一种基于遗传算法的极限学习机改进算法研究
2017-09-29王新环刘志超
王新环 刘志超


摘 要:針对传统极限学习机(ELM)缺乏有效的训练方法、应用时预测精度不理想这一弱点,提出了一种基于遗传算法(GA)训练极限学习机(GA-ELM)的方法。在该方法中,ELM的输入权值和隐藏层节点阈值映射为GA的染色体向量,GA的适应度函数对应ELM的训练误差;通过GA的遗传操作训练ELM,选出使ELM网络误差最小的输入权值和阈值,从而改善ELM的泛化性能。通过与ELM、I-ELM、OS-ELM、B-ELM4种方法的仿真结果对比,表明遗传算法有效地改善了ELM网络的预测精度和泛化能力。
关键词:遗传算法;极限学习机;权值;阈值
DOI:10.11907/rjdk.171419
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2017)009-0079-04
Abstract:In order to improve the prediction accuracy of traditional Extreme Learning Machine (ELM) algorithm. Aim to overcome the lack of effective training methods for traditional extreme learning machine (ELM), the prediction accuracy is not ideal .We proposed a method which based on genetic algorithm (GA) training Extreme Learning Machine. In this method, the initial input weights and threshold vector of ELM maps to the chromosome vector of GA, and the fitness function of GA corresponds to the training error of ELM;By means of the GA to train ELM, improve the ELMs generalization capacity. Comparing the simulation results of GA-ELM with ELM, I-ELM, OS-ELM, B-ELM, the simulation results show that the genetic algorithm can effectively improve the prediction accuracy and generalization ability of ELM network.
Key Words:genetic algorithm; extreme learning machine; weight
0 引言
Huang G B等[1] 于 2006 年在传统神经网络的基础上,提出了极限学习机(Extreme Learning Machine,ELM)算法,它属于单隐藏层前馈神经网络(SLFNs),具有自适应能力和自主学习特点,主要应用于图像分割、故障诊断、数据挖掘自动控制等领域[2-4]。该算法通过对单隐藏层前馈神经网络的输入权值和隐藏层节点的阈值随机赋值,用最小二乘法求解得到输出权值,极大提高了网络训练速度和泛化能力[5-6]。但是,在解决梯度下降问题时,随机产生网络的输入权值和隐藏层节点的阈值向量参数不能保证训练出的ELM模型达到最优,有收敛速度慢等问题。针对这些问题,陈绍炜等[7]提出利用蝙蝠算法优化ELM,王杰等[8]提出了粒子群优化的极限学习机,张卫辉等[9]提出了DE-ELM,这些方法都有可能出现早熟,陷入局部最优。
遗传算法(genetic algorithm,GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种基于概率转换规则的全局搜索优化方法[10]。它将问题的解看作一个种群,通过不断选择、交叉、变异等遗传操作,使解的质量越来越好[11]。
为了提高ELM算法的预测准确率,本文提出了一种基于遗传算法的极限学习机。在可行解空间,把遗传算法优化极限学习机初始权值和阈值的问题,转化为遗传算法中选择最适应染色体过程。将本算法与其它几个算法如ELM、I-ELM、OS-ELM、B-ELM,分别对回归和分类问题进行仿真,以验证GA-ELM运行效果的准确性。
1 极限学习机
极限学习机(ELM)是一种新的学习算法,它是一种单隐藏层前馈神经网络学习算法。相比传统的基于梯度的学习算法,只需随机选取输入权值和隐藏层节点的阈值即可求出输出权值,避免了传统学习方法面临的问题。ELM学习速度快且泛化性能好,其网络结构如图1所示。
给定训练集{(xi,ti)}Ni=1Rn×Rm,隐藏层节点激励函数g(·)是非线性函数,有Hardlim函数、Sigmoid函数、Gaussian函数等,其中Sigmoid函数最为常用,隐藏层节点个数为L。
(1)随机选取隐藏层节点参数(ai,bi),i=1,…,L,ai为第i个隐藏层节点的输入权值,bi为第i个隐藏层节点阈值。
(2)计算隐藏层节点输出矩阵H=g(ai,bi,xi)。H=h(x1)
h(xn)=g(a1,b1,x1)…g(aL,bL,x1)
…
g(a1,b1,xn)…g(aL,bL,xn)n×L
(1) (3)计算隐藏层到输出层的输出权值β:β=H↑·T,β=βT1
βTLL×m,T=tT1
tTnn×mendprint
(2) 式中:H↑是隐藏层输出矩阵H的Moore-Penrose广义逆,T为目标输出,即T={tj}nj=1。
(4)计算输出值Oj。
当训练到误差(|Oj-Tj|)小于预先设定的常数ε时,ELM能够接近这些训练样本: Oj=∑Li=1βig(ai,bi,xi),|Oj-Tj|≤ε,j=1,…,n (3) (5)求取误差:E(ai,bi)=∑nj=1(Oj-Tj)2
(4) 其中,(ai,bi)分别为隐藏层节点输入权值、阈值, Tj是第j组数据的输出实际值,Oj是第j组数据输出预测值。GA-ELM的目标是使误差E(ai,bi)最小。该方法的主要思想是:把ELM的初始输入权值和隐藏层节点阈值作为GA算法的染色体向量,通过选择、交换、变异、遗传等操作,选择出最适应染色体作为ELM预测数据的输入权值和阈值。
2 遗传算法(GA)
遗传算法是Holland教授于1975年提出的一种模拟自然界遗传机制和生物进化论的搜索全局最优解算法。GA把搜索空间映射为遗传空间,把可能的解编码成一个向量——染色体,向量的每个元素称为基因,通过不断计算各染色体的适应值,选择最好的染色体获得最优解。遗传算法执行过程如下:
(1)初始化。确定种群规模M,随机生成M个染色体作为初始种群Y(0)、交叉概率Pc、变异概率Pm、终止进化代数N。
(2)计算个体适应度。计算第t代种群Y(t)中每个染色体的适应度。设种群为f(y),y∈M,其中M={y1,…,ym}, yi={x1,…,xm},每个染色体含m个基因,则f(y)=y1
yM=x11…x1m
…
xM1…xMm
(5) 适应度函数为fit(y),y∈{y1,…,yM},求取fit(y)函数时,假设为优化神经网络,则fit(yi)=1n∑nj=1(Oj-Tj)2
(6) 其中:Oj为第j个预测输出值;Tj为实際输出值;n为输入数据总数。
(3)进化。选择(母体):从Y(t)中运用选择算子选择出L对母体L≥M;交叉:随机选择L2对染色体(双亲染色体),当其中一个染色体概率小于Pc时,随机制定一点或多点进行交叉,可得两个新的染色体(子辈染色体),最后形成L个中间个体;变异:对L个中间个体分别依概率Pm执行变异,形成M个候选个体。
(4)选择子代。从上述种群中形成的L个候选个体中选择适应度高的M个染色体,形成新一代种群Y(t+1),选择方法是适应度比例法(转轮法)。
某染色体被选的概率为Pc:Pc=fit(yi)∑fit(yi)
(7) yi为种群中第i个染色体,fit(yi)是第i个染色体的适应度值,∑fit(yi)是种群所有染色体适应度值之和。
具体步骤如下:①计算各染色体适应度值;②累计所有染色体适应度值,记录中间累加值S-mid和最后累加值sum=∑fit(yi);③产生一个随机数N,0 (5)终止进化。当达到进化代数N时,终止进化,选择出第N代中适应度最高的染色体作为最优解。targetvalue=max{fit(yi)}
3 GA-ELM算法
为提高极限学习机预测精度,本文提出了基于遗传算法的极限学习机(GA-ELM)。在该算法中,将ELM训练数据的输入权值和隐层节点阈值,映射为GA种群中每条染色体上的基因;GA的染色体适应度对应于ELM的训练误差,这样将求取最优输入权值、阈值问题转换为通过降低染色体适应度,选择最优染色体问题。通过GA繁殖、交叉、变异等遗传操作,选择出最优染色体,作为优化后ELM的输入权值和阈值;再用ELM求取输出权值的方法——最小二乘法,算出隐层神经元的输出权值,从而计算预测输出。该算法集成了GA全局搜索最优能力和ELM的强学习能力。
GA-ELM学习过程:
取训练数据N,该组数据有输入神经元A个,隐层神经元B个,选择激活功能函数,可以取Hardlim函数、Sigmoid函数、Gaussian函数等。
(1)初始化种群。初始化种群X,包括m个染色体,其中每个染色体xi都包括A·B个输入权值和B个阈值,并把初始群体作为第一代种群:X=x1
xm=a11…a1Ab11…b1B
……
am1…amAbm1…bmB
(9) 其中:akg为输入权值;bkh为隐层神经元阈值,初始群体中的权值和阈值是随机获取的。k=1,2,…,m;g=1,2,…,A;h=1,2,…,B (2)计算适应度。xi由输入权值向量ωi和阈值向量bi组成:xi=ωi+bi;ωi=ai1,…,aiA;bi=bi1,…,biB
(10) 用ELM求输出权值的方法求隐层神经元输出权值β:β=H+T
(11) 则适应度函数fit为:fit=∑nj=1(Oj-Tj)2=∑Nj=1∑Bi=1(βig(ai,bi,xi)-Ti)2
(12) (3)选择染色体。计算出每个染色体的适应度后,对种群进行选择、交叉、变异等操作,形成新一代种群。继续进行优化运算,直至达到设定的遗传代数,选出此时适应度最高的染色体作为优化后的输入权值和阈值。
4 实验结果与分析
为了验证GA-ELM算法的有效性,将GA-ELM与ELM、I-ELM、OS-ELM、B-ELM分别应用于5个回归问题、5个分类问题,进行仿真测试及结果分析。仿真实验环境:内存4G,处理器为Core i5-3470,频率为3.2GHz的普通PC机,matalb2013a环境下运行。endprint
4.1 实验参数设置
以下实验中,所有回归和分类问题的输入都归一化到[-1,1],权值和阈值在区间[-1,1],输出归一化为[0,1],隐层神经元激励函数采用Sigmoid函数,遗传算法的进化代数为50代,交叉概率为0.4,变异概率为0.1,种群规模为40。
4.2 仿真数据属性及设置
测试数据在UCI(University of CaliforniaIrvine)数据库中下载。表1列出了回归数据属性,表2列出了分类数据属性。每种算法运行100次,取其平均训练时间、平均误差和平均精度,仿真结果如表3、表4所示。
结果分析:从表3可以看出,所有回归试验中,在相同隐层神经元情况下,GA-ELM的测试误差远远小于其它算法误差。这是因为在原始的ELM中,一些隐层节点在求网络输出时作用很小,有时还有可能增加网络的复杂性,降低泛化性能。表4中,每组数据在相同隐层节点情况下,GA-ELM的测试精度均达到最高。
4.3 隐层节点数目性能比较
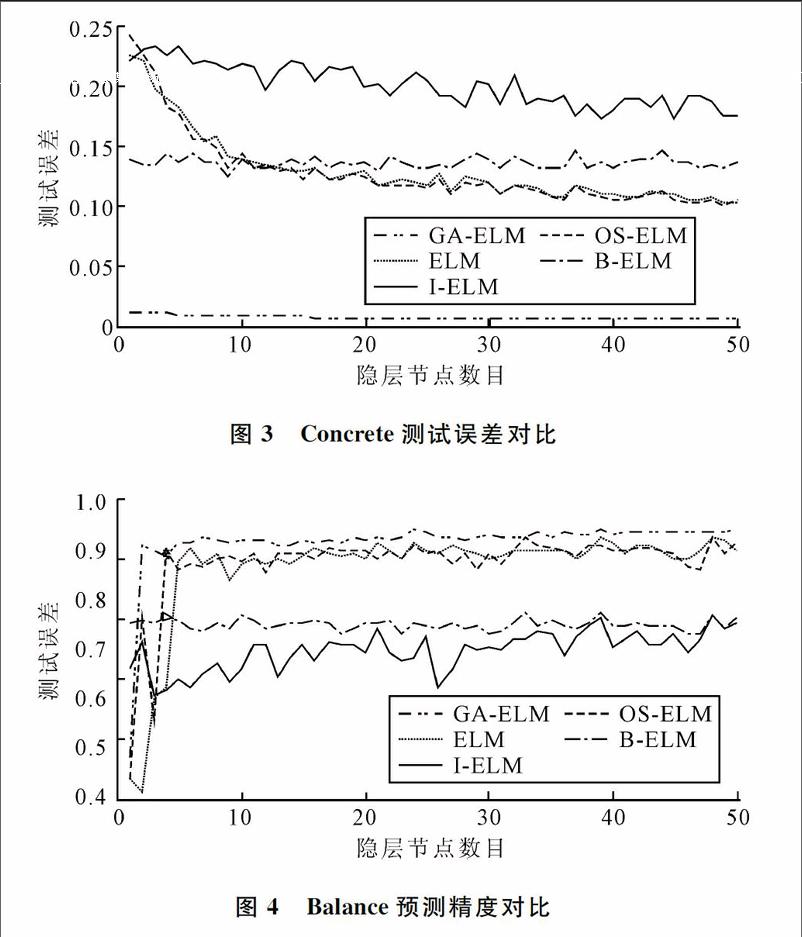
将 GA-ELM、ELM、OS-ELM、I-ELM、B-ELM等SLFNs的隐层节点数初始设置为1个,每次加1,直到50个为止。测试结果如图3和图4所示。图3取Concrete数据,图4取Balance数据。
结果分析:从图3可以看出,GA-ELM在很少隐层节点的情况下,误差已经很小,表明经过GA训练得到了使ELM网络误差最小的输入权值和阈值,提高了收敛速度。从图4可以看出,在相同测试精度情况下,GA-ELM的隐层节点数比其它算法少很多,这意味着在处理固定型SLFNs时,GA-ELM比ELM、I-ELM、OS-ELM、B-ELM能获得更加紧凑的网络结构。简言之,GA-ELM在解决回归和分类问题时,可以更好地提高测试精度。
5 结语
本文提出了一种新的单隐层前馈神经网络算法GA-ELM,与其它算法的仿真结果对比表明,无论在回归问题还是分类问题上,GA-ELM都具有高预测精度。与其它算法不同的是,GA-ELM具有自组织、自适应、自学习性,能够迅速搜索到最优权值和阈值,使ELM的网络模型更加紧凑,计算代价更低,更适用于离线训练、在线识别或预测等对精度要求较高的场合。
参考文献:
[1] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: theory and applications [J].Neurocomputing, 2006,70(s1-3):489-500.
[2] FENG GUORUI, LAN YUAN, ZHANG XINPENG, et al. Dynamic adjustment of hidden node parameters for extreme learning machine [J]. IEEE Transactions On Cybernetics, 2015,5(2):279-288.
[3] HUANG GUANG-BIN, ZHOU HONGMING. Extreme learning machine for regression and multiclass classification [J]. IEEE Transactions On Systems, Man, and Cybernetics-Part B: Cybernetics, 2012,42(2):513-529.
[4] LIN SHAOBO, LIU XIA, FANG JIAN. Is extreme learning machine feasible?a theoretical assessment(Part II)[J]. IEEE Transactions On Neural Networks And Learning Systems, 2015,26(1):21-34.
[5] YOAN MICHE, ANTTI SORJAMAA, PATRICK BAS, et al. OP-ELM: optimally pruned extreme learning machine [J]. IEEE Transactions On Neural Networks, 2010,21(1):158-162.
[6] ALIM SAMAT, PEIJUN DU, SICONG LIU,et al. Ensemble extreme learning machines for hyperspectral image classification [J]. IEEE Journal Of Selected Topics In Applied Earth Observations And Remote Sensing,2014, 7(4):1060-1068.
[7] 陳绍炜,柳光峰,冶帅,等.基于蝙蝠算法优化ELM的模拟电路故障诊断研究[J].电子测量技术,2015,38(2):138-141.
[8] 王杰,毕浩洋.一种基于粒子群优化的极限学习机[J].郑州大学学报,2013,45(1):100-104.
[9] 张卫辉,黄南天.基于广义S变换和DE-ELM的电能质量扰动信号分类[J].电测与仪表,2016,53(20):50-54.
[10] YANG CHENG-HONG, LIN YU-DA, LI-YEH CHUANG, et al. Evaluation of breast cancer susceptibility using improved genetic algorithms to generate genotype SNP barcodes [J].IEEE/ACM Transactions On Computational Blology And Bioinformatics,2013,10(2):361-371.
[11] CHEN BILI, ZENG WENHUA, LIN YANGBIN, et al. A new local search-based multiobjective optimization algorithm[J].IEEE Transactions On Evolutionary Computation,2015,19(1):50-73.
(责任编辑:杜能钢)endprint
