基于Hive的性能优化研究
2017-09-18,*,
, *,
(1.上海师范大学 信息与机电工程学院,上海 200234; 2.南京航空航天大学 计算机科学与技术学院,南京 211106)
基于Hive的性能优化研究
王 康1,陈海光1*,李东静2
(1.上海师范大学 信息与机电工程学院,上海200234;2.南京航空航天大学 计算机科学与技术学院,南京211106)
主要从MapReduce作业调度和Hive性能调优两个方面对Hive的性能优化进行研究.对于MapReduce主要从编程模型切入,分析其执行过程,并从map端、reduce端进行参数调优.接着从Hive框架角度入手,分别从分区表和外部表以及常用数据文件的压缩、行式存储与列式存储等方面进行深入研究.实验结果表明,snappy压缩、orcfile/parquet存储格式对于列式查询,提高查询效率,对于大数据分析平台有较好的兼容性.
数据仓库; 作业调优; 性能优化; 压缩; 存储格式
在大数据背景下,数据仓库的应用主要分为即联机分析处理(Online Analytical Processing,OLAP)和即联机事务处理(Online Transaction Processing,OLTP)两种.其中,OLAP类型主要是统计分析型查询,如max、min等操作,读取整行数据查询的可能性比较小;OLTP类型主要是事务型的查询,一般是完整读一行数据,IO开销比较大;大数据背景下信息爆炸,使得分布式/并行计算变得非常重要.从单机应用到集群应用的过渡中,诞生了MapReduce这样的分布式计算框架[1],简化了并行程序的开发,提供了水平扩展和容错能力.在互联网企业(如电商、游戏行业)中,对于存储和分析每天订单日志数据的需求变得越来越迫切,因此由Facebook用于解决海量结构化日志的数据统计开源数据仓库Hive越来越受欢迎,从2010年下半年开始,Hive成为Apache顶级项目.
1 Hive与MapReduce
Hive是一个基于Hadoop的数据仓库工具[2],通过Hive可以方便地进行数据提取转化加载(ETL)的工作.Hive定义了一个类似于SQL的查询语言HQL,能够将用户编写的SQL转化为相应的MapReduce程序.
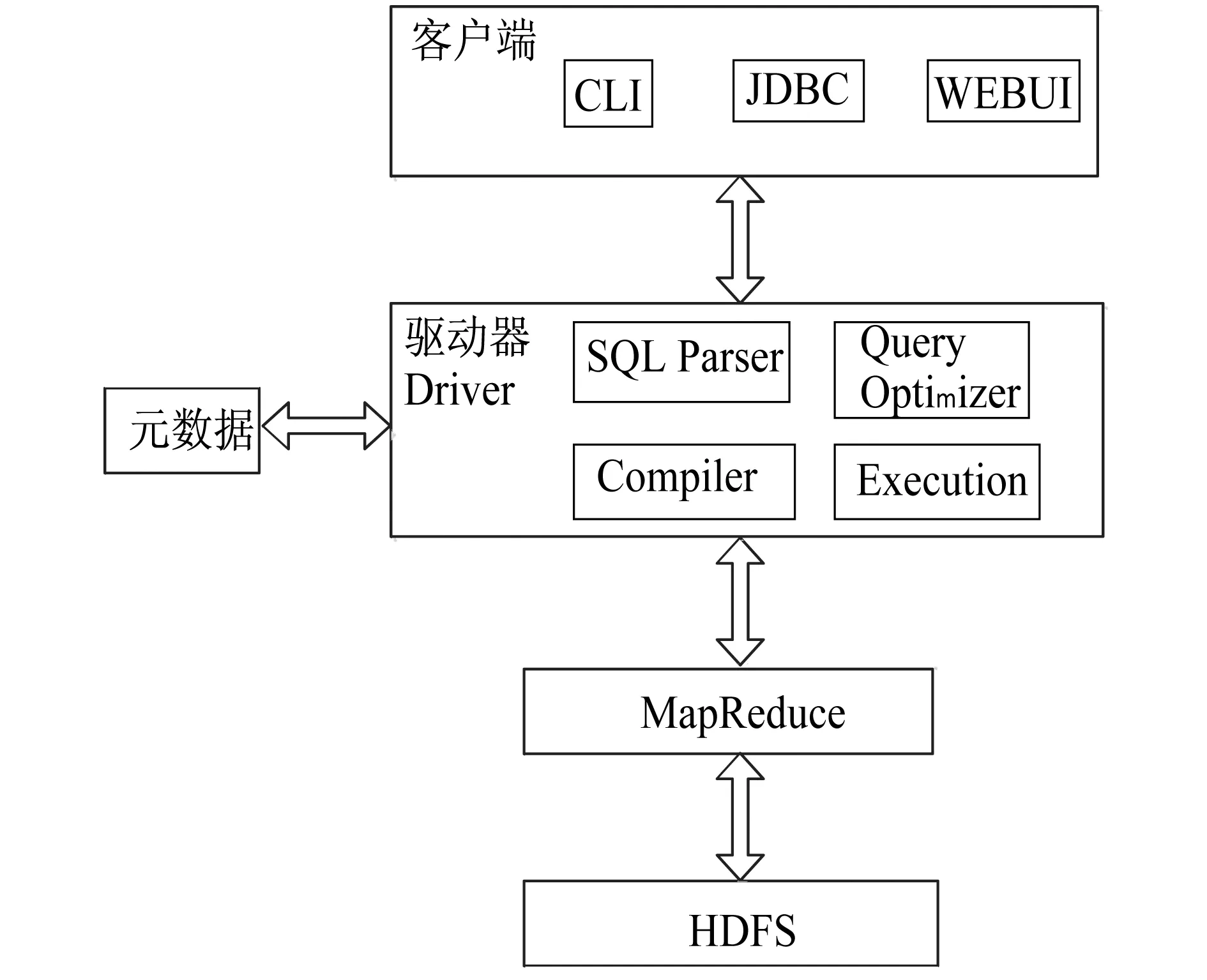
图1 Hive架构
Hive架构如图1所示.客户端主要分为CLI(hive shell)、JDBC(java访问hive)、WEBUI(浏览器访问hive,如Hue)等方式.元数据通常采用MySQL存储,主要存储表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等.驱动器Driver主要包含解析器、编译器、查询优化器、执行器.其中,解析器SQL Parser将HQL字符串转换成抽象语法树AST,这一步一般通过第三方工具库完成.比如antlr主要对AST进行语法分析,比如表、字段是否存在,SQL语义是否有误(比如select中被判定为聚合的字段在group by中是否有出现).编译器Compiler将AST编译生成逻辑执行计划,查询优化器Query Optimizer对逻辑执行计划进行优化,执行器把逻辑执行计划转换成可以运行的物理计划,对于Hive来说,就是MapReduce.最后通过执行这些MapReduce任务完成查询任务和数据处理.
因此对Hive优化来说,主要分为底层的MapReduce作业调优[3-4]和Hive性能调优两大部分,将分别在第二节和第三节进行分析.
2 MapReduce作业调优
2.1MapReduce编程模型
MapReduce是一种分布式计算模型,主要解决海量数据的计算问题[5].MapReduce将整个并行计算过程抽象到两个函数[6]:(1)map(映射).对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行;(2)reduce(化简).对一个列表的元素进行合并.
MapReduce的总体执行流程主要分为五个部分:input→map→shuffle→reduce→output,如图2所示[7].map和reduce函数的输入和输出都是键/值对(K/V对).对于hadoop应用开发人员需要实现的接口有:InputFormat、RecordReader、Mapper、Partitioner、Combiner、Reducer、OutputFormat.其中,InputFormat接口用于将输入文件解析成逻辑上的输入分片(InputSplit,其大小默认是一个文件块大小128 MB,数量决定map task的个数),并将它们分割成K/V对形式的记录,默认类型TextInputFormat;RecordReader接口从输入分片读取记录并将其解析成K/V对,并交由map处理,一般使用默认方式LineRecordReader即可;Mapper主要负责解析输入的K/V对,并产生一些中间K/V对,通常遵循格式如map(k1,v1) →list(k2,v2),一般来说map函数的输入K/V的类型(k1和v1)不同于输出类型(k2和v2);Partitioner接口用以指定map task产生的K/V对交由哪个reduce task处理;Combiner接口完成map节点内的规约,即进行map端的reduce操作,使得map的输出更为紧凑,传递给reduce的数据更少;Reducer完成对多个map任务的输出进行合并、排序,执行reduce函数自己的逻辑,对输入的K/V处理,转换成新的K/V输出,通常遵循格式如reduce(k2,list(v2))→list(k3,v3);reduce函数的输入类型必须和map函数的输入类型相同,输出类型(k3和v3)可以不同于输入类型;OutputFormat用于将reduce输出的K/V对写到类似于Hadoop分布式文件系统(HDFS)上[8-9].
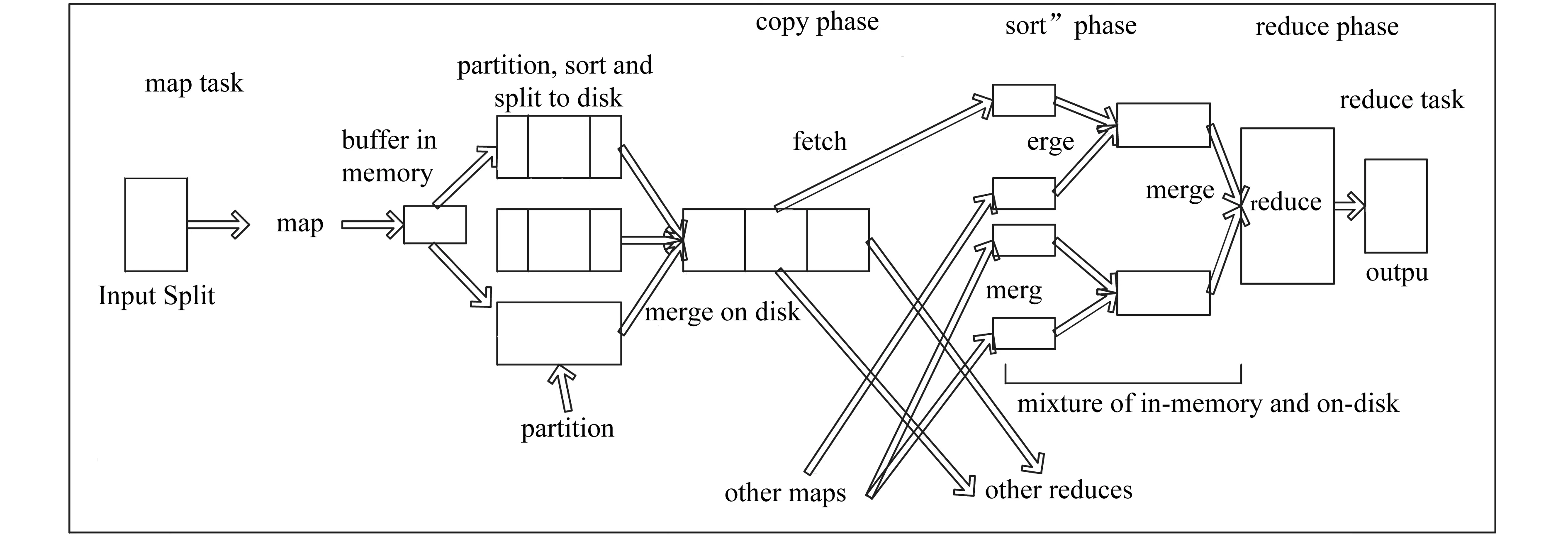
图2 MapReduce处理流程图
但实际上,开发人员只需要完成Mapper和Reducer接口的设计.对于少数简单的应用,甚至连Reduce接口都不用实现.这大大降低了并行编程的技术难度和工作量,其他并行编程中的种种复杂问题,如分布式存储、工作调度、负载平衡、容错处理、网络通信等,均由YARN框架负责处理.从map输出到reduce处理数据的中间的这个过程称为shuffle[10],这个过程是MapReduce的核心,在接下来的两小节围绕这个过程展开进行优化.
2.2map端调优参数
2.2.1 mapreduce.task.io.sort.mb
当map task开始运算,其产生的中间K/V对并非直接写入磁盘,而是利用内存buffer执行缓存,并在内存buffer中进行一些预排序优化整个map的性能[11].如图2所示,每一个map都会对应存在一个内存buffer(图2中的buffer in memory),map会将已经产生的部分结果先写入到该buffer中,当buffer达到一定阈值,会启动一个后台线程对buffer的内容进行排序,然后写入本地磁盘(spill文件).这个buffer默认是100 MB大小,对于大规模集群可以将这个参数调大,用以减少磁盘I/O.
2.2.2 mapreduce.map.sort.spill.percent
这个参数值就是buffer的阈值,默认是0.80,当buffer中的数据达到这个阈值,后台线程会对buffer中已有的数据进行排序,然后写入磁盘.这个参数同样也是影响spill执行的频繁程度,进而影响map task对磁盘I/O的频率,但通常不需要人为调整,调整io.sort.mb参数对用户来说更加方便.
2.2.3 mapreduce.task.io.sort.factor
当map task的计算部分全部完成后,如果map有输出,就会生成若干个spill文件,这些文件就是map的输出结果.map在正常退出之前,需要将这些spill文件合并(merge)成一个文件.merge的过程中,执行merge sort的时候,每次同时打开多少个spill文件由该参数决定,默认值10.当map的中间结果非常大,调大io.sort.factor有利于减少merge次数,进而减少map对磁盘的读写频率,达到优化作业的目的.
2.2.4 mapreduce.map.output.compress和mapreduce.map.output.compress.codec
减少中间结果读写进出磁盘的方法还有压缩.map的过程中,无论是spill的时候,还是最后的merge结果,文件都是可以压缩的.压缩的好处在于减少写入读出磁盘的数据量.如果对中间结果进行压缩,需要将这2个参数分别设置为true(默认值false不压缩)及org.apache.hadoop.io.compress.DefaultCodec(默认值),关于是否压缩及压缩方式的权衡在3.2节将进行详细介绍.
2.3reduce端调优参数
2.3.1 mapreduce.reduce.shuffle.parallelcopies
当job(mapreduce.job.reduce.slowstart.completedmaps参数控制)已完成5%的map tasks数量之后reduce开始进行shuffle,从不同的已经完成的map上下载属于自己这个reduce的部分数据.由于map通常有许多个,所以对一个reduce来说,下载也可以是并行地从多个map下载,可以通过这个参数来调整并行度.如果一个时间段内job完成的map有100个或者更多,那么reduce最多只能同时下载5个map的数据.所以当map很多并且完成得比较快的情况下调大该参数,有利于reduce更快地获取属于自己的数据,对于大集群可调整为15~20.
2.3.2 mapreduce.reduce.shuffle.input.buffer.percent
reduce在shuffle阶段对下载的map数据,并不立刻写入磁盘,而是会先缓存在内存中,然后当内存使用达到一定量的时候才刷入磁盘.这个参数(默认值0.7)是shuffle在reduce内存中的数据最多使用内存量为:0.7×reduce task的最大heap使用量(通常通过mapred.child.java.opts来设置).如果reduce的heap由于业务原因调整得比较大,相应的缓存大小也会变大.
2.3.3 mapreduce.reduce.shuffle.merge.percent
假设reduce task最大内存使用量为1 GB(-Xmx1024m),2.3.2节参数为0.7,则约700 MB内存用来缓存从map端copy过来的数据.而这700 MB的缓存数据,需要写入磁盘完成spill操作.与map端相似,内存使用到定义百分比程度就开始往磁盘写,默认值是0.66.调整此参数的目的是避免下载速度过快造成reduce端缓存来不及释放的问题.
2.3.4 mapreduce.task.io.sort.factor
reduce将map结果下载到本地时,也是需要进行merge的,所以这个参数的配置选项同样会影响reduce进行merge时的行为,该参数的详细介绍2.2节已提及.
2.3.5 mapreduce.reduce.input.buffer.percent
在reduce过程中,内存中保存map输出的空间占整个堆空间的比例.默认值为0,在reduce任务开始之前,所有map输出都被合并到磁盘上,以便reduce提供尽可能多的内存.如果reduce计算需要的内存比较小,可以增加此参数值来最小化访问磁盘的空间,加速数据读取速度.
2.4其他优化技术
对于Hadoop 2.x版本的集群,可以将NameNode配置成基于QJM(Quorum Journal Manager)方式的高可用集群[3-4],来避免单点故障.此外,可以通过配置fs.trash.interval属性(以min为单位的垃圾回收时间,默认值0,垃圾回收机制关闭)来启动垃圾回收机制,一般可以设置成10 080 min,即被删除的文件在回收站中保留7 d.针对MapReduce小作业,开启uber模式(mapreduce.job.ubertask.enable,默认值false,将其设置成true)使得该作业在一个Java虚拟机(JVM)中运行,省去启动多个JVM的时间.
3 Hive性能调优
3.1分区表和外部表
和传统的数据库相比,Hive也是将数据存储于表中,表的每一列都有一个相关的类型.分区表实际上就是对应一个HDFS文件系统[8-9]上的独立的文件夹,该文件夹下是该分区所有的数据文件.Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成更小的数据集.在查询时通过where子句中的表达式来选择查询所需要的指定的分区,这样的查询效率会提高很多.例如通过“select * from click_log where ds=′20151111′”语句选取查询所需要的分区目录,其中ds为分区的字段,这样查询时可以降低磁盘I/O、网络I/O,提高查询效率.
Hive中表主要分为内部表和外部表两种.内部表也称之为MANAGED_TABLE,默认存储在/user/hive/warehouse目录下,也可以通过location指定,删除表时会删除表数据以及元数据.外部表称之为EXTERNAL_TABLE,在创建表时可以自己指定目录位置,删除表时只会删除元数据不会删除表数据.
3.2数据文件的压缩
数据压缩其实就是对数据进行编码的过程,它能够减少存储空间和网络传输时间.数据压缩类型主要分为2种:第一种是无损压缩,压缩过程中重复数据会被删除,解压的时候会被添加进来.常见的无损压缩方法有Run Length Encoding、Lempel-Ziv-Welch Encoding、Huffman Encoding.无损压缩不能忍受任何数据丢失,用于法律或医学类文档、计算机程序等重要类文档;第二种是有损压缩,常见的有损压缩类型有图片JPEG、音频MP3、视频MPEG.有损压缩后的细微变化,无法用肉眼观察.
数据压缩的优点是能够提高I/O效率,节省存储空间和提高网络传输速度并减少网络负载.缺点是CPU利用率和处理时间的增加.因此CPU处于空闲状态可以考虑压缩,如果集群CPU被MapReduce作业占满,那么就不应该考虑压缩.
为了测试常用的bzip2、gzip、lzo、snappy等压缩格式,对1.4 GB的纯文本原始文件进行压缩对比,测试环境机器配置为:内存:8 GB,硬盘:1 TB,CPU:8core i7,网络:1个1 000 MB网卡,操作系统:CentOS 6.4-64 bit.实验结果如图3、4所示.
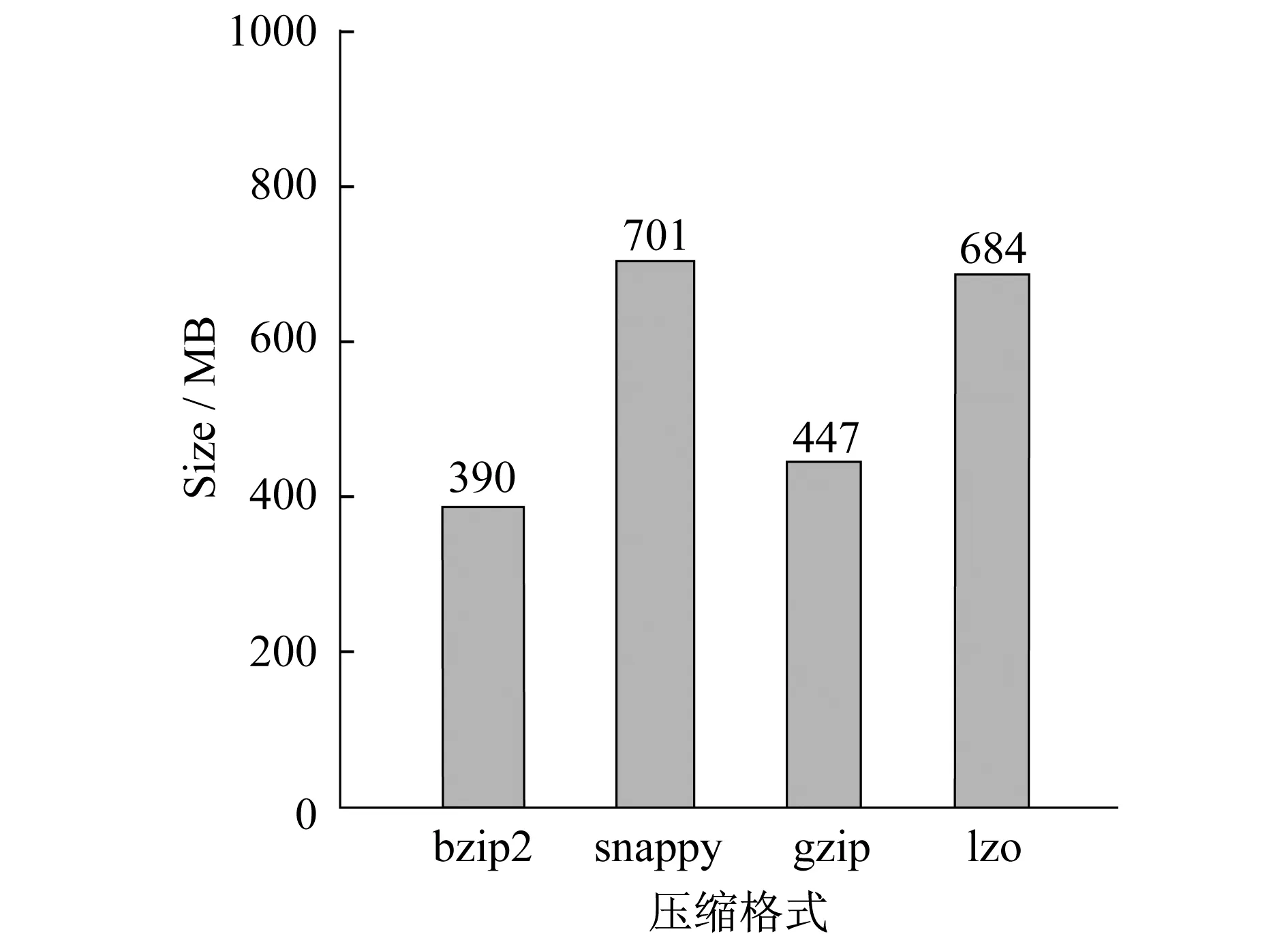
图3 不同压缩格式压缩比对比

图4 不同压缩格式压缩解压时间对比
从实验结果可以得出,压缩比排序为:bzip2>gzip>lzo>snappy,其中bzip2最节省存储空间.解压速度排序为:lzo>snappy>gzip>bzip2,其中lzo解压速度是最快的.历史数据可以选用一些压缩比高的压缩方式,如bzip2,降低存储空间.一些新的数据或热点数据(即访问量比较多的Hive表)可以采用解压速度比较快的压缩方式,如lzo、snappy等.因此,压缩方式的权衡主要是存储资源和计算资源之间的权衡,主要取决于CPU资源的繁忙程度.压缩比高(如bzip2)在存储、计算时占用资源比较多,解压速度就比较慢.
3.3数据存储格式
3.3.1 行式存储
3.3.1.1 TextFile
当通过“create table mylog(user_id bigint,page_url string,unix_time int)stored as textfile;load data inpath ′/user/myname/log.txt′ into table mylog;”两条HQL语句创建Hive表并从HDFS上加载数据时,默认的存储格式是stored as textfile(纯文本存储),数据不做压缩,磁盘开销大.TextFile具有以下特点:(1)解析开销大;(2)没有schema(类似关系型数据库中的列);(3)每个字段之间用分隔符分割;(4)不具备类型,所有的数据都是字符串类型.例如年龄age=10,将年龄当做字符串来处理.
3.3.1.2 SequenceFile
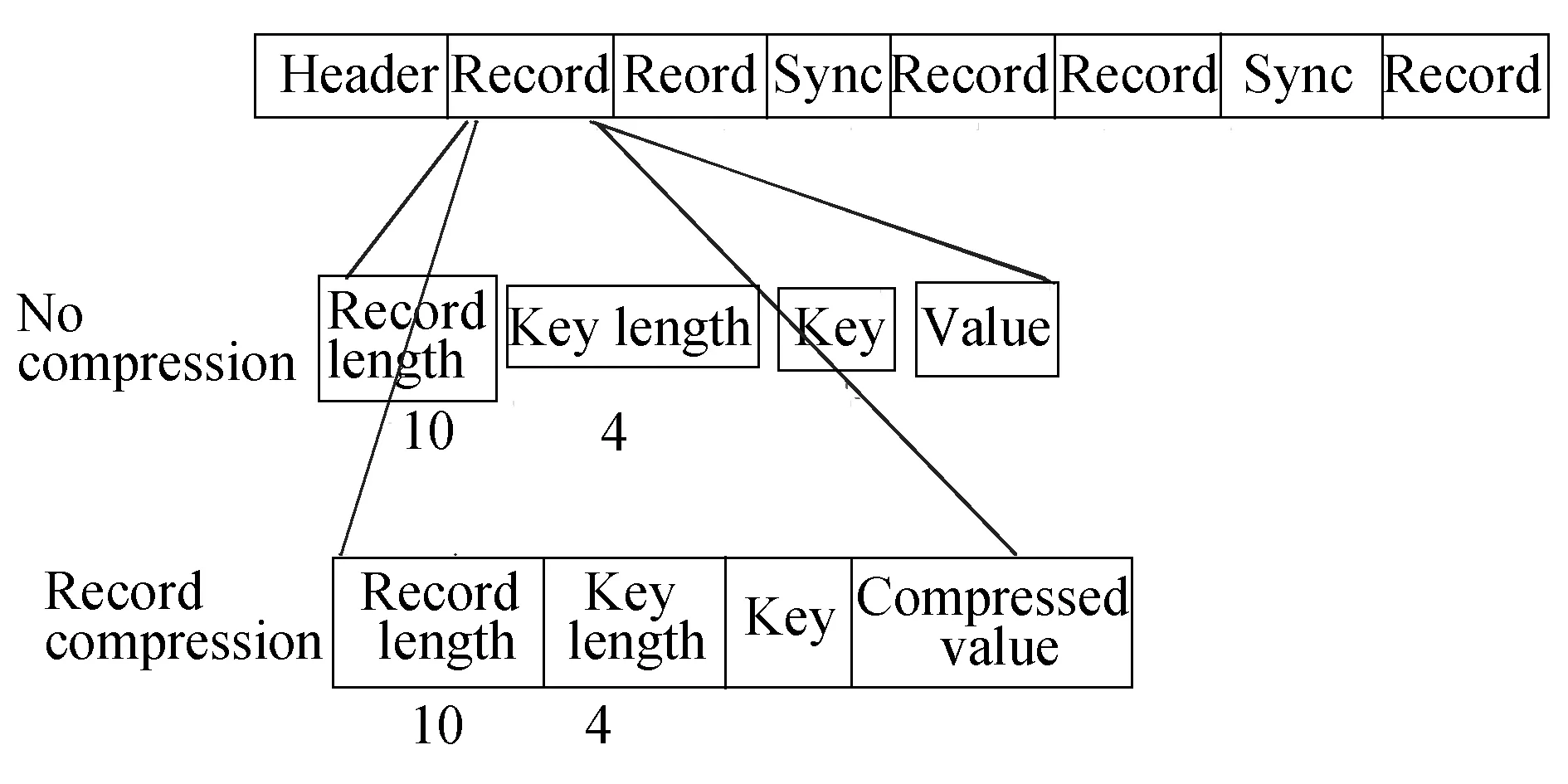
图5 SequenceFile文件格式结构
SequenceFile格式是按照K/V对存储,一行记录Record一个K/V对,其本质还是按行存储.例如一个Record是10个字节,K的长度是4(如“abcd”),那么在读取V的时候,可以跳过前面的4个字节即可取得V值,即Record Length=KLength+VLength.此外,还可以对V进行压缩,如图5所示.
TextFile与SequenceFile区别主要有:(1)SequenceFile相比TextFile,冗余了长度记录(如同样的文件用TextFile格式存储是100 MB,用SequenceFile格式存储很可能变成120 MB);(2)SquenceFile可以进行压缩(不对K做任何操作,只对V进行压缩),而且是可以分割(并行计算)的.
3.3.2 列式存储
对于5行3列的逻辑表,如图6所示.当只提取字段c时,行式存储需要读取的15个字段值,而列式存储只需要读取5个字段值,其读取数据量是行式存储的1/3.
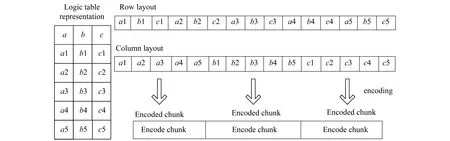
图6 列式存储与行式存储对比
3.3.2.1 Row Columnar File(rcfile)
鉴于行式存储的缺点,FaceBook提出了一种rcfile列式存储格式.rcfile优点主要有:(1)保证row group为单位的块中所有列存储在一起,避免查询时跨块进行查询;(2)每个row group是按列存储的,减少HDFS读取数据量(例如,一张表有100个列,查询只需要3列,那么rcfile存储格式查询时可以跳过其中的97列,降低查询的延时);(3)按列存储,每列的数据类型相同,采用特定的压缩方式进行压缩.在Facebook内部,rcfile只实现了部分功能,存储空间仅仅能减少10%,查询性能并没有得到显著的提高.
3.3.2.2 Optimized Row Columar File(ORCFile)
ORCFile是Hive、Shark、Spark支持的存储格式,使用这种存储格式存储列数较多的表.使用ORCFile存储格式,一个表由多个条带(stripe)组成orcfile,一个stripe 256 MB.stripe主要分为:(1)按照列存储数据;(2)index data索引数据,每列数据的存储范围(数值类型则存max、min等信息,string类型则存字符串的前缀、后缀等信息),默认10 000行建立一个索引index.例如“select *** from xxx where age > 50”查询语句,先到stripe的index data中寻找索引进行判断.假设这张表有3个stripe([10,30],[31,50],[51,99]),那么直接跳过前两个stripe到第3个stripe读取数据,提高了查询效率.
ORCFile的优点主要有:(1)每一列的数据类型分布采用相应的压缩算法(数值类型采用Run-Length Encoding,String类型采用Dictionary Encoding),压缩性能能得到很大提高;(2)数值类型或字符串类型建立相应的索引,使查询效率提高.
3.3.2.3 Parquet
Parquet等开源框架比较复杂,其灵感主要来自于Google公开的Dremel论文,其优势是能3 s分析1 PB数据.Parquet存储结构的主要亮点是支持嵌套数据结构以及高效且种类丰富的算法,以应对不同值分布特征的压缩,支持的压缩格式有uncompressed不压缩、gzip、snappy等.
3.4实验分析

图7 实验建表语句
实验通过对原始数据为18.1 MB大小(textfile存储格式)的网站访问日志进行测试,导入到Hive表中,其中建表语句如图7所示.
实验的Hadoop(hadoop-2.5.0-cdh5.3.3)和Hive (hive-0.13.1-cdh5.3.3)集群是由3台与单机配置相同的机器组成(测试环境机器配置如3.2节所述),通过命令“hadoop fs-du -h /user/hive/warehouse/page_ views_xxx”查看某个HDFS文件的大小.
3.4.1 ORCFile存储格式与行式存储对比
ORCFile相关联的Hive表属性配置如表1所示,与行式存储对比结果如表2所示.

表1 ORCFile相关联的Hive表属性配置说明

表2 ORCFile存储格式与行式存储对比结果表
通过分析实验结果,可以发现HDFS Read的字节数是19015214 B(18.1 MB),和原始的文件大小相同.当采用SequenceFile格式后,相比原始的TextFile存储格式存储空间,大小明显增大,采用列式存储ORCFile格式后HDFS的写入字节数明显减少,大大减少了磁盘写入的数据量.
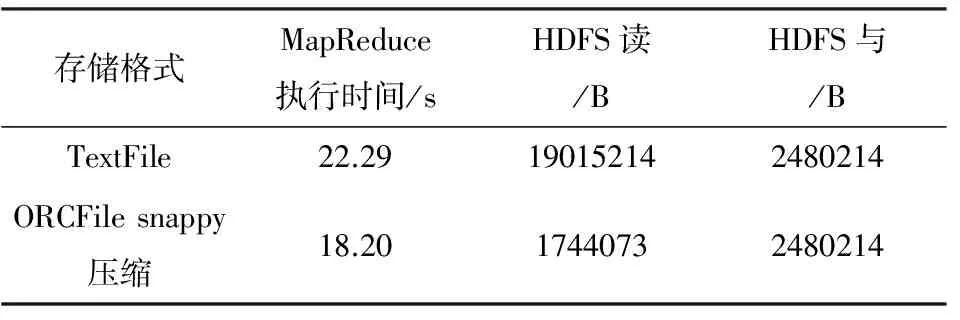
表3 单列查询结果对比
3.4.2 单列条件查询对比
查询语句采用行式存储和列出存储对比实验,结果如表3所示.
通过分析实验结果,可以得到行式存储TextFile读取了19015214 B,和原始文件大小相同,也就是全表读取.而列式存储ORCFile读取的数据量明显减少,只读取session_id这一列,过滤了其他不必要的列,整个查询语句对应的MapReduce执行时间明显缩短,提高了查询效率.

表4 Parquet不同压缩格式存储空间大小对比
3.4.3 Parquet不同压缩格式对比
通过分析实验结果(表4),可以得出对于原始数据18.1 MB大小的数据,通过snappy压缩之后大概可以压缩至6.4 MB,gzip压缩能压缩至3.9 MB.gzip压缩比高,解压速度比较慢,snappy解压速度比较快.
4 结束语
本文作者通过对MapReduce作业进行调优,主要围绕其核心的shuffle过程进行参数优化,总结了常用的重要参数.此外分析了分区表、外部表的基本特性,采用常用压缩、存储格式角度入手,分析各自优缺点.传统的数据仓库中大多数都是OLAP查询,使用snappy压缩、ORCfile/parquet列式存储格式可以大大提高查询性能,同时也可以兼容spark分布式计算框架.通过实验验证了压缩、列式存储格式在Hive列式查询场景的优势.
[1] 怀特.Hadoop权威指南 [M].北京:清华大学出版社,2010.
White T.Hadoop:the definitive guide [M].Beijing:Tsinghua University Press,2010.
[2] 叶文宸.基于hive的性能优化方法的研究与实践 [D].南京:南京大学,2011.
Ye W C.The research and practice of performance optimization based on Hive [D].Nanjing:Nanjing University,2011.
[3] Babu S.Towards automatic optimization of MapReduce programs [C].Proceedings of the 1st ACM symposium on Cloud computing,Indianapolis:ACM,2010.
[4] Jiang D,Ooi B C,Shi L,et al.Theperformance of MapReduce:an in-depth study [J].Proceedings of the Vldb Endowment,2010,3(1-2):472-483.
[5] 高莉莎,刘正涛,应毅.基于应用程序的MapReduce性能优化 [J].计算机技术与发展,2015,25(7):96-99.
Gao L S,Liu Z T,Ying Y.Performance optimization of MapReduce based on applications [J].Computer Technology and Development,2015,25(7):96-99.
[6] Yang H C,Dasdan A,Hsiao R L,et al.Map-reduce-merge:simplified relational data processing on large clusters [C].Proceedings of the 2007 ACM SIGMOD international conference on Management of data,Beijing:ACM,2007.
[7] 李建江,崔健,王聃,等.MapReduce并行编程模型研究综述 [J].电子学报,2011,39(11):2635-2642.
Li L J,Cui J,Wang D,et al.Survey of MapReduce parallel programming model [J].Acta Electronica Sinica,2011,39(11):2635-2642.
[8] Ghemawat S,Gobioff H,Leung S T.The Google file system [C].Acm Sigops Operating Systems Review,2003,37 (5):29-43.
[9] Shvachko K,Kuang H,Radia S,et al.TheHadoop distributed file system [C].Mass Storage Systems and Technologies (MSST) 2010 IEEE 26th Symposium on,Incline Village:IEEE,2010.
[10] Seo S,Jang I,Woo K,et al.HPMR:Prefetching and pre-shuffling in shared MapReduce computation environment [C].2013 IEEE International Conference on Cluster Computing,New Orleans:IEEE,2009.
[11] 张密密.MapReduce模型在Hadoop实现中的性能分析及改进优化 [D].成都:电子科技大学,2010.
Zhang M M.Performance analysis and improvement optimization of MapReduce model in Hadoop implementation [D].Chengdu:University of Electronic Science and Technology of China,2010.
(责任编辑:包震宇)
PerformanceoptimizationresearchbasedonHive
Wang Kang1,ChenHaiguang1*,LiDongjing2
(1.The College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai200234,China;2.College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing211106,China)
This paper research Hive performance optimization mainly from the two aspects of MapReduce scheduling and Hive performance tuning.MapReduce′s programming model and its implementation process is analyzed,and parameters are tuned from the map side and reduce side.Then Hive′s framework is researched from the aspects of the partition table,the external surface and common data file compression,the line storage and column type storage.The experimental results show that snappy compression and orcfile/parquet storage format can improve the efficiency of query for the column type queries, and has good compatibility.
data warehouse; job optimization; performance optimization; compression; storage format
2015-12-10
王 康(1988-),男,硕士研究生,主要从事数据挖掘方面的研究.E-mail:525262800@qq.com
导师简介: 陈海光(1971-),男,副教授,主要从事数据挖掘、信息安全方面的研究.E-mail:chhg@shnu.edu.cn
TP301
:A
:1000-5137(2017)04-0527-08
*
