一种并行差分隐私关联规则挖掘算法
2017-09-29申泽宇袁健
申泽宇 袁健


摘 要:针对传统基于ε-差分隐私模型的top-k关联规则挖掘算法在大规模数据环境下挖掘效率低下的问题,提出了一种并行差分隐私关联规则挖掘算法。算法利用Hadoop框架实现并行计算,利用负载均衡策略,使每一个节点分配到的数据量相当,利用指数机制挑选出k个频繁模式,采用拉普拉斯机制对这k个频繁模式添加噪音。通过实验对算法的频繁模式挖掘结果与同类算法进行比较分析,结果表明,该算法在保证挖掘结果具有可用性的前提下,在效率上较传统算法有所提升。
关键词:频繁模式挖掘;差分隐私;指数机制;并行计算
DOI:10.11907/rjdk.171559
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2017)009-0065-03
Abstract:In order to solve the problem of low efficiency of mining Top-k Association Rules Mining Algorithm Based on the differential privacy model in large scale data environment, a parallel algorithm for mining association rules based on differential privacy is proposed. The algorithm using Hadoop framework to realize parallel computing using the load balancing strategy, the amount of data so that each node is assigned to a selected K, using the index mechanism of frequent pattern, using the Laplasse mechanism add noise to these K frequent pattern. The results of the algorithm are compared with other algorithms. The experimental results show that the proposed algorithm can improve the efficiency of the mining algorithm than the traditional algorithm.
Key Words:frequent pattern mining; differential privacy; exponential mechanism; parallel computing
0 引言
随着大数据时代的到来,数据挖掘成为研究热点。而关联规则挖掘是数据挖掘中的一个重要研究课题。关联规则挖掘能够从数据中挖掘出潜在的项目之间的隐藏关系,如应用医疗数据挖掘疾病之间的关联,利用用户交易数据挖掘用户购买行为之间的关联等。然而对原始数据的发布会造成个人隐私泄漏,频繁模式挖掘是关联规则挖掘的核心,传统的频繁模式挖掘算法在面对海量数据时占用内存大、效率低。如何提高算法效率和数据的可用性,同时解决隐私保护问题成为关联规则分析的一个热点。鉴于此,提出一种并行差分隐私频繁模式挖掘算法。
1 相关工作
目前,在差分隐私模型下对频繁模式挖掘进行研究并取得了一定的研究成果。文献[1]利用指数机制选取支持度最大的k个模式,对其添加噪声得到top-k频繁模式。文献[2]利用θ-基以及映射技术提出了PrivBasis算法,首先由θ-频繁对构建出候选集合,接着对候选集合的频度添加噪声,最后选取k个作为top-k频繁模式。文献[3]考虑事务长度对全局敏感度的影响,提出智能截断和双重标准,有效提升了结果的可用性,但该方法只限于短事务居多的事务数据集。文献[4]利用指数机制从候选集中选取top-k频繁模式,并对选取的频繁模式进行噪音扰动,而后通过对结果进行二次规划,提升数据的可用性。目前,关于差分隐私频繁模式挖掘的研究虽已取得一定成果,但相关算法仍存在着消耗内存大、效率低的问题。文献[5-13]提出了并行频繁模式挖掘算法,利用Hadoop平台的多个节点并行运算算法,可以有效地实施并行化,但仍会产生大量候选项集,且当数据量大于数十万数量级时算法无法高效率运行。针对这一问题,本文提出基于指数机制和带负载均衡的分布式FP-growth算法的分布式差分隐私频繁模式挖掘算法(Parallel Differential Privacy Frequent Pattern Mining Algorithm,PDPFPM),拟在保证挖掘结果可用的前提下提升频繁模式挖掘效率,满足大数据的需求。通过与同类算法进行比较,验证了PDPFPM算法的可行性和有效性。
2 相关定义
2.1 差分隐私
定义1(邻近数据集):若数据集D1和D2有且仅有一条数据项的值不同,则称D1和D2为邻近数据集。
定义2(差分隐私):给定隐私保护算法f,若f对邻近数据集D1和D2的输出结果O∈Range(f)均满足下列不等式,则称算法f满足ε-差分隐私。Pr[f(T1∈0)]≤eε×Pr[f(T2∈0)]
(1) 其中,ε為隐私预算,衡量差分隐私保护的水平。由式(1)可知ε越小,隐私保护的水平越强。f是一个随机的算法,Range(f)表示算法f的取值范围。Pr[f(T∈0)]表示输出f(T)结果为O的概率。
定义3(全局敏感度):对于任意的查询函数q:D→Rd,函数q的全局敏感度为:Sq=max‖q(D1)·q(D2)‖endprint
(2) 其中,D1和D2是兄弟数据集,R表示所对应的实数空间,d表示查询q的查询维度,q(Di)表示查询函数q在数据集Di上的查询结果。
定理1(串行组合定理):给定一组随机算法f={f1,f2,…,fn},每个算法fi均在数据集T上实现了εi-差分隐私,其中i=1,2,…,n,则该组随机算法f在数据集T上实现了∑ni=1εi-差分隐私。
2.2 噪声机制
定义4(拉普拉斯机制):通过对数据添加服从拉普拉斯分布的噪声,实现差分隐私保护。其基本思想是对数据集D进行查询q,查询结果为q(D)。向q(D)添加噪声χ,其中χ是一个满足拉普拉斯分布的连续型随机变量,其概率密度函数为:Pr[χ]=12be|x-μ|b
(3) μ为期望,在差分隐私算法中一般μ取0,方差为2b2,b用来衡量添加噪声的大小。对于给定的查询函数q:D→Rd,若算法f的输出结果满足式(3),则算法f满足ε-差分隐私。f(D)=q(D)+〈Lap1(sqε),…,Lapd(sqε)〉
(4) 其中,Lapd(sqε)是相互独立的拉普拉斯噪声,拉普拉斯参数b=Sq/ε。
2.3 指数机制
定义5(指数机制[15]):对于给定的一个评价函数u:(D×0)→R,若算法f满足等式(5),则算法f满足ε-差分隐私。f(D,u)={r:Pr[r∈0]}∝exp(εu(D,r)Δu)
(5) 其中,r表示输出项,Pr(r∈0)表示r输出的概率,Δu为评价函数u的全局敏感度。其关键在于设计一个评价函数u,通过u得到输出结果集O中r的指数分布,r被选择输出的概率服從式(5)的概率分布。
3 并行差分隐私频繁模式挖掘算法
PDPFPM可以有效解决在海量数据下,运用FP-Growth算法进行频繁模式挖掘时,占用内存过多、效率低的不足,克服了MPI并行编程模型存在的节点失效、网络通信故障等缺点,同时在挖掘出频繁模式时,可以保护其支持度计数不被泄漏。
3.1 基本思想
首先,统计事务数据库中每一个项的支持度并找出所有频繁项,得到频繁F1项集(FList);其次进行计算量估计,Map 过程采用根据计算量估计的分割方式读入事务项,分发到不同的Reduce 节点。Reduce 过程对构造的FP-Tree 进行FP-Growth 挖掘得到局部频繁项集,再由指数机制Pr[c]=exp(ε1×c×r2×n)∑ni=0exp(ε1×ci×r2×n)选出n个频繁模式,对所选出的支持度计数添加拉普拉斯噪音,最后由局部频繁项集合并成全局频繁项集,选取支持度最高的n个。
3.2 基于计算量估计的分组策略
整个并行FP-Growth的计算量主要在于各节点的频繁模式的数量,而一般支持度高的项,其计算量较大。SSCE设定每项的估计计算量为C=∑ri=0Ci,其中r为每条数据的含有项集。将传入数据集前P个数据r的每一项作为一组,P为节点数,计算每一组的计算量,将下一条数据加入到最小的一组,重复计算直到整个数据集遍历完毕。
3.3 算法描述及流程
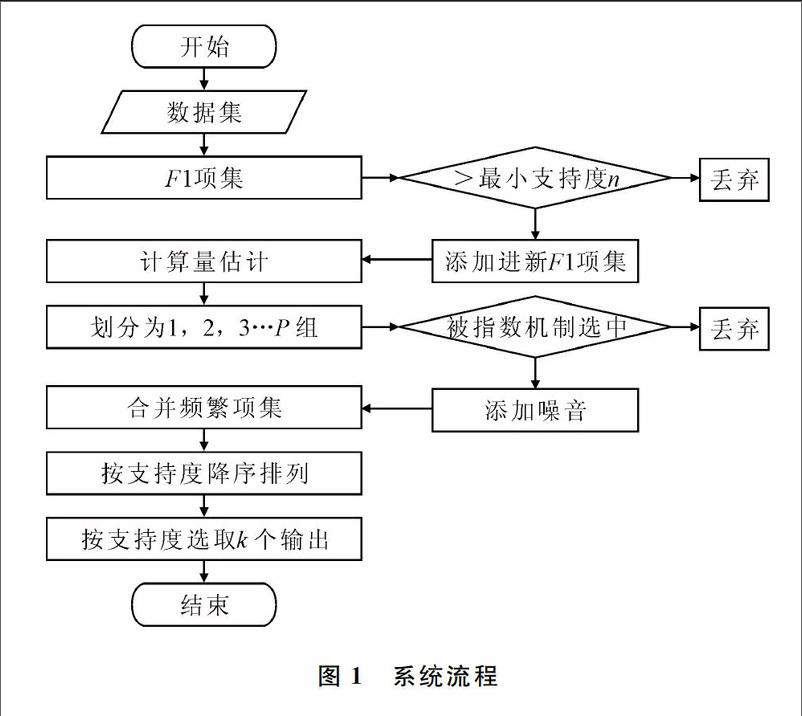
PDPFPM算法流程如图1所示。
步骤1:扫描数据集,统计频繁F1项集(FList)。Map过程:第一次全量扫描数据,计算出各自候选F1项集。Reduce过程:收集Map 阶段输出的中间结果,进行求和,统计每项在整个数据源中的支持度,舍弃小于最小支持度的项,得到FList并按支持度降序排列。
步骤2:计算量估计,进行数据划分。Map过程:第二次全量地访问数据集,遍历每条数据中的项,按SSCE分成P个组输出的key值为分组号p,value为去除小于最小支持度的子项集。Combiner过程:聚合每组中的数据,形成待处理的数据。
步骤3:添加噪音,进行隐私保护。此为加噪以及挖掘的一步,整个步骤为一个Reduce过程。建立FP-Tree,然后通过FP-Growth挖掘算法得到频繁项集,采用指数机制选出n个频繁模式,对其支持度添加Lap(kε2)噪音。
步骤4:局部频繁项集合并成全局频繁项集。读取HDFS 文件中的结果,相同局部频繁项集的支持度求和,得到全局支持度。按支持度降序排列,选择前n个保存,作为最后的全局频繁项集。
4 实验设计与分析
本文从数据可用性和算法性能的角度对PDPFPM算法进行分析,并与传统的频繁模式隐私保护算法进行比较。采用算法耗时来对算法性能进行衡量,采用准确率和召回率的调和平均值(F-score)对数据的可用性进行衡量,由于算法添加噪音具有随机性,取10次实验的平均值。
定义5(F-score) 设Rp为隐私保护后的挖掘结果,Ra为准确的挖掘结果。准确率(Precision)表示挖掘出的准确结果,召回率(Recall)表示准确结果被挖掘出的概率,由定义可以看出,准确率和召回率是一对互斥的标准,采用F-score将两者结合,F-score值越大,数据的可用性越高。Precision=Rp∩RaRp
(5)
recall=Rp∩RaRa
(6)
F-score=2×precision×recallprecision+recall
(7)4.1 实验设置
实验采用IBM研究团队开发的数据生成器生成T10I4D100K数据集,对PDPFPM算法的数据可用性和算法性能进行分析。
4.2 实验结果分析
隐私预算ε1和ε2各取0.5,计算F-score的取值,与DP-topkP[4]相比发现PDPFPM算法F-score的值比DP-topkP有所下降,这主要是由于分布式处理时,各单节点添加的噪音造成噪音积累,因此造成了F-score的下降,实验结果如表2所示。endprint
通过实验验证算法的性能,实验结果如表3所示(时间单位:s)。可以发现,PDPFPM算法处理时间提升同时隐私保护水平相当。
频繁模式挖掘的隐私保护日益成为大数据分析的基础之一,频繁模式挖掘受到了大量数据分析者的青睐,针对传统基于ε-差分隐私模型的top-k关联规则挖掘算法在大规模数据环境下挖掘效率低下的问题,提出PDPFPM算法,实验表明其可以有效解决算法的性能问题。
参考文献:
[1] BHASKAR R, LAXMAN S, SMITH A, et al. Discovering frequent patterns in sensitive data[C].Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2010:503-512.
[2] LI N, QARDAJI W, SU D, et al. PrivBasis:frequent itemset mining with differential privacy[J].Proceedings of the Vldb Endowment,2012,5(11):1340-1351.
[3] ZENG C, NAUGHTON J F, CAI J Y. On differentially private frequent itemset mining[J]. Proceedings of the Vldb Endowment,2012,6(1):25-36.
[4] ZHANG X, WANG M, MENG X.An accurate method for mining top-k frequent pattern under differential privacy[J]. Journal of Computer Research & Development,2014,51(1):104-114.
[5] FANG M,SHIVAKUMAR N,GARCIA-MOLINA H,et al.Computing iceberg queries efficiently[C].Proceedings of the 24rd International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc.,2000:299-310.
[6] QURESHI Z,BANSAL J,BANSAL S.A survey on association rule mining in cloud computing[J]. International Journal of Emerging Technology and Advanced Engineering,2013,3(4):2250-2459.
[7] ASHRAFI M Z, TANIAR D, SMITH K.ODAM: An optimized distributed association rule mining algorithm[J]. Distributed Systems Online IEEE,2004,5(3):1.
[8] LI L,ZHANG M.The Strategy of mining association rule based on cloud computing[C].International Conference on Business Computing and Global Informatization.IEEE Computer Society,2011:475-478.
[9] SANJEEV R, GUPTA P. Implementing improved algorithm over apriori data mining association rule algorithm[J]. IJCST,2012,3(1):2250-2459.
[10] CHEN S Y, LI J H, LIN K C, et al.Using MapReduce framework for mining association rules[M]. Information Technology Convergence. Springer Netherlands,2013:723-731.
[11] RIONDATO M, DEBRABANT J A, FONSECA R, et al. PARMA:a parallel randomized algorithm for approximate association rules mining in MapReduce[C].ACM International Conference on Information and Knowledge Management,2012:85-94.
[12] YANG X Y, LIU Z, FU Y. MapReduce as a programming model for association rules algorithm on Hadoop[C]. International Conference on Information Sciences and Interaction Sciences,2010:99-102.
[13] LI N, ZENG L, HE Q, et al. Parallel implementation of apriori algorithm based on MapReduce[C]. Acis International Conference on Software Engineering, Artificial Intelligence,NETWORKING and Parallel & Distributed Computing,2012:236-241.
(責任编辑:孙 娟)endprint
