反向Top—k查询算法研究
2017-09-29黄伟国
黄伟国

摘 要:互联网中沉淀了大量可分析利用的数据,如何有效地利用这些海量数据,为不同行业产品制造方提供对新产品的分析,已成为时下的热点。反向Top-k查询技术是一种常用的数据分析及处理技术,并且已经在很多领域得到了应用。研究了已有的基于反向Top-k的查询算法Skyband-based算法和Branch-and-bound算法,针对很多实际应用领域偏好权重向量会出现改变的情况,提出了一种适用于进行“二次计算”的交互式算法,通过实验将交互式算法跟效率高的Branch-and-bound算法对比得出,当用户修改部分偏好权重向量之后,利用交互式算法可以比Branch-and-bound算法更加高效率地计算出结果。
关键词:交互式算法;Skyband-based算法;Branch-and-Bound算法;Top-k查询
DOI:10.11907/rjdk.172266
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2017)009-0075-04
Abstract:Among the Internet, a large amount of data can be analyzed and utilized. How to effectively use these vast amounts of data, for different industries, manufacturers of products to provide new product analysis, has become a hot topic. Reverse Top-k query technology is a commonly used data analysis and processing technology, and has been applied in many fields. Study of the existing reverse Top-k query algorithm Skyband-based algorithm and Branch-and-bound algorithm based on the preference weight vector in many practical applications will appear to change the situation, a method is presented for the “two” interactive algorithm by experiment that compared to Branch-and-bound algorithm, interactive algorithm with high efficiency, when part of the user to modify the preference weight vector is calculated by the interactive method can be more efficient than Branch-and-bound algorithm results.
Key Words:interactive algorithm; skyband-based algorithm; branch-and-bound algorithm; Top-k queries
0 引言
Top-k查询作为一种高效的信息对比查询技术,经过多年的发展,已经较为成熟。本文研究的基于Top-k查询的反向Top-k查询技术,能够提供与Top-k不同的查询角度。反向Top-k查询算法可以为各行业提供“影响值”最大的产品参考。产品制造方通过参考这些“影响值”最大的产品,可以制造出更受大众欢迎的产品,从而为产品制造方带来更多利益。
1 国内外研究现状
Top-k查询[1]是指基于用户的偏好函数从所有产品集中提取优先的k个产品集。比如,知道一个用户的偏好权重向量,然后用Top-k查询来查找该用户喜欢的k个产品。反向Top-k查询[2]是指基于用户根据他们的偏好认为某个产品作为他们的Top-k个产品中的一个来评估一个潜在的产品在市场上的影响。但是根据反向Top-k查询去找出m个最有影响的产品所耗的时间特别多,因为它需要对数据库中的每个产品进行反向Top-k查询。因此,本文使用文献[3]中提到的两个可以提高计算效率的算法。同时,充分考虑现实中的一些情况,也即针对用户偏好权重发生改变的情况,提出一种交互式算法,用来进行“二次计算”,以提升“二次计算”效率。
最近,研究产品制造方而不是用户方的一些创新查询算法被提出。文献[4]基于支配关系的分析,幫助制造商完成它们的产品市场定位。文献[5]中提到了如何创建有竞争力的产品。然而在这两种方法中,都是将用户偏好作为数据点代表更好的产品,而反向Top-k查询是根据权重向量分析出用户偏好。文献[6]中提到如何为一个对象的推广寻找Top-k个最有兴趣的区域。文献[7]中给出一个查询点q,反向最近邻查询是基于一个相似的函数,找出那些与q最近邻的点,这些点描述成被q影响。
2 反向Top-k查询算法
一种找出前m个影响值最大的结果集的朴素方式是用暴力计算方法计算结果集。如对于每一个点p属于数据向量集合S都进行反向Top-k查询从而得到它的影响分数fki(p)。但是其效率非常低下,即使是一个中等大小的数据库,也要消耗很多时间。因此,下文主要介绍文献[3]和文献[8-9]中可以提高计算效率的算法,分别是Skyband-based算法[10]、Branch-and-Bound算法。
2.1 Skyband-based算法
Skyband-based算法依赖于ComputeSkyband算法和RTA算法,用ComputeSkyband选出点集mSB,这样就减少了计算RTA的点,从而提升了计算效率。因此,本文首先介绍ComputeSkyband算法和RTA算法。endprint
2.1.1 ComputeSkyband算法
算法思想:计算电影集S中每部电影被支配的数量,如果被支配的数量小于m,则将这部电影插入到mSB集合中,否则不进行操作。
2.1.2 RTA算法
作为一种计算向量的反向Top-k集合的算法,RTA算法能够避免一些重复计算,从而更快速地给出结果集合[11-12]。
该算法的思想是:考虑在整个计算中用户权重值W的数量较多,如果用W中的每一个权重去和特定的点计算,那么计算量无疑很大,因此用RTA通过已经计算过的Top-k结果集,避免计算那些不可能在Reverse Top-k 结果集中的w向量值,从而能够避免一些对结果没有影响的计算过程,进而提高算法效率。
2.1.3 Skyband-based算法
Skyband-based算法簡称SB算法。算法基本思想:先利用ComputeSkyband算法计算出mSB(S)点集,然后利用RTA算法计算mSB(S)中的所有点集的影响值。在计算点的影响值时,把影响值压缩进一个从大到小的队列Q中。当mSB(S)中所有点集的影响值计算完后,取出Q中前m个点,这m个点就是SB算法计算出来的结果集。
2.2 Branch-and-bound算法
上文介绍的Skyband-based算法不是渐增性的,导致当需要扩大或者缩小算法的m值时,该算法不能够利用上一次的计算结果,而是需要完全重新计算,即Skyband-based算法不是渐进的。与此相对,本节提出的Branch-and-bound算法是渐增性的,当需要获得更多的结果值时,即当扩大m值时,并不需要进行全盘的重新计算,只是进行递增计算即可。因此,面对需要经常修改m值的情况,该算法的效率会更高,能够在更短的时间内给出计算结果。
Branch-and-bound算法依赖ComputeBound函数和RTA算法。RTA算法在上文已介绍过,因此,下文主要介绍ComputeBound函数。
2.2.1 ComputeBound函数
ComputeBound函数的基本思想:输入一个点q,计算出一个点q的影响值,然后计算出所有点q的影响值集中的反向Top-k值,并且求交集,得到的交集个数就是影响值的上界。
2.2.2 Branch-and-bound算法
Branch-and-bound算法的基本思想是:先将电影数据集S存放在R树中,之后把R树根节点上的MBR加载到从大到小的优先队列Q中;然后用ComputeBound函数改进每个MBR的上界,并用RTA算法计算出实际影响值。
Branch-and-bound算法详细描述如下:首先将电影评分数据S集加载到R树上得到一棵树tree;然后计算tree根节点的所有子节点的上界值,并插入到优先队列Q中;接着,做一个循环,当结果集RES的数量小于m时循环一直执行。从Q中推出一个MBR为c,判断c是否为电影数据点。如果c是电影数据点,而且已经计算了它的影响值,则添加到结果集RES中;否则计算它的上界,如果上界变小了,则再次插入到Q中,否则用RTA计算其影响值然后插入Q中。如果c不是产品数据点,则计算它的上界值,如果上界值没有变小,则重新插入到Q中;否则把c的子节点及其相应的上界值插入到Q中。
3 交互式算法
本文算法在计算过程中有大量用户偏好权重向量,算法计算得到的结果集跟用户偏好权重向量有关。本文所介绍的Skyband-based算法和Branch-and-bound算法都是批量式的查询,因此每次计算都需要将所有数据计算一次。而当部分用户偏好权重向量被修改后,不需要重新计算所有数据而得到结果集。可以利用第一次计算得到的结果,然后使用增量式的方法进行查询,即可得到最新的查询结果集。鉴于此,本文提出交互式算法,也即当部分用户偏好权重向量改变时,可以用交互式算法快速计算出结果集。
3.1 Top-k集比较算法
因下文介绍的交互式算法需要用到Top-k集比较算法,因此先介绍Top-k集比较算法。
为了在后面的算法过程中描述得更加清楚,在对算法作进一步介绍前,先对交互式算法中用到的一些变量进行定义。变量定义如表1中所示。
Top-k集比较算法的基本思想描述如下:如果一个用户偏好权重向量w的OldTop-k集中的MtimeId和NewTop-k中的MtimeId相同,则不作任何处理。如果一个MtimeId在OldTop-k集中存在,而在NewTop-k集中不存在,就把OldS中对应MtimeId的电影的影响值减去w的权值;如果一个MtimeId在NewTop-k中存在,而在OldTop-k集中不存在,那么就把OldS中对应的MtimeId的电影的影响值加上w的权值。
3.2 交互式算法介绍
针对改变的用户偏好权重向量作增量式查询,为了能够让交互式算法对已有的结果做增量式查询,要在第一次计算时进行一些处理,也即在用Skyband-based算法和Branch-and-bound算法进行结果查询之后,将查询出来的每个产品的影响值写入到存有产品集的文件中,然后针对每个改变的用户偏好权重向量进行计算。
交互式算法的基本思想是:在用户修改用户权重向量之后,系统管理员不定时地将改变的用户权重向量从Mysql数据库中导出到本地,得到新的用户偏好权重向量NewW,并根据得到的NewW读取文件中的OldW,调用Top-k算法分别计算OldW集中的每个用户偏好权重向量的Top-k集称之为OldWTop-k集,NewW集中的每个用户偏好权重向量的Top-k集称之为NewWTop-k集。对OldWTop-k集和NewWTop-k集中的每个OldTop-k集和NewTop-k集都调用Top-k集比较算法,得到新的电影集NewS。最后将用户偏好权重向量中的OldW修改为NewW并存于文件中,以保持数据库中用户偏好权重向量和文件中用户偏好权重向量的一致性。将计算得到的NewS存于文件中,以记录最新电影的影响值。endprint
4 反向Top-k查询算法性能比较
4.1 实验数据获取及预处理
实验数据获取包括两部分:一部分是电影数据获取[13-15],网络爬虫爬取专业电影网站“时光网”(http://movie.mtime.com/)中的电影数据网页,之后将电影网页数据用正则表达式进行处理,得到电影的各项评价标准值;另一部分是获取用户偏好权重向量,由于用户偏好权重向量值不是真实值,因此用户偏好权重向量采用程序生成。
4.2 算法实验效果
本文中的Branch-and-bound算法和Skyband-based算法都是批量式算法。从文献[4]中可以看出,在算法所需时间上Branch-and-bound算法(图中称BB算法)优于Skyband-based算法。因此,在对比批量式算法和交互式算法的效率时,选择Branch-and-bound算法与交互式算法进行对比。
在对比过程中,如果不加特别说明,各数据的默认值如下:k值默认为10,m值默认为100,电影评分的条数为12 000条,用户偏好权重向量的条数为20 000条,电影评分和用户偏好权重向量的维度是7。两个算法的计算效率对比有两个指标,分别是执行时间、Top-k计算次数。
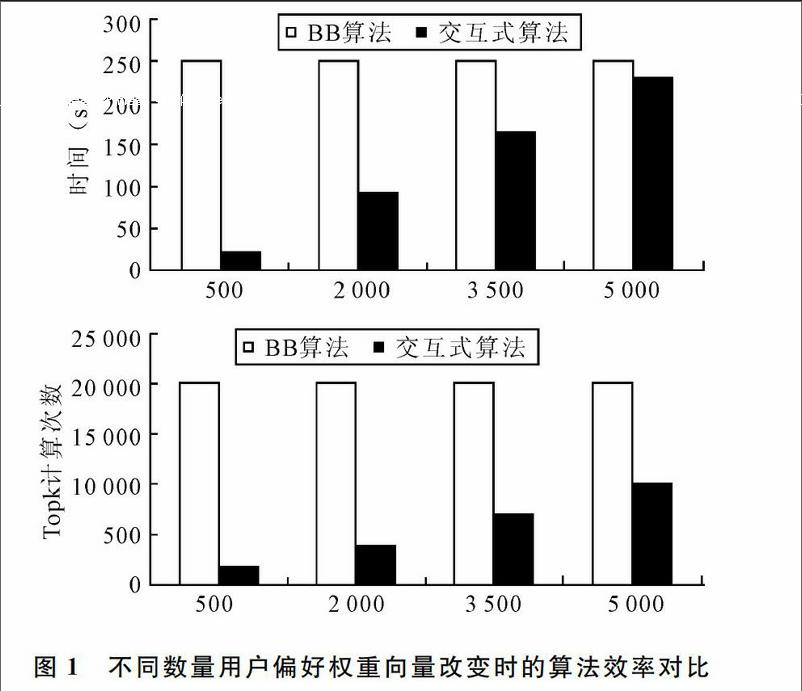
如图1所示,当不同数量的用户偏好权重向量发生改变时,Branch-and-bound算法的时间都为250,Top-k计算次数都为20 000,即没有发生变化。这是因为Branch-and-bound算法不能根据已有结果作增量式查询,因此当用户偏好权重向量改变时,需要对全部数据进行计算。而采用交互式算法,当用户偏好权重向量改变时,只需要对改变的向量作增量式查询就可以得到结果集。由图1可以看到,当不同数量用户偏好权重向量发生改变时,交互式算法执行的时间不一样。在交互式算法中,花费时间最多的是计算改变的用户偏好权重向量的Top-k集和对硬盘上数据的读取。当改变的用户偏好权重向量数为500时,为了作增量式查询,需要计算改变前的用户偏好权重向量的Top-k集和改变后的用户偏好权重向量的Top-k集。因此,一共计算了两倍改变的用户偏好权重向量的数量,也即当改变的用户偏好权重向量的数量为500时,计算1 000次Top-k集。因此,随着改变的用户偏好权重向量的增加,交互式算法所花时间和计算Top-k集的次数也在不断增加。由此可见,当用户修改部分偏好权重向量之后,用交互式算法可以比Branch-and-bound算法更加高效率地计算出结果。
5 结语
本文对已有的基于反向Top-k查询的算法进行研究,其中包括Skyband-based算法和Branch-and-bound算法,并针对这两种算法的不足,提出交互式算法以提高“二次计算”效率。本文的重点是用批量式算法中效率较高的算法进行第一次计算,当用户偏好权重向量发生改变时,用交互式算法针对第一次计算得到的结果做增量式计算,以提高系统效率。
参考文献:
[1] IIYAS IF, BESKALES G, SOLIMAN MA.A survey of top-k query processing techniques in relational database systems[J]. ACM Computing Surveys,2008,40(4):1-58.
[2] VLACHOU A, DOULKERIDIS C,KOTIDIS Y,et al.Reverse top-k queries[J]. IEEE International Conference on Data Engineering, 2010,41(3):365-376.
[3] VLACHOU A, DOULKERIDIS C. Identifying the most influential data objects with reverse top-k queries[J]. Proceedings of The VLDB Endowment,2010,3(1-2):364-372.
[4] LI C, OOI BC, TUNG AKH, et al. DADA:a data cube for dominant relationship analysis[J]. In Proc. of SIGMOD,2006:659-670.
[5] QIAN W, WONG CW, IIYAS IF, YU P. Creating competitive products[J]. PVLDB,2009,2(1):898-909.
[6] WU T, LI C, HAN J. Region-based online promotion analysis[J]. In Proc. of EDBT,2010:63-74.
[7] KORN F, MUTHUKRISHNAN S. Influence sets based on reverse nearest neighbor queries[J]. In Proc. of SIGMOD,2000,29(2):201-212.
[8] LAWLER EL, WOOD DE. Branch-and-Bound methods: a survey[J]. Informs,1966,14(4):699-719.
[9] NARENDRA, FUKUNAGA.A branch and bound algorithm for feature subset selection[J]. IEEE,2006(9):917-922.
[10] PAPADIAS D, TAO Y, FU G, et al. Progressive skyline computation in database systems[J].ACM Transactions on Database Systems,2005,30(1):41-82.
[11] WANG B, DAI Z, LI C, CHEN H.Efficient computation of monochromatic reverse top-k queries[J].Fuzzy Systems And Knowledge Discovery (FSKD),2010,4:1788-1792.
[12] LIAN X, CHEN L. Monochromatic and bichromatic reverse skyline search over uncertain databases[C].Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data,2008:213-226.
[13] 夏冰,高军,王腾蛟,等.一种高效的动态脚本网站有效页面获取方法[C].中国数据库学术会议,2009.
[14] 罗刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010:17-84.
[15] 许笑,张伟哲,张宏莉,等.廣域网分布式Web 爬虫[J].软件学报,2010,21(5):1067-1082.
(责任编辑:孙 娟)endprint
