动态标签匹配DLMS调度器设计与实现
2017-09-29毛韦竹翠
毛韦 竹翠


摘 要:针对Hadoop集群节点性能差异大、资源分配随机、执行时间过长的问题,提出一种将节点性能标签(简称节点标签)和作业类别标签(简称作业标签)进行动态匹配的调度器。节点初始分类并赋予原始节点标签,节点检测自身性能指标生成动态节点标签,作业根据部分运行信息进行分类并生成作业标签,资源调度器将节点资源分配给对应标签的作业。实验结果表明,相对于YARN中自带的调度器,其在作业执行时间上有很大缩短。
关键词:Hadoop;资源调度器;动态匹配;动态标签
DOI:10.11907/rjdk.171392
中图分类号:TP319 文献标识码:A 文章编号:1672-7800(2017)009-0095-05
Abstract:In order to solve the problem of big performance difference, random resource allocation, and long time execution in Hadoop cluster nodes,this paper propose a scheduler which allocates the Node Performance Label(NPL) and Job Category Label(JCL) dynamically.The node makes the classification of initialization and is assigned original node label. The node detects its own performance metrics to generate dynamic node labels. The job is classified based on part of the run information to generate the job label. The resource scheduler assigns the node resource to the corresponding label job. The experimental results shows that the scheduler has a certain degree of shorten in the time of job execution compared with one that comes with YARN.
Key Words:hadoop; scheduler; dynamic matching; dynamic label
0 引言
早期Hadoop版本由于將资源调度管理和MapReduce框架整合在一个模块中,导致代码的解耦性较差,不能较好地进行扩展,不支持多种框架。Hadoop开源社区设计实现了一种全新架构的新一代Hadoop系统,该系统为Hadoop2.0版本,将资源调度抽取出来构建了一个新的资源调度框架,即新一代的Hadoop系统YARN。众所周知,在某一确定的环境下,合适的调度算法能够在满足用户作业请求的同时,有效提升Hadoop作业平台的整体性能和系统资源利用率。在YARN中默认自带3种调度器:先入先出(fifo)、公平调度器(Fair Scheduler)和计算能力调度器(Capacity Scheduler)。Hadoop默认采用fifo调度器,该算法采用先进先出的调度策略,简单易实现,但是不利于短作业的执行,不支持共享集群和多用户管理;由Facebook提出的公平调度算法考虑了不同用户与作业资源配置需求的差异,支持用户公平共享集群的资源,但是作业资源的配置策略不够灵活,容易造成资源浪费,并且不支持作业抢占;雅虎提出的计算能力调度算法支持多用户共享多队列,计算能力灵活,但是不支持作业抢占,易陷入局部最优[1-2]。
然而在企业生产中,随着企业数据量的加大,每年集群都会加入一些新节点,但是集群节点的性能差异很显著,这种异构集群在企业生产环境中很普遍。设想如果将一个计算量很大的机器学习任务分配在CPU计算能力很差的机器节点上,显然会影响作业的整体执行时间。Hadoop自带的3种资源调度器并没有很好地解决该问题。本文提出一种节点性能和作业类别标签动态匹配的资源调度算法(DLMS),将CPU性能较好的机器贴上CPU标签,将磁盘IO性能较好的机器贴上IO标签或者是两者都一般的普通标签。作业根据分类可以贴上CPU标签、IO标签任务或者普通标签,然后进入不同的标签队列,调度器尽可能将相应标签节点的资源分配给相应的标签作业,从而减少作业运行时间,提高系统资源利用率,提高系统整体效率。
1 相关研究
Hadoop集群异构调度相关研究已较多,Quan Chen等[3-4]提出动态MapReduce调度算法SAMR,能够动态计算任务的进展,自动适应不断变化的环境。但是该算法并没有考虑到数据的本地化问题,同时也缺少一种动态参数调优机制。Aysan Rasooli等[5]提出异构环境中的动态调度算法,通过估计作业到达率和平均作业执行时间决定调度策略。该文讨论了不同作业的资源需求,把任务分配到不同的队列中,设计了一个MapReduce负载预测机制来检测MapReduce过程的负载类型,并对其分类后放入相应的队列中。针对需要频繁IO的作业类型,HUI Kang等[6]提出MapReduce组调度算法,以降低上下文切换次数和解决IO阻塞问题。宁菲菲、郑均辉等[7]探讨了三队列作业调度算法,提出节点分类的概念,基于Hadoop1.0框架,没有考虑到节点运行作业时性能的变化等情况。以上这些算法都是针对异构集群提出的优化调度算法,都没有将节点和作业进行动态匹配的调度,缺少一种更加通用简单高效的解决方法,增加了用户的学习使用成本。endprint
2 调度算法
2.1 整体架构
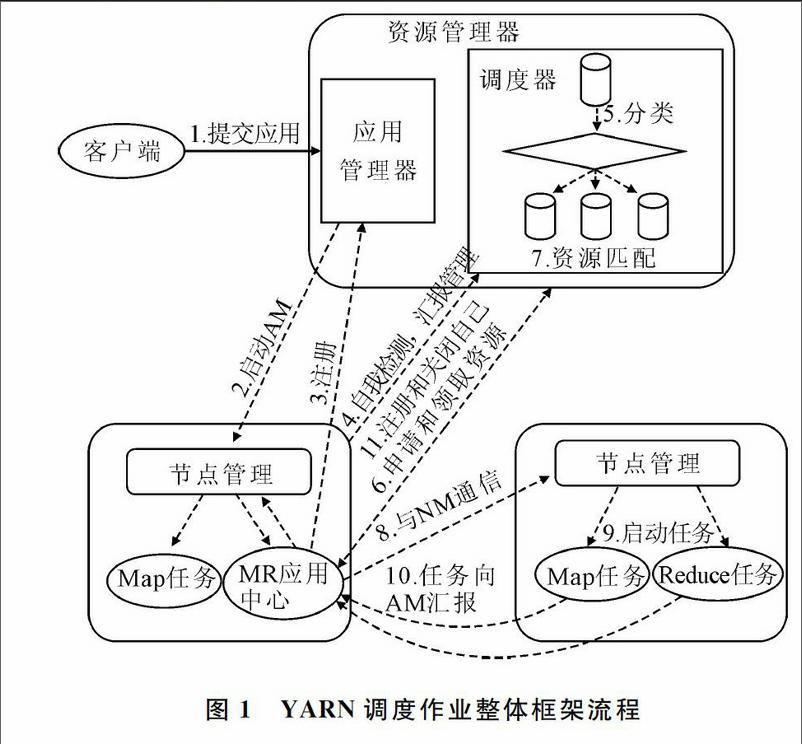
本文提出的调度框架将集群节点进行初始分类并赋予相应的标签。NodeManager发送心跳前作自我检测并对原始标签进行动态调整,并使用机器学习分类算法对作业进行分类并赋予相应的标签,根据用户设定的作业优先级、作业等待时间等属性动态实现作业排序,并将相应标签的资源分配给相应标签队列中的作业。YARN调度作业整体框架流程如图1所示。
各步骤解释如下:①用户向YARN提交应用程序,其中包括用户程序、启动ApplicationMaster命令等;②ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它启动应用程序的ApplicationMaster;③ApplicationMaster向ResourceManager注册后,为各任务申请资源,并监控它们的运行状态,直到运行结束;④NodeManager发送心跳前作自我检测生成动态的节点标签,并向ResourceManager汇报资源;⑤作业分类进入不同的标签队列中,进行优先级排序等待分配资源;⑥ApplicationMaster通过RPC协议向ResourceManager申请和领取资源;⑦根据NodeManager汇报的节点标签和资源,调度器将此节点的资源分配给对应标签队列的作业;⑧ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务;⑨NodeManager为任务设置好运行环境(环境变量、JAR包、二进制程序等)后,将任务启动命令写到脚本中,并通过运行该脚本启动任务;⑩各任务通过某个RPC协议向ApplicationMaster匯报自己的状态和进度,可以在任务失败时重新启动任务;应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
该调度器主要模块包括:①集群节点原始分类及其动态分类标签;②Map执行信息的获取与回传;③多优先级队列;④作业分类;⑤数据本地性;⑥调度算法。
2.1.1 集群节点原始分类及其动态类别标签
根据节点运行单个任务的时间与集群中所有节点运行时间平均值的大小关系将节点大致分成CPU型节点、磁盘IO型节点、普通型节点。分类方法如下:
(1)设节点集为N={Ni|i∈[1,n]},n为节点数量。
(2)在每台节点上都执行一个相同任务量的3种类型的作业并记录作业执行时间,Tcpu(i)表示在第Ni个节点上执行CPU作业的花费时间,Tio(i)表示在第Ni个节点上执行IO作业的花费时间,Tcom(i)表示在第Ni个节点上执行普通作业的花费时间。
(3)计算每种作业的集群平均时间,计算公式如下:Avgj=∑n1Tj(i)n i∈[1,n],j∈{cpu,io,com}
(1) 计算出每个节点在此种作业下与平均时间的时间差,如果Tcpu(i)Avgcpu,可以为此节点贴上普通型原始标签,通过比较后很可能每台节点上的标签会有多个,选择节省时间最多的标签为此节点的最后标签。
在集群节点运行过程中,如果一个节点的负载过大,即使该节点原始标签是CPU型标签,但在此环境下CPU性能优势已经不能体现,因此采取动态标签的方法,在nodeManager向resourceManager发送心跳时动态检测节点机器的CPU和IO使用率,如果超过了一定的阈值,将此节点标签贴上普通标签,由此实现动态标签。
2.1.2 Map信息回传与获取
Hadoop作业通常分成Map阶段和Reduce阶段,通常大作业的Map数量有上百个甚至更多,一个作业的时间主要消耗在Map阶段计算上,但是每个Map又是完全相同的执行内容,因而会收集作业运行的第一个Map进程的运行信息,这些信息在Nodemanage向ResourceManager发送心跳时传递到调度器中,由调度器进行作业分类。当生产环境中同一种类型作业每天都会运行,即用户已经知道作业所属标签,可以在命令行或者代码中为作业设置作业类型标签,在调度时调度器会进行检查,如果用户已经对作业贴上标签,就省去分类环节,直接进行调度。设Map的运行信息为,M={Min,Mout,Rate,Acpu,Mcpu,Zcpu,Mrate},它包括以下需要收集的信息:Min表示Map输入数据量,Mout表示Map输出数据量,Rate表示输入数据量/输出数据量,Acpu表示CPU平均使用率,Mcpu表示CPU中位数,Zcpu表示CPU使用率超过90%的平均数,MRate表示内存使用量,这些数据将成为以后该作业分类的特征属性。在实验过程中发现,单纯计算CPU的平均时间不能很好反映作业特征,CPU型作业的CPU使用率大于90%的次数较多,其类型作业的CPU使用率大于90%的次数相对较少。因此,将此信息也加入到Map回传的信息中。
2.1.3 多级优先级队列
在调度器中新建5个队列:原始队列、等待优先级队列、CPU优先级队列、IO优先级队列、普通优先级队列。用户提交的作业首先进入原始队列中,先运行作业部分Map并收集这部分Map运行信息,作业进入等待优先级队列中根据作业的分类类别标签进入到对应标签的队列中。在队列优先级方面采取用户自定义双层权重的设计方法,设作业的大小属性所占权重为worthNum,该属性可以分成3个等级Ni∈{long,mid,short}。作业的拥有者属性所占权重为worthUser,该属性可以分成两个等级Ui∈{root,others};作业的紧急程度所占权重为worthEmogence,该属性可分成3个等级Ei∈{highPrority,midPrority,lowPrority};作业的等待时间所占权重为worthWait,等待的计算公式为Jwait=nowTime-submitTime,赋予相应权重,最后计算出每个任务的优先级数,然后在相应的队列中进行排序。上述5种任务属性权重相加和为100%,具体公式如下:worthNum+worthUser+endprint
worthEmogence+worthWait=1
(2) 最后权重计算公式:finalWorth=worthNum*Ni+worthUser*Ui+
worthEmogence*Ei+worthWait*Jwait
(3)2.1.4 作业分类
在作业分类上,选择简单、使用比较普遍而且分类效果较好的朴素贝叶斯分类器进行分类[8]。如果用户在命令行和任务代码中已经添加作业类型,则此步骤会省掉,直接进入相应的队列中等待分配资源。朴素贝叶斯分类器算法具体分类步骤如下:
(1)分别计算一个作业在某些条件下是CPU、IO还是普通型作业下的条件概率:P(job=cpuV1,V2…Vn)
P(job=ioV1,V2…Vn)
P(job=comV1,V2…Vn) 其中,job表示作业类别标签,为作业的属性特征。
(2)根据贝叶斯公式P(BA)=P(AB)/P(A)得:P(job=cpuV1,V2…Vn)=
P(V1,V2…Vnjob=cpu)P(job=cpu)P(V1,V2…Vn)
(4) 假设V之间相对独立,根据独立假设:P(V1,V2…Vn|job=cpu)=∏n1P(Vi|job=cpu)(5) (3)实际计算中P(V1,V2…Vn)与作业无关可忽略不计,因此最终可得:P(job=cpuV1,V2…Vn)=
P(job=cpu)∏n1P(Vijob=cpu)
(6) 同理有:P(job=ioV1,V2…Vn)=
P(job=io)∏n1P(Vijob=io)
(7)
P(job=comV1,V2…Vn)=
P(job=com)∏n1P(Vijob=com)
(8) 作业是CPU型作业、IO型作业还是普通型作业取决于哪个概率值更大[9]。
2.1.5 数据本地性
Hadoop中遵循一个原则是“移动计算比移动数据更好”[9],移动到放置数据的计算节点要比将数据移动到一个计算节点更加节省成本,性能更好。关于数据本地性,本文采取了延时降级调度策略。该策略具体思想如下:
为每个作业增加一个延时时间属性,设Ti为第i个作业当前的延时时间,i∈[1,n],n为集群的节点数目,初始化为0,Tlocal表示本地节点延时时间阈值,Track表示机架节点延时时间阈值。当调度器分配资源给作业时,如果作业的执行节点和数据输入节点不在一个节点上,此时自增1,表示该作业有一次延时调度,则可以将此资源分配给其它合适的作业,直到当Ti>Tlocal时,作业的本地性就会降低为机架本地性,此时只要是本机架内的节点都可以将资源分配给该作业;当Ti>Track时,作业的本地性降低为随机节点。其中Tlocal和Track都采用配置文件的方式由用户根据集群情况自行配置。采用延时的调度策略可以保证在一定的延时时间内获得较好的本地性。
2.1.6 DLMS调度算法
DLMS调度算法的基本思想是预先分配部分作业执行,根据作业回传信息对作业进行分类,然后将节点标签的资源分配给相应队列中的任务,基本流程:
步骤1:当节点通过心跳向资源管理汇报资源时,如果原始队列不为空,则遍历原始队列中的作业,将已经在命令行或者程序中指定了作业类型标签的作业分配到相应的标签优先级队列中,原始队列移除此作业。
步骤2:如果原始队列不为空,则将此节点上的资源分配给原始队列,作业进入等待队列中等待下次分配资源,原始队列移除此作业,此轮分配结束。
步驟3:如果等待优先级队列不为空,则对等待优先级队列中的作业进行分类进入相应的标签优先级队列。
步骤4:如果节点性能标签相应的作业类别队列不为空,则将此节点的资源分配给此队列,此轮分配结束。
步骤5:设置查看资源访问次数变量,如果超过集群的数量,则将节点的资源按CPU、IO、普通、等待优先级顺序将资源分配给相应的队列,此轮调度结束。此步骤可以防止出现如下情况:CPU队列作业过多,导致CPU型节点资源已经耗尽,而其它标签的节点还有资源,但是作业无法分配资源。
算法流程如图2所示。
DMLS调度算法流程伪代码如下:
算法1:
When a heartbeat is received from Node i to RM
If 初始队列不为空
遍历原始队列中的作业将已经贴上标签的作业放入相应的标签队列中
if applicats中有app不为空
为app分配ApplicationMaster
endif
endif
if 等待队列不为空
分类得到app类型
根据app类型进入不同的队列中
在等待队列中将app移除
Endif
根据节点标签的类型将节点资源分配给CPU、IO、COM优先级队列之一
if(调度次数变量 >= 总节点数目)
依次将资源分配给CPU、IO、COM队列
调度次数变量=0;
endif
算法2:
assignContiners(applications,node)
for(app : applications)
获取app用户、大小、紧急程度、等待时间对应的权重
计算app最后的总权重
endforendprint
根據计算的权重值为app排序
for(app : applications)
fifo为app分配资源
endfor
3 实验验证
本文通过实验验证DLMS调度器的实际效果。实验环境为5台PC机搭建而成的Hadoop完全分布式集群,集群的节点机器配置统一为操作系统Ubuntu-12.04.1,JDK1.6,Hadoop2.5.1,内存2G,硬盘50G。其中NameNode的CPU核数为2,dataNode1的CPU核数为2,dataNode2的CPU核数为4,dataNode3的CPU核数为2,dataNode4的CPU核数为4。
3.1 节点原始标签分类
首先准备数据量为128M的wordCount(IO型),kmeans(CPU型)作业各一个,分别在4台节点上面运行6次,记录作业运行时间。
表1中,s表示时间单位秒,avg表示该节点运行相应标签任务的平均时间,allAvg表示所有节点运行相应标签任务的总平均时间,rate的计算公式如下:rate=avg-allAvgallAvg×100%
(9) 其中,负号表示平均时间相对于总平均时间的减少,正号表示平均时间相对于总平均时间的增加。
由图2可以看出,DataNode1运行两个任务都是节省时间的。采取节省最多的CPU作业作为机器的原始标签,DataNode4为IO标签,DataNode2、DataNode3为普通机器。
3.2 实验及结果分析
使用可以明显区分作业类型的几种作业,WordCount在Map阶段需要大量地读取数据和写入中间数据,Map阶段和Reduce阶段基本上没有算数计算,因此将这种作业定性为IO型作业,Kmeans在Map阶段和Reduce阶段都需要大量计算点和点之间的距离,并没有太多中间数据的写入,因此将这种作业定性为CPU型作业,TopK在Reduce阶段没有大量的数据写入磁盘,也没有大量的计算,只涉及简单的比较,因此可认为是普通型任务。
通过两组实验进行验证,第一组实验设置调度器为fifo,在500M、1G和1.5G的数据量下分别运行WordCount、Kmeans、Topk作业各3次,记录每个作业3次的平均时间作为最终时间,切换调度器为Capacity和DLMS调度器做同样的实验操作,实验中记录DLMS调度器下每种作业的Container在集群的分布,Container表示集群资源的划分单位,记录了作业分片在集群中运行的分布情况,YARN中每个Map和Reduce进程都是以一个Container来表示。Container在集群中每个节点分布比例表明节点执行作业任务量的比例。
图3的横坐标是作业数据量,纵坐标是WordCount、Kmeans、Topk这3种作业共同运行的总时间。在数据量增大的情况下,DLMS调度器相比于其它调度器节省约10%~20%的时间。
DLMS会将相应节点标签的资源分配给相应标签的作业。作业的Map和Reduce以Container的形式在节点上运行,图4—图6是在DMLS调度器下不同数据量作业的Container数量。原始分类Node1是CPU型的标签节点,Node2和Node3是普通标签节点,Node4是IO标签节点。WordCount是IO型作业,Topk是普通型作业,Kmeans是CPU型作业。从图中可以看出,Container的分布规律为WordCount作业在Node4上分配的Container较多,Tokp在普通节点Node2和Node3上分布较多,Kmeans作业在Node1节点上分布较多。以上不同作业的Container在集群节点上的分布表明,DLMS调度器提高了相应节点标签的资源分配给对应标签作业的概率。
第二组实验中,准备了5个作业,分别是128M和500M数据量的WordCount作业,128M和500M数据量的Kmeans作业,500M的Topk作业组成一个作业组,5个作业同时提交运行。在不同调度器的集群中模拟连续作业执行情况,记录作业组执行完的总时间。作业组在不同的调度器下运行3次,记录作业组运行完的总时间。
具体结果如图7所示,可以看出本文提出的DLMS调度器相比于Hadoop自带调度器执行相同作业组节省的时间较明显,本文提出的DMLS调度器相比Hadoop自带的Fifo调度器节省了大约20%的时间,比Capacity调度器节省了大约10%的运行时间。
4 结语
本文提出的DLMS调度器用两个不同的实验验证该调度器的效率,从实验数据上可以看出,无论是执行不同数据量的单个作业,还是执行由不同数据量组成的多个不同作业组成的作业组,相对于Hadoop自带的其它调度器,其在执行时间上都大大减少,集群资源利用率得以提高。后续研究的重点是在本文提出的调度器中考虑Reduce的数据本地性。
参考文献:
[1] 朱洁,赵红,李雯睿.基于Hadoop的三队列作业调度算法[J].计算机应用,2014,34(11):3227-3230,3240.
[2] 邓传华,范通让,高峰.Hadoop下基于统计最优的资源调度算法[J].计算机应用研究,2013,30(2):417-419.
[3] CHEN Q, ZHANG D, GUO M, et al. SAMR: a self-adaptive mapreduce scheduling algorithm in heterogeneous environment[C]. IEEE, International Conference on Computer and Information Technology,2010:2736-2743.
[4] 陈全,邓倩妮.异构环境下的动态的Map-Reduce调度[J].计算机工程与科学,2009,31(S1):168-171,175.
[5] RASOOLI A, DOWN D G. An adaptive scheduling algorithm for dynamic heterogeneous Hadoop systems[C]. Conference of the Center for Advanced Studies on Collaborative Research,2011:30-44.
[6] KANG H, CHEN Y, WONG J L, et al. Enhancement of Xen′s scheduler for MapReduce workloads[C]. ACM International Symposium on High PERFORMANCE Distributed Computing,2011:251-262.
[7] 宁菲菲,郑均辉.基于Hadoop平台的三队列作业调度算法[J].微型电脑应用,2015, 31(8):19-21.
[8] 赵文涛,孟令军,赵好好,等.朴素贝叶斯算法的改进与应用[J].测控技术,2016,35(2):143-147.
[9] 杨洋.基于资源状况的延时等待公平调度算法的研究[D].沈阳:东北大学,2014.
(责任编辑:孙 娟)endprint
