基于双目立体视觉的三维拼接和融合方法
2017-08-08张晓林
陈 曦,张晓林
(中国科学院 上海微系统与信息技术研究所,上海200050)
基于双目立体视觉的三维拼接和融合方法
陈 曦,张晓林
(中国科学院 上海微系统与信息技术研究所,上海200050)
为了获得更为全面的三维信息,本文提出了基于双目立体视觉图像的三维拼接和融合的解决方法,并且完成了算法的实现。本方法仅使用双目图像作为输入,完成了高效的空间转换,并侧重于利用重投影融合和场景信息建模的方法对空间开销的控制,提高了处理的效率。同时,为了方便三维信息的观察和效果显示,对三维数据进行了可视化。经实验证明,本方法不仅能够用于拼接和融合三维数据,更能较好地用于显示三维数据。
三维数据;拼接;融合;立体视觉
目前,在计算机视觉领域,越来越多的高精度三维重建方法以及实时定位和地图构建(SLAM)[1]算法正在被提出用来对三维世界进行描述和分析。在计算机图形领域,快速和精细的三维建模与逼真的人机交互使得三维模型带给人超越真实的感受。自动驾驶[2]、机器人自主行走[3]、虚拟现实[4]和增强现实等应用场景中[5-6],三维数据被广泛地用来满足各种需求。三维数据的拼接与融合是对三维数据进行处理和建模抽象的重要步骤。通过三维数据的拼接与融合,局部三维数据得以整合,可以得到全面反应采集对象特征的全局模型。
三维数据的获取方式有很多,包括主动式的方式,如激光[7]、红外测量[8];也包括被动式的方式,如视觉系统测量。主动式的方式通常可以获得较为准确的深度信息。然而,由于缺乏被测量对象的纹理信息,在三维拼接和融合中难以借助纹理信息对深度信息进行更好的处理。被动式的方式中,尤其是针对于视觉系统的三维拼接与融合,可以有效的利用纹理信息对拼接和融合进行促进。在自动驾驶,机器人自主行走领域,使用视觉系统对地图信息进行重建,利用三维拼接和融合技术得到信息更为全面的地图,可以为后续的场景识别与定位,障碍物判断提供基础。
在能够重建三维信息的视觉系统中,双目立体视觉系统[9]了很广泛研究和应用。获取景物的三维信息的方法是使用两个视点观察同一景物,以获取在不同视角下的图像,通过计算两幅图像的对应像素的位置偏差(即视差)配合三角测量原理[10]。在获取三维信息后就可以利用本文的方法进行高效地、低空间开销地三维数据的拼接和融合。
1 三维数据的拼接
三维数据的拼接是将获取到的三维数据进行空间转换,统一到相同的空间内的过程。对于三维数据的获取,在文中采用了基于双目立体视觉的大规模有效立体匹配方法获得局部的三维信息[11]。在拼接时,结合双目视觉系统的特性,利用图像的特征,文中采用帧间的运动估计的策略[12]来计算相机的运动从而得到空间转换的关系,能够达到准实时处理速度。具体如下:
第一步,使用角点和区域特征双目图像进行特征提取,并用sobel算子作为前后左右帧的特征描述子,进行特征的匹配。
第二步,对匹配好的特征进行聚合,使其数目减少,并尽量均匀分布在整幅图像上。使用立体视觉的标定的相机内参,假设没有畸变,构建出如公式(1)所示的三维模型。
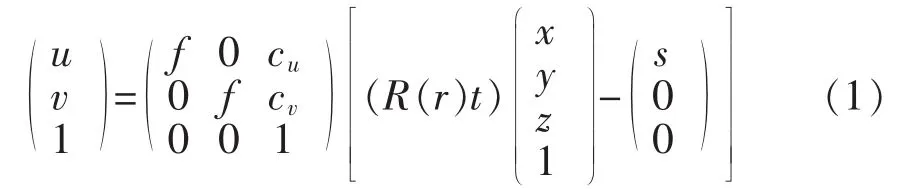
其中,(u v 1)T是当前图像的齐次坐标,f是焦距,(cu,cv)为主点的坐标,R(r)=Rx(rx)Ry(ry)Rz(rz)旋转矩阵,t=(txtytz)T为平移向量,前序三维点坐标X=(x y z)T,s为以左摄像机为基准的基线长度。
现设 π(l)(X;r,t):R3→R2是由(1)建立的映射,将一个三维点X映射为一个左图像平面上的一个像素x(l)i∈R2。 同理,令 π(r)(X;r,t)为到右图像上的一个映射。使用高斯-牛顿优化,针对于空间转换参数(r,t),迭代最小化公式(2)。
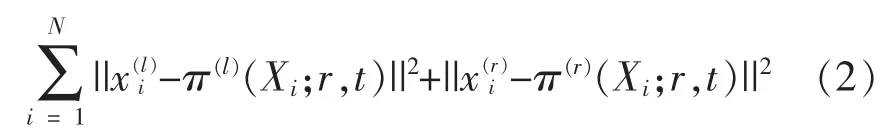
第三步,使用一个标准卡尔曼滤波器,并做了连续加速假设。我们首先获得了速度向量v=(r t)T/Δt,Δt为帧间时间。状态方程由下给出:
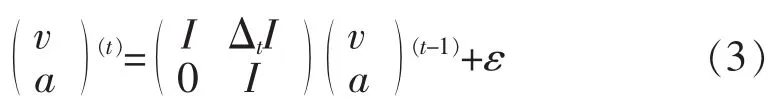
因为可以直接观测ν,输出方程化为:

这里,a代表加速度,I为一个6阶的单位阵。ε和ν各自代表高斯过程的测量误差。
通过迭代优化,通过方程1可以得到相机的运动的旋转平移矩阵(R(r)t)。 在齐次坐标下,此矩阵可以表示为

相机是三维数据的局部坐标,得到局部坐标转换关系后Hc,可以得到坐标中的三维数据的对应的转换关系Hp为:

通过三维数据的对应转换关系Hp,可以将三维数据统一到初始相机所在的坐标系中。
记初始帧为第0帧。用基于运动估计的方法计算出空间转换矩阵如表1所示。

表1 空间转换结果示例
2 三维数据的融合
在对三维数据进行了空间转换后,所有三维数据都处在世界坐标为初始相机坐标的坐标系下。三维数据需要进行融合以达到重叠部分数据冗余去除并且光滑平顺的目的。最常用的方法是光束平差法(Bundle adjust)[14]。光束平差法后续需要解决优化问题,因而在时间和空间上的开销过大。在本方法中,相机模型和各帧之间的空间转换都已求得,因此采用将前序三维信息投影至当前帧所在的图像平面进行融合的算法。这种算法更为快速,而且可以消除一定程度上的随机噪声,非常适合于对实时性有所要求的三维数据融合。
首先,利用相机模型和空间转换矩阵将前序三维数据投影至当前图像平面,即将三维数据降维成二维数据。在这里重写三维数据到图像平面的映射公式:
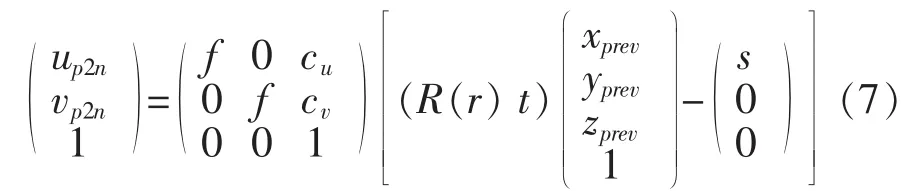
其中,(xprevyprevzprev1)T是之前帧中的三维点的齐次坐标,(up2n,vp2n)是重投影到当前帧的图像平面的坐标。
第二步,投影后在视差图D上找到对应视差D(up2n,vp2n),作为三维信息是否有效的标准,有效的三维点(xprev,yprev,zprev,1)T可以作为融合的备选点。
第三步, 对于有效的之前帧中的点(xprev,yprev,zprev,1)T,通过 D(up2n,vp2n)找到在对应的当前帧中的点(xprev,yprev,zprev,1)T,计算两点间的欧式距离:

第四步,在某种距离范围内的点,即deu<dthreshold可以进行融合,dthreshold是距离阈值。融合的策略是使用重叠点的平均值代替重叠点。如果距离较远就不进行融合而作为新的数据加入当前帧中,并从之前帧去除。
综合精度和效率进行融合之后,三维数据重叠部分的数据进行了精简。经过对10幅图像的实验可以看到,在相邻帧之间数据量平均减少了31.05%。记初始帧为第0帧,具体结果如表2所示。
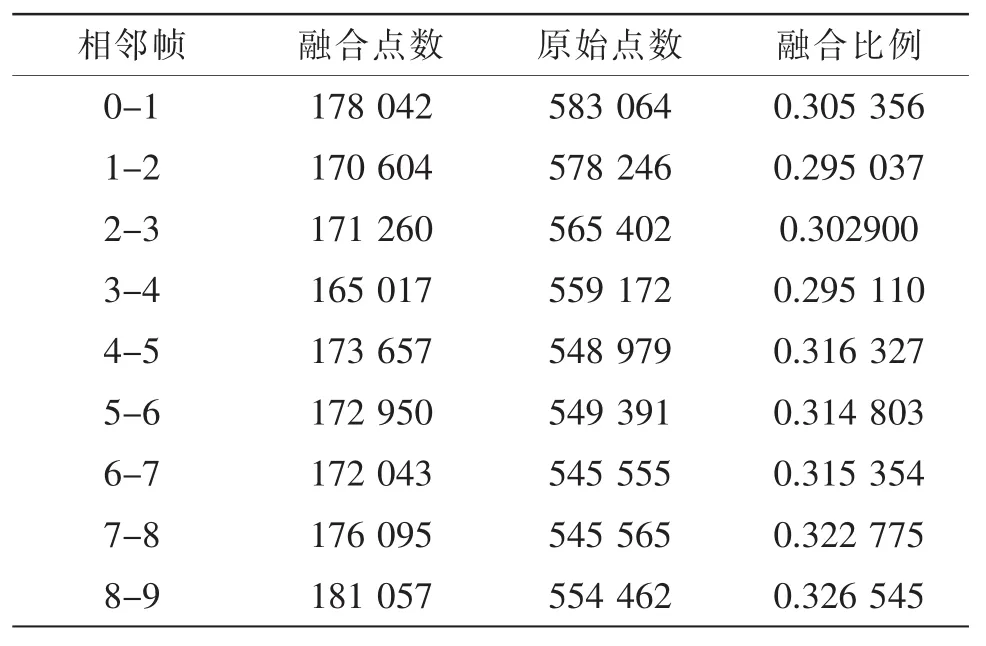
表2 三维数据融合结果
融合的结果使用点云来对三维数据进行可视化表达。其中融合前的三维数据如图1中(a)所示,暗灰色为第0帧,亮灰色为第1帧。融合后的三维数据如图1中(b)所示,可以看到点云变得更加光滑和平顺。将纹理加入点云中,效果如图3中(c)所示。经融合并加入纹理的点云,已经能够较好的重建和表现场景了。

图1 三维数据融合
3 道路场景建模
融合后的三维数据可以对其中的场景信息进行建模,用来减少冗余的三维数据和方便显示和存储。针对于室外道路场景,道路的特点包括:可以在一定程度上视为一个平面、道路边缘大部分是可以近似看作为平行的线段等。目前,主要的道路检测方法是从原始图像信息中利用道路的几何特点和纹理信息检测方法[15]以及在视差图中通过对视差图处理构建获得道路的信息。由于本文的主要目的是减少平坦道路的数据开销,所以主要侧重于对较为平坦且边缘近似为直线段的道路进行处理与拟合。
首先,使用边缘线段检测形成二维道路描述子。文中基于概率霍夫变换对道路边缘线段进行了检测,形成了一个多边形道路描述子。(xp,yp)为二维道路描述子中的点,{P|P⊆R2}为二维描述子点集,包括多边形内部点{mp|mp⊆P}和多边形边缘点{np|np⊆P},多边形顶点{k|k∈np}。二维道路描述子如图2中(a)图白色区域所示。
第二步,将二维的道路描述子使用三角测量法映射到三维空间中形成三维道路描述子 {Q|Q⊆R3}。此时三维道路描述子边缘由两部分组成:一部分是由二维道路描述子确定的边界{nq|nq⊆Q};另一部分是二维描述子内部点由于二维的道路描述子边界视觉测量值缺失转换而成边界点 {nqa|nqa⊆Q},如图2(b)所示。
第三步,确定三维道路描述子的顶点,用三角形网格进行拟合。提取顶点策略如下:
1)二维描述子中的顶点k映射到三维后仍然存在的点{kq|kq∈nq};

图2 道路描述子
2)在三维描述子边缘进行搜索,新的顶点{kqa|kqa∈nqa},将二维描述子的边缘映射np到三维中得到点集 nq,则新的顶点{kqa|kqa∈nqa∩nq};
3)去除 1)和 2)中的重复顶点得到{kf|kf∈kqa∪kq}。
第四步,对后续图像进行描述子顶点进行提取和处理。采用增量式方法,若后续顶点在之前顶点的范围之内就不进行绘制,若后续顶点在之前顶点范围外则进行绘制,效果如图3(a)(b)所示。加入拼接和融合的其他场景信息如图3(c)所示。

图3 路面网格拟合
4 结 论
文中基于双目视觉系统的特点,提出了基于双目图像的拼接和融合的方法,对场景进行了建模和重建。相比于传统的三维拼接与融合方法,本方法更多的使用了图像的特征,使得三维拼接与融合的过程更加可靠和稳定。特别的,本方法利用重投影融合以及路面场景建模对空间开销进行了极大的缩减,有利于后续对于特大场景的重建和存储,对于汽车自动驾驶和机器人自主行走的地图建立奠定了基础。
[1]Fuentes-Pacheco J,Ruiz-Ascencio J,Rendón-Mancha J M.Visual simultaneous localization and mapping:a survey [J].ArtificialIntelligence Review,2015,43(1):55-81.
[2]Fernandes L C,Souza J R,Shinzato P Y,et al.Intelligent robotic car for autonomous navigation:Platform and system architecture[C]//Critical EmbeddedSystems(CBSEC),2012SecondBrazilian Conference on.IEEE,2012:12-17.
[3]Häne C,Zach C,Lim J,et al.Stereo depth map fusion for robot navigation[C]//Intelligent Robots and Systems(IROS),2011 IEEE/RSJ International Conference on.IEEE,2011:1618-1625.
[4]Westwood J D.Real-time 3D avatars for telerehabilitation in virtual reality[J].Medicine Meets Virtual Reality 18:NextMed,2011(163):290.
[5]Van Krevelen D W F,Poelman R.A survey of augmented reality technologies,applications and limitations [J].International Journal of Virtual Reality,2010,9(2):1.
[6]Benko H,Jota R,Wilson A.MirageTable:freehand interaction on a projected augmented reality tabletop[C]//Proceedings of the SIGCHI conference on human factors in computing systems.ACM,2012:199-208.
[7]陈田.激光测量点云的数据处理方法研究 [J].激光与光电子学进展,2011,48(9):72-76.
[8]彭祎帆,陶毅阳,于超,等.基于红外结构光的三维显示用交互装置[J].光学学报,2013(4):108-114.
[9]罗桂娥.双目立体视觉深度感知与三维重建若干问题研究[D].长沙:中南大学,2012.
[10]靳盼盼.双目立体视觉测距技术研究[D].西安:长安大学,2014.
[11]Geiger A,Roser M,Urtasun R.Efficient Large-Scale Stereo Matching[C]//Asian Conference on Computer Vision.Springer-Verlag,2010:25-38.
[12]Fraundorfer F,Scaramuzza D.Visual odometry:Part i:The first 30 years and fundamentals[J].IEEE Robotics and Automation Magazine,2011,18(4):80-92.
[13]Fraundorfer F,Scaramuzza D.Visual odometry:Part II:Matching,robustness,optimization,and applications[J].Robotics&Automation Magazine,IEEE,2012,19(2):78-90.
[14]Salas-Moreno R,Newcombe R,Strasdat H,et al.
Slam++:Simultaneous localisation and mapping at the level of objects[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition,2013:1352-1359.
[15]Kong H,Audibert J Y,Ponce J.General road detection from a single image [J].Image Processing,IEEE Transactions on,2010,19(8):2211-2220.
3D registration and fusion based on binocular stereo system
CHEN Xi,ZHANG Xiao-lin
(Shanghai Institute of Microsystem and Information Technology,Shanghai 200050,China)
For getting more comprehensive 3D information,this paper presents a registration and fusion method based on binocular stereo vision and completes algorithm implementation This method uses only binocular image as input and completes efficient space transformation,focused on the use reprojection fusion and scene information modeling to control space cost as well as improving efficiency.Meanwhile,the method visualizes 3D data for the convenience of observation.The experiments show that this method can be used for 3D registration and fusion as well as display 3D data.
3D data; registration; fusion; stereo vision
TN919.82
:A
:1674-6236(2017)14-0119-04
2016-05-13稿件编号:201605132
中国科学院战略性先导科技专项(B类)(XDB02080005);上海张江国家自主创新示范区专项"张江科技成果转化集聚区"项目(Y55SYB1J01)
陈 曦(1990—),女,陕西宝鸡人,硕士研究生。研究方向:计算机视觉、信号处理。
