垃圾债券新闻自动过滤
2017-07-16陈钦明刘丁屹吕威
陈钦明+刘丁屹+吕威
【摘要】 本文首先介绍了文本分类的应用背景,从传统的人工分类到后面的基于机器学习的文本分类,而垃圾债券新闻自动过滤实际上可以看作文本分类的一个特例二分类问题,因此便可以基于文本分类的相关知识与理论对垃圾债券新闻进行自动过滤。接下来本文从数据预处理,文本分类算法设计与实现及分类算法评估等方面详细地描述了垃圾债券新闻自动过滤的处理过程。
【关键字】 垃圾债券 文本二分类 数据预处理 SVM 分类指标 交叉验证
一、应用背景
随着网络技术的迅猛发展以及电脑的普遍使用,电子化的文档得到了“爆炸性”的增长,各种各样的文档层出不穷,充斥着网页各个角落。一方面提高了人们获取信息的便利性与快捷,丰富了人们的阅读世界,另一方面也存在各种各样的垃圾文档包括垃圾新闻、垃圾邮件[1]等等,鱼目混珠,良莠不齐。给人们的阅读带来了迷惑与不良的效果。本文主要基于它说平台的债券新闻模块尝试了垃圾新闻的自动分类以达到自动过滤垃圾新闻的效果。
文本分类(Text categorization)[2]是指在给定分类体系下,根据文本内容自动确定文本类别的过程.20世纪90年代以前,占主导地位的文本分类方法一直是基于知识工程的分类方法,即由专业人员手工进行分类.人工分类非常费时,效率非常低.90年代以来,众多的统计方法和机器学习方法应用于自动文本分类,文本分类技术的研究引起了研究人员的极大兴趣并对其进行研究,在信息检索、Web文档自动分类、数字图书馆等多个领域得到了初步的应用。而本文所提到的垃圾债券新闻自动过滤实际上可以看做文本分类的一个特例,文本二分类的问题,即垃圾新闻与非垃圾新闻的分类问题,从而为垃圾债券新闻的自动过滤奠定了理论及实践基础。下面将从数据预处理,分类算法设计与实现及算法评估几方面具体说说垃圾债券主体新闻自动过滤的处理过程。
二、数据预处理
数据预处理属于文本分类的一个非常重要阶段,它主要包括数据的过滤,转化,清洗等过程,数据预处理的好坏一定程度上影响到后续算法分类效果的好坏。本文采用的数据来源为通过武大爬虫,万德数据库以及鹏元爬虫获取到的新闻,本文抽取8306条新闻数据作为样本集并对数据做了处理:记录?txt文档、非UTF-8编码?UTF-8编码;去掉html标记、换行符、多余空格,然后针对该样本集进行垃圾新闻与非垃圾新闻的人工标记,最终非垃圾新闻数量为5807条,垃圾新闻数量为2499条。垃圾新闻样例如下表1所示: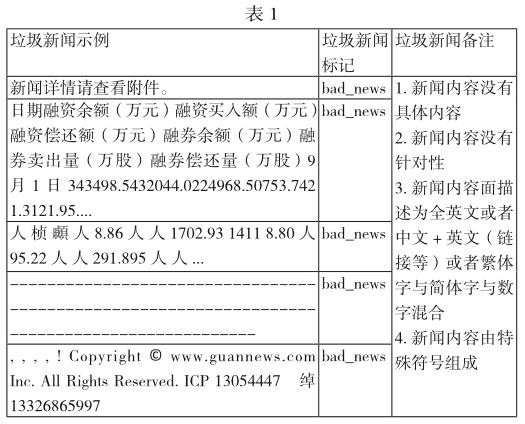
三、算法实现
常见的机器学习分类算法包括决策树,神经网络,贝叶斯,KNN,SVM等。本文主要采用贝叶斯,KNN以及SVM分类算法对垃圾债券新闻自动过滤进行算法实现。各种算法的主要思想如下文所示:
(1) 贝叶斯——对于给定的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就把此待分类项归属于哪个类别.贝叶斯公式如下1-1所示: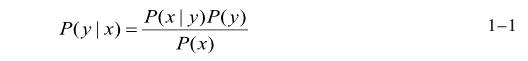
(2)KNN——KNN算法又称为k最近邻分类(k-nearest neighbor classification)[3]算法。该算法从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
(3)SVM——SVM为support vector machine(支持向量机)[4]的缩写,它的主要思想是建立一个超平面作为决策平面,使得正例与反例之间的间隔最大化,这两类的样本中离决策平面最近的训练样本就叫做支持向量。
本文使用经数据预处理后的8306条新闻作为最终的样本集,并对样本集进行中文分词[5]处理,构造样本集文本对象,构建样本集TF_IDF词向量空间,然后使用相关分类算法进行预测分类结果。具体的算法流程图如下图1所示:
四、算法评价
常见的评价一个分类系统的好坏的分类指标大体可以分为两大类。线上的指标还有离线的指标。线上的指标包括用户满意度等,需要通过调查问卷等方式进行采集。离线的指标包括平均绝对误差(mean absolute error,MAE),ROC(Receiver Operating Characteristic)曲线,精度,召回率,F1-score,覆盖率等。本文使用精度、召回率,错分率以及 F1-score,混淆矩阵作为主要的评价指标。下面简单介绍一下精度、召回率,错分率以及F1-score,混淆矩阵:
1、精度(Precision,也称为准确率):是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
精度(Precision)= 系统检索到的相关文件 / 系统所有检索到的文件总数
2、召回率(Recall Rate,也叫查全率):是检索出的相关文档数和文档库中所有相关文档数的比率,衡量的是检索系统的查全率。
3、錯分率为另外一个角度对召回率的刻画,满足错分率+召回率=1
4、F1-score综合考虑了精度以及召回率,是两者的协调评价指标。
5、混淆矩阵(confusion matrix),是由false positives,false negatives,true positives和true negatives组成的两行两列的表格。它允许我们做出更多的分析,而不仅仅是局限在正确率。
本文按照10%测试集、90%训练集的数据集随机切分方式对分类结果进行了交叉验证(cross_validation),最终的分类结果如下表2所示:
五、结论
由上表可知:SVM算法在垃圾债券新闻的自动过滤上能取得最好的过滤效果,贝叶斯算法也能取得相当不错的效果,这一定程度上说明了垃圾债券新闻与非垃圾债券新闻两者的区分度很高,两种算法在垃圾债券新闻自动过滤上基本达到了可以相媲美的高度。而KNN算法则在区分度上不高。
参 考 文 献
[1]郭泓.电子邮件过滤技术浅析.信息网络安全,2002(10):4244.
[2]李荣陆.文本分类及其相关技术研究[D].上海:复旦大学计算机与信息技术系,2005,4-5
[3]亚南.KNN文本分类中基于遗传算法的特征提取技术研究[D].中国石油大学,2011.
[4]毛雪岷,丁友明.基于语义引导与支持向量机的中文文本分类[J].情报杂志,2007,26(1 1):56-58
[5]李淑英.中文分词技术[J].科技信息,2007, 36:65-66
