基于大数据的数据挖掘引擎研究
2017-09-03王小燕张丽敏
王小燕,张丽敏
(1.陕西广播电视大学 陕西 西安 710119;2.西安外事学院 信息与网络学院,陕西 西安 710077)
基于大数据的数据挖掘引擎研究
王小燕1,张丽敏2
(1.陕西广播电视大学 陕西 西安 710119;2.西安外事学院 信息与网络学院,陕西 西安 710077)
为了解决数据挖掘在大数据中存在的问题,文中对大数据下的数据挖掘引擎进行了研究,以Spark作为核心引擎,并在Spark的内存计算算子的基础上,实现了多个传统数据挖掘算法的并行计算,使得传统的数据挖掘算法能在集群环境中并行运行,从而在大数据中得到较好的应用。然后通过系统分层方法,将数据挖掘系统进行分层设计,实现了一个完整的大数据挖掘平台。实验表明,基于Spark实现的Apriori算法跟PageRank算法的并行计算能有效减少执行时间,在大数据挖掘上具有较好的应用。
大数据;数据挖掘;Spark;引擎
由于计算机的普及以及网络的发展,互联网在人们的日常生活与工作中应用越来越广泛,每天均有大量的人在使用互联网,同时也产生了大量的数据。随着时间的推移,人们积累的数据量越来越多,规模高达TB级甚至PB级。为了取得这些数据中的有用信息,人们利用各种数据挖掘算法来挖掘其中的潜在价值。虽然数据挖掘在小数据集上的应用具有较好的效果,但对于大数据集而言,数据挖掘算法在执行效率,算法并行化及平台易用性等存在问题[1-5]。
为了解决上述问题,文中对大数据下的数据挖掘引擎进行了研究,以Spark作为核心引擎,并在Spark的内存计算算子的基础上,实现了多个传统数据挖掘算法的并行计算,使得传统的数据挖掘算法能在集群环境中并行运行,从而在大数据中得到较好的应用。然后通过系统分层方法,将数据挖掘系统进行分层设计,实现了一个完整的大数据挖掘平台。
1 基于Spark的并行数据挖掘算法
Spark是一种开源集群计算环境,与Mahout相比,其拥有更快的计算速度,更适用于大数据的数据挖掘中,因此将其选为数据挖掘的核心引擎。由于Spark所提供的数据挖掘算法覆盖量较少,例如缺少Apriori算法和PageRank算法。为了使Spark能成为核心引擎,本文在Spark的基础上实现了Apriori算法和PageRank算法的并行执行。
1.1 Spark编程模型
Spark[6-7]主要有两个特点,首先是弹性分布式数据集(RDD),其将集群中的节点内存全部组织起来,从而使所有节点内存能并行使用。RDD的建立一方面可通过加载HDFS文件来实现,也可由转换现有的RDD来得到。用户可将指定的RDD缓存在内存中,从而在再次使用时可免去创建过程,提升速度。
另一个特点是变量共享功能。Spark能在不同节点执行的任务中对共享向量进行拷贝,其能够在并行计算中使用。Spark的共享变量主要有广播变量及累加器变量,广播变量用于将一个值缓存到所有节点内存中,累加器变量执行累加功能。
1.2 Apriori算法
Apriori算法[8-9]是一种关联规则算法,其功能为挖掘大数据中事件的关联性,筛选出关联性大于预设阈值的事件,主要用于分析用户的消费行以及为商业政策的制定提供可行性分析等。设定事件A与B同时发生的概率为支持度,事件项集支持度大于预设值称为频繁项集,Apriori算法的工作步骤为:
1)扫描数据库,计算每个事件集的支持度,并将支持度小于预设值的事件集筛选掉,得到频繁项集L1。
2)将频繁项集的元素两两结合为一个事件项,形成新的事件项集。
3)将支持度小于预设值的事件集筛选掉,得到频繁项集Lk。
4)重复执行步骤 2)、3),直到不能形成新的事件项集。
1.3 PageRank算法
PageRank算法[10-11]是一种对网页搜索结果进行排序的算法,其工作原理为,以所有链接到某一网页的链接数作为该网页的支持度,对于一次搜索行为后,计算每一个搜索结果网页的支持度,并按照支持度从大到小的顺序对搜索结果进行排序。
2 系统设计
2.1 系统架构设计
本文的数据挖掘系统架构[12-15]如图1所示,从底往上分别分为引擎层、中间层以及用户层。引擎层为系统的最低层,其作为系统的数据处理引擎,以Spark集群为主体,并通过Zookeeper实现集群配置管理,以及使用Mesos对资源进行调度,封装常见的数据接入接口。中间层包括对(RPC)接口的远程调用以及多用户并发的控制请求。用户层主要包含开发套件和可视化控件等。
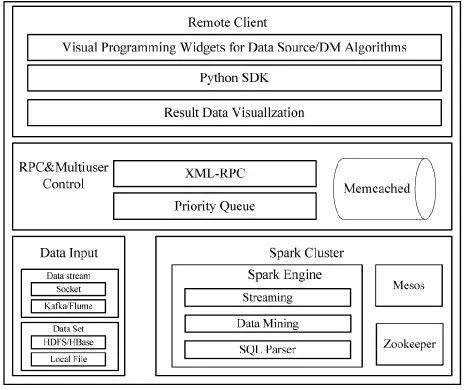
图1 系统整体架构图
2.2 引擎层
引擎层是整个数据挖掘系统的核心部分,其担负着系统的数据处理引擎。引擎层运行在Linux集群环境下,文中使用的是Ubuntu 16.04 64位系统。引擎层以spark集群为核心,通过Zookeeper实现集群配置管理,并使用Mesos对资源进行调度,封装常见的数据接入接口,包括Kafka,Flume等。此外,引擎层还具有3个组件,包括Spark SQL、数据挖掘算法包及Spark Streaming。Spark SQL用于处理结构化大数据;数据挖掘算法包用于提供数据挖掘算法,包括前文介绍的Apriori算法和PageRank算法;Spark Streaming用于处理流式数据。
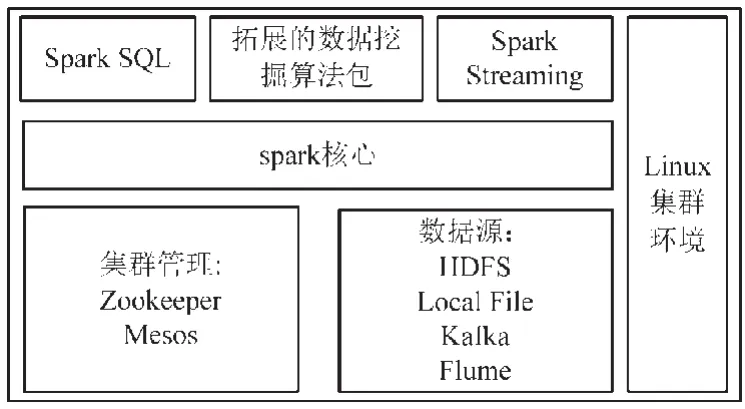
图2 引擎层设计图
2.3 中间层
中间层负责对(RPC)接口的远程调用以及多用户并发的控制请求。RPC(Remote Procedure CallProtocol),即远程过程调用协议,其是一种通过网络从远程计算机程序上请求服务,而无需要了解底层网络技术的协议。RPC能够使用户免去登录到集群环境中进行操作的环节而直接在本地进行调用,减去了提交大数据计算任务的环节。由于RPC由Python语言编写,因而选用Python的xml-rpc,其工作过程如图3所示。
首先是用户发起调用请求后,数据将被封装为xml的格式,然后通过HTTP的post方法,将xml格式的数据传播给rpc服务端,服务端解析xml数据,执行相关指令后,将结果以xml格式返回给调用端。
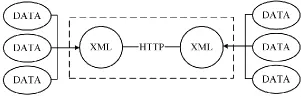
图3 xml-rpc处理过程
为了满足同一时间不同用户的需求,引入队列作为请求的存储结构,对任务进行优先级排序。用户请求调度过程如图4所示,中间层在接收到一个RPC调用时,先判断是否为getModel调用,若是将调用从Memcached取出执行,并将结果返回给用户层。若不是getModel调用,判断是否为Schedule调用,若为Schedule调用,则将调用标记为KEY锁定并放入到候选队列中等候执行;若不是Schedule调用,则不执行调用。
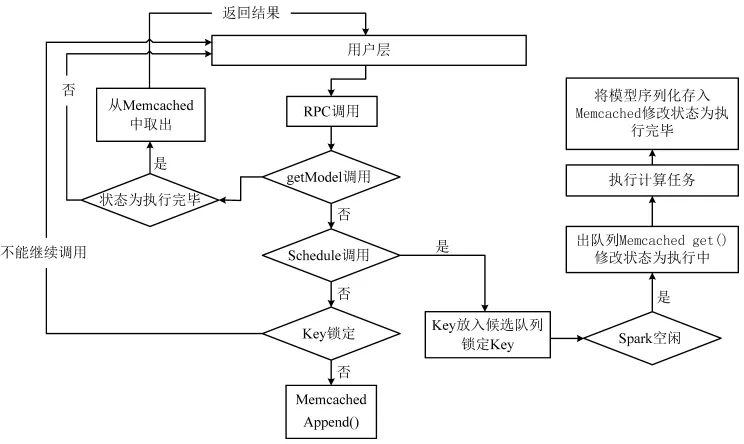
图4 中间层流程图
3 实验测试
文中在惠普Precision T5810工作站上搭建实验平台,处理器为Intel E5-1620处理器,主频3.5GHz,内存16G,硬盘1TB。在工作站上建立虚拟机,系统环境为Ubuntu 16.04 64位系统,完成Spark分布式环境的搭建。本文通过实验来比较以MapReduce及以Spark为基础的Apriori算法和PageRank的并行化执行效率,其中数据集采用大小分别为20MB,30MB,70MB,100MB 的 Note Dame,Stanford,Google以及Berkeley-Stanford数据集,对于频繁项分析,本文采用T10I4D100K.数据集,实验结果如图5~8所示。
由图5,图7可看出,不管是Apriori算法还是PageRank算法,本文提出的基于Spark的内存计算算子实现的数据挖掘算法的并行计算,其平均执行时间远小于MapReduce的平均执行时间。随着数据量的增加,基于MapReduce的数据挖据算法执行时间成线性增长,且斜率较大。而基于Spark的数据挖掘算法执行时间增长缓慢,并未发生较大变化。这是由于Spark基于内存进行计算的,其将每次迭代结果均缓存在内存中,因而能直接读取,减少了从硬盘读取数据的时间。
其次,随着Slave节点的增加,基于Spark的数据挖掘算法Apriori和PageRank算法的执行时间呈线性下降,说明这两种算法均能较好地进行算法的并行计算。
4 结束语
基于大数据的数据挖掘算法其在执行效率,算法并行化以及平台易用性等存在问题。为了解决这些问题,本文对大数据下的数据挖掘引擎进行了研究,以Spark作为核心引擎,并在Spark的内存计算算子的基础上,实现了多个传统数据挖掘算法的并行计算,使得传统的数据挖掘算法能在集群环境中并行运行,从而在大数据中得到较好的应用。然后通过系统分层方法,将数据挖掘系统进行分层设计,实现了一个完整的大数据挖掘平台。实验表明,基于Spark实现的Apriori算法跟PageRank算法的并行计算能有效减少执行时间,在大数据挖掘上具有较好的应用。
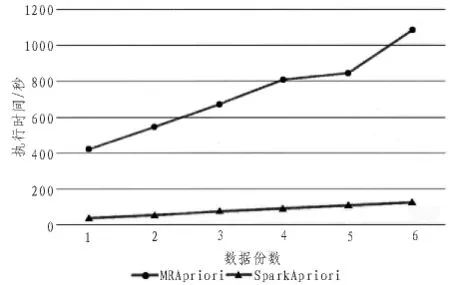
图5 并行化Apriori算法的数据规模实验结果
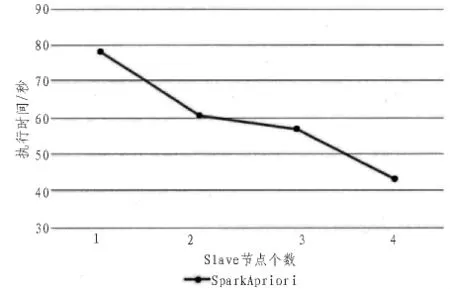
图6 并行化Apriori算法的集群规模实验结果
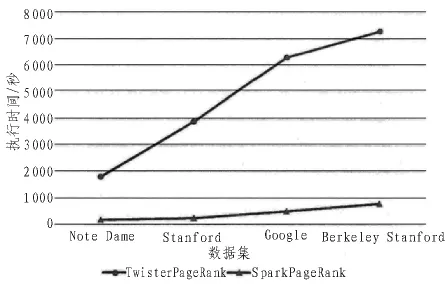
图7 并行化PageRank算法的数据规模实验结果
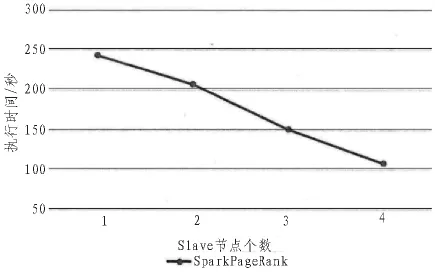
图8 并行化PageRank算法的集群规模实验结果
[1]Gheraawat S,Gobioff H,Leung ST.The Google file system [C].ACM SIGOPS Operating Systems Review.ACM, 2003,37(5):29-43.
[2]Dean J,Ghemawat S.MapReduce:simplified data processing on large chisters[J].Communications of the ACM,2008,51(1):107-113.
[3]Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems(TOCS),2008,26(2):4.
[4]Taylor R C.An overview of the Hadoop/Map Reduce/HBase framework and its current applications in bioinformatics[J].BMC bbinformatics,2010,ll(Suppl 12):S1.
[5]McKenna A, Hanna M, Banks E,et al.The Genome Analysis Toolkit:aMapReduce framework for analyzing next-generation DNA sequencing data[J].Genome research^2010,20(9):1297-1303.
[6]胡俊,胡贤德,程家兴.基于Spark的大数据混合计算模型[J].计算机系统应用,2015(4):214-218.HU Jun,HU Xiande,CHENG Jiaxing.Spark Big Data hybrid computing model[J].Computer Systems&Applications,2015(4):214-218.
[7]王虹旭,吴斌,刘旸.基于Spark的并行图数据分析系统[J].计算机科学与探索,2015,9(9):1066-1074.
[8]崔贯勋,李梁,王柯柯,等.关联规则挖掘中Apriori算法的研究与改进[J].计算机应用,2010,30(11):2952-2955.
[9]栗青霞,王换换,傅喆.改进的Apriori算法在试题关联分析中的应用[J].电子科技,2014,27(2):35-38.
[10]李稚楹,杨武,谢治军.PageRank算法研究综述[J].计算机科学,2011(s1):185-188.
[11]钱功伟,倪林,MIAO,等.基于网页链接和内容分析的改进PageRank算法[J].计算机工程与应用,2007,43(21):160-164.
[12]余永红,向晓军,高阳,等.面向服务的云数据挖掘引擎的研究[J].计算机科学与探索,2012,6(1):46-57.
[13]张英朝,邓苏,张维明,等.智能数据挖掘引擎的设计与实现[J].计算机科学,2002,29(10):11-13.
[14]姚全珠,张杰.基于数据挖掘的搜索引擎技术[J].计算机应用研究,2006,23(11):29-30.
[15]陈勇,张佳骥,吴立德,等.基于数据挖掘的面向话题搜索引擎研究[J].无线电通信技术,2011,37(5):38-40.
Research on data mining engine based on big data
WANG Xiao-yan1,ZHANG Li-min2
(1.Shaanxi Radio and TV University, Xi'an 710119,China; 2.Xi'an Institute of Foreign Affairs and Network Information Institute, Xi'an 710077, China)
In order to solve the problem of data mining in large data,the data of the large-scale data mining engine is studied, using Spark as the core engine, and in the memory of Spark operator on the basis of the implementation of a number of traditional data mining algorithms of parallel computing,the traditional data mining algorithm can run in parallel in a cluster environment,so as to obtain the very good application in big data.Then through the system layering method,the data mining system is designed,and a complete big data mining platform is realized.Experimental results show that the Apriori algorithm based on Spark algorithm and PageRank algorithm can effectively reduce the execution time,and it has a good application in large data mining.
big data; data mining; Spark;engine
TN99
:A
:1674-6236(2017)15-0031-04
2016-09-17稿件编号:201609153
陕西省教育厅科研项目(16JK2176);陕西工商职业学院2015年度教学改革研究项目(GJ1510)
王小燕(1982—),女,陕西西安人,硕士,工程师。研究方向:软件工程。
