一种基于语义的网络信息过滤三层模型设计
2017-09-18美子
美子, , ,
(1.上海师范大学 信息与机电工程学院,上海 200234;2.泰山护理职业学院 公共教学部计算机教研室,泰安 271000)
一种基于语义的网络信息过滤三层模型设计
李美子1,李欣2*,潘建国1,沈涤1
(1.上海师范大学 信息与机电工程学院,上海200234;2.泰山护理职业学院 公共教学部计算机教研室,泰安271000)
提出了一种面向网络信息的层次过滤模型及其体系架构,该模型分为本体过滤层、需求过滤层和兴趣过滤层.本体过滤层中,利用本体为基础对信息内容进行语义描述,实现信息的计算机理解与过滤;在需求过滤层,模型通过理解用户所提出的需求中所包含的语义,进而更加准确地通过过滤规则进行信息流过滤;在兴趣过滤层,用户兴趣通过特定方式表达,并通过语义相似度计算实现第三过滤层.
语义; 信息过滤; 层次模型; 本体
0 引 言
面对大数据时代的信息海洋,人们往往面临着“信息过载、信息迷航”等问题.信息过滤技术为用户提供了从动态海量信息中选择出满足用户需求的信息的能力[1-3].这种个性化的服务方式使用户真正摆脱了信息海洋的困境,从根本上解决了主动式信息服务的问题.
本文作者提出并设计了一个引入了三过滤层(Semantic based Three-layer Web Information Filtering Model,SFM)方法的网络信息过滤系统.SFM系统主要面向来自网络的各类信息,经过需求过滤、兴趣过滤和语义近似计算过滤3个阶段实现比传统的信息过滤技术更好的过滤效果.
1 SFM模型设计
SFM的核心思想是:将信息过滤的流程分为3个层次,即本体过滤层、需求过滤层和兴趣过滤层;其过程包括:在本体过滤层,将各类网络信息通过形式化语义描述,并精确地得到本体标注的第一层过滤;在需求过滤层,模型通过理解用户所提出的需求中所包含的语义,进而更加准确地通过过滤规则进行信息流过滤;在兴趣过滤层,用户兴趣通过特定方式表达,并通过语义相似度计算实现第三层过滤.
1.1SFM的系统的总体设计
SFM模型主要框架分为:用户模板空间、领域本体、信息流空间、信息过滤核心模块和人机交互模块等5个部分,其组成示意图如图1所示.
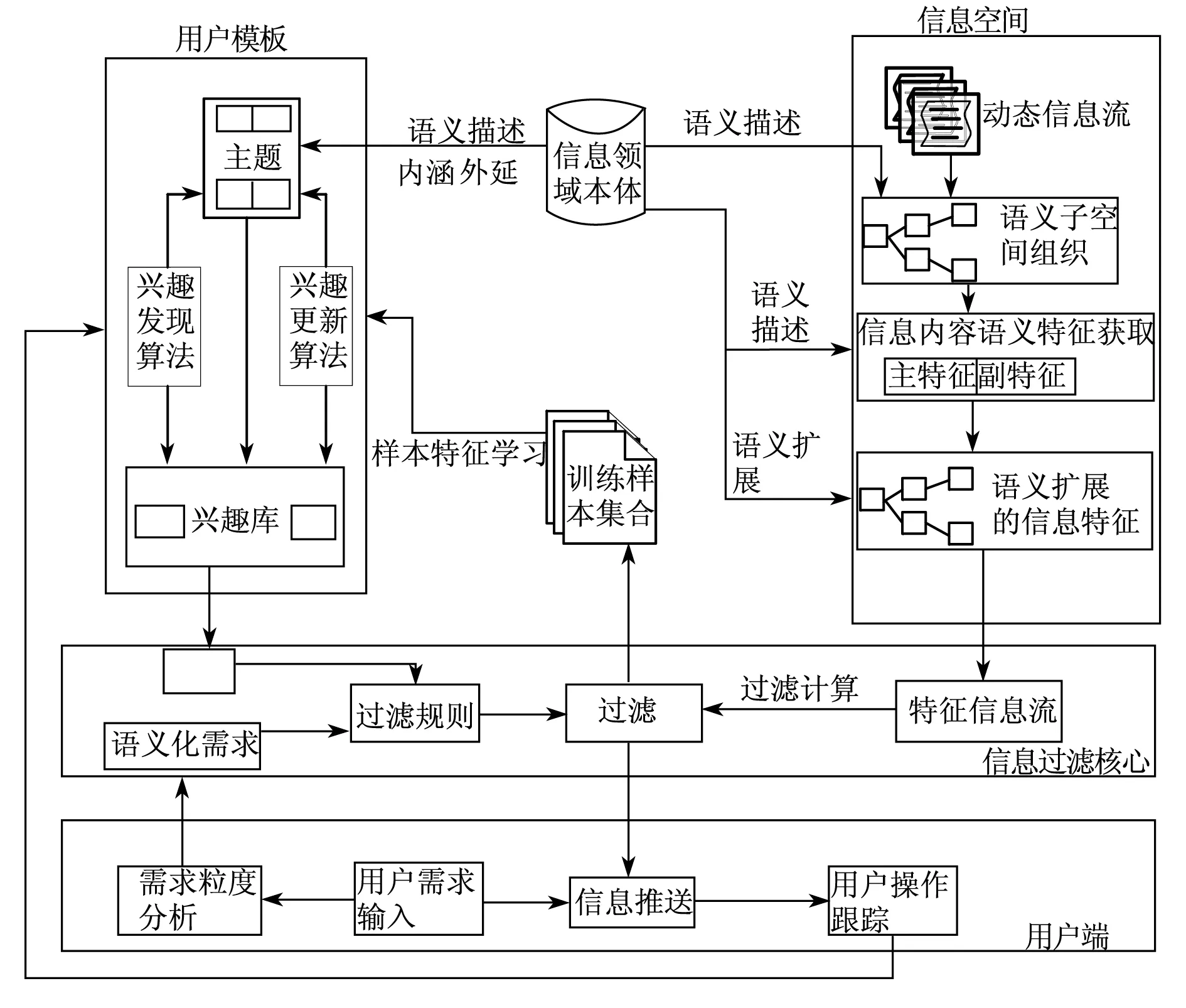
图1 SFM模型总体架构
用户模板(Profile)空间:用户模板空间主要由用户需求、用户属性以及用户兴趣库组成.用户模板空间从用户的操作行为、用户的阅读习惯、用户历史过滤记录和新获得的训练样本中得到符合用户过滤的兴趣等,从而更新用户主题和用户兴趣库.
领域本体:领域本体是SFM中用来进行语义表示的关键,同时也是对获取的信息流进行计算机语义理解的核心.领域本体对特定领域中所包含的知识、术语等进行形式化、概念化的描述;同时,本体作为计算机实现语义理解的基础手段,使信息中的知识在最大程度上得到语义描述,形成内涵、外延等具体语义形式,从而使机器能够自动理解信息中所表达的内容.
信息空间:信息空间即网络信息流在SFM中未被过滤前所存在的储存空间.信息流空间依据领域本体定义的不同类别,将信息流中不同信息划分为若干个由信息领域本体描述的语义;进而在信息内容特征语义获取模块中组织成为具有特征的语义向量,利用主特征和副特征来描述信息,最后进行信息语义扩展.
信息过滤核心:信息过滤核心是利用现有的用户兴趣库,结合用户需求,对信息流空间中处理完毕的动态信息流进行信息过滤的过程,其工作原理为本文作者给出的三层信息过滤方法.
人机交互模块:人机交互模块是为用户提供了可供用户输入具体信息需求的界面.针对用户输入的需求,系统将需求进行语义化处理,通过粒度分析获得需求语义,提供给信息过滤核心;同时,SFM的在信息过滤过程中的有两种交互方式:根据用户具体需求过滤以及根据用户浏览历史、训练样本过滤.
1.2SFM的三过滤层结构

图2 SFM三过滤层图
SFM采用了三过滤层的结构,将信息分类、信息过滤、冗余消除等结合在一起,如图2所示.
本体过滤层:本体过滤层核心任务在于将网络中杂乱无章的信息流按照一定的领域进行分类.本体过滤层的意义在于,去除了那些不符合SFM拥有理解能力的信息,使保留下来的信息具备了领域语义.
需求过滤层:需求过滤层主要通过用户需求粒度分析、用户需求语义获取以及信息需求过滤等方面的工作,将本体过滤层中已经被初步处理的信息进行分离,获得能够符合用户需求的信息.
兴趣过滤层:兴趣是对用户以往进行的阅读偏好、习惯等各种用户个性化信息的简称.SFM通过用户模板空间和人机交互模块,为用户提供了个性化的输入窗口.SFM利用用户兴趣语义,将符合用户兴趣要求的信息尽量往前排列,同时将用户历史上不关心的信息进行后置或者删除处理,从而得到最可能符合用户要求的信息.
2 SFM的三层信息过滤
2.1本体层信息过滤方法
2.1.1 信息领域本体相关概念与语义相似度计算
首先,定义SFM中的信息领域本体如下:
定义1信息领域本体IO是一个七元组:
IO=(C,SR,IR,P,SF,V,I),
(1)
其中C表示领域本体的概念名;SR表示概念在该领域中的上下位结构性关系,也就是父子关系;IR表示概念与概念之间存在的非结构性关系;P表示描述概念所使用的属性;SF是一个二元组SF=(O,x),用以表示该概念与其他本体O之间存在的语义关联度x;V为该概念的同义词典;I表示属于概念的实例.
每一条信息如果看作是对一个事件或一个状态的描述,那么描述的格式就应该有结构化、非结构化、半结构化等各种方式.本体就是一种提供结构化知识的最好工具,因此对于信息过滤而言,所处理的最佳对象就是结构化信息.在处理以前,就需要将非结构化或者半结构化的信息转化为结构化的信息.这个过程可以看作是对信息内容的特征提取.
定义2对于一个给定的阈值,如果在信息中出现的概念相对于该文档的重要度大于该阈值,那么这个概念可以看作是信息的主特征,记做MC;否则,该概念记为信息副特征,记为NC;信息的特征向量C为由主特征和副特征组成的向量集合,表示为C=(MC,NC).
信息内容的特征向量可以表示为如下特征:
F(c)={((mc1,mr1),(mc2,mr2),…,(mci,mri)),((nc1,nr1),(nc2,nr2),…,(ncj,nrj))},
(2)
其中F(c)是信息的特征向量集合;mci是第i个主特征项,mri是该主特征项的权重;ncj是第j的副特征项,nrj是该副特征项的权重.关于权重计算的方法,作者在[8]中详细阐明.
当信息特征已经确定之后,那么特征之间的相似度就可以看做是两个特征在本体中的语义相似度的计算.下面给出两个概念的语义相似度计算方法.
定义3本体层次树中两个概念的语义距离为同一本体中不同类间关系链中最短关系链长度的一种度量方法,与相似度的对应关系需要满足以下条件:
1) 两个概念语义距离为0时,其相似度为1;
2) 两个概念语义距离为无穷大时,其相似度为0;
3) 两个概念语义距离越大,其相似度越小.

定义5在本体层次树中,概念在层次树中越深,语义距离越小.概念的分类越细致,语义距离越小.概念C在树中的深度D(c)为该节点到树根的最短路径,将从概念C引出的边的权值记为概念C的权值w(c),C的父节点记为p(c),wid(c) 为概念C的宽度,即其孩子节点的数目.定义概念的权重计算公式为:
(3)
定义6语义距离与相似度相互转换公式为:

(4)
其中t为一个可调节的参数.
2.1.2 基于语义相似度的本体过滤层
本体层信息过滤实现在信息语义分类的基础上,抽取出SFM能够理解其语义的信息,将这些信息作为本体概念的实例.本体过滤层的主要流程为:
1) 对于信息的一个特征t,搜索其在信息领域本体库中的本体Oi(0 3) 搜索信息领域本体库中所有本体,直到所有概念都获取完毕; 4) 对该信息的所有主特征进行上述步骤的计算; 5) 将没有成为本体库中概念的实例的信息直接存入一级缓存库中. 2.2用户需求层信息过滤 用户的需求是由用户主动输入得到,有若干个特征词组成的表达式.用户需求由若干特征词组成,这些需求定义如下: 定义7用户需求是指用户所关心的概念,用户需求特征词可以表示为一个序对Ti|wi,其中Ti表示特征词的概念,wi表示该需求特征词的用户关心度[8]. 用户需求进行本体解释的原理如下:输入后,首先为用户建立一个需求特征,即对用户输入的特征词进行本体标注,从而使计算机能够利用自有的信息领域本体对用户输入的主题进行一定程度的理解.用户需求特征词即为本体中的概念名. 经过本体过滤层获得信息流中的被识别的信息,SFM通过需求特征和信息特征之间的相似度计算进行过滤.需求过滤层的工作流程如下: 3) 将该需求特征与信息中所有主特征和副特征进行相似计算,记需求特征x的所有可记录相似度为f(x)=a∑l(x)+b∑l(x)(公式中a,b为调节参数,分别代表与x所计算的信息特征为主特征和副特征的参数,并且a+b=1); 4) 将所有需求特征与信息中所有特征进行计算; 5) 需求与信息的语义相似度为∑f(x); 6) 若∑f(x)≥θ(θ为预设过滤阈值),则将该信息存入缓存数据库,否则将该信息丢弃. 2.3基于用户兴趣语义的过滤 首先定义用户兴趣表示方法如下: 定义8用户兴趣是若干用户主题组成的对信息的复杂心态.用户兴趣形式化表示为: I=<(T1|w1,T2|w2,T3|w3,…,Ti|wi),F>, (5) 其中主题序对表示兴趣具体的主题组成,断言公式集合F是指主题的逻辑组合方式. SFM将根据用户历史上对信息过滤的经验进行过滤,找出尽量符合用户兴趣和习惯的信息. 假设一个用户兴趣为I=<(T1|w1,T2|w2,…,Ti|wi,…,Tn|wn),F>,其中Ti表示主题的概念,wi表示该主题的用户关心度,断言公式集合F是指主题之间的组合方.信息的特征为F(c)={((mc1,mr1),(mc2,mr2),…,(mci,mri)),((nc1,nr1),(nc2,nr2),…,(ncj,nrj))}其中F(c)是信息的特征向量集合;mci是第i个主特征项,mri是该主特征项的权重;ncj是第j的副特征项,nrj是该副特征项的权重.过滤算法流程如下: 1) 计算sim(Ti,mcj),进而计算λi=(sim(Ti,mcj)+wi+mrj)/3; 2) 计算sim(Ti,ncj),进而计算σi=(sim(Ti,ncj)+wi+nrj)/3; 3) 设断言公式为析取范式,其形式为(T1∪…∪Tm)∩Ti∩…∩Tn,则信息与用户需求的语义相似度为: (6) 其中η∈[0,1]为预设调节参数; 4) 根据用户设定进行信息推送. 本文作者设计了针对计算机领域内的论文自动过滤模型,该模型通过构建计算机领域本体进行知识表示,提供语义支持;利用了中科院计算所的分类词典进行中文分词,从而获取过滤需求的语义;采用三层过滤模型进行论文的过滤. 3.1基于本体的论文过滤实验 为了验证所提出的依赖于本体进行信息过滤的效果,采用来自互联网的中文论文数据源进行测试.测试的中文论文分为两组:第一组300篇,全部为计算机领域的学术论文;第二组300篇,其中150篇为计算机领域的论文,150篇为计算机领域与非计算机领域的交叉学科论文(包括30篇非计算机领域论文),并且这600篇论文不重复.分别记录了两组论文的过滤识别率和错误率,如图3所示. 图3 基于本体的信息过滤分析 从图3中看出,依赖于本体进行信息过滤基本能够实现不同领域论文的过滤.然而两组论文过滤平均识别率分别为55.2%和50.6%,错误率分别为10.7%和17.9%,可见仅依赖与本体进行过滤,其性能仍有待提升.分析原因在于:本体设计缺陷,即由于本体中所包含的专业术语数量有限,并不一定能够准确地识别出论文中出现的各类词汇.这种情况主要有两种:一是术语识别错误,二是术语缺失. 3.2信息过滤性能分析 为了验证该原型系统的信息过滤效果,设计了利用百度搜索引擎、Google学术论文搜索引擎、CNKI中文学术引擎以及所提出原型进行对比的实验.实验中,用户针对同样的计算机论文需求进行过滤.在百度搜索引擎和Google学术论文中,记录前100个记录中符合用户兴趣的主题数量;在CNKI中文学术引擎中,依据输入需求记录全部搜索记录中符合用户需求的论文数;在设计的原型中记录全部搜索中符合用户需求的论文数(最优数据预先人工设定). 图4 SFM信息过滤性能分析 实验进行了8组,每组进行20次需求过滤,并针对每组记录平均准确率.如图4中所示,由于本设计的原型采用了计算机领域本体的语义支持,因此其过滤效果优于其他方案.同时,本设计的原型系统由于存在一定的用户积累效果,准确率逐次提高,用户查看论文花费的时间相对较少. 本文作者提出了一种基于语义的信息三层过滤系统SFM,并且详细介绍了该系统的框架结构设计.SFM对信息的过滤主要可以分为本体过滤层、需求过滤层和兴趣过滤层.这三层过滤的主要功能分别对应于信息过滤需要的领域分类、用户要求和用户兴趣3个方面.本体层过滤主要负责将来自互联网的动态信息流依据信息领域本体库的标准进行领域划分,从而提高以后进行信息过滤的效率.需求层过滤主要针对用户所提出的具体信息要求,获取用户对信息要求的准确语义,然后针对这些需求语义进行信息的过滤.兴趣层过滤在前面两层过滤的基础上,针对具体用户之间的差别,分析不同用户可能出现的兴趣、习惯以及阅读倾向等,进而挑选出符合用户兴趣习惯的信息推送给用户. 未来工作的重点包括以下方面:(1)本体库的完善.计算机领域本体库只是信息领域本体库中的一个组成部分.而本设计的计算机领域本体库还比较粗糙,所包含的术语知识数量不够充分,属性描述比较简单,还需要进一步补充完善;(2)各类语义获取方法的准确度提高.通过中文切词获得语义是一种普遍采用的方法,但是中文切词也存在很多缺陷,例如对歧义的处理等等.因此以后工作需研究如何提高语义获取的准确性. [1] Huang X J,Xia Y J,Wu L D.A text filtering system based on vector space model [J].2003,14(3):435-442. [2] Sánchez S N,Triantaphyllou E,Kraft D.A feature mining based approach for the classification of text documents into disjoint classes [J].Information Processing & Management,2002,38(01):583-604. [3] Zeng C,Xing C X,Zhou L Z.A personalized search algorithm by using content-based filtering [J].Journey Software,2003,14(5):999-1004. [4] Song W J,Guo Q,Liu J G.Improved hybrid information filtering based on limited time window [J].Physica A:Statistical Mechanics and its Applications,2014,416:192-197. [5] Liu J H,Zhang Z K,Yang C,et al.Gravity effects on information filtering and network evolving [J].PloS one,2014,9(3):e91070. [6] Tian F J,Li C R,Wang D X.Evolving information filtering method [J].Journey Software,2000,11(3):328-333. [7] Liu Q,Li J H.Research on network content security administration system and its key technologies [J].Computer Engineering,2003,29(2):287-289. [8] Zhang B,Xiang Y,Wang J.Information filtering algorithm based on semantic understanding [J].Journal of Electronics & Information Technology,2010,32(10):2324-2330. [9] Yu X L.Information filtering model based on ontology [J].Computer Applications and Software,2014,31(2):119-122. [10] Ma L,Chen Q X,Cai L H.An improved model for adaptive text information filtering [J].Journal of Computer Research and Development,2015,42(1):79-84. (责任编辑:包震宇) Thedesignofsemanticbasedthree-layerwebinformationfilteringmodel Li Meizi1,LiXin2*,PanJianguo1,ShenDi1 (1.The College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai200234,China;2.Computer Teaching Section of Public Teaching Department,Taishan Vocational College of Nursing,Taian271000,China) Asemantic based three-layer web information filtering model and its architecture are presented,which comprises ontology filtering layer,requirement filtering layer,and interest filtering layer.In ontology filtering layer,contents of information are described formally based on ontology,and those information which cannot be understood by ontology can be recognized and filtered;in requirement filtering layer,web information would be filtered through calculating the semantic similarity degrees between user requirements and information features;in interest filtering layer,the user interests are described based on formal semantic,and further,the information can be filtered by comparing the similarity of user interest and information content. semantic; information filtering; layer model; ontology 2015-11-18 国家自然科学基金(61572326,61103069),上海教委教育规划一般项目(C160049) 李美子(1979-),女,讲师,主要从事智能信息处理,数据挖掘方面的研究.E-mail:Limeizi@shnu.edu.cn *通信作者: 李 欣(1978-),女,讲师,主要从事智能信息处理教育信息化方面的研究.E-mail:lifebest78@163.com TP391 :A :1000-5137(2017)04-0514-07

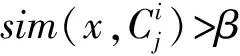

3 实验仿真

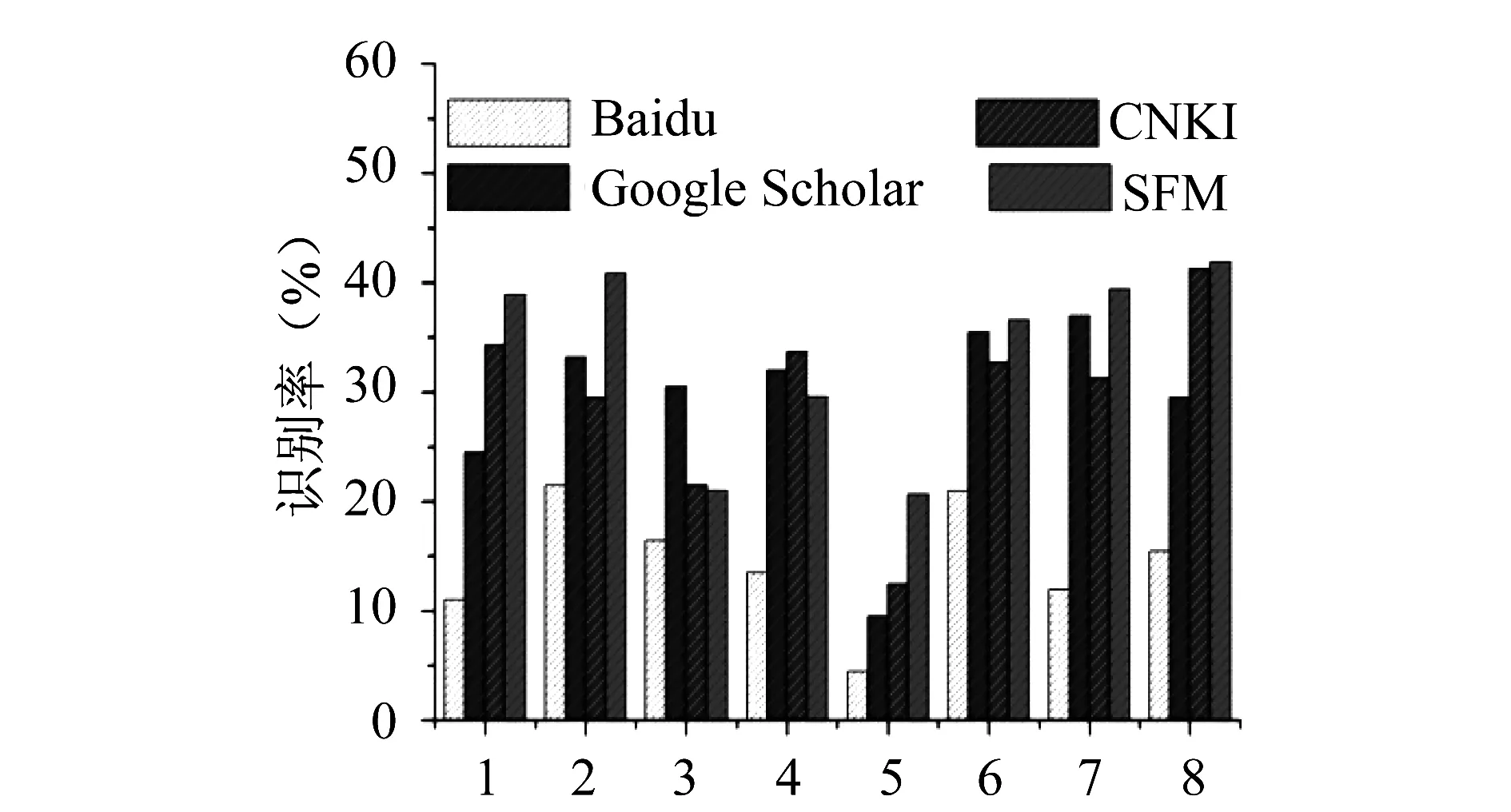
4 结论与展望
