基于HOG特征和MLP分类器的印刷体维吾尔文识别方法
2017-06-27于丽亚森艾则孜
于丽, 亚森·艾则孜
(新疆警察学院 信息安全工程系, 乌鲁木齐 830011)
基于HOG特征和MLP分类器的印刷体维吾尔文识别方法
于丽, 亚森·艾则孜*
(新疆警察学院 信息安全工程系, 乌鲁木齐 830011)
针对印刷体维吾尔文的有效识别问题,提出了一种基于梯度方向直方图(HOG)特征和多层感知器(MLP)神经网络的印刷体维吾尔文识别方案。对维吾尔文图像进行预处理,获得去除噪声后的二值化图像。利用水平投影积分对文本执行行切分,利用垂直投影积分方法执行单词切分和字母切分,获得独立的字母。基于HOG方法提取字母的特征。通过训练好的MLP神经网络分类器,根据提取的HOG特征对字母进行识别。实验结果表明,提出的方法能够精确地从图像中识别出维吾尔文字母。
印刷体维吾尔文; 识别; 字母切分; 梯度方向直方图; 多层感知器
0 引言
印刷体文本的光学字符识别(Optical Character Recongnition, ORC)是图像处理、模式识别和机器学习的交叉研究领域,其是用来将印刷体的文档转换为可编辑的电子文档格式[1]。由于计算机技术的不断进步,印刷体ORC技术得到快速发展,大大提高了文字录入的效率。
随着国家对新疆地区的大力投入,以维吾尔文出版的文档越来越多,如一些古籍文献、档案等,这些都需要进行电子化[2]。为此,需要一种能够自动识别并录入维吾尔文的智能系统。目前,对于英文和中文等大语种的识别技术已经得到大量研究,并趋于成熟[3]。然而,由于维吾尔文是一种粘着性文字,与传统字母组合文字具有明显的区别,致使对维吾尔文的识别技术还不成熟[4]。
目前,学者提出了一些印刷体维吾尔文识别方法。例如,文献[5]提出了一种基于模板匹配的维吾尔文识别方法,通过提取字母的外形和结构特征,然后与字母图像库进行匹配来识别字母。然而其所提取的特征不能很好的表示字母,且匹配过程很耗时间。文献[6]采用了字母的分布密度和局部方向特征,利用隐马尔科夫模型构建维吾尔文字母分类器。但是,其没有说明如何从文本图像中获得单个字母。
为此,提出一种基于梯度方向直方图(Histogram of Oriented Gradient, HOG)特征和多层感知器(Multi Layered Perceptron,MLP)神经网络的印刷体维吾尔文识别方案。其中,利用了投影积分方法来对图像中的字母进行切分,利用HOG方法提取字母特征,通过由字母库训练的MLP分类器来进行字母识别。实验结果证明了该方法的有效性和可行性。
1 提出的维吾尔文识别方案框架
维吾尔文是一种粘着型文字,不同于由相互独立字母组成的英文等文字,维吾尔文单词中的字母是相互连接的[7]。维吾尔文一共有32个字母和20个附加笔画,在一个维吾尔文单词中,附加笔画位于字母主体的上方、下方或内部,且不与主体连接[8],如图1所示。

图1 由字母和附件笔画组成的维吾尔文单词
另外,根据维吾尔文字母在单词中的位置,每个字母可最多有4种不同的书写形式,总共有126种形式。
由于维吾尔文的独特性,所以维吾尔文识别不能采用传统的英文识别技术。为此,提出了一种基于字母切分、HOG特征和MLP分类器的印刷体维吾尔文识别方法,其基本流程,如图2所示。
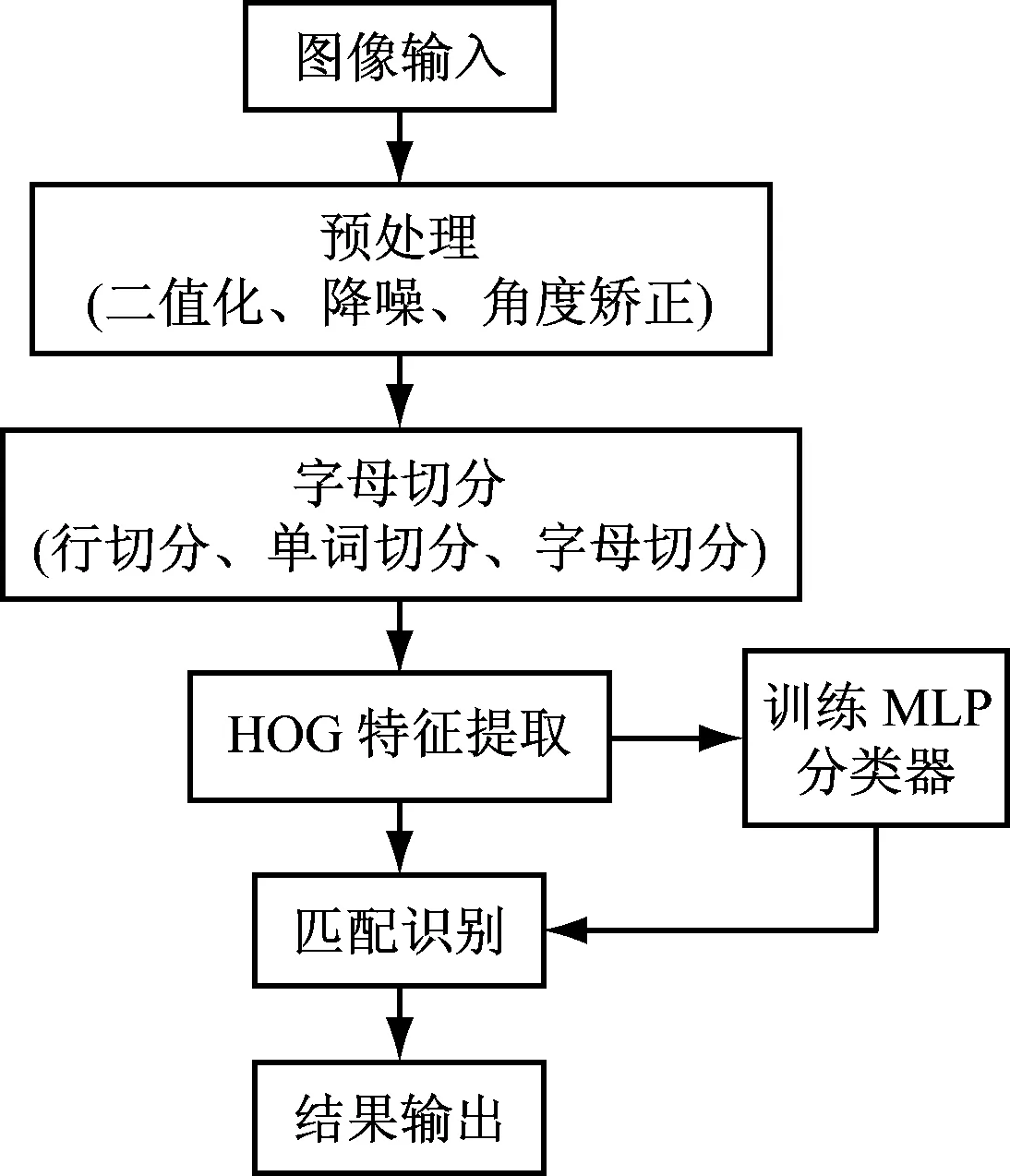
图2 提出方法的流程图
主要分为4个部分,即预处理、基于积分投影法的字母切分、基于HOG的特征提取和基于MLP分类器的字母识别。
文本资料中的印刷体维吾尔文是通过图像扫描仪等设备将其转换成图像,然后上传到计算机上的识别软件中,作为数据输入。由于图像捕获设备和环境的不一致性,需要对文字图像进行预处理。
预处理过程包括图像二值化,降噪、角度矫正和归一化等操作。在二值化过程中,首先将文本图像中的像素转化为0-255级的灰度值,然后以192作为判断阈值,将图像转换成黑白的二值图像[9]。在降噪过程中,采用了中值滤波法来去除图像中的噪声点。在角度矫正过程中,根据维吾尔文书写的基线来调整图像角度,避免文字倾斜[10]。归一化操作中,利用高阶插值算法对图像进行缩放,以此实现对文字大小的归一化。
2 基于投影积分的字母切分
由于维吾尔文字母之间相互粘连,相似字母较多,字形的宽高不统一,使得单词中字母之间没有明显的界限。为此,在文本识别之前,需要对单词中的字母进行切分。本文利用像素积分投影方法[11]来进行字母切分,包含文本行切分、单词切分和字母切分3个步骤。
经过预处理过程后,图像变成无噪声的二值图像,即白色背景点的像素值为0,黑色文字点的像素值为1。即位于第i行、第j列像素g(i,j)的表达式为式(1)。
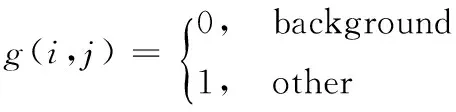
(1)
步骤1:行切分。根据行与行之间的空白间隙,利用水平投影积分法来确定文本行的上下边界,完成行切分。各行的积分投影表达为式(2)。
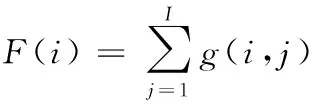
(2)
式中,I为一行中像素点的个数。
对于文本下届的确定,从上往下对图像像素进行逐行扫描,通过阈值判断来确定文本下届。若有连续n行满足下式,则取第i行作为文本的下届。

(3)
对于文本上届的确定,从下往上对图像像素进行逐行扫描,若有连续n行满足下式,则取第i行作为文本的下届。
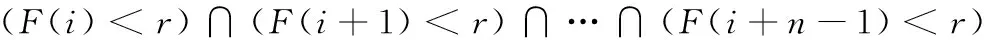
(4)
式中,阈值p和阈值r由实验效果来确定,本文中都设定为2。
一张文本图像的水平投影和行切分结果,如图3所示。

图3 基于水平投影积分法的文本图像行切分
步骤2:单词切分。在完成行切分后,然后进行单词切分,即将每个单词分离开。由于印刷体维吾尔文单词之间有明显的间隙,且字母之间的间隙比单词间的间隙小很多,所以可以利用垂直投影积分法进行单词切分。垂直投影切分的过程与水平投影切分类似。一张文本图像的垂直投影和单词切分结果,图4所示。


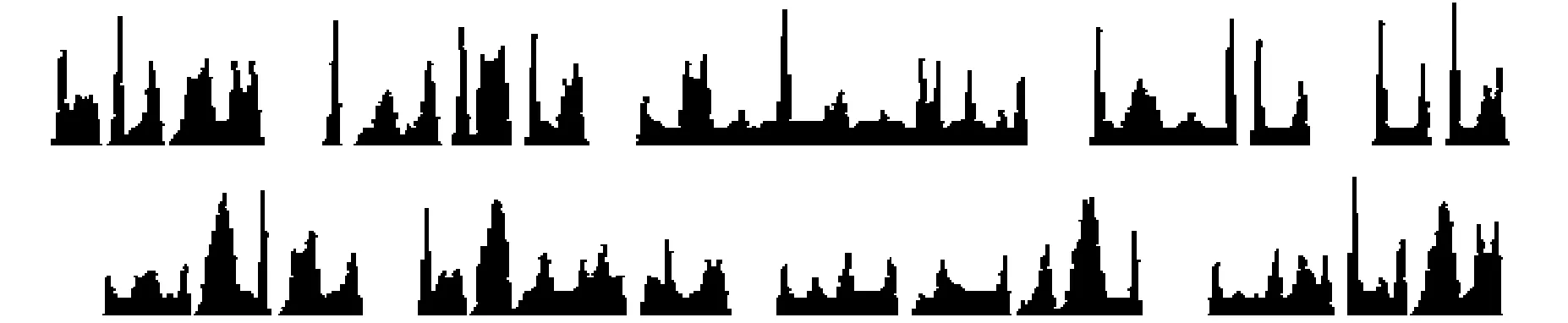
图4 基于垂直投影积分法的文本图像单词切分
步骤3:字母切分。基于行切分和单词切分后所获得的独立单词,执行字母切分,获得独立的字母。由于单词中,有些字母是相互连接的,但这些连接部分都在基线上。为此,可根据垂直投影和基线位置来得到切点。
首先,通过垂直投影积分法对单词中存在间隙的字母进行切分。然后,对于相互连接的字母,采用基线置白法,即将单词基线设置成白色,再通过垂直投影来切分连体字母,如图5所示。
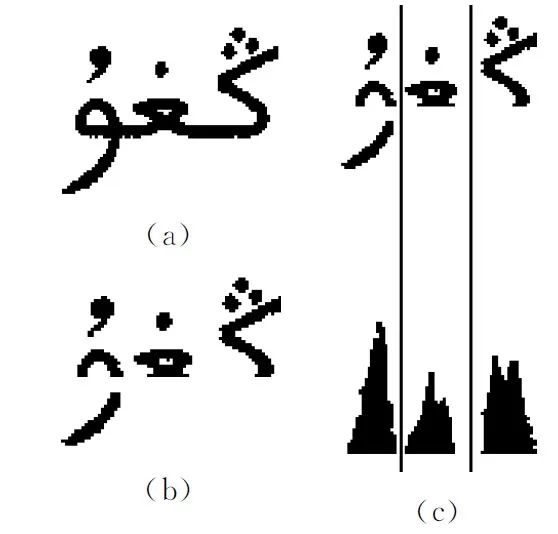
图5 单词中连体字母的切分示意图
图5显示了一个连体单词切分过程,其中图5(a)为单词,图5(b)为去掉基线的单词,图5(c)为垂直投影和字母垂直切分的结果。
在垂直方向分离出每个字母后,再通过水平投影法来构建字母的上下边界框,最终获得单独的字母,如图6所示。

图6 单词中字母切分的最终结果
3 基于HOG的特征提取
特征提取用来将输入字母图像变换为特征集合,是维吾尔文识别系统中的重要部分。采用梯度方向直方图(HOG)[12]来检测和提取维吾尔文字母的特征。HOG是通过计算图像局部梯度信息来检测边缘轮廓。其将切分后的字母分割成小的连通单元,对单元中的每个像素生成一个梯度直方图,然后将这些直方图进行串联形成矩形块,从而来获得字母形状的HOG特征。
首先,计算字母图像的像素梯度。通过Sobel滤波器计算梯度最大强度变化的方向和量级,从而获得梯度的水平(H)和垂直(HT)分量。然后将每个像素与H和HT分量进行卷积,获得水平和垂直方向上的梯度值Gx和Gy,表达式式(5)
(5)
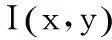
(6)
梯度的方向表示为式(7)。
(7)
然后,将字母图像分割成8*8的单元,采用具有9个bin的直方图来统计每个单元中的像素梯度,其中直方图以每个像素的梯度值作为权重进行投票。
最后,将这些单元合并出一个矩形块,并对所有重叠块内的像素梯度进行归一化。接着,将所有块的直方图向量进行聚合,最终形成一个大的HOG特征向量。
4 基于MLP分类器的字母识别
提出的方案基于一种多层前馈人工神经网络(Multi-Layer Forward Artificial Neural Network, MFANN)[13]来构建分类器。在将所提取的每个字母转换为矩形HOG后,在该HOG向量中将存在576个值,将作为分类器的输入特征。MLP是一种常见的前馈网络,其典型架构,如图7所示。
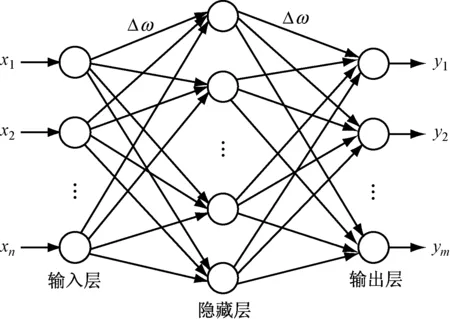
图7 MLP神经网络的结构
由输入层、隐藏层和输出层构成。其中,x为输入向量,y为输入向量,Δω为层与层之间的连接权重。
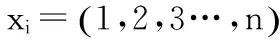
(8)
式中,f可为一个简单的阈值函数、S形函数或双曲正切函数。
反向传播算法是一种梯度下降算法,在MLP训练过程中用来调整神经元i和j之间的连接权重Δωji,表示如式(9)。
(9)
式中,η为学习规则参数,特征δ取决于神经元j类型。例如,对于一个隐藏神经元或一个输入神经元,其对应的δj为式(10-11)。
(10)
(11)
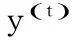
(12)
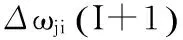
5 仿真及分析
为了评估提出的印刷体维吾尔文识别方案的性能,使用Matlab8.0工具构建实验环境。实验中使用了拍摄自维吾尔文杂志的4张图片,共包含528个单词,约1762个字母,作为测试样本,其中字体为ALKATIP Basma字体。另外,使用带附件笔画的的标准维吾尔文印刷体字母库作为训练集,通过提取的HOG特征来训练MLP神经网络分类器。
将本文提出的方案与文献[5]提出的结构特征+模板匹配的方案进行比较。另外,为了验证所采用MLP分类器的性能,将其与支持向量机(Support Vector Machine, SVM)分类器进行比较。统计字母识别的错误接受率(False Acceptance Rate, FAR)、正确接受率(True Acceptance Rate, TAR)和错误拒绝率(False Rejection Rate, FRR),并以此作为性能指标。
3种方法的比较结果,如表1所示。
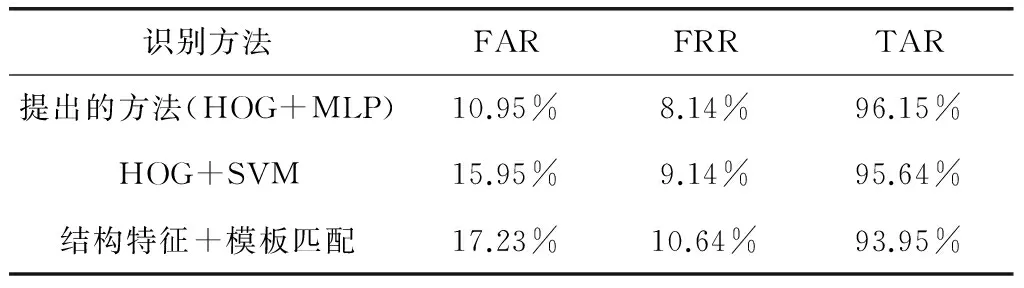
表1 印刷体维吾尔文的识别结果
可以看出,提出的方案具有较高的性能,且所采用的MLP分类器比SVM的分类性能更好。这是因为,本文对维吾尔文字母进行了精确切分,然后通过利用HOG来表示字母特征,为MLP神经网络分类器提供了高效的特征,所以具有较高的正确识别率。
6 总结
提出了一种印刷体维吾尔文识别系统,首先利用投影积分法从文本图像中切分出每个字母,然后提取每个字母的HOG特征,最后通过MLP分类器来识别字母。在一些维吾尔文杂志的图像上进行实验,结果表明提出的方案具有96%的正确识别率,具有较高的实用价值。
[1] 宋云涛, 刘烨, 王源彬,等. 一种基于SWT面向RGB-D图像的高效字符检测算法[J]. 微型电脑应用, 2015, 31(9): 33-36.
[2] 刘卫, 李和成. 基于多模板归一化的维吾尔文字母识别算法[J]. 中文信息学报, 2016, 30(1):156-161.
[3] 于伯峰. 印刷体中文文档中表格和汉字的识别研究[D]. 哈尔滨:哈尔滨工程大学, 2011: 10-11.
[4] Ubul K, Adler A, Abliz G, et al. Off-line Uyghur signature recognition based on modified grid information features[C]// International Conference on Information Science, Signal Processing and Their Applications. IEEE, 2012:1056-1061.
[5] 陈卿, 袁保社, 李晓,等. 基于模板匹配的印刷维吾尔文字符识别研究[J]. 计算机技术与发展, 2012, 22(4):119-122.
[6] 努尔艾力·喀迪尔, 彭良瑞, 哈力木拉提. 一种基于HMM和统计语言模型的维吾尔文及阿拉伯文识别方法[J]. 计算机应用与软件, 2015, 32(1):171-174.
[7] 姜志威, 丁晓青, 彭良瑞. 针对无切分维吾尔文文本行识别的字符模型优化[J]. 清华大学学报(自然科学版), 2015, 55(8):873-877.
[8] 苏佩佩, 哈力木拉提·买买提, 艾尔肯·赛甫丁,等. 一种基于连体段的维吾尔文单词特征提取方法[J]. 新疆大学学报(自然科学版), 2015, 32(4): 462-468.
[9] Simayi W, Ibrayim M, Tursun D, et al. Research on on-line Uyghur character recognition technology based on center distance feature[C]// IEEE International Symposium on Signal Processing and Information Technology. IEEE, 2013:293-298.
[10] 万金娥. 印刷体维吾尔文字识别系统关键技术研究与实现[D]. 乌鲁木齐:新疆大学, 2013: 20-21.
[11] 李晓, 袁保社, 陈卿,等. 基于像素积分投影的印刷体维文字母切分方法[J]. 计算机技术与发展, 2012, 22(4):41-44.
[12] 刘军, 白雪. 基于梯度方向直方图与高斯金字塔的车牌模糊汉字识别方法[J]. 计算机应用, 2016, 36(2):586-590.
[13] 孔令美, 汤庸. 基于小波变换和小波神经网络的3D遮挡人脸识别方法[J]. 湘潭大学学报(自然科学版), 2015, 37(4): 82-86.
[14] 毛勇华, 桂小林, 李前,等. 深度学习应用技术研究[J]. 计算机应用研究, 2016, 33(11): 3201-3205.
A Printed Uyghur Recognition Method Based on HOG Feature and MLP Classifier
Yu Li, Yasen·Aizezi*
(Department of Information Security Engineering, Xinjiang Police College, Urumqi 830011, China)
For the effective recognition issues of printed Uyghur, a printed Uighur recognition scheme based on histogram of gradient oriented (HOG) and multi-layer perceptron (MLP) neural network is proposed. Firstly, the Uighur image is preprocessed to remove noise and obtain a binarized image. Then, the text is linearly segmented by the horizontal projection integral, and the vertical projection integral method is used for word segmentation and letter segmentation, so as to obtain some independent letters. After that, the character of letter is extracted based on the HOG method. Finally, a trained MLP neural network classifier is used to identify the letter according to the extracted HOG features. Experimental results show that the proposed method can accurately identify Uighur alphabets from image.
Printed Uyghur; Recognition; Letter segmentation; Histogram of gradient-oriented; Multi-layer perceptron
新疆维吾尔自治区自然科学基金科研项目(2015211A016)
于丽(1981-),女,河北巨鹿人,讲师,硕士,研究方向:软件工程、中文信息处理等。 亚森·艾则孜(1975-),男,新疆库车人,通讯作者,教授,硕士,国家电子数据司法鉴定员,研究领域:信息安全、自然语言处理等。
1007-757X(2017)06-0030-04
TP391
A
2017.02.14)
