基于内涵模糊概念格的汽车评价知识发现方法研究
2017-07-18郭晓敏王素格梁吉业
李 旸,郭晓敏,王素格,2,梁吉业,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
基于内涵模糊概念格的汽车评价知识发现方法研究
李 旸1,郭晓敏1,王素格1,2,梁吉业1,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
为了有效利用汽车评论数据,参照已建立的汽车评价本体,从文本中抽取评价搭配对,提出基于五元组的对象评价度量,从而获取汽车评价模糊形式背景。在模糊形式背景中,定义了内涵模糊概念和内涵模糊概念格。设计了模糊形式背景和内涵模糊概念格构建算法,并以实例对如何基于内涵模糊概念格进行知识发现予以讨论。
汽车评价;知识发现;模糊形式概念分析;内涵模糊概念;模糊概念格
1 引言
Web2.0技术的在线交互性使得用户产生的数据呈现爆炸式增长,但人们在享有先进技术所带来的便利性的同时,也面临着如何从海量评论数据中寻求有价值信息的难题[1]。互联网上的海量用户评论数据蕴含着巨大的价值,比如,企业可通过对产品评论数据的价值挖掘,及时了解用户的反馈和建议,以辅助产品定位、产品设计、营销策略等企业生产经营中的决策过程。然而,在产品评价领域,如何有效地挖掘、表示和组织数据中蕴含的大量有价值的评价知识是自然语言处理和知识工程领域亟需解决的问题。
在基于知识的系统中,知识表示的形式多种多样,但形式简洁、便于推理的概念、规则、关联等占有重要的地位。然而,在文本大数据环境下,鉴于语言现象的复杂性和数据的不确定性,即使限定领域,研究知识表示及基于数据挖掘技术构建领域知识库也仍是一项挑战性工作。
本文针对互联网上的海量汽车评论数据,提出了一种基于内涵模糊概念格的汽车评价知识发现方法。该方法首先依据面向观点挖掘的汽车领域本体,从原始语料中抽取评价搭配五元组,并通过定义属性对评价对象的情感倾向性指标构建模糊形式背景;然后,利用置信阈值、内涵模糊形式概念和偏序关系等,构建方面粒度意义下的汽车评价内涵模糊概念格;最后,基于构建的内涵模糊概念格,利用规则抽取技术和概念相似性度量等,形成汽车评价知识库。该方法具有以下特点: 内涵模糊形式概念为概念描述提供了一种新颖的形式,同时可作为规则和关联知识的基本单元;内涵模糊概念格可作为知识的结构化组织方式;置信阈值可调节控制知识库的规模。
2 相关工作
知识的表示形式主要有案例式、逻辑模式、框架式、语义网络、产生式(规则)、状态空间等[2]。不同的知识获取方法对应于不同类型的知识表示方式,而不同的知识表示方式又对应于不同的知识组织方式。
目前,常用的知识库构建方法有基于本体的方法和基于认知模型的方法两类。基于本体的知识库构建方法已相当成熟,而基于认知模型的方法还在被不断地深入研究。Liwei Tan[3]等在其专著中论述了基于认知模型的知识库构建方法,并对两种方法的异同进行了讨论。形式概念分析(formal concept analysis,FCA)[4]是一种基于概念内涵与外延统一性认知,以格结构的形式直观化隐含在数据中概念的特化和泛化关系的数学工具。FCA不仅提供了一种从数据中挖掘概念的方法,同时将获取的概念以格的形态进行组织,有利于概念规则的生成和概念关联的建立,在知识获取和处理中扮演着重要角色[5]。Belen[6]论述了FCA作为基于事例推理(case-based reasoning,CBR)的支撑技术的可能性,他们利用FCA从事例中获取知识并建立知识库,表明FCA能够刻画事例知识库中概念化结构的本质。它不仅可找到事例中的模式、规律和例外,还可从描述事例的属性中抽取依赖规则,从而指导知识库查询过程。Muangprathub[7]利用FCA作为知识发现与组织的基本工具,构建了增量式知识库,进而构建CBR系统。模糊集理论(fuzzy sets)[8]是关于不确定性最重要的理论之一。模糊集理论还衍生了重要的不确定性推理理论——模糊逻辑(fuzzy logic,FL)。Achiche[9]利用模糊逻辑,提出了构建知识库的方法FL-GA,并与另一种基于模糊逻辑的知识库构建方法FL-MA进行了对比分析。为了拓展应用范围,许多知识获取的理论与方法被推广至模糊背景下,FCA也不例外。Tadrat[10]将模糊集引入经典FCA,通过将数值型的多值属性转化为0-1二值属性,然后利用FCA构建知识库,结果表明构建的知识库提升了CBR系统的分类效果。经典的FCA是处理0-1形式背景的,即对象要么有某种属性,要么没有某种属性,它不能反映对象具有某种属性的“程度”。将模糊集或模糊逻辑与经典的FCA相结合有利于刻画数据中的模糊性,挖掘具有模糊属性的概念和规则,构建具有模糊属性的知识库,拓展FCA的应用场景。
3 内涵模糊概念格
经典的FCA通过伽罗瓦连接从所谓的经典形式背景中抽取概念,定义概念间的偏序关系,进而构建概念格。为了适应数据的不确定性,特别是模糊性,Quan等人[11]将模糊集与经典FCA相结合,发展了一类模糊形式概念分析技术(fuzzy formal concept analysis,FFCA),其对应的概念格被称为模糊概念格。这一拓展从对经典形式背景的推广开始。
定义1[11]三元组K=(O,A,R)被称为一个模糊形式背景,其中O是有限对象集;A是有限属性集;R是O×A上的一个模糊关系,即存在一个映射μ:O×A→[0,1],使得对任意的o∈O,a∈A,有μ(o,a)∈[0,1],μ(o,a)被称为(o,a)隶属于关系R的隶属度。
显然,当模糊关系R退化为一个确定性关系时,模糊形式背景就退化为一个经典的0-1形式背景。模糊形式背景可以表示为一个二维表。表1给出了一个面向汽车评价的简单模糊形式背景。

表1 一个面向汽车评价的简单模糊形式背景
其中,对象集O={桑塔纳,比亚迪G3,马自达2},属性集A={动力性,加速能力,坡道表现},模糊关系R由相应的隶属度μ(o,a)所定义,比如,μ(比亚迪G3,加速能力)=0.84等。本例中,模糊关系R表示“动力性”、“加速能力”及“坡道表现”等属性对对象即汽车在评价情感方面的影响程度,其值越大,表示汽车在这一属性下的评价越高,反之,评价越低。
实际应用中,为了聚焦于感兴趣的对象(属性)或得到有意义的概念,设置阈值是一种常用的技巧。为此,在模糊形式概念分析中,需要对模糊关系的隶属度设置阈值,它可以用来控制从数据中抽取的概念数量,从而控制所生成的模糊概念格的规模和生成的规则数量。
定义2[11]设K=(O,A,R)是一个模糊形式背景,给定隶属度置信阈值λ∈[0,1]。设W⊆O,V⊆A,定义两个映射如下:
定义2中,W*表示W中对象所共有的隶属度不小于置信阈值λ的属性;V*则表示在V中所有属性下隶属度都不小于置信阈值λ的对象全体。
例如: 对表1所示的模糊形式背景,给定置信阈值λ=0.5。设W={桑塔纳,马自达2},则W*={坡道表现}。设V={动力性,坡道表现},则V*={桑塔纳}。
定义3设K=(O,A,R) 是一个模糊形式背景,给定置信阈值λ。设W⊆O,V⊆A,满足W*=V,V*=W,则称二元组(W,VF)是一个内涵模糊形式概念,其中属性a∈V隶属于该模糊概念的隶属度μa=mino∈Wμ(o,a)。
需要说明的是,在定义4中,VF的上标是为了强调VF是一个定义在V上的模糊集。另外,为了表示及推导方便,约定(O,∅)=(O,{a(μa=0)}a∈V)和(O,A)=(∅,{a(μa=1)}a∈V)是两个特殊的内涵模糊概念。
根据定义3,不难得到表1所示的模糊形式背景中的所有内涵模糊概念,它们被罗列在表2中。比如,Concept 3=({桑塔纳,比亚迪G3},{动力性(0.7),加速能力(0.5)}),其中属性后所列数值表示该属性隶属于此概念的隶属度。

表2 由表1中抽出的内涵模糊概念
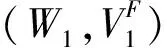

以CS(Kλ)表示模糊形式背景K在置信阈值λ下产生的所有内涵模糊概念。容易证明,上面定义的≤关系是CS(Kλ)上的一个偏序关系,且偏序集(CS(Kλ, ≤)构成了一个格,称其为内涵模糊概念格。
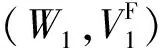


例如,计算表2中Concept1和Concept3的相似度,则有
图1给出了由表2所示的模糊形式背景在置信阈值λ=0.5时所得到的内涵模糊概念格,连线上的权重表示其所连接的两个概念的相似度。

图1 表2所给定的模糊形式背景在λ=0.5时所获内涵模糊概念格
定义6设C=(W,VF)是一个内涵模糊概念,称gran(C)=|W|,即概念外延中所包含的对象的个数,为概念C的粒度。
内涵模糊概念的粒度越小,表明概念的外延越少,内涵属性越多。概念的粒度越大,表明概念的外延越多,内涵属性越少。
4 汽车评价知识库的构建
汽车评价知识库的构建分为两个阶段: 构建模糊形式背景和内涵模糊概念格。首先,依据汽车本体[12]抽出评价搭配对构成五元组,将其处理后得到模糊形式背景。然后,在一定的置信阈值下,从构造的模糊形式背景中抽取内涵模糊概念;采用渐进式算法构建对应的内涵模糊概念格;计算相邻模糊概念的相似度并添加到对应的边上,形成内涵模糊概念格。最终,构建面向汽车评价的知识库。主要流程如图2、图3所示。
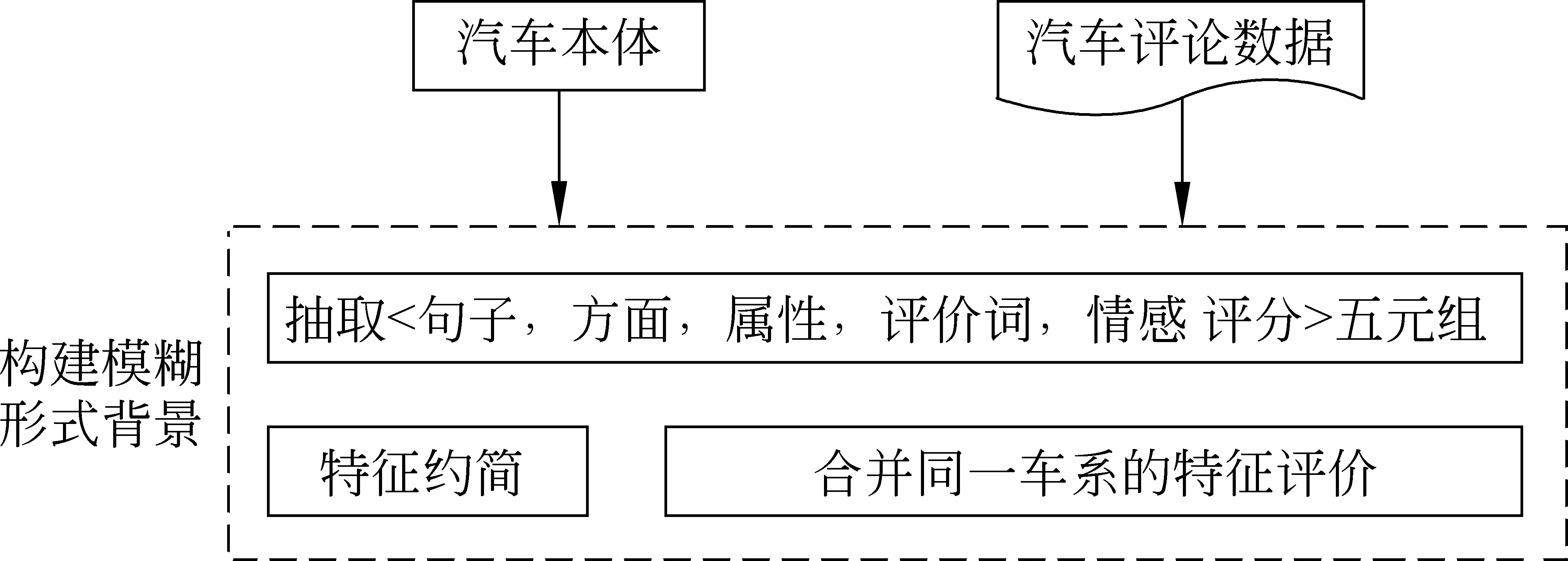
图2 汽车评价知识库构建流程图—构建模糊形式背景

图3 汽车评价知识库构建流程图—构建内涵模糊概念格
4.1 构建模糊形式背景
构建面向汽车评价的模糊形式背景,需要度量属性对对象即汽车在评价情感方面的影响程度,并用来作为模糊形式背景中的模糊关系R。
定义7设o是一个汽车品牌(对象),a是用于评价汽车的一个属性(特征),属性a对对象o的重要度μ(o,a)定义为

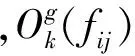
算法1构建面向汽车评价的模糊形式背景K。
Input: 汽车评论语料。
Output: 模糊形式背景K。
Step 1: 将原始语料按照车系(g=1,2,…)进行分类存储。



Step 5: 将Step 4中的五元组按方面分解为6个矩阵表示(行标签为车系,列标签为属性),并依据公式(5)计算出方面a对车系g的重要度μ(g,a),得到面向汽车评价的模糊形式背景K。
4.2 构建内涵模糊概念格
本节在Godin[14]的渐进式概念格构建算法中,对概念添加相应的对象隶属度,构建面向汽车评价的内涵模糊概念格CS(Kλ)。
算法2构建面向汽车评价的内涵模糊概念格CS(Kλ)。
Input: 面向汽车评价的模糊形式背景K,置信阈值λ。
Output: 面向汽车评价的CS(Kλ)。
Step 1: 更新内涵模糊概念格的最小元。
Step 2: 遍历现存节点。
Step 3: 将当前要插入的对象和格中所有的节点求交集,判断格中节点是下面的哪类节点。
Step 3.1 不变点: 新增对象的属性和它们的内涵交集是空的;
Step 3.2 更新节点: 若新增对象拥有的属性集包含了这些节点的内涵,则将该对象加到节点的外延中;
Step 3.3 新增节点: 若加入的对象的内涵与原来格中某个节点的内涵的交集不在格中出现,则新节点的父节点是某个新增节点或更新节点。
Step 4: 修改现存节点或增加新的节点(给每个节点的属性添加相应的隶属度),并将它放在适当的位置。
Step 5: 依据节点的修改进行边的修改。
Step 6: 循环Step2~Step5,直到将所有的对象都用于构建内涵模糊概念格。
Step 7: 依据公式(4),计算相邻内涵模糊概念的相似性度量,并将其添加到对应的边上。
5 知识库构建实例
5.1 数据及预处理
数据选取了新浪汽车网站上价格区间为5万~20万的374个车系的37 646条评论。
首先,通过添加汽车本体中的属性词和评价词到用户词典中,利用中科院分词软件ICTCLAS将评论数据进行分词,并标注出属性词和评价词。筛选包含属性词和评价词的评论13 013条,相应的车系为338个。相应的语料统计信息如表3所示。

表3 新浪汽车价格区间为5万~20万的汽车评论语料统计信息表
关于汽车评价的每个方面都对应着一定数量的属性,经过属性约简,这些属性对应着模糊形式背景中的属性,汽车六个方面所对应的属性数如表4所示。

表4 汽车六个方面所对应的属性数
5.2 参数分析
在汽车评价知识库的构建过程中,参数词窗口大小windsize和置信阈值λ会影响知识库的构建效果。词窗口windsize的具体设置依据文献[15]。为了分析和说明置信阈值λ对知识库构建的影响,设计了以下两个实验。
实验1: 置信阈值λ对知识库规模的影响。
知识库的规模由内涵模糊概念格的规模所决定,而内涵模糊概念格的规模可由内涵模糊概念的数量定量表示。实验对比了每个方面在9个不同的λ取值点下(从0.1到0.9,步长为0.1)所获得的内涵模糊概念数量。图4和图5分别给出了“安全性”和“服务性”两个方面的实验结果。

图4 汽车安全性在不同λ值下的内涵模糊概念数量
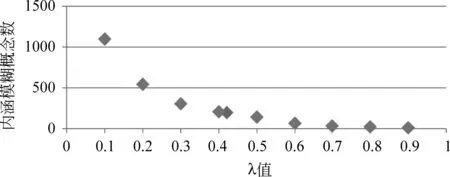
图5 汽车服务性在不同λ值下的内涵模糊概念数量
由图4和图5可知: 随着λ的增大,内涵模糊概念个数减少,即知识库的规模在减小。λ取值分别为0.593 6和0.415 2时,内涵模糊概念数目处于平均水平。
实验2: 置信阈值λ对内涵模糊概念粒度的影响。
本实验对比了每个方面在不同置信阈值下内涵模糊概念的平均粒度。图6和图7分别给出了“安全性”和“服务性”两个方面的情形。
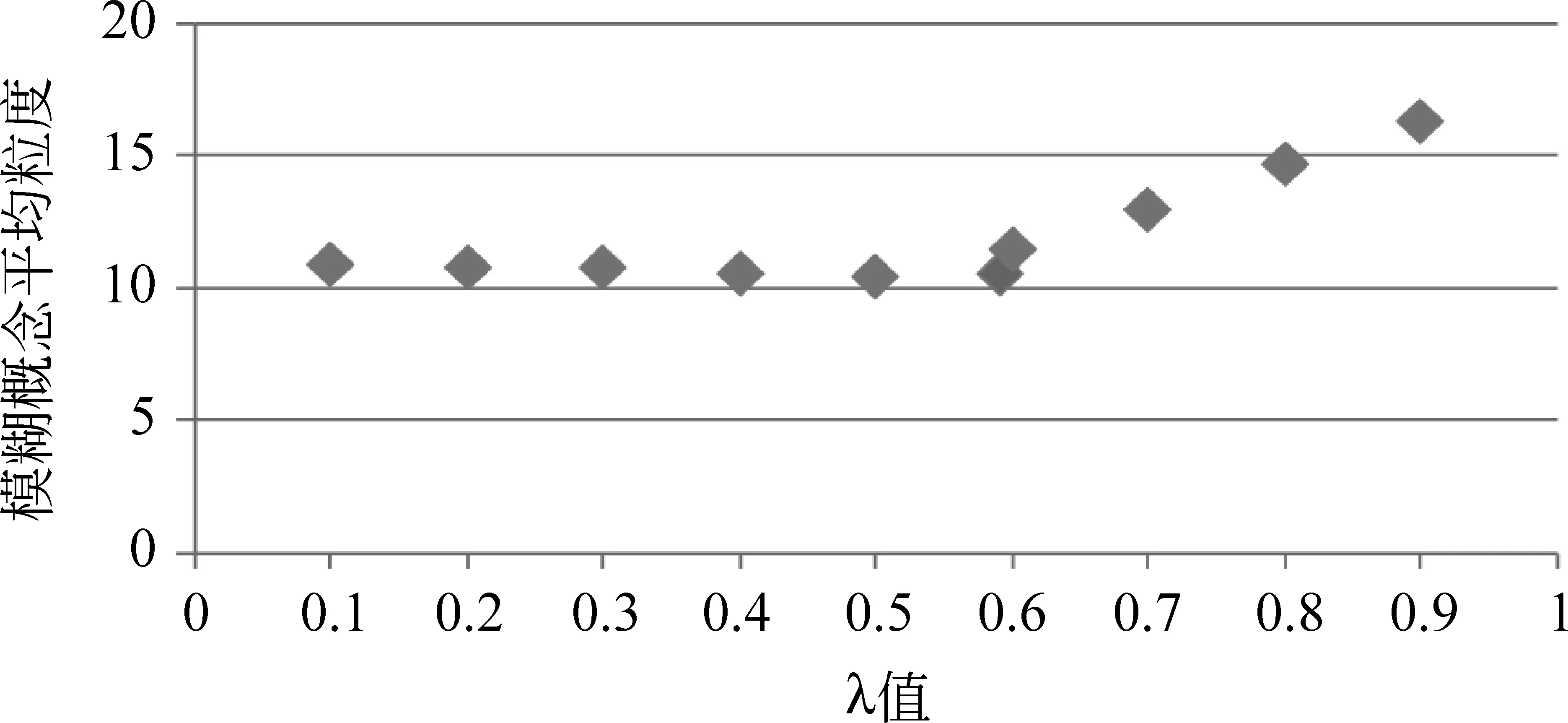
图6 汽车安全性在不同λ值下模糊概念平均粒度
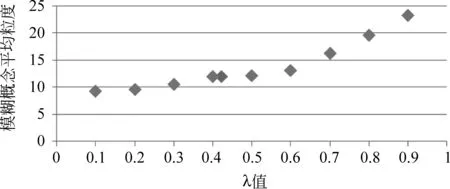
图7 汽车服务性在不同λ值下模糊概念平均粒度
由图6和图7可知: 随着λ的增大,两个方面的内涵模糊概念平均粒度呈现增大趋势,在λ值分别取0.593 6和0.415 2时,内涵模糊概念的平均粒度处于平均水平。
上述实验1和实验2表明:λ越小,获得的内涵模糊概念越多,概念的粒度越小,知识库规模越大;λ越大,获得的内涵模糊概念越少,概念的粒度越大,知识库规模越小。但在实际应用中,可根据问题的需要结合领域专家意见合理选择置信阈值。
5.3 知识库构建结果
依据第4.2节的内涵模糊概念格构建过程和第5.2节的参数分析,windsize针对不同的搭配对抽取模式设置为3或5个词长,得到了15 633个五元组。依据汽车本体中六个方面的属性词将其矩阵化后得到了的模糊形式背景,然后由模糊形式背景构建了内涵模糊概念格这一汽车评价知识库的表示核心,其中知识以内涵模糊概念来表示,知识库的框架以格结构来表示。表5所示汽车的六个方面在置信阈值λ取其对应的模糊形式背景K的隶属度均值时所获得的概念数量和概念平均粒度情况。其中,汽车经济性在λ取隶属度均值0.271 6时所获内涵模糊概念格和部分概念如图8和表6所示。需要说明的是,在图7中,并没有标注相邻概念的相似度。比如,Concept 11和Concept 30的相似度见式(7)。
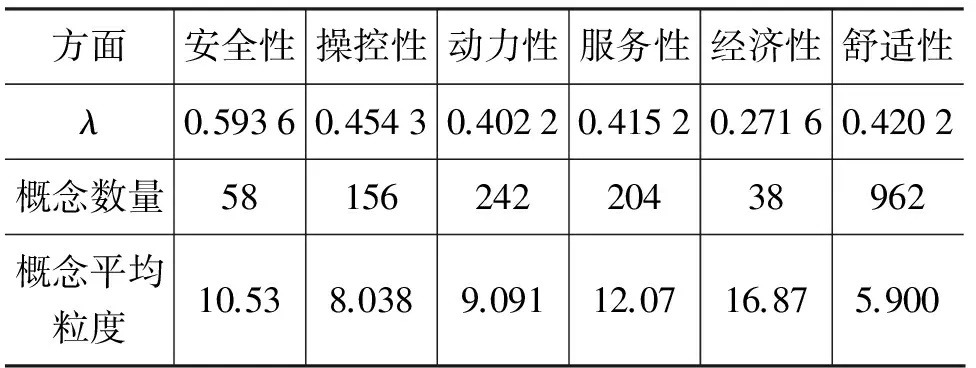
表5 汽车六个方面的内涵模糊概念发现结果
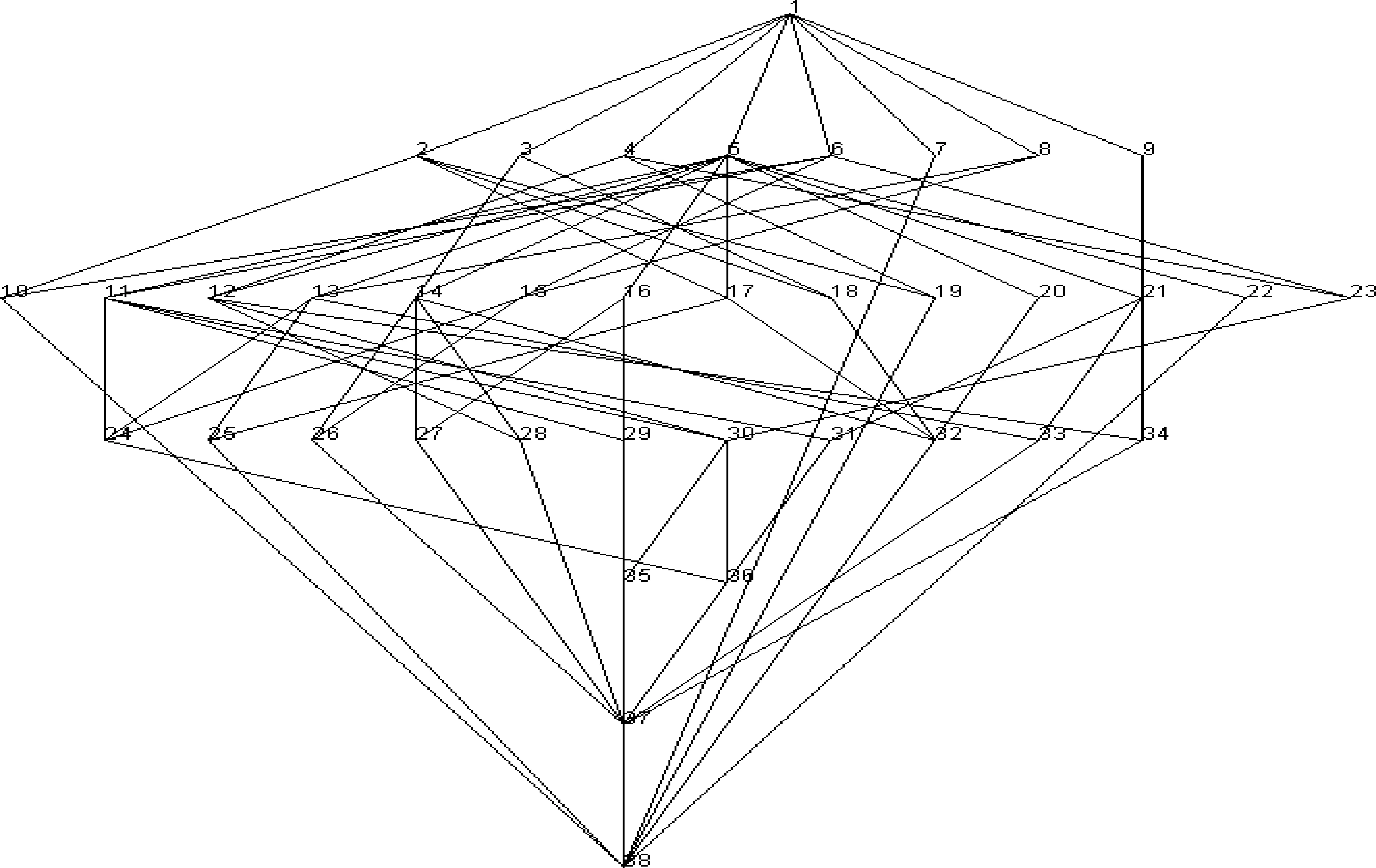
图8 汽车经济性方面评价的内涵模糊概念格(λ=0.271 6)

︙︙11({派喜,比亚迪F3,赛拉图,锐欧,海福星,长城C30,风云,猎豹,逍客,SX4,世嘉,福瑞迪,陆风X8,新阳光,天籁,凯美瑞,W5},{费用(0.3158),油耗(0.2753)})12({赛拉图,标致206,风云,新佳乐,轩逸,逍客,骑士,世嘉,天籁,睿翼,昊锐,比亚迪M6},{性价比(0.2817),油耗(02806)})︙︙

续表
结合图8和表6,对如何利用内涵模糊概念格和其中包含的概念进行如下说明。
(1) 由于内涵模糊概念中的外延和内涵是由伽罗瓦连接相互约束的,并且概念的内涵属性具有隶属度值,所以概念本身即表达了一些由数据支撑的陈述,即知识。比如,由概念Concept 23=({赛拉图,风云,逍客,世嘉,秀尔,天籁},{性价比(0.281 7),费用(0.315 8)})可知: 赛拉图、风云、逍客、世嘉、秀尔、天籁等是唯一一组性价比评价均超过0.281 7,且费用评价均超过0.315 8的车型。
(2) 当指定一组属性时,有可能从内涵模糊概念格中找到与指定属性完全一致的一类汽车集。例如,指定经济性方面的属性{性价比,费用,油耗},则从Concept 30可知,它对应着一组车型,即{赛拉图,风云,逍客,世嘉,天籁},它们同属一个评价类别的车,并且这些车在三个属性上的隶属度都大于或等于对应的隶属度(0.281 7,0.315 8,0.280 6)。
(3) 在内涵模糊概念格上的任何一条从上到下的链上,排在下面的概念所包含的车型一定比排在上面的概念所包含的车型评价要高。即有规则:
这个规则告诉用户,在搜索到相关汽车集的基础上需要搜索更高要求的汽车时,可以在内涵模糊概念格中向下搜索。例如,搜索到Concept30中的汽车后,若还想寻找更细粒度的汽车时,可以向下查找它的子概念,分别为Concept35和Concept36。并且可以看到,相比Concept30,在Concept35和Concept36中的属性都多了一个,而其余三个属性的隶属度值保持不变或有所增大。
(4) 概念的关联性也是一种知识,通过计算内涵模糊概念间的相似度可以找到评价相近的产品。以Concept30为例,它的超概念为Concept11、Concept12和Concept23,子概念为Concept35和Concept36。Concept30与这些概念的相似度分别为0.673 2、0.640 4、0.680 4、0.375 8和0.712 0。这样即可找到与Concept30中汽车评价相近的汽车。
(5) 由于格结构的缘故,基于内涵模糊概念格可提高查询的效率。很多基于属性的查询只需在内涵模糊概念格的某一条链上查询即可,而不需要遍历整个知识库。
基于内涵模糊概念格还可挖掘更多其他类型的评价知识。
6 结束语
本文针对包含丰富情感信息的产品评论数据,提出了一种基于内涵模糊概念格的汽车评价知识发现方法,通过将属性对评价对象作用形式化为一个模糊关系,在数据上加载了一种适用于评价知识发现的架构,即模糊形式背景。利用定义的内涵模糊概念及其偏序关系,设计了从模糊形式背景中抽取内涵模糊概念和其对应的格结构的算法。通过汽车评价领域的真实数据,给出了一个构建产品评价知识库的实例,并对如何利用构建的内涵模糊概念格进行知识抽取进行了说明。未来计划在构建的汽车评价知识库的基础上,从内涵模糊概念格的关联规则等出发去挖掘知识库的应用。
[1]EpplerMJ,MengisJ.Theconceptofinformationoverload:areviewofliteraturefromorganizationscience,accounting,marketing,MIS,andrelateddisciplines[J].TheInformationSociety, 2004, 20(5): 325-344.
[2]ErnestDavis.Internationalencyclopediaofthesocial&behavioralsciences[M]. 2nd,Amsterdam:Elsevier, 2015: 98-104.
[3]TanL,ZhuS,ManW.Aknowledgebaseconstructionmethodbasedoncognitivemodel[M].KnowledgeEngineeringandManagement.SpringerBerlinHeidelberg, 2011: 235-240.
[4]GanterB,WilleR.Formalconceptanalysis:mathematicalfoundations[M].Berlin,Springer-Verlag, 1999.
[5]PoelmansJ,KuznetsovSO,IgnatovDI,etal.Formalconceptanalysisinknowledgeprocessing:Asurveyonmodelsandtechniques[J].ExpertSystemswithApplications, 2013, 40(16): 6601-6623.
[6]Díaz-AgudoB,González-CaleroPA.FormalconceptanalysisasasupporttechniqueforCBR[J].Knowledge-basedSystems, 2001, 14(3): 163-171.
[7]MuangprathubJ,BoonjingV,PattaraintakornP.Anewcase-basedclassificationusingincrementalconceptlatticeknowledge[J].Data&KnowledgeEngineering, 2013, 83: 39-53.
[8]L.Zadeh.Fuzzysets[J].InformationandControl, 1965, 8(1): 338-353.
[9]AchicheS,BalazinskiM,BaronL,etal.Toolwearmonitoringusinggenetically-generatedfuzzyknowledgebases[J].EngineeringApplicationsofArtificialIntelligence, 2002, 15(3): 303-314.
[10]TadratJ,BoonjingV,PattaraintakornP.Buildingclassificationrulesforcase-basedclassifierusingfuzzysetsandformalconceptanalysis[C]//Proceedingsofthe5thInternationalConferenceonSoftComputingasTransdisciplinaryScienceandTechnology.ACM, 2008: 13-18.
[11]QuanTT,HuiSC,CaoTH.Afuzzyfca-basedapproachforcitation-baseddocumentretrieval[C]//ProceedingsofIEEEConferenceonCyberneticsandIntelligentSystems, 2004, 1: 578-583.
[12] 冯淑芳, 王素格. 面向观点挖掘的汽车本体知识库的构建[J]. 计算机应用与软件, 2011, 28(5): 45-47.
[13] 薛宾. 基于评价搭配的产品情感倾向聚类方法研究[D]. 太原: 山西大学, 2013.
[14]GodinR.IncrementalconceptformationalgorithmbasedonGalois(concept)lattices[J].ComputationalIntelligence, 1995, 11(2): 246 -267.
[15] 廖健, 王素格, 李德玉, 等. 基于观点袋模型的汽车评论情感极性分类[J]. 中文信息学报, 2015,29(3): 113-120.
KnowledgeDiscoveryfromCarCommentsBasedonIntensionFuzzyConceptLattice
LI Yang1, GUO Xiaomin1, WANG Suge1,2, LIANG Jiye1,2
(1. School of Computer & Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China; 2. MOE Key Laboratory of Computational Intelligence and Chinese Information Processing, Shanxi University, Taiyuan, Shanxi 030006, China)
To utilize car comments efficiently, this paper extracts collocations from reviews texts, and proposes the 5-tupel based evaluation measurement of objects. With such built fuzzy formal context of car comments, we define intension fuzzy concept and intension fuzzy concept lattice. We design the algorithms for constructing a fuzzy formal context and an intension fuzzy concept lattice, and illustrate how to conduct knowledge discovery based on an intension fuzzy concept lattice with a real example.
car evaluation; knowledge discovery; fuzzy formal concept analysis; intension fuzzy concept; intension fuzzy concept lattice

李旸(1988—),博士研究生,主要研究领域为文本情感分析。

郭晓敏(1990—),硕士,主要研究领域为文本情感分析。

王素格(1964—),博士,教授,主要研究领域为自然语言处理与文本情感分析。
1003-0077(2017)03-0069-08
2015-08-15定稿日期: 2015-12-15
国家自然科学基金(61573231,61632011,61432011,61672331);山西省科技基础条件平台计划(2015091001-0102)
TP391
: A
