者很难同时达到要求。BD-Rate是综合这两个因素判断图像编码性能的一个重要算法[16-17],本文实验采用这种方法。 本文的编码系统用到了重构过程,每个块在量化之后,进行反量化、反变换得到重构块,作为下一个块的分类依据。在解码系统中,根据解码信息确定使用DCT或KLT反变换。 5 实验结果 本文的编解码系统除了变换编码,其它部分均与JPEG标准相同,测试样本及训练样本为标准序列,均来自于网络[10],样本命名为kodim01~24。前7张图像序列kodim01~07作为测试样本,后面17张图像序列kodim08~24为训练样本。表1是自适应变换,以JPEG为参考的BD码率和PSNR的比较结果。
从结果可以看出,本文应用的KLT自适应变换编码比目前主流的图像编码标准JPEG在性能上有明显提升。
6 结语
本文训练了大量图像序列以获得适应各种统计特性的KLT,在变换编码时利用相邻块的相关性巧妙避免了分类信息的编码,从而避免了大量码流开销,并自适应选择表现最佳的变换。从实验结果看,本文的自适应变换比固定DCT有明显的改善。
参考文献:
[1] R C GONZALEZ, R E WOODS.Digital image processing [C].Addison-Wesley Publishing Co, Boston, MA,1992.
[2] 翁默颖,奚宁.使用K-L变换进行图像压缩的一种新方法[J].华东师范大学学报:自然科学版,1996(3):63-71.
[3] R J CLARKE.Relation between the karhunen-loève and cosine transforms[J].Proc Inst Electr Eng F, 1981,128(6):359-360.
[4] TORRES-URGELL L, KIRLIN R L. Adaptive image compression using karhunen-loeve transform[J]. Signal Processing, 1990,21(4):303-313.
[5] 高西奇,茅一民.基于KLT的指纹图像压缩[J].通信学报,1994(1):113-115.
[6] 方凌江,粘永健,王迎春.基于分类KLT的高光谱图像压缩[J].计算机技术与发展,2013(11):82-85.
[7] 牛万红,赵静,葛永斌.基于K-LT的高分辨率图像的分块算法[J].济南大学学报:自然科学版,2014(3):198-203.
[8] KRAMM A M. Compression of image clusters using karhunen loeve transformations[J]. Proc Spie, 2007(6492):101-106.
[9] WANG M, NGAN K N, XU L. Efficient H.264/AVC video coding with adaptive transforms[J]. IEEE Transactions on Multimedia, 2014,16(4):933-946.
[10] BISWAS M, PICKERING M R, FRATER M R. Improved H.264-based video coding using an adaptive transform[C]. IEEE International Conference on Image Processing. IEEE, 2010:165-168.
[11] TEW Y, WONG K S. An overview of information hiding in H.264/AVC compressed video[J]. Circuits & Systems for Video Technology IEEE Transactions on, 2014, 24(2):305-319.
[12] MAYCOCK J, ELHINNEY C P M, MCDONALD J B, et al. Independent component analysis applied to digital holograms of three-dimensional objects[J]. Optical Information Systems III, 2005(5908):42-50.
[13] ZENG R, WU J, SHAO Z, et al. Color image classification via quaternion principal component analysis network[J]. Neurocomputing, 2015(216):416-428.
[14] SHI J, SONG W. Sparse principal component analysis with measurement errors[J]. Journal of Statistical Planning & Inference, 2016(175):87-99.
[15] WALDEMAR P, T A RAMSTAD.Hybrid KLT-SVD image compression[C]. IEEE International Conference on Acoustics, 2007:79-89.
[16] WANG Q, JI X, DAI Q, et al. Free viewpoint video coding with rate-distortion analysis[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2012, 22(6):875-889.
[17] M KARCZEWICZ, Y YE, I CHONG. Rate distortion optimized quantization[C].document VCEG-AH21, ITU-T Q.6/SG16 VCEG, Antalya,Turkey,2008.
[18] KODAK.Kodak lossless true color image suite[EB/OL].http://r0k.us/graphics/kodak/.
(責任编辑:杜能钢)endprint
