基于CRF模型的网络新闻主题线索发掘研究
2017-07-18杨小平
徐 静,杨小平
(1. 中国人民大学 信息学院, 北京 100872;2. 中华女子学院 计算机系,北京 100101)
基于CRF模型的网络新闻主题线索发掘研究
徐 静1,2,杨小平1
(1. 中国人民大学 信息学院, 北京 100872;2. 中华女子学院 计算机系,北京 100101)
为了准确挖掘出同一主题的大量网络新闻的线索发展脉络,该文提出了一种基于条件随机场模型的网络新闻主题线索发掘方法。首先,根据新闻主题线索句的识别规则提取出相关特征,并应用到条件随机场模型中提取出主题线索句;然后,按照时间顺序构建原始线索链;最后,对语义相近的原始线索链进行合并处理,获得最终的新闻主题发展脉络。实验结果表明,该方法在主题线索句识别上有较好的效果,最终得到的主题线索脉络能够较清晰地展现新闻发展趋势。
主题线索;条件随机场;线索链
1 引言
网络时代的快速发展使得网上的信息量正以几何级别速度不断增加,而以Web为载体的网络新闻已经成为人们获取信息的重要来源之一。随着时间的延伸,某个主题的网络新闻内容也会随之发生变化,且一篇网络新闻可能只是描绘与主题相关的一个事件的发展片段。如何能够从大量相关网络新闻中挖掘出整个主题的线索脉络,从而帮助用户尽快掌握某个新闻的发展脉络及追踪感兴趣的主题,具有实际意义。
2 相关工作
主题一般是指文本或文档集的中心思想,主题的线索脉络可以反映一个主题从开始发生,到发展的各个阶段,到高潮,再到逐渐没落的整个变化过程。目前,对新闻的主题或话题进行探测主要分为两大类: 一类是针对话题演化或话题线索检测的研究,目前关于这个方面的研究多采用向量空间模型[1-2]或概率模型,文献[2]提出了一个基于TF-IDF的向量空间模型方法以进行初步的话题检测和话题线索抽取,并在模型中加入了时间关系信息。应用广泛的LDA模型属于基于概率的模型[3-4],具有较好的文本主题表示能力。文献[5]运用LDA模型从大量的新闻事件语料中抽取线索,并选择合适的线索词作为线索标签。基于向量空间的模型受限于独立性假设,且存在文本高维度、稀疏等问题。LDA模型比基于向量空间的模型的话题表示能力更强,能有效解决文本高维的问题,但基于LDA模型的方法大都假设任意时刻的话题数目都相同,且话题只能向一个方向演化。另一类是基于事件抽取的主题线索化,其研究目标是依据事件特征的规则从文档或文档集中挖掘出主题线索[6-8]。文献[9]建立一种基于事件框架的信息抽取模式并提出按时间流顺序输出线索性文件。通过定义结构化、层次化的事件框架来实现主题事件的抽取,并应用于灾难性事件检索中。文献[10]提出一种基于事件多向量模型的事件演化分析算法,以发现同一主题下事件的发展演化关系。这种针对新闻内容的事件抽取方法可以提取出单个新闻中事件的结构化元素,但不能对一个新闻主题内部的线索结构以及发展脉络进行探测。
本文在获得主题线索句的基础上,以时间词为线索特征,从大量的主题线索句集合中提取新闻的主题线索。由于条件随机场模型能较好地捕捉上下文信息,已被应用于文本摘要抽取中,并且取得了较好的效果[11-12]。因此,借助条件随机场模型可以得到新闻的主题线索句,然后按照时间顺序构建主题线索链,并对冗余的线索链进行过滤,对语义相近的线索链进行合并处理,最终得到新闻的主题线索集合。实验结果表明,该方法获得的新闻主题线索能较好地表示网络新闻的主题发展脉络。
3 基于CRF模型的主题线索句生成
新闻主题线索的生成需要经过新闻文本内容预处理、主题线索句获取、原始线索链构造和新闻主题线索提取几个步骤完成,具体流程如图1所示。
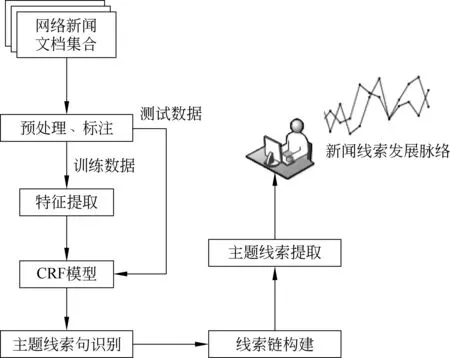
图1 新闻主题线索提取流程
3.1 新闻文本内容预处理
首先对从网络上抽取到的新闻页面进行预处理,主要包括新闻标题、正文内容的提取,并对正文内容进行中文分词、词性标注、句子切分等。
对于一个新闻专题,该专题有一组相关新闻文章,我们将一篇网络新闻的正文看成是一篇文档,可以表示成一个观测到的句子序列S=(s1,s2,…,si,…,sm),m为句子的个数,将每条句子进行分词,去除停用词、虚词,并将剩下的实词按照权重大小进行排列,每一条句子可表示为si=(w1,w2,…,wj,…,wn),n为句子si中的实词个数,即n为句子的长度。ωj为实词wj的权重,用式(1)进行计算。
其中,Tj为实词wj在文本中出现的频率,m为文本的句子总数,nj为实词wj出现的句子数。
3.2 主题线索句识别
利用条件随机场(CRF)模型可以对主题线索句进行识别。对于文档中的主题线索句识别问题可以转化为序列标注问题,将文档分解成可观测的句子序列,并采用具有强大的特征描述能力的CRF模型,同时将观测序列中的相关特征加入到CRF模型中,最后产生可识别主题线索句的标注序列[13]。
3.2.1CRF模型
CRF模型是由Lafferty等人于2001年在最大熵和隐马尔科夫模型的基础上提出的一种基于统计的无向图模型,它可以任意选择特征,并且对所有特征进行全局归一化,从而得到全局最优解[14-15]。CRF模型主要用于处理序列标注问题,近年来CRF模型在自然语言处理、信息抽取等领域都有了广泛的应用。在CRF模型中,给定一个观测到的句子序列S=(s1,s2,…,sm),输出相应的标注序列Y=(y1,y2,…,ym),这里的yi从一个集合φ={0,1}中取值。CRF的目标是找到序列Y,使得式(2)最大化。
其中,fj(yi-1,yi,S)是标记观测序列的特征函数,它一般取布尔值,W=(w1,w2,…,wm)是经过训练数据对模型训练后各特征函数所对应的权重值,对于W的估计一般采用最大似然法,同时为了避免过拟合,一般给参数加入高斯先验。Zs是一个归一化因子,它通过式(3)进行计算。
3.2.2 特征选取
CRF模型的学习与预测是在样本的多个特征上进行的。如何针对特定的任务为模型选择合适的特征集合是使用CRF模型进行主题线索句识别的关键步骤。CRF模型不仅能使用句子位置、句子长度、词典及语义等特征,还能利用它们组合而成的复杂特征。
在应用CRF模型提取主题线索句时,采用的特征包括以下几个。
(1) 文本基本特征: 包括长度特征Len和位置特征Pos。
长度特征: 指句子去除停用词后的词汇数量,通常长句较之短句包含有更多的信息,即较短的句子是主题线索句的可能性较小。
长度特征函数如式(4)所示。
位置特征: 指句子处在正文中的位置。文章开头一般多为概述全文的主题句,结尾句有时也会是总结性的主题句。因此,我们标记在文章的开始段落为B,结尾段落为E,其余位置为I。
位置特征函数如式(5)所示。
(2) 词典特征Dic: 建立了时间和地点两种词典。时间和地点是新闻事件的基本要素,也是表示新闻主题线索的重要元素。因此,如果句子中包含的单词属于时间词典(Dtime)或地点词典(Daddress)中的一项,则该句子有可能被标记为主题线索句(topiccluesentence)。
基于词典的特征函数如式(6)所示。
fD(si,wj)=
(3) 语义特征: 包括关键词特征Key、与标题相近度特征SimT和与相邻句子相似度特征SimS。
关键词特征: 指句子去除停用词后包含的关键词数量,用sumw表示。句子包含的关键词越多,被标定为主题线索句的可能性也越大。
关键词特征函数如式(7)所示。
fK(si,sumw)=
与标题相近度特征: 标题包含了新闻内容的重要信息,句子与标题相似度越大,则通常更可能出现在主题句中。
与标题相近度特征如式(8)所示。
句子si与标题的相近度计算公式如式(9)所示。
其中,TW={tw1,tw2,…,twm)表示标题的词语集,si=(w1,w2,…,wj,…,wn)表示一条句子的词语集,f(twi) 表示词twi在当前文本中出现的次数,f(twi∩wj)表示词twi与词wi在当前文本中共同出现的次数。
与相邻句子相似度特征: 与前后句子的相似度在一定程度上可反映句子在局部的重要性。与相邻句子的相似度越大,则成为主题线索句的可能性越大。相似度计算公式同式(9)。
根据以上考虑,我们定义了模型中的特征模板,每一个特征可作为一个原子模板(长度特征Len用L表示,位置特征Pos用P表示,关键词特征Key用K表示,与标题的相近度特征SimT用T表示,与相邻句子的相似度特征SimS用S表示)。很多时候如果上下文只采用原子模板,则很难完全描述语言中的复杂现象。通过对原子模板进行组合,构成相应的组合特征模板来表示较复杂的、非线性的上下文信息。在本文中,设计了如表1所示的复合特征模板,为了增加对上下文信息的描述,还要将上述各特征模板分别做-2,-1,1, 2四个位置的偏移,这些特征可以用二值特征函数的形式来表示。
3.3 原始线索链构建
利用条件随机场CRF模型识别出每篇新闻文章的主题线索句, 把所有的主题 线索句放到一起构成与新闻主题相关的线索集合,用每一个线索句来构造一条原始线索链,通过原始线索链的构建将与新闻主题相关的所有线索聚集起来。

表1 CRF模型特征模板
线索中最重要的部分是时间。主题线索句中的实词(可称为线索关键词)在语义上也可表示线索与新闻主题的相关度。用线索时间和线索关键词来构建原始线索链。因此,首先要提取出主题线索句中的时间。考虑到一个句子中可能包含多个时间词或者没有时间词的情况,我们设定如下规则来识别主题线索句中的线索时间:
(1) 如果句子中有多个时间词,取最靠前的时间词作为该句的线索时间;
(2) 如果句子中没有时间词,取句子所在段落中的第一个时间词作为该句的线索时间;
(3) 如果句子所在的段落也没有时间词,则往前选取离句子所在段落最近的一个段落的第一个时间词作为该句的线索时间。
经过处理后,每一个主题线索句都包含一个时间,将此时间词ti作为该原始线索链的链头结点。然后将该主题线索句中的实词(去掉停用词后的名词和动词)按照词频权重由高到低依次加入相应原始线索链中。该链表的结点分为数据域和指针域,数据域存储的数据为(w,value),w为实词,value为该实词的权重值,指针域存储指向后续结点的指针,结点按其数据域中实词对应的权重值降序排列。

3.4 新闻主题线索提取

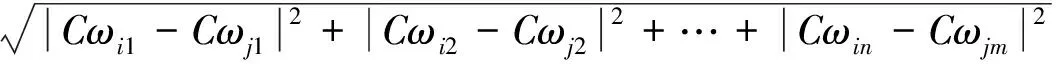
其中, ti为原始线索链OCi对应的时间,即该线索的发生时间,当任意两条原始线索链的时间间隔小于平均时间间隔时,我们对这两条原始线索链之间的语义相似度进行计算。Cωij表示原始线索链OCi中的实词wj的权重值。当dist(OCi,OCj)小于阀值α时,认为两条原始线索链OCi和OCj是相似的,可以对这两条线索链按照链表的插入方法进行合并处理。
对原始线索链按时间排序及语义合并处理后,就可以利用线索的发生时间和其强度来表示主题线索的发展趋势,每一条线索链链头中所包含的时间为线索的发生时间,每一条线索链上所有结点的权重平均值及该线索链来源的文本数量决定该线索的强度。线索链OCi的线索强度VCi的计算如式(11)所示。
其中,k为原始线索链语义合并后剩下的线索链个数,di表示线索链OCi的线索来源的文本数量,即该线索链是经过多少条原始线索链合并而成的。
4 实验结果分析
4.1 实验语料
由于目前没有针对中文新闻主题线索句进行评测的标准数据集,所以本文采用人工标注的方法构造评测数据集。实验中采用的语料是从新浪网抽取的六个新闻专题下的新闻报道。所有新闻通过网页分析,去除广告链接等无关内容,并进行规范化处理,并筛选掉少于三句话的新闻文章,最终选出文本3 105篇。
我们按照第三节介绍的方法对六个主题的新闻文档集合进行处理,将实验分为两个部分进行验证: (1)利用CRF模型识别新闻的主题线索句;(2)构建原始线索链获取新闻主题线索。表2给出了实验数据集的简要描述和结果统计表。

表2 实验数据集统计表
4.2 CRF模型识别主题线索句实验
由于人工标注的局限性,我们仅对“人民币汇率持续贬值”,“乌克兰局势动荡”“四川雅安7.0级地震”3个主题共1 986篇新闻进行主题线索句识别的实验验证。实验前先手工标注出这些新闻的主题线索句,且实验中假设这些标注全部为正确标注。将所有语料分为两部分,其中1 490篇作为训练语料,其余496篇作为测试数据集合。本文的分词、词性标注等使用了中科院的分词工具ICTCLAS的工具包,并选用CRF ++v 0.53(http://crfpp.sourceforge.net/)对模型进行训练和测试,实现基于CRF模型的主题线索句识别任务。
对于识别性能进行评测时,采用准确率(P)、召回率(R)、综合指标F1值(F1)三个指标来进行评价。在基于CRF的主题线索句识别中,特征函数的选取对识别性能起着关键性的作用。因此在训练CRF模型时,选用了不同的特征组合,以挑选最优的特征模板,表3是采用不同特征模板的实验对比结果。从表3的实验结果可看出,采用文本基本特征和词典特征的组合方式时,主题句的正确识别率不高,这是由于仅通过句子长度、位置,以及是否包含时间地点词这样的特征,会识别出很多非主题线索句,导致准确率较低,召回率反而更高一些。而在此基础上加入语义特征,可以明显地提高识别效果,这是因为关键词本身可以表示文本的语义内容,而标题往往都是文本主题内容的凝练,上下文关系可体现句子的局部重要性,因此加入任意一种语义特征都可以改善主题线索句的识别效果;而模板3较模板2的准确率低是因为有少量网络新闻采用了更吸引人眼球的标题党,并没有反映文本的主题,因此加入与标题相似度特征的组合模板对主题线索句识别有一定的局限性。实验结果显示当组合所有特征时,实验方法能够识别出F1值为80%以上的主题句,说明加入语义特征能达到较好的识别效果。
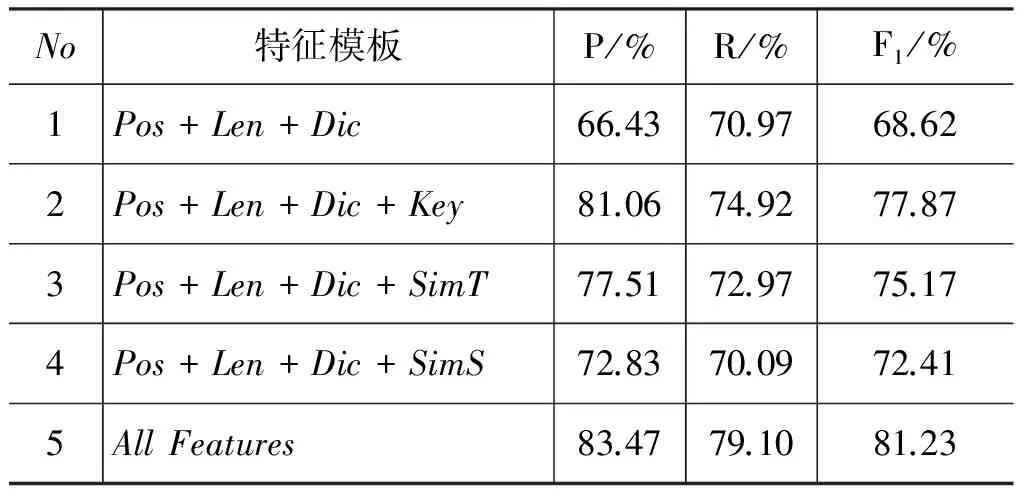
表3 特征模板对比结果
为了验证CRF模型识别主题线索句的有效性,以文献[8]为基准,基准的方法是结合中文新闻句子的词频、长度、位置及与标题的相似度等特征计算句子的重要性,并进一步提取出新闻的主题句。表4给出了本文采用的方法和文献[8]的对比情况,这里仅取“乌克兰局势动荡(专题1)”“叙利亚局势持续动荡(专题2)”“马来西亚客机在乌克兰坠毁(专题3)”三个新闻专题进行验证。
4.3 新闻主题线索提取实验
利用CRF模型识别出每篇新闻的主题线索句,并按照第三节原始线索链的构造方法进行主题线索提取。为了评测主题线索抽取的有效性,我们将本文方法得到的新闻主题线索与新浪专题下给出的按时间轴的主题发展关键点(包括关键时间点和对应的事件描述)进行对比。我们针对“乌克兰局势动荡”“马来西亚客机在乌克兰坠毁”这两个新闻专题将实验中得到的主题线索和新浪专题给出的参考关键点进行对比。
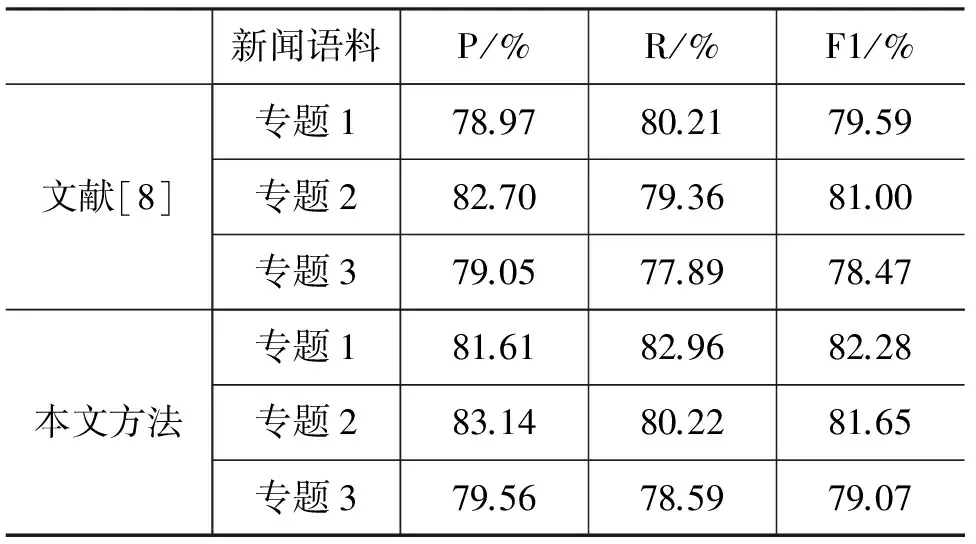
表4 不同主题语料下的实验结果对比
评测方式根据获取的主题线索的覆盖率C和准确率R来衡量。覆盖率为识别出的正确的主题线索占新浪参考关键点的比例,反映出本文算法获取主题线索的能力。准确率为本文识别出的正确的主题线索占总的主题线索的比例。由于“乌克兰局势动荡”“马来西亚客机在乌克兰坠毁” 这两个新闻专题的复杂性较高,因此产生的主题线索个数较多,实验中我们分别取线索强度较高的前15、20、30个主题线索进行实验验证。从图2的实验结果可看出,针对这两个新闻专题,当取线索强度较高的前20个主题线索来形成新闻主题的发展概述,准确率和覆盖率都较好。
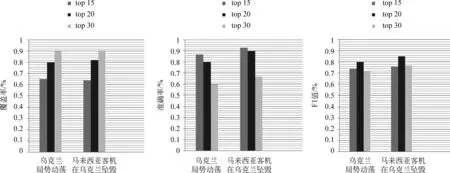
图2 新闻主题线索提取实验评测结果
利用线索链的线索时间ti和线索强度VCi可以生成新闻主题的发展趋势图。图3给出了“叙利亚局势持续动荡”新闻专题的主题线索发展脉络图,图中的折点就是获取到的主题线索。从图3的结果可以看出,我们的方法不仅可以清晰地发现新闻的主题线索,而且还能动态地反映新闻主题线索强度变化和发展趋势。相比于新浪专题按时间轴给出新闻主题的关键时间点及对应的事件描述,我们的方法能自动化地从大量相关新闻中挖掘出新闻的主题线索,同时还能表现出整个主题的动态发展趋势。
5 结束语
本文针对网络上同一主题的大量相关新闻进行研究,提出了一种基于条件随机场模型的网络新闻主题线索发掘方法。该方法首先利用条件随机场模型提取出主题线索句,然后以时间词为线索特征构建主题线索链,最后对语义相近的线索链进行合并处理,获得新闻主题发展脉络,解决了目前话题演化和事件抽取研究中无法实现关于同一主题的新闻线索发展脉络的问题。实验结果表明该方法在主题线索句识别和新闻主题线索构建上有着良好的效果。但是仍有需要进一步研究的地方,包括: (1)在利用CRF模型识别主题线索句时,要扩大训练语料库的规模,并进一步完善语义特征,以改进模型的效率,提高识别的准确率;(2)在语料选取上考虑收集多来源即多个网站上的网络新闻,并将网站的权威度及新闻时效性、可信度等因素加入到线索强度中,从而使新闻的主题线索抽取研究更加完善。

图3 新闻主题线索发展脉络图
[1]ZhangXiaoyan,WangTing.Topictrackingwithimprovedrepresentationmodelandjointtrackingmethod[J].InternationalJournalofWavelets,Multi-resolutionandInformationProcessing, 2010, 8(6): 913-930.
[2]AdamsPH,MartellCH.Topicdetectionandextractioninchat[C]//ProceedingsofIEEEInternationalConferenceonSemanticComputing.LosAlamitos,CA,2008: 581-588.
[3]BleiD,NgA,JordanM.Latentdirichletallocation[J].JournalofMachineLearningResearch, 2003(3): 993-1022.
[4] 单斌,李芳.基于LDA话题演化研究方法综述[J].中文信息学报, 2010,24(6): 43-49.
[5]YanZehua,LiFang.Threadlabelingfornewsevent[J].JournalofShanghaiJiaotongUniversity(Science),2013,18(4): 418-424.
[6]SmritiSharma,RajeshKumar.Newseventextractionusing5w1Happroach&itsanalysis[J].InternationalJournalofScientific&EngineeringResearch,2013,4(5): 2064-2068.
[7]ZhaoC,YiD.Textresourceemergence:discoveringevolutionaryeventpatternsfromwebtexts.Kybernetes, 2012, 41(9): 1386-1395.
[8] 王伟,赵东岩,赵伟.中文新闻关键事件的主题句识别[J].北京大学学报(自然科学版),2011,47(5): 789-796
[9] 梁晗, 陈群秀等. 基于事件框架的信息抽取系统[J]. 中文信息学报, 2006, 20(2): 40-46.
[10] 吕楠, 罗军勇等. 一种有效的事件演化分析算法[J]. 计算机应用研究, 2009, 26(11): 4101-4104.
[11] 吴晓峰, 宗成庆. 一种基于LDA的CRF自动文摘方法[J]. 中文信息学报, 2009, 23(6): 39-45.
[12] 张龙凯, 王厚峰. 文本摘要问题中的句子抽取方法研究[J]. 中文信息学报, 2012, 26(2): 98-101.
[13]NenkovaA,McKeownK.Asurveyoftextsummarizationtechniques[M].CharuCAqyarwal,ChenXingZhai.MiningTextData.SpringerUS, 2012: 43-76.
[14]ShenDou,SunJiantao,LiHuaetal.Documentsummarizationusingconditionalrandomfields[C]//Proceedingsofthe20thinternationaljointconferenceonartificialintelligence, 2007: 2862-2867.
[15]SuttonC,McCallumA.Anintroductiontoconditionalrandomfields[J].MachineLearning, 2011, 4(4): 267-373.
TopicCluesExtractionofNetworkNewsBasedonConditionalRandomFields
XU Jing1,2, YANG Xiaoping1
(1. School of Information, Renmin University of China, Beijing 100872, China; 2. Computer Department, China Women’s University, Beijing 100101, China)
To accurately find out the clues of the same topic from a large number of Web news, a method of topic clues mining is proposed based on the Conditional Random Fields model. Firstly, according to the identification rules of the topic sentence, the relative characteristics were extracted and utilized on the Conditional Random Field model to get the candidate topic sentences. Then the lexical chains of topic clues were built by chronological order and lexical weight. Finally the similar clue chains in semantic needed to be merged and the whole development context of network news can be described. The experiment results show the method proposed achieves a good performance on the topic clue sentence extraction and the topic clue chains obtained can clearly show the development trend of network news.
topic clue; conditional random fields; clue chain

徐静(1980—),博士,讲师,主要研究领域为Web可用性评估,语义分析。

杨小平(1956—),博士,教授,主要研究领域为信息系统工程。
1003-0077(2017)03-0094-07
2015-06-05定稿日期: 2015-12-07
国家自然科学基金(71271209);北京市自然科学基金(4132067);教育部人文社会科学青年基金(11YJC630268)
TP391
: A
