一种自动检测K近邻值算法
2017-07-19沈莉莉蒋林华邬春学
沈莉莉,刘 丛,蒋林华,邬春学
(上海理工大学 光电信息与计算机工程学院,上海 200093)
一种自动检测K近邻值算法
沈莉莉,刘 丛,蒋林华,邬春学
(上海理工大学 光电信息与计算机工程学院,上海 200093)
由于传统的KNN算法需要针对不同的数据集选择不同的k值的缺陷,提出了两种自适应近邻值的检测算法。该算法以传统的KNN算法为基础,使用多个K值对数据进行多次分类,而后对多次分类结果进行统计,根据统计值来决定样本点的类归属。方法一为统计多次分类中每个类别所包含的近邻数目,将近邻数目最多的类作为样本点的归属类;方法二为统计多次分类中的归属类数目,将数目最多的作为样本点的归属类,两种方法可以避免每次设置K值的弊端。从实验结果可以看出,提出的算法得到的数据更加稳定,更具有代表性。
KNN算法;分类;自适应
随着网络技术与数据存储技术的发展,每天都有大量的数据不断涌现,给数据存储和分析领域带来了挑战,设计强有力的数据分析工具是当今面临的主要问题。K近邻算法是一种比较简单的分类算法,其已在数据分析中得到了广泛应用。该算法的主要思想为对某一待分类样本X,在训练集中找出K个与其最相近的样本,分析这些样本的分类情况,对分类样本X分类。大量的研究者致力于KNN算法的研究,由于KNN需要多次寻找周围最近的K个邻居点,这会导致计算量巨大。所以如何降低算法的时间复杂度是研究热点之一。樊东辉提出了基于聚类的KNN算法,改进[1]IKNN算法,该算法首先使用DBSCAN聚类算法对样本进行聚类,再使用KNN算法找到n个最近邻样本对测试样本进行分类。张顺提出用于多标记学习的K近邻改进算法WML-KNN算法,对样本进行均匀抽样,降低算法的时间复杂度,根据邻近样本类别标记信息计算测试样本的最大后验概率,最后得到测试样本的类别标记。滕敏的K-最近邻分类算法应用研究[3],对近邻算法中K的取值对算法的影响,测试出不同的K值在分类算法中的误差率,实验得出当K值约为n/k时,具有较低的误差率,分类效果较好。KNN算法使用预先设定好的K值进行分类,但在传统的K最近邻算法中并不能已知哪个K值是最佳的分类结果,所以要对选取的K值进行判断,否则选取的K值可能与真实数据有较大的偏差。另一方面,K值的选择也是研究热点之一,杨柳提出一种自适应的大间隔近邻分类算法[4],在LMNN算法提出了自适应K值的ALMNN算法,该算法克服了K值全局固定的缺点,减少了K值对分类结果的影响。王增民提出基于熵权的K最临近算法改进[5],该算法克服了维度灾难问题,对样本进行属性约简。焦淑红提出KNNY算法采用KNN和SVM融合的方法,降低识别率低的问题[6]。王邦军提出了改进协方差特征的KNN分类算法[7],不使用欧氏距离。邓箴提出用模拟退火算法改进的KNN算法[8],加快KNN的分类速度。刘应东划分K最近邻图来改进KNN算法[9]。张著英提出一种高效的KNN算法[10],对属性约简。邓振云提出基于局部相关性的KNN分类算法[11],解决固定值选取问题。本文提出一种新的改进算法,无需直接确定K的值也达到了最佳分类的效果,解决了选取不同K值对实验结果不同的问题,达到了实验结果的自适应。
1 K最近邻算法
K近邻算法(K-Nearest Neighbor,KNN)[12],即寻找测试数据点周围最近的K个数据点,可以简单地认为是K个最近的邻居。当K=1时,就是寻找最近的邻居,如果K=N时,即为整个数据集。KNN算法是数据挖掘十大算法之一,是较为常用的分类器。
所谓K近邻算法是对于一个新的测试数据点,在给定的训练集中对测试数据进行分类,对于提前给定的K值,在训练数据集中根据距离的远近找到与测试数据最接近的K个数据点,在这K个数据中,分别查看这K个数据分别属于哪一个类,如果多数属于某一个类,那么将该测试数据就分到那个类中去,这个测试数据点就分类完成。
KNN算法中需要找到与测试数据最接近的K个实例,这里度量邻居的方式是采用欧氏距离。欧氏距离是常见的两点之间或多点之间的距离表示方法,是m维空间中两点之间的真实距离,又称为欧几里德度量。二维空间中点i与点j之间欧氏距离的计算公式为

其中,(xi,yi)为数据点i的坐标值,D值为数据点i与j之间的距离。
传统KNN算法流程:
输入 (1)数据测试点x;(2)训练数据集;(3)设置K。
输出x的分类结果。
步骤1 设定参数选择合适的K值;
步骤2 对于测试数据点x,在训练数据集中利用欧氏距离计算出与数据点x最近的K个数据点;
步骤3 查看并记录K个数据点所属的类别Ci,(i=1,2,3,…,C,C为训练数据集总共的类别数);
步骤4 对相同类的数据点进行相加,把数据点x分类到数目最多的那个类中。
传统的KNN算法也存在某些不足:(1)当训练数据集不平衡时,数据集中的某一个类所拥有的数据占整个数据集的一大部分,在搜索K个邻居时,得到的结果将偏重于拥有数据较多的类,所得结果受到影响,不一定正确;(2)K值需要人工设定,K值的大小对KNN算法结果有直接的影响,李航博士在文献[13]中阐述:K值过小容易发生过拟合,K值过大忽略了训练数据集中大量有用的信息。所以K值选择尤为重要,算法采用交叉验证法选择最优K值。
2 AKNN算法
针对传统KNN算法需要针对不同的数据集设置不同K值的局限性,本文提出了两种自动K值的检测方法,分别为AKNN1和AKNN2算法。
2.1 AKNN1算法
第一种改进的KNN算法是对每一个测试数据而言,在训练集中找到K个邻居,统计每一个K值下得到的所有邻居,将测试数据点归为类别数出现次数最多的那个类。
算法1 AKNN1算法框架。

输出x的分类结果。
算法流程:
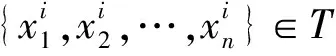
步骤2 设置l个计数器{cou1=0,cou2=0,…,coul=0},分别表示k个近邻样本所对应的类别计数;
步骤3 选择离x最近的k个训练样本{y1,y2,…,yk}⊂T进行分析,如果yi=Cj,则couj=couj+1;
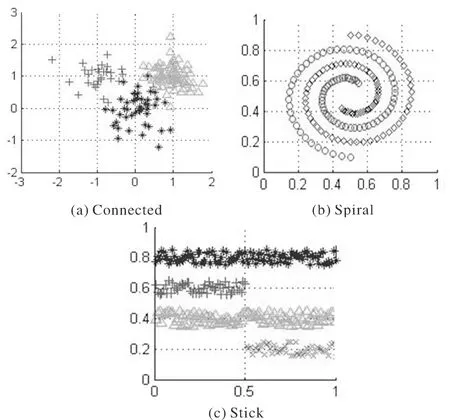
步骤4k=k+1,如果k 步骤5 得到最大的couj,将x放入类Cj中。 AKNN1算法需要使用不同K值做多次KNN运算,对于每次邻域中的类别数进行多次叠加计数。 2.2 AKNN2算法 第二种改进的KNN算法是对每一个测试数据点而言,先统计每一个K值下邻居出现次数最多的类,之后再统计出这些类中出现次数最多的类,那么测试数据点就归为此时统计出来的类中去。 两种改进算法的不同在于:第一种改进算法AKNN1是在2+3+4+…+K(K值为设定的Kmax值)个数据点进行统计,将测试数据点归为出现次数最多的类;第二种改进算法AKNN2是在每个K值下统计出现次数最多的类,最后在Kmax个出现次数最多的那几类中做统计,将测试数据点归为这Kmax个类中出现次数最多的类中。 为验证所提算法的有效性,实验使用了3组人工设置的不规则数据和5组UCI数据,这3组不规则数据的分布如图1所示。 这3组不规则数据中,Connected数据集共有150个样本,含3个互相连接的类,3个类中样本点的数目分别为47,30和73个。每个类都是符合超球型的分布。Spiral数据包含160个样本,表现为两个互相缠绕的螺旋,每个螺旋的样本数据为80个。Stick含有300个数据点,可分为4个类,每个类的样本为100,50,100和50个点。5个UCI数据集为IRIS、Glass,Soybean,Wine和Live数据。IRIS数据包含150个样本点,可分为3类,每类的样本数为50个。Glass数据包括214个分类样本,一共分为6类,每类样本数为70,76,17,13,9和29。Soybean数据一共有4类共47个点,每类分别为10,10,10和17个点。Wine数据集有3类178个数据,每类为59,71和47个数据点。 图1 3种人工测试集 实验中将改进的KNN算法与传统KNN算法中K值为1,3,5,7和9的正确率做比较,得到的实验结果如表1所示。 表1 各算法数据实验值 3.1 数据处理 在选择训练集和测试集上采用交叉验证[14]方法,训练集和测试集的比值为1∶2,随机选择2/3的数据集作为训练集,剩余数据作为测试数据集。 3.2 距离度量 实验采用两点之间的距离来寻找测试数据点的邻居,在K值下寻找到最近的K个邻居。实验用欧氏距离[15]来计算两点之间的距离,特征空间中两个实例的距离可以反应出两个实例之间的相似程度。 3.3 参数设置 对于传统的KNN算法并不能很好地判断K的具体大小,所以在传统的KNN算法中,对K的取值为1,3,5,7和9。 3.4 实验结果分析 如表1所示,对于传统的KNN算法来说,首先对于不同的K值,得到的分类结果不同。对于3个人工测试集,Connected和Stick数据集的实验数值波动不大,但对于Spiral数据,传统算法的正确率从1.00~0.98再到0.75有所下降,然而K为7时又上升到0.95,K为9时下降到0.38,从这些数值可知,实验结果波动幅度较大。而对于AKNN1改进算法,实验值在K=9时从0.96变化到0.78才有了波动,其它数据值在K为1,3,5和7时非常稳定。AKNN2算法的实验值总体来说相对稳定,变化幅度较小,只是在K为5变化到K为7时有小幅变动。 实验中的5组UCI真实数据集中,IRIS,Live和Wine数据集的结果比较稳定,而从对Soybean数据的分析看来,各算法的数据正确率都在1.00,随着K的增加KNN算法的正确率最先发生变化,随后AKNN1和AKNN2算法的正确率相继发生了变化。而Glass数据集整体数值变化虽然没有人工数据集Spiral变化的幅度大,但是对于AKNN1和AKNN2算法来说变化的幅度就大得多了,从实验数值来看,两种改进算法的实验值都较为稳定。 综合6组数据集的实验结果,传统KNN算法虽然有部分实验结果正确率较高,但总体的分类结果正确率波动较大,不能准确得到理想的分类结果。而对于论文中改进的KNN算法,无需已知K值,分类结果更稳定、更具有代表性,达到了预想的最佳分类效果。 本文提出了一种改进的KNN分类算法,该算法自适应进行KNN算法,解决了传统KNN算法使用固定K值而得不到一个稳定具有代表性的实验结果的缺点。从实验的结果来看,分类的正确率有所提高,分类结果更具代表性。但是,本文所提算法需要进行大量计算,开销较大,有待于进一步提高。 [1] 樊东辉,王治和.基于聚类的KNN算法改进[J].电脑知识与技术,2011,7(35):9033-9037. [2] 张顺,张化祥.用于多标记学习的K近邻改进算法[J].计算机应用研究,2011,28(12):4445-4450. [3] 杨柳,于剑,景丽萍.一种自适应的大间隔近邻分类算法[J].计算机研究与发展,2013,50(11):2269-2277. [4] 王增民,王开珏.基于熵权的K最临近算法改进[J].计算机工程与应用,2009,45(30):129-131. [5] 焦淑红,孙志帅.基于GPCA的KNNY与SVM融合的人脸识别方法[J].电子科技,2016,29(2):74-76. [6] 王邦军,李凡长.基于改进协方差特征的李-KNN分类算法[J].模式识别与人工智能,2012,27(2):174-178. [7] 邓箴,包宏.用模拟退火算法改进的KNN分类算法[J].计算机与应用化学,2010,27(3):303-307. [8] 刘应东,牛惠民.基于K-最近邻图的小样本KNN分类算法[J].计算机工程,2011,37(9):198-200. [9] 张著应,黄玉龙.一个高效的KNN分类算法[J].计算机科学,2008,35(3):170-173. [10] 邓振云,龚永红.基于局部相关性的KNN分类算法[J].广西师范大学学报,2016,34(1):52-58. [11] 张莹.基于自然最近邻的分类算法研究[D].重庆:重庆大学,2015. [12] 李航.统计学习方法[M].北京:清华大学出版社,2012. [13] 范永东.模型选择中的交叉验证方法综述[D].太原:山西大学,2013. [14] 罗四维,黄雅平.聚类分析中的相似性度量及应用研究[D].北京:北京交通大学,2012. An Adaptive Improved Algorithm forK-nearest Neighbors SHEN Lili,LIU Cong,JIANG Linhua,WU Chunxue (School of Optical-Electrical and Computer Engineering, University of Shanghai for Science & Technology, Shanghai 200093, China) Since the value ofkcannot be determined by the traditional k-nearest neighbor algorithm, a novel k-nearest neighbor improved algorithm is proposed. This algorithm is based on the traditional k-nearest neighbor algorithm, but the results are handled in different ways. We choose different values of k for each tasting data. Then, we count the numbers of the data belonging to each cluster. Finally, the test data belongs to the cluster that has the maximum of numbers. Compared with the traditional k-nearest neighbor algorithm, this improved algorithm avoids the disadvantage that how to choose the best value of k due to the great influence of different values of k on classification results. The innovation of our algorithm can be adaptive to the classification results. This algorithm does not consider the problem of the real value of k. According to the results of experiment, the improved algorithm is much more stable than the traditional algorithm with the result of classification closer to the real value. k-nearest neighbors; classification; adaptive 2016- 09- 20 沈莉莉(1992-),女,硕士研究生。研究方向:计算智能。刘丛(1983-),男,博士,讲师。研究方向:计算智能等。蒋林华(1977-),男,博士,教授,博士生导师。研究方向:电子光学图像处理等。邬春学(1964-),男,博士,教授。研究方向:嵌入式系统及应用等。 10.16180/j.cnki.issn1007-7820.2017.07.008 TP301.6 A 1007-7820(2017)07-029-043 实验结果与分析

4 结束语
