一种基于融合的词袋模型和大裕度最近邻分类算法的图像识别方法
2017-09-18,
,
(上海师范大学 信息与机电工程学院,上海 200234)
一种基于融合的词袋模型和大裕度最近邻分类算法的图像识别方法
杨亦波, 王斌*,王剑锋
(上海师范大学 信息与机电工程学院,上海200234)
图像分类作为图像处理和计算机视觉的重要组成部分,能够快速准确地对数字图像进行分析和管理.对基于bagofword(BOW)模型的分类问题进行了研究,针对图像理解中的图像相似度之间的关系,提出了一种最大间隔最近邻居分类算法,通过对成对约束的度量学习算法,在优化目标中增加原空间数据分类的约束,学习到了一个可以反映当前样本数据的距离函数,并且在k-NearestNeighbor(KNN)分类器上使用该学习到的距离函数来构建分类器,并在多个国际标准图像数据集上进行实验,结果表明:该算法相比传统的基于欧式距离的算法具备更高的正确率.
图像分类; 词袋模型; 大裕度最近邻分类算法
0 引 言
超过80%的自然界信息都是通过视觉被人类所接收的,而图像又作为视觉信息的基础载体,具有呈现直观、内容复杂多变、蕴含丰富信息等特点.随着数字互联网的蓬勃发展,社会生活数字化程度逐渐加深,包含视觉信息的数字图像数量增长迅猛,并广泛地充斥于人们的生活当中.因此,人们急切地需要依据计算机来智能地理解这些数字图像的语义内容及信息,进而便于数字图像的智能化管理、分析及应用.
近几年来,有大量关于图像理解的研究成果发表在国际顶级学术期刊以及顶级学术会议上.图像理解的定义为:利用计算机从影像中提取被摄景物的语义信息,以实现识别、分类和判读的过程[1].其主要的任务就是对图像中的实体进行识别、判断图像所表达的主题和分析图像中所包含的语义信息.
由于图像是非结构化的数据,并没有一个原始的自然的向量表达形式,很多传统的基于向量空间输入的机器学习算法对此并不适用.近年来,图像bag of word(BOW)模型受到了非常广泛的关注,并且在各种场景图像分类任务中都取得了非常好的效果.在早期的基于BOW模型的分类方法中[2],常常假定图像局部区域之间是彼此独立的.Wang[3]释放独立性假设条件,对图像局部区域之间的关系进行显示建模.Wu[4]于2007年提出了一种基于视觉语言模型的方法,其将每幅图像都转化为视觉单词的矩阵并假设视觉单词之间是条件相关的.随后,Tkmy[5]提出了一种新的视觉语句图像表示方法,该方法在BOW模型的基础上利用视觉单词之间的空间关系构成相应的“句子”,然后再对图像进行分类.
对于构建好的BOW模型,现有的大部分图像相似度比较方法都是使用向量空间的距离函数作为图像相似度的衡量准则,并在经典的机器学习分类器上进行学习和判断.其本质就是把每一副用于训练的图像通过某种函数关系映射到欧式空间里的一个点,并利用欧式空间的良好性质在其中进行分类器的训练和学习.最常用的就是k-NearestNeighbor(KNN)分类器,其基本原理是根据与测试样本最近的k个训练样本的类别来决定测试样本的类别.最初用于解决文本分类的问题,后来广泛地应用于模式识别的各个领域.虽然KNN应用很广,但KNN中点与点之间的距离通常采用欧式距离度量,该距离对所有属性特征同等对待,忽略了属性特征间的主次关系,没有突出不同的属性特征对分类带来不同的影响,因此会降低分类器的性能.为了克服欧氏距离的缺点,本文作者提出了一种大裕度最近邻的度量学习算法,通过对样本的训练学习到模型间的内在关系,更好地提高了分类的效果.
1 词袋模型及图像分类流程
1.1BOW模型
BOW模型最早出现在自然语言处理(NLP)和信息检索(IR)领域中[6],常被用于处理文档的识别与分类.如下两个句子:(1)John likes to watch movies.Mary likes too.(2)John also likes to watch football games.根据这两句话中出现的单词,先构建一个单词的词典,如下{1‘John’,2‘likes’,3‘to’,4‘watch’,5‘movies’,6‘also’,7‘football’,8‘games’,9‘Mary’,10‘too’}.这个词典中包含了所有10个单词,每个单词有着它自己的唯一索引,根据这个词典,统计每个单词所出现的次数,就能够将上述两句话重新表达为下面两个变量:(1)[1,2,1,1,1,0,0,0,1,1],(2)[1,1,1,1,0,1,1,1,0,0],然后就可以直接计算这两个向量间的距离知道这两句话是否相似.
近些年来,BOW模型因其简单且行之有效的优点得到了更加广泛的应用,受BOW模型在文档分类中的启发,Li等[7]利用BOW模型将图像类比为文档提出了用BOW模型表达图像的方法.文档和图像在BOW模型下的对应关系如下:
文集对应图像集,单词对应视觉单词,词典对应视觉词典.
1.2图像分类的基本流程
如今,BOW模型被广泛地应用到图像的目标分类与场景分类中,在基于BOW的模型的图像分类技术中,通常包含了如下3个主要部分:1)特征提取;2)视觉词典构造;3)分类器的训练.特征提取主要是从给定的图像集中提取全局或者局部不变特征,得到图像的表示.视觉词典的构造主要是对提取的图像特征进行聚类,将聚类中心作为视觉单词,所有聚类中心的集合即为构造的视觉词典.分类的训练是针对于要进行的图像分类任务所进行的操作,结合训练的分类器即可进行图像的分类与识别.图1给出了BOW模型应用于图像分类的基本流程,首先提取训练图像和测试图像,然后用简单的k-means聚类方法将提取的特征聚成300类,如此,每张训练图像和测试图像就可以用一个300维的向量表示了.接着,将训练图像输入到分类器里,调整分类器的各个参数,再用训练好的分类器来预测测试图像,得到其分类结果.
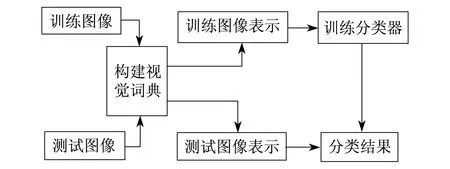
图1 图像分类的基本流程图
2 Large Margin Nearest Neighbor(LMNN)算法
在所有的分类器中,KNN算法是最简单有效的分类算法,但是KNN忽略了属性特征之间的主次关系,会降低分类器的性能.因此,为了克服欧氏距离的缺点,Xing在文献[8]中提出了基于成对约束度量学习框架的LMNN算法.
LMNN算法是一种基于马氏距离的分类方法,该方法的原理是通过最小化目标函数,来缩小同类样本之间的距离,加大属于不同类样本之间的距离.设n维欧式空间中的两个点x=(x1,x2,…,xn)T和y=(y1,y2,…,yn)T,则点x和y之间的马氏距离为:
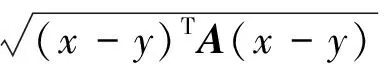
(1)
其中,A必须是一个半正定的矩阵,才能够保证M的度量性.矩阵A实际上包含了对原空间坐标的线性变换和伸缩操作.可以对A进行特征分解,分解为A=VTDV,其中V是A的特征向量组成的矩阵,D是对角阵并且其各个元素分别对应矩阵A的特征值,则有:

(2)
(2)式中矩阵A实际上是通过线性变换V作用到样本点上,然后对每一个坐标进行伸缩处理(乘以D).在度量学习问题中,这是一个优化问题,可以通过确定矩阵A,得到符合一定条件和要求的度量函数.而在Xing[8]的工作中,增加了同类样本之间的成对约束来求解这个优化问题,最终可以来确定A矩阵中的参数.形式上,该优化问题可以表述如下:
(3)
(4)
A≥0.
(5)
(3)、(4)式中集合S表示同类样本对所组成的集合,D表示不同类样本对所组成的集合.该优化问题要求不同类样本对之间的距离之和大于等于一个常数,而优化的目标是使相同类别的样本对之间的距离和尽可能的小.文献[9]中提出了一个梯度下降的迭代算法,来求解满足条件的A.该算法虽然能够很好地找出满足条件的A矩阵,但是面对十分庞大的样本数据集,计算的复杂程度也明显上升,这是由于当训练样本集比较大时,所构造出来的集合S和D反应的是样本对之间的关系,也会非常大.假设对于两分类的训练集,训练样本集的大小为L,其中正例有P个,反例有N个,则同类样本对的集合S中元素的个数为(P2+N2)/2-P-N个,而不同类样本对的集合D中元素个数为PN/2个[10].因此在实际问题中往往随机从S和D中抽取一些元素进行优化.
3 实验过程
3.1实验数据
本算法是在Matlab平台上搭建图像检索系统实现的,实验开始时首先将训练集与测试集的图片一起加载入系统,采用简单的k-means聚类方法得到数据集的视觉词典,构建好词袋模型.接着用训练集的构建好的词袋来训练分类器,由于数据庞大的原因,首先在每个类别中只选择10个样本进行训练,这100个样本两两构成约束对,利用梯度下降法得到最小的误差以及对应的距离矩阵.若误差不满足预期的要求,则每个类别增加5个样本,以此类推,直到求得符合预期要求的距离矩阵.本实验选用了4个国际标准的图像分类集,分别是CVCL、Caltech101中选取10类、Ground Truth中8类、Corel中10类.其中CVCL和Corel这2个图像集中每一类别的图片的大小是相同的,而Caltech 101和Ground Trurh中每类图片的大小层次不齐.具体数据集的相关属性如表2所示.

表2 样本数据集
3.2实验分析
在实验中,对比了传统基于欧氏距离的KNN以及基于马氏距离的可学习的LMNN算法,其中KNN和LMNN算法中K取值为3.KNN算法只是根据最近邻的3个样本来确定该图像属于的类别,由于选取的数据集都不是很大,因此LMNN通过所有训练集的样本来学习得到一个适合的矩阵,然后来预测测试集的类别,用准确率作为判别算法优劣的准则.实验数据如表3所示.

表3 各数据集预测准确率 (%)
从表3中数据可以反映出,运用本文算法后,在各个数据集上预测的准确率都有明显的提升,在某些测试集上准确率相比传统算法提高了将近20个百分点,这结果令人较为满意.
一个完美的图像分类模型预测结果与实际一致,但在实验过程中,该模型的预测与实际之间存在误差.为了探测模型预测的正确率,引入“混淆矩阵”.
通过比较计算每个实测像元与分类图像的位置和分类,可以得出混淆矩阵.其每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实际的数目.如图2所示,在LMNN算法下,4个图像数据集的混淆矩阵.

图2 LMNN中4个数据集的混淆矩阵
从实验结果可以看出,LMNN比KNN在这4个数据集上预测分类的结果正确率较高,但是对于Caltech101和Ground Truth这2个数据集,两种算法都有较高的错误率,可能是由于图片大小不同,在建立BOW模型时,特征提取方面存在问题,这将是未来研究需要改善的地方.
4 结 论
本文作者融合了BOW词袋模型和度量学习中的LMNN大裕度最近邻分类算法,提出了一种新的图像分类算法.BOW词袋模型最早用于文档的分类中,运用到图像分类中可以大大减少训练样本的输入维度,方便计算.LMNN算法是对传统KNN算法的改进,传统的KNN只是简单地计算2个样本的欧氏距离,而LMNN算法的思想是要求同类样本之间的距离尽可能小,而非同类样本之间的距离要大于等于某个固定的常数,根据这个条件,就可以优化出一个满足要求的矩阵.通过在4个国际标准的图像数据集上的实验,也证明了该算法能在一定程度上提高分类性能.但是,在实验过程中也遇到了许多新的问题,比如对于不同大小,不同像素的图像,BOW词袋模型也具有一定的局限性.对于K数值的确定,为了减少计算量,取值为3,但是提高K值是否会提高分类性能,或者对于不同数据集是否都有一个最佳的K值,这些都是要在未来作进一步深入研究和探讨.
[1] Chen Y,Wang J Z.Image categorization by learning and reasoning with regions [J].Journal of Machine Learning Research,2004,5(4):913-939.
[2] Sivic J,Russell B C,Efros A A,et al.Discovering object categories in image collections [R].Cambridge:Massachusetts Institute of Technology Computer Science & Artificial Intelligence Laboratory,2005.
[3] Wang G,Zhang Y,Li F F.Using dependent regions for object categorization in a generativeFramework [C].2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,New York:IEEE,2006.
[4] Wu L,Li M,Li Z,et al.Visual language modeling for image classification [C].Proceedings of the 9th ACM SIGMM International Workshop on Multimedia Information Retrieval,Augsburg:ACM,2007.
[5] Tirilly P,ClaveauV,Gros P.Language modeling for bag-of-visual words image categorization [C].Proceedings of the 7th ACM International Conference on Image and Video Retrieval,Niagara Falls:ACM,2008.
[6] Lewis D D,Jones K S.Natural language processing for informationretrieval [J].Communications of the ACM,1996,39(1):92-101.
[7] Li F F,Perona P.A bayesian hierachical model for learning natural scene categories [C].IEEE Computer Society Conference on IEEE,2005,2(2):524-531.
[8] Xing E P,Ng A Y,Jordan M I,et al.Distance metric learning with application to clustering with Side-information [J].Advances in Neural Information Processing System,2002,15:505-512.
[9] Schutz M,Joachims T.Learning a Distance Metric from Relative Comparisons [C].Proceedings of the 16th International Conference on Neural Information Processing Systems,Whistler:ACM,2003.
[10] Davis J V,Kulis B,Jain P,et al.Information-theoretic metric learning [C].Proceedings of the 24th international conference on Machine learning,Corvallis:ACM,2007.
(责任编辑:包震宇)
Animagerecognitionmethodbasedonbag-of-wordmodelandlargemarginnearestneighborclassificationalgorithm
Yang Yibo,WangBin*,WangJianfeng
(The College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai200234,China)
As an important part of image processing and computer vision,image classification can analyze and manage digital images quickly and accurately.This paper studies the classification problem based on bag of word (BOW)model and learns the relationship between image similarities in image comprehension.Then,this paper proposes a maximum-interval Nearest Neighbor classification algorithm.By learning the pair-wise constraint metric and adding the constraint of the original spatial data classification to the optimal target.This paper learns a distance function which can reflect the current sample data and uses this function to construct the classifier according to thek-NearestNeighbor(KNN) classifier.Compared with the traditional Euclidean distance algorithm,the classifier based on metric learning has higher correct rate than the traditional one based on the experiments on several international standard image datasets.
image classification; bag of word model; large margin nearest neighbor classification algorithm
2016-11-27
国家自然科学基金(61503251)
杨亦波(1992-),男,硕士研究生,主要从事图像处理方面的研究.E-mail:530056910@qq.com
导师简介: 王 斌(1986-),女,讲师,主要从事图像处理方面的研究.E-mail:binwang@shnu.edu.cn
TP391
:A
:1000-5137(2017)04-0584-06
*
