线性回归模型中非正态数据的处理
2017-07-18丘甜华伟平李宝银江希钿
丘甜,华伟平,李宝银,江希钿
(1.武夷学院商学院,福建武夷山354300;2.武夷学院生态与资源工程学院,福建武夷山354300;3.福建江夏学院,福建福州350108;4.福建农林大学林学院,福建福州350002)
线性回归模型中非正态数据的处理
丘甜1,华伟平2,李宝银3,江希钿4
(1.武夷学院商学院,福建武夷山354300;2.武夷学院生态与资源工程学院,福建武夷山354300;3.福建江夏学院,福建福州350108;4.福建农林大学林学院,福建福州350002)
为了对非正态数据进行线性回归分析,需要对非正态数据的处理方法进行研究。在Box-Cox变换的基础上改进的双幂变换是一种有效的处理方法。结合Matlab软件给出了双幂变换下线性回归模型中参数的极大似然估计与最小二乘估计方法,并通过实例研究显示:双幂变换使非正态数据服从正态分布,对于异常数据的处理有一定的效果,是数据正态变换的理想工具。
非正态数据;双幂变换;线性回归模型;极大似然估计;最小二乘估计
线性回归模型的因变量假定来源于正态分布的总体。在这一假定前提下,通常的做法是采用极大似然法或最小二乘法给出参数的估计。如果通过随机抽样的数据非正态分布,则会使显著性检验程序是无效的,实际上估计出来的参数没有意义,直接影响回归分析结果。这意味着,当数据不满足正态性假定时,可能拒绝实际上好的模型,大大地增加了统计推断中所犯第一类错误的概率。因此,非正态数据的处理是应用线性回归模型时需要解决的问题。
1 处理非正态数据的常用方法
1.1 Box-Cox变换
在考察可观测随机因变量Y和自变量X之间的关系时,经常采用如下正态线性回归模型[1-2]:

其中β∈Rp为回归系数,ε为不可观测随机误差向量。易知,模型(1)实际上需要满足Gauss-Markov条件:Y~Nn(Xβ,σ2In)。针对所获得的数据,对其进行回归诊断,若不满足Gauss-Markov条件,研究者在统计推断时有可能会增加犯错误的概率。常用的处理方式是对数据采取某种“治疗”措施,其中,数据变换就是一种常用的处理非正态数据的办法。至于采取何种变换更为有效,这取决于数据本身的特点,也成为了如今国内外统计学界研究的热点问题之一。迄今为止,如下由观测值Y到Y(λ)的Box-Cox变换[3](依赖于未知参数λ):
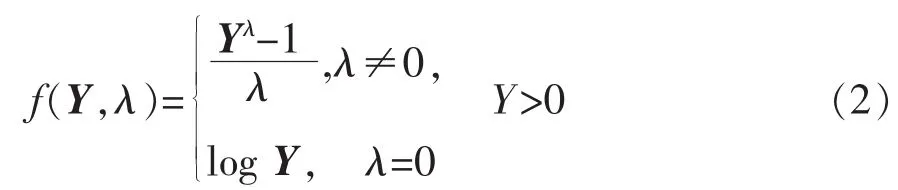
式(2)是研究得最为透彻的变换。通过参数的选择,达到对非正态数据的综合治理。虽然Box-Cox变换具有许多优点,但注意到

这表明Box-Cox变换存在截断问题,即当λ<0时,Y(λ)在-1/λ处右截断,而λ>0时,Y(λ)是在-1/λ处左截断的,只有在λ=0时,Y(λ)取值范围是(-∞,+∞),从而认为Y经过变换(2)得到的f(Y,λ)是一组正态样本是不正确的(除了λ=0这种情况)。
1.2 双幂变换
为了克服Box-Cox变换中的截断问题,诸多学者进行了研究。目前,Yang[4-5]引入了如下变换。

变换(3)是在Box-Cox变换的基础上进行修正而得到的一种新变换,被称为双幂变换。非正态数据通过双幂变换后服从以下正态线性回归模型:

式中:X是已知n×p列满秩设计阵;ε是不可观测的n维随机误差向量;λ∈(-∞,+∞),β,σ2是未知参数。
对于参数λ∈(-∞,+∞)均有g(Y,-λ)=g(Y,λ)成立,这意味着根据样本Y=(Y1,…,Yn)T不能唯一确定模型(4)中的参数λ。因此,为了消除这种不确定性,将参数λ限制在区间[0,+∞)内。
2 非正态数据处理下参数的估计
2.1 极大似然估计
由模型(4)可得未知参数λ,β,σ2基于Y=(Y1,…,Yn)T的对数似然函数为:

其中J(Y,λ)表示变量Y(λ)=(Y1(λ),…,Yn(λ))T和Y=(Y1,…,Yn)T之间的变换Jacob行列式,其表达式为:
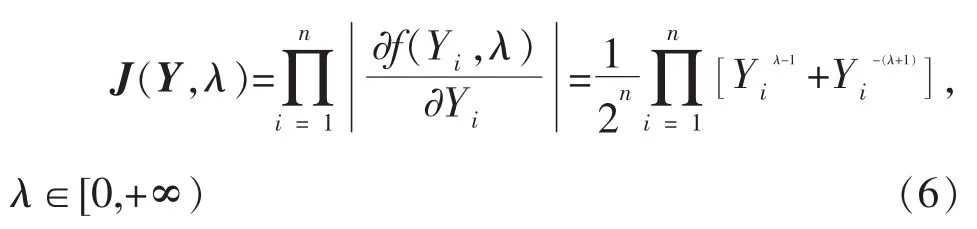
当λ≥0已知时,由(5)利用熟知的正态线性回归模型极大似然估计的结果可得知(β,σ2)的极大似然估计分别为:

其中PX=(XTX)-1XT为一正交投影阵。将(7)式代入(5)中可得:
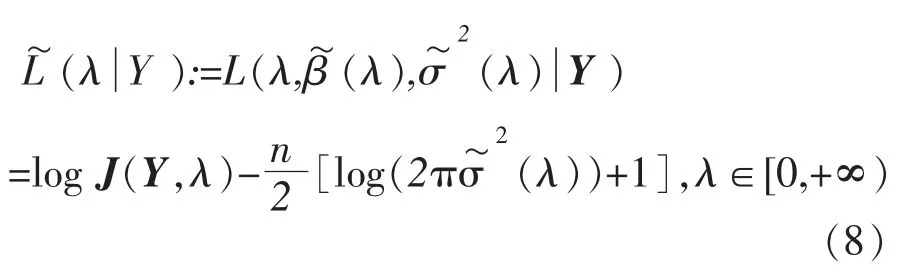
这说明了参数λ∈[0,+∞)的极大似然估计是以下极值问题的解∈[0,+∞),而参数β∈Rp,σ2>0的极大似然估计分别为用Matlab中内嵌的函数fminbnd可方便地算出[6-7]。
2.2 最小二乘估计
最小二乘估计作为另一种参数估计方法,也经常被人们所运用。作为比较,本文同时考虑模型(4)中参数λ,β,σ2的最小二乘估计法。此时,相应的误差平方和为:
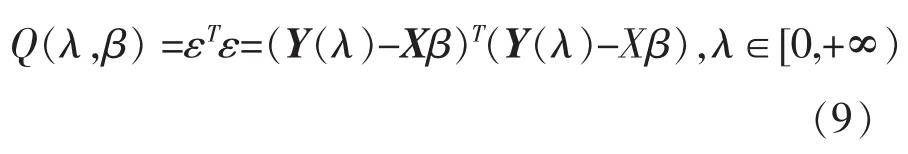
由此及熟知的线性回归模型最小二乘估计的结果可得已知λ≥0时,β的最小二乘估计为:
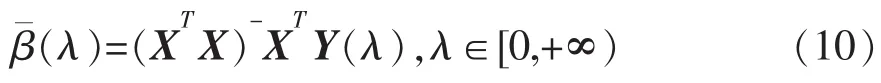
3 数值实验
在实际分析时,常常考虑多个变量,并且这些变量中有一个变量是特别关心的,称为因变量Y,其他变量作为影响因变量的自变量(考虑三个自变量X1、X2和X3)。为了分析自变量对因变量的影响,按照随机原则抽取了36个样本数据,如表1所示。
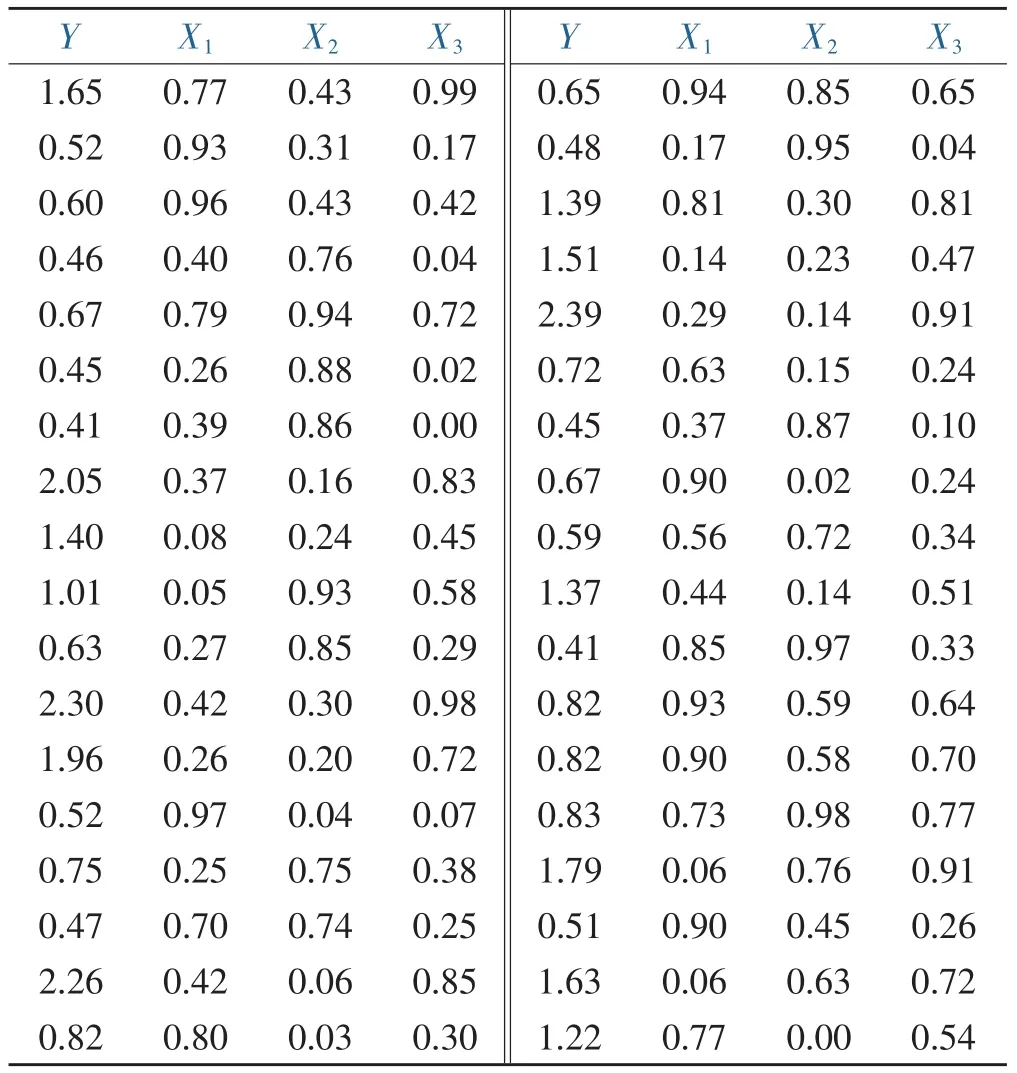
表1 样本数据Table 1 Sample data
3.1 非正态数据诊断
数据非正态性诊断[8-10]的常用方法是K-S检验。该检验的原假设认为总体符合正态分布。在显著性水平取0.05时,若检验的P值小于0.05,则否定原假设,认为总体呈现非正态分布。
通过对因变量Y进行基本统计分析,统计结果(表2)显示K-S检验的P值为0.031,小于0.05,说明数据总体不符合正态分布,并且偏态系数为0.912,表现出一定程度的右偏,这在图1有更直观的表现。通过统计软件SPSS操作,并输出结果。可以判断该因变量是非正态数据。因此,在进行回归分析前必须进行数据正态性处理。
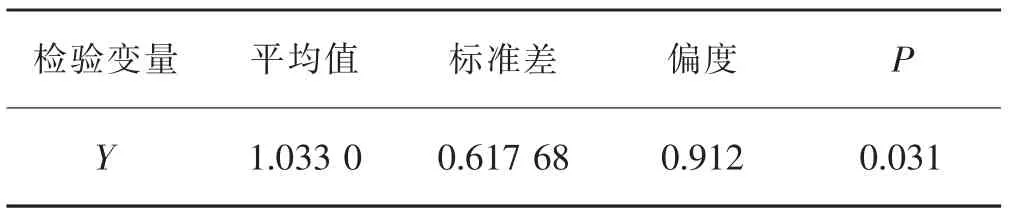
表2 因变量Y的基本统计量Table 2 Basic statistics of dependent variable Y
3.2 数据变换及正态性检验
采用双幂变换对因变量Y进行修正得到Y(λ),用极大似然法估计出变换参数λ^ML为1.128 6,用最小二乘法估计λ^LS为0.883 4。对变换的效果进行正态性检验。通过软件SPSS进行基本统计分析,得到变换后的偏度系数及K-S检验结果(表3),发现右偏程度有所减少,且变换值能顺利通过K-S检验。
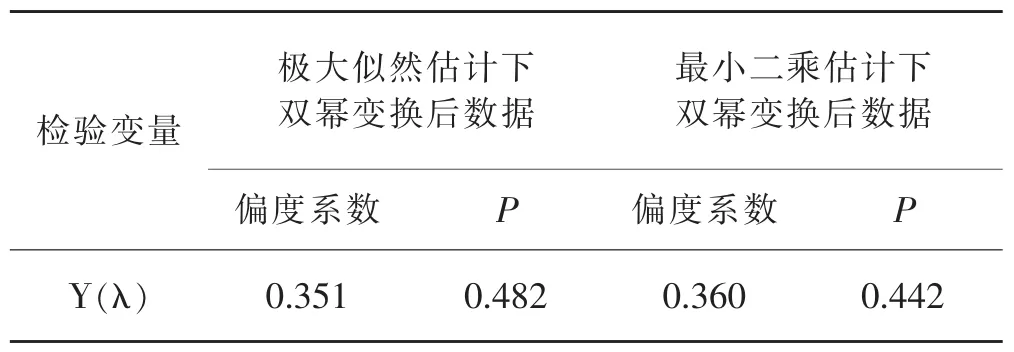
表3 原数据的双幂变换及正态分布检验结果Table 3 The results of the dual power transformation and normal distribution of the original data
为更直观的反映双幂变换下两种估计的正态效果,给出变换后的与的正态Q-Q图,同变换前进行比较,见图2。
3.3 双幂变换后线性回归分析
由于线性回归分析[11]的思路是一致的,目的在于考察变量之间的数量关系,并通过一定的数学表达式即回归方程将关系描述出来,进而确定自变量对因变量的影响程度。以通过极大似然估计下双幂变换后线性回归分析为例。以Y()为因变量,X1、X2和X3为自变量进行多元线性回归分析,具体结果见表4、表5。
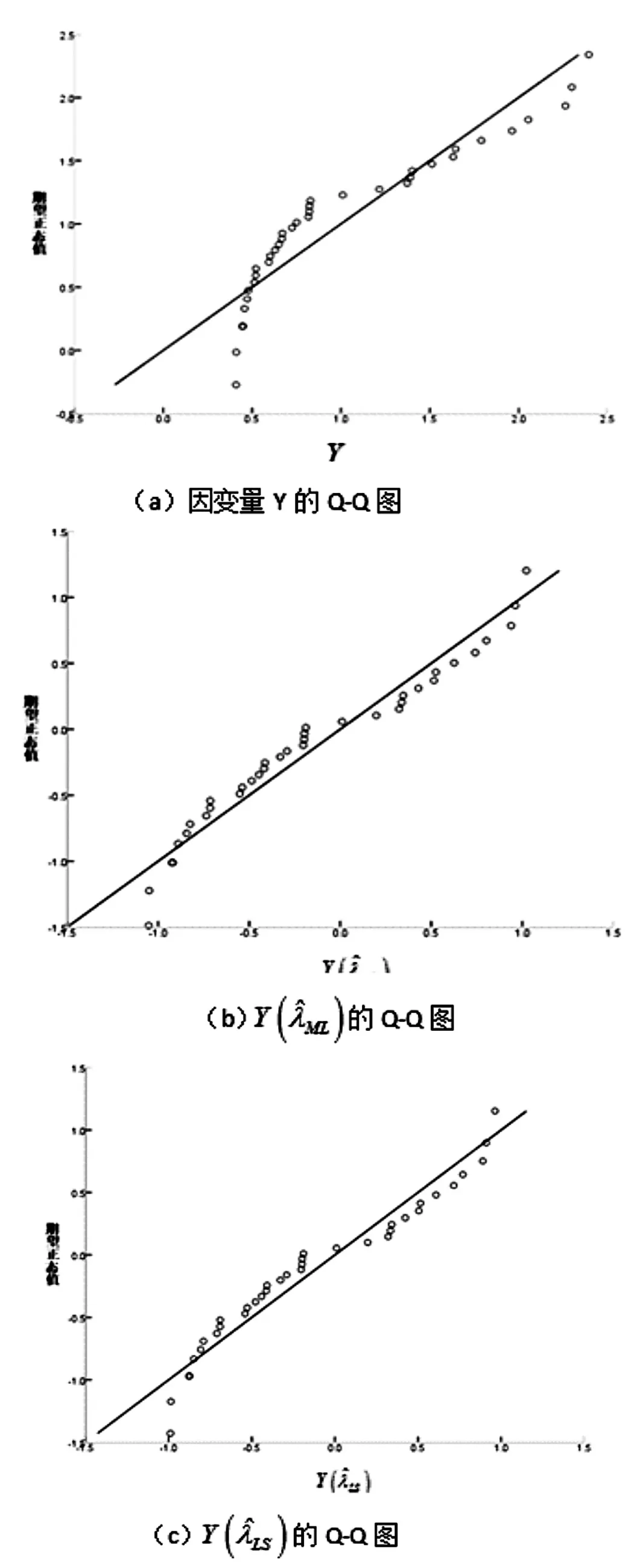
图2 原数据与双幂变换后数据Q-Q图比较Figure 2 Comparison of the original data and the dual power transformation data Q-Q

表4 方差分析Table 4 Variance analysis
从表4中得到,模型复相关系数达到0.998,而决定系数为0.996,取得了较好的拟合优度。检验回归方程的P值为0,小于显著性水平0.05,通过了回归方程的显著性检验,即所得到的回归方程有统计学意义。
标准回归系数的绝对值反映了影响因变量的程度,绝对值越大,则有越大的控制。由表5可看出影响程度从大到小依次为X3、X2、X1。回归方程为:
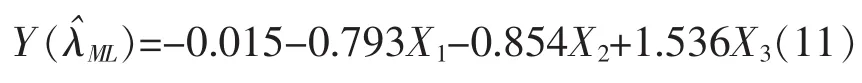
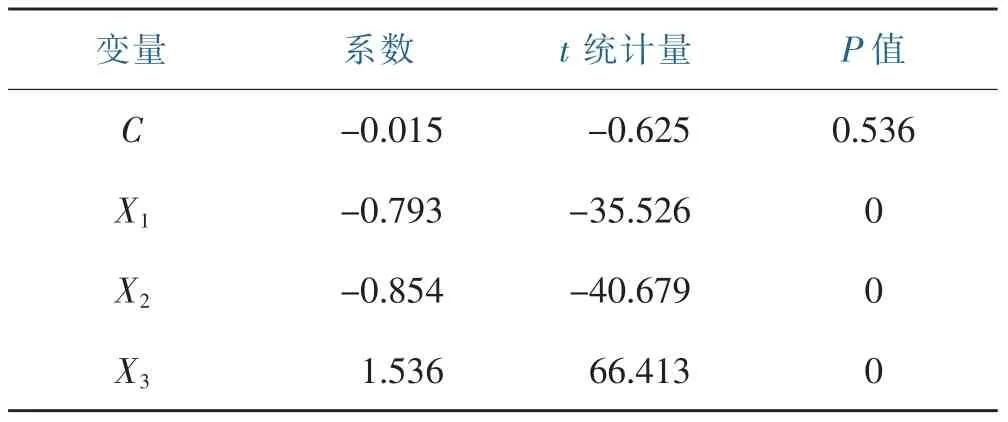
表5 参数估计Table 5 Parameter estimation
回归系数的显著性检验是要检验自变量对因变量的影响是否显著。由表5可知,在显著性水平为0.05时,三个自变量X1、X2、X3的回归系数显著性水平t检验的P值都小于0.05,所以拒绝原假设,即认为这些回归系数和0有显著差异。
4 小结
当搜集回来的样本数据不满足正态分布时,用线性回归模型分析所得到的结论是不准确的。因此,需要进行非正态数据的正态变换。目前,Box-Cox变换是一种研究的最为透彻的方法之一,但存在截断问题。而双幂变换能够克服截断问题。结合Matlab软件给出了双幂变换下线性回归模型中参数的极大似然估计与最小二乘估计的求法。在实例分析中,采用统计软件SPSS对数据诊断其正态性后,用双幂变换对该数据进行正态变换,结果表明双幂变换具有较强的正态变换能力,是非正态数据正态变换的理想工具。
[1]王桂松,史建红.线性模型引论[M].北京:科学出版社,2004:175-178.
[2]王松桂.线性统计模型:线性回归与方差分析[M].北京:高等教育出版社,1999:1-20.
[3]BOX G E P,COX D R.An analysis of transformation[J].Journal of the Royal Statistical Society B,2012(26):211-252.
[4]YANG Z L.A modified family of power transformations[J].Economics Letters,2006,92(1):14-19.
[5]YANG Z L,Anthony F.Inference for general parametric functions in Box-Cox-type transformation models[J].Canadian Journal of Statistics,2008,36(2):301-319.
[6]张学敏.Matlab基础及应用[M].北京:中国电力出版社,2009:201-205.
[7]赵芳芳,贾翔宇,许作良.CIR模型参数校准的极大似然法[J].统计与信息论坛,2015(9):3-7.
[8]李晓晖,袁峰,白晓宇,等.典型矿区非正态分布土壤元素数据的正态变换方法对比研究[J].地理与地理信息科学,2010(6):102-105.
[9]庄泓刚.基于非正态分布的动态金融波动性模型研究[D].天津:天津大学,2009.
[10]焦璨,张敏强,黄庆均,等.非正态分布测量数据对克隆巴赫信度α系数的影响[J].应用心理学,2008(3):276-281.
[11]刘兆君.伴随置信度的线性回归模型[J].统计与信息论坛,2015(7):3-7.
(责任编辑:叶丽娜)
Processing of Non-normal Data in Linear Regression M odel
QIU Tian1,HUAWeiping2,LIBaoyin3,JIANG Xidian4
(1.School of Business,Wuyi University,Wuyishan,Fujian 354300;2.School of Ecology Resource Engineering,Wuyi University,Wuyishan,Fujian 354300;3.Fujian Jiangxia University,Fuzhou,Fujian 350108;4.School of Forestry,Fujian Agriculture and Forestry University,Fuzhou,Fujian 350002)
In order tomake a linear regression analysis on the non-normal data,it is necessary to study the non-normal data processingmethod.Based on the Box-Cox transform,the improved dual power transformation is an effectivemethod.Themaximum likelihood estimation and least square estimation of the parameters in the linear regression model are given by the Matlab software.The case studies show that the non-normal data is subject to normal distribution with the dual power transformation,which has a certain effect on the processing of abnormal data and is an ideal tool for the normal transformation of data.
non-normal data;dual power transformation;linear regressionmodel;maximum likelihood estimate;least squares estimation
O212
A
:1674-2109(2017)06-0053-05
2017-02-16
南平市科技计划项目(N2014Z01);校科研项目(XLZ201401,XL201512S);福建省生态产业绿色技术重点实验资助项目(WYKF2017-8)。
丘甜(1988-),女,汉族,助教,主要从事空间计量模型的统计推断研究。
江希钿(1958-),男,汉族,教授,主要从事生物数学建模研究。
