基于四部图的协同过滤推荐算法比较研究*
2017-06-15牟斌皓张智恒
牟斌皓,张智恒,张 林,闵 帆+
1.西南石油大学 计算机科学学院,成都 610500
2.西南石油大学 理学院,成都 610500
基于四部图的协同过滤推荐算法比较研究*
牟斌皓1,张智恒2,张 林1,闵 帆1+
1.西南石油大学 计算机科学学院,成都 610500
2.西南石油大学 理学院,成都 610500
MOU Binhao,ZHANG Zhiheng,ZHANG Lin,et al.Comparison study of collaborative filtering algorithms based on quadripartite graph.Journal of Frontiers of Computer Science and Technology,2017,11(6):875-886.
推荐系统通常利用商品属性、用户信息以及用户对商品的已有评分来获取用户或者商品之间的相似度,进而预测未知评分。构造了关于这些信息的四部图,然后根据图中不同部分的组合获得了10类推荐算法,并比较了它们的时间复杂度。前两类算法基于用户与商品之间的关系,为经典的协同过滤算法。中间4类算法以用户或商品为中心,利用相应的标签信息进行相似度的计算并预测评分。后4类算法为中间4类算法的部分拓展,进一步考虑了评分信息。以MAE(mean absolute error)和RMSE(root-mean-square error)为评价指标,在两个MovieLens数据集上的测试结果表明,商品之间的相似度比用户之间的相似度更可靠,商品标签也比用户标签更有用,而且某些信息的简单线性组合可以提高推荐质量。
推荐系统;协同过滤;四部图;协同过滤标签
1 引言
协同过滤(collaborative filtering,CF)是推荐系统[1-4]中应用最早并且最成功的算法之一。协同过滤算法根据一系列的信息来预测用户对商品的喜好。一般来说,这些信息来源于用户对商品的评分、用户的档案和商品属性等[5]。协同过滤算法可以分为基于用户的算法[6-9]和基于商品的算法[10-11]。
考虑测试用户对测试商品的未知评分,基于用户的协同过滤算法首先需要计算测试用户与其他用户之间的相似度,而基于商品的协同过滤算法则需要计算测试商品与其他商品之间的相似度。获得相似度后,基于用户的算法会根据用户相似度得知与测试用户相似的其他用户,然后根据他们对测试商品的已知评分来预测未知评分。同样的,对于基于商品的算法,则根据测试用户对相似商品的已知评分来预测未知评分。
尽管协同过滤算法已经获得了很大的成功,但是它们的性能仍然受限于数据的稀疏性。这样一来,研究者们向经典的协同过滤框架中添加了一些额外的信息,比如用户标签信息和商品标签信息等。协同过滤标签系统允许用户自由地给商品打标签,在很大程度上为解决数据稀疏性的问题提供了可能性[12]。协同过滤标签对于用户并没有特别的技术性要求,这个特点使得它克服了用户词汇量有限的问题,扩展了商品间关系的语义,甚至衍生出多种分类[13]。
近年来,许多基于资源扩散的推荐算法研究得到了广泛的开展,这些算法在难以管理的稀疏性系统上实现了相对准确的推荐。在基于资源扩散的推荐算法中,用户或者商品所拥有的资源可以扩散到与其相连接的其他用户或者商品,资源扩散过程结束后便可以得到用户或者商品之间的相似度,进而根据相似度来预测未知评分。
本文将评分和标签等不同类型的信息进行组合,并构造了一个四部图,根据四部图中不同信息的组合获取了10种基于资源扩散的协同过滤推荐算法,并比较了不同算法的时间复杂度,进而使用MAE(mean absolute error)和RMSE(root-mean-square error)评价指标来评价不同算法的性能。
在MovieLens数据集上的实验结果表明:(1)商品之间的相似度比用户之间的相似度更可靠,而商品标签也比用户标签更有用。(2)某些信息的简单线性组合可以提高预测评分的准确度。
2 推荐系统四部图
定义1(推荐系统四部图)推荐系统四部图G是一个五元组,其具体形式为:

其中,U={u1,u2,…,un}是全体用户构成的集合;I= {I1,I2,…,Im}是商品的集合;T={T1,T2,…,Tk}是商品标签的集合;T′={T1′,T2′,…,Tr′}是用户标签的集合;E是四部图中连接用户、商品和标签的所有边的集合。
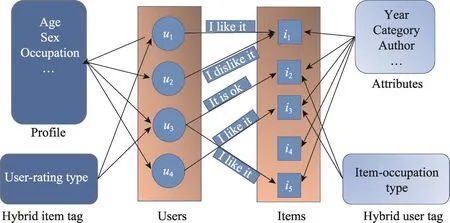
Fig.1 Quadripartite graph of recommender system图1 推荐系统四部图
一个四部图中包含了关于用户描述、商品内容、商品属性和用户评分等丰富的信息。同时,四部图中还包含了用户、商品以及各种标签之间的关系,每一组关系都可以用两个邻接矩阵来描述。一个推荐系统四部图如图1所示。
3 协同过滤算法
下面分别介绍基于用户和商品的协同过滤算法。针对N个用户和M个商品,用户对商品的评分信息可以用一个N×M的评分矩阵X来描述。X中的每个元素xn,m表示用户n对商品m的评分,如果xn,m=0表示用户n对商品m没有评分。
评分矩阵X的行向量表示形式[14]为:
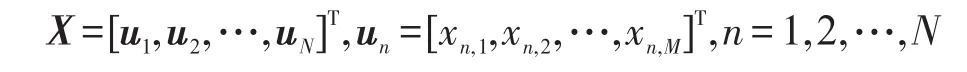
评分矩阵X也可以用列向量的形式来描述:
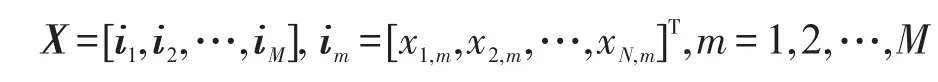
其中,列向量im表示所有N个用户对特定商品的评分。
3.1 基于用户的协同过滤算法
基于用户的协同过滤算法通过来源于相似用户的信息来预测用户对测试商品的兴趣。
如图2所示,预测评分可以通过相似用户的已知评分来获得,并且如果相似用户给出的评分越多,则它对预测商品评分的贡献就越大。相似用户可以通过施用阈值或者选择top-N的方法来确认。
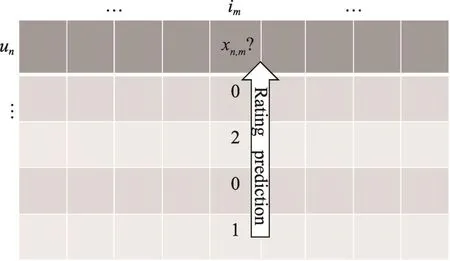
Fig.2 User-based rating prediction图2 基于用户的评分预测
定义2(top-N相似用户集合)用户k的top-N相似用户集合[14]为:
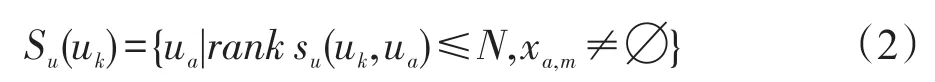
其中,|Su(uk)|=N,su(uk,ua)表示用户k和用户a之间的相似度。
本文采用基于资源扩散的相似度指标度量用户间的相似度。假设要计算用户u和用户v之间的相似度,首先假定用户v有一个单位的资源。
定义3(商品从用户获得的资源)在四部图中,假设存在用户v和商品i,则用户v分配给商品i的资源为:

其中,k(v)表示四部图中用户v的度,如果用户与商品i在图中有连线,那么avi=1,否则avi=0。
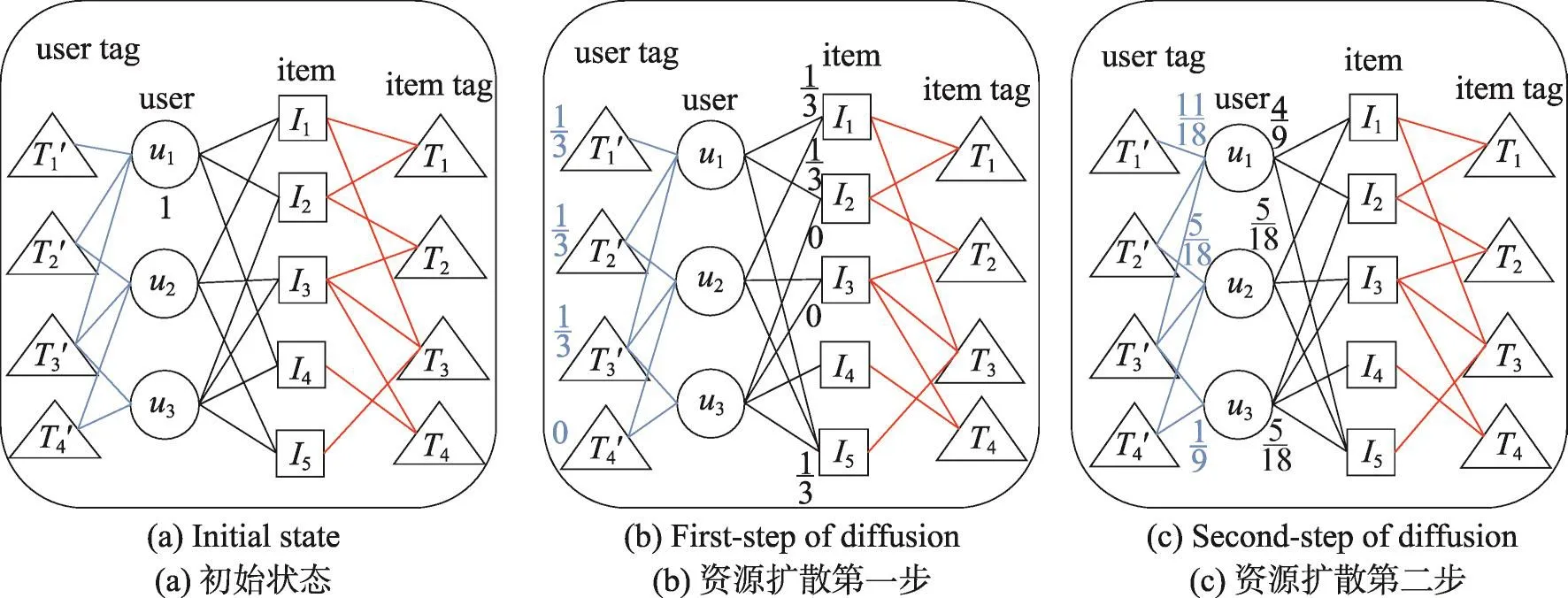
Fig.3 User-based diffusion process图3 基于用户的资源扩散过程
定义4(基于资源扩散的用户相似度)假设存在用户u和用户v,则用户间的基于资源扩散的相似度[15]为:

其中,k(i)是图中商品i的度;k(v)表示用户v的度;I是商品的全集。如果用户u对商品i有评分,aui=1,否则aui=0。同理可以得到avi的取值。实际上,suv的本质是用户v通过图传给用户u的资源数量。
定义了基于资源扩散的相似度后,便可以根据图中各个部分的连接情况来计算不同用户之间的相似度。在一个四部图中,基于用户的资源扩散过程一共有3个状态:第一个状态如图3(a)所示,是资源扩散的初始状态,在这个状态中假设用户u1被分配了一个单位的初始资源。第二个状态如图3(b)所示,这个状态下用户的初始资源将扩散到与其连接的所有商品和标签。最后一个状态下,资源将从商品和标签返回与其连接的所有用户,其过程如图3(c)所示。需要说明的是,为了保持图的易读性,本例假设只有用户u1拥有一个单位的资源,在真实的数据集中,每一个用户都有可能拥有一个单位的初始资源数。
定义5(基于用户的预测评分)在得到用户之间的相似度后,测试用户u对测试商品i的预测评分为:

3.2 基于商品的协同过滤算法
基于商品的协同过滤算法遵循同样的思想,只是它计算商品而不是用户之间的相似度。如图4所示,测试用户针对测试商品的未知评分可以通过测试用户对相似商品的已知评分来获得。
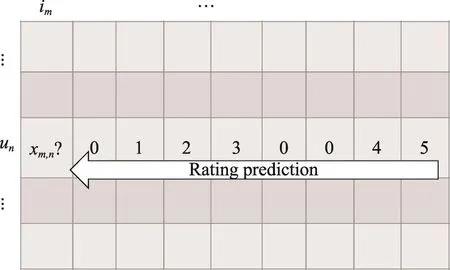
Fig.4 Item-based rating prediction图4 基于商品的评分预测

其中,k(j)表示四部图中商品j的度;如果用户u与商品j有连线,那么aju=1,否则aju=0。
定义6(用户从商品获得的资源)用户u从商品j获得的资源为:
定义7(基于资源扩散的商品相似度)对于图中的两个商品i和商品j,它们之间的相似度为:
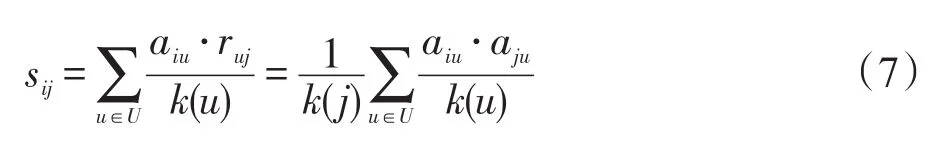
其中,k(u)是用户u的度;k(j)为商品j的度;U为用户的全集。
基于商品的协同过滤的资源扩散过程也分为3个状态。初始状态下,假设只有商品i1拥有一个单位的资源,如图5(a)所示。接着资源将从商品扩散到与其连接的用户和标签,如图5(b)所示。最后资源将从用户和标签返回到与其连接的商品,如图5(c)所示。
定义8(基于商品的预测评分)基于商品的协同过滤算法获得商品相似度后,测试用户u对测试商品i的预测评分为:

3.3 整合相似度
Tso[16]和Zhang[17]等人通过整合不同的相似度明显提高了推荐的准确性。受其启发,本文采用简单的线性整合方法来整合用户或者商品相似度。
定义9(整合相似度)假设有两个相似度sij和sij′,则整合的相似度为:

其中,λ为取值从0到1之间的可变参数。
4 基于四部图的协同过滤算法
下面详细说明从四部图中提取出来的10种协同过滤算法的具体运行步骤,这些算法来源于图中不同信息的部分组合。
4.1 基于用户-商品关系的算法
基于用户和商品关系的算法是经典的协同过滤算法,被分为基于用户和基于商品的算法,这两个算法都仅仅考虑了用户对商品的评分信息而忽略了标签信息。因为这两个算法并没有考虑标签信息,所以此时的四部图模型实际上退化为只包含用户-商品关系的二部图。
基于用户的经典协同过滤算法首先根据用户评分信息计算用户平均评分,然后使用式(4)计算用户相似度,最后使用式(5)计算预测评分。对于基于商品的情形,首先根据评分表计算商品的平均评分,然后分别使用式(7)和式(8)计算商品之间的相似度和预测评分。
4.2 基于商品标签-用户-商品关系的算法
基于商品标签-用户-商品关系的算法同时考虑了用户和商品之间以及用户与整合商品标签之间的关系,这两个关系构成了一个三部图。本算法的一个例子如下:
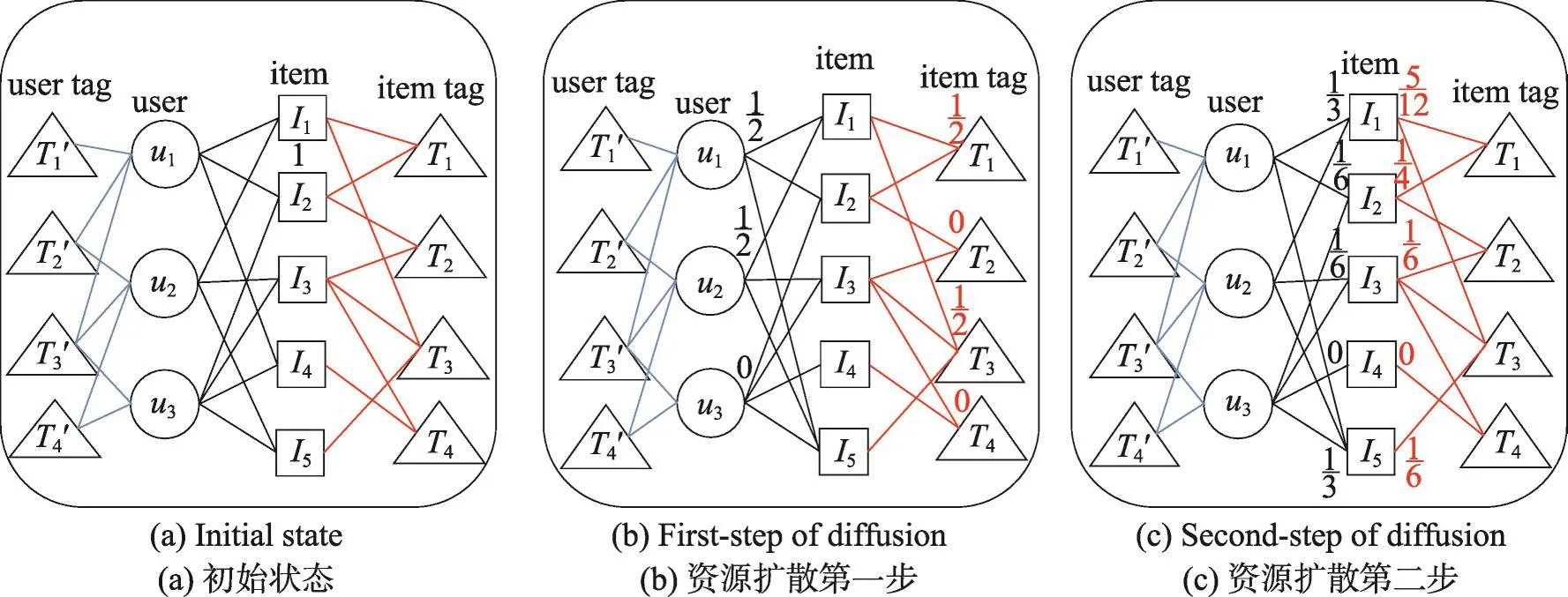
Fig.5 Item-based diffusion process图5 基于商品的资源扩散过程
步骤1输入评分和电影类型表,如表1所示。
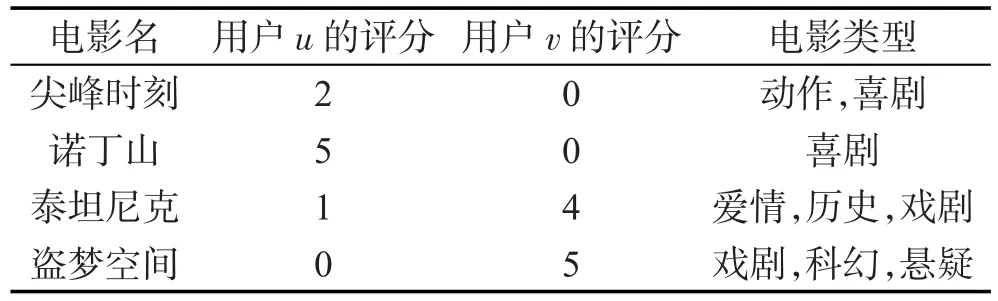
Table 1 User rating and movie type表1 用户评分和电影类型表
步骤2通过评分表计算每个用户的平均评分。
步骤3根据表1的评分以及电影类型信息获得整合用户评分类型表,如表2所示。
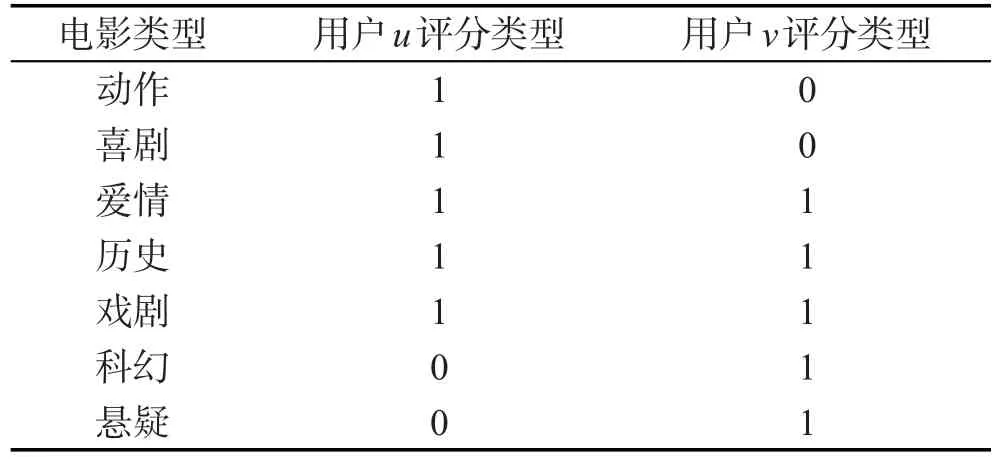
Table 2 User rating type表2 用户评分类型表
步骤4根据表1中的评分信息,使用式(4)计算用户之间的相似度suv。
步骤5根据步骤3获得的用户评分类型信息,使用式(4)来计算另一个用户相似度suv′。
步骤6根据步骤4和步骤5中的两个用户相似度,使用式(9)计算整合相似
步骤7根据步骤2的用户平均评分以及步骤6的整合相似度,使用式(5)计算预测评分。
4.3 基于用户标签-用户-商品关系的算法
基于用户标签-用户-商品关系的算法同时考虑了用户标签和用户之间以及用户和商品之间的关系。在实际应用中,用户标签的类型有很多,比如用户的年龄和职业标签。下面以用户职业标签为例说明算法实现步骤:
步骤1输入用户评分和用户职业表,如表3所示。
步骤2根据表3的评分信息计算用户的平均评分。
步骤3基于评分表,使用式(4)计算用户之间的相似度,记为suv。
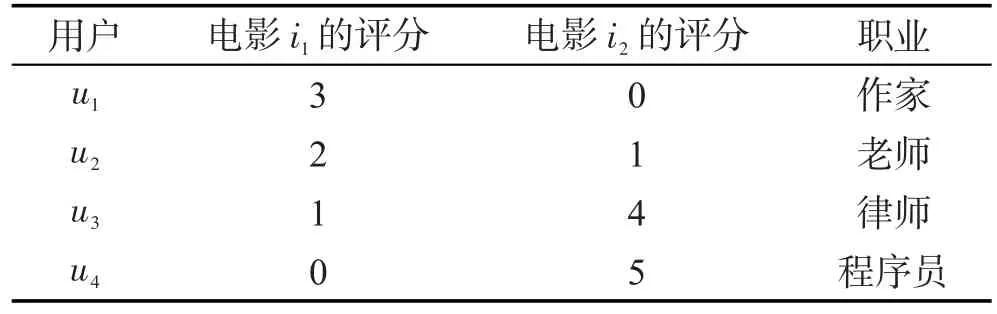
Table 3 User rating and user occupation type表3 用户评分和职业类型表
步骤4根据表3的用户职业类型信息,使用式(4)计算用户之间的相似度,记为
步骤5根据步骤3和步骤4中获得的两种相似度,使用式(9)计算整合相似度
步骤6根据步骤2中的平均评分以及步骤5中的整合相似度,使用式(5)计算预测评分。
4.4 基于商品标签-商品-用户关系的算法
基于商品标签-商品-用户关系的算法考虑了商品与用户以及商品标签与商品之间的关系。算法的具体步骤如下:
步骤1输入评分和电影类型表,如表1所示。
步骤2根据表1用户评分计算商品的平均评分。
步骤3基于表1评分信息,使用式(7)计算商品之间的相似度,记为sij。
步骤4根据表1中的电影类型信息,使用式(7)计算商品之间的相似度,记为sij′。
步骤5根据步骤3和步骤4中的两种商品相似度,使用式(9)计算整合相似度,记为
步骤6根据步骤2中得到的平均评分以及步骤5中计算出的整合相似度,使用式(8)计算预测评分。
4.5 基于用户标签-商品-用户关系的算法
基于用户标签-商品-用户关系的算法考虑了商品和用户之间以及整合后的用户标签与商品之间的关系。算法的具体步骤如下:
步骤1输入用户评分和职业表,如表3所示。
步骤2根据表3评分信息计算商品的平均评分。
步骤3根据表3的用户评分以及用户职业信息获取整合后的商品-职业类型表,如表4所示,这个表说明了看过某个电影的用户的职业信息。
步骤4基于评分信息,使用式(7)计算商品之间的相似度,记为sij。

Table 4 Item-occupation type表4 商品-职业类型表
步骤5根据表4使用式(7)计算另一个商品之间的相似度,记为
步骤6根据步骤3和步骤4的两个商品相似度,使用式(9)计算整合相似度,记为
步骤7根据步骤2中的平均评分以及步骤6中的整合相似度,使用式(8)计算预测评分。
4.6 基于用户标签-用户关系的算法
基于用户标签-用户关系的算法仅仅考虑了用户和用户标签之间的关系。算法的具体步骤如下:
步骤1输入评分和职业类型表,如表3所示。
步骤2根据用户评分表计算用户的平均评分。
步骤3基于用户评分使用式(4)计算用户相似度。
步骤4根据步骤2中得到的平均评分以及步骤3中的用户相似度,使用式(5)计算预测评分。
4.7 基于商品标签-用户关系的算法
基于商品标签-用户关系的算法只考虑了用户与整合商品标签之间的关系。算法的具体步骤如下:
步骤1输入评分和电影类型表,如表1所示。
步骤2根据用户评分表计算用户的平均评分。
步骤3根据评分表以及电影类型信息来获得整合后的用户评分类型表,如表2所示。
步骤4基于用户评分类型表,使用式(4)计算用户之间的相似度。
步骤5根据步骤2中的平均评分以及步骤4中得到的用户相似度,使用式(5)计算预测评分。
4.8 基于商品标签-商品关系的算法
基于商品标签-商品关系的算法只考虑了商品标签与商品之间的关系。算法的具体步骤如下:
步骤1输入评分和电影类型表,如表1所示。
步骤2根据用户评分表计算商品的平均评分。
步骤3根据表1中的电影类型信息,使用式(7)计算商品之间的相似度。
步骤4根据步骤2中得到的平均评分以及步骤3中的商品相似度,使用式(8)计算预测评分。
4.9 基于用户标签-商品关系的算法
基于用户标签-商品关系的算法考虑了用户标签与商品之间的关系。算法的具体步骤如下:
步骤1输入评分和用户职业表,如表3所示。
步骤2根据用户评分表计算商品的平均评分。
步骤3根据用户评分表以及表3中的用户职业信息获取整合后的商品-职业类型表,如表4所示,这个表说明了看过某个电影的用户的职业信息。
步骤4根据表4中商品-职业类型信息,使用式(7)计算商品之间的相似度。
步骤5根据步骤2中得到的平均评分以及步骤4中的商品相似度,使用式(8)计算预测评分。
5 算法时间复杂度分析
在实际的推荐系统应用中,各种类型的数据量相当大,除了考虑算法推荐的准确度外,还应当考虑算法实施的效率,本文分析了10种协同过滤算法的时间复杂度。
考虑一个含有n个用户、m个商品、k个用户标签和r个商品标签的推荐系统。以基于用户标签-用户-商品的算法为例,首先根据评分表和用户标签信息表计算两个用户的相似度矩阵,它们的时间复杂度分别为O(n2m)和O(n2k),然后花费O(n2)时间计算整合用户相似度,接着需要O(mn)+O(n2m)的时间来预测评分,因此总的时间复杂度为O(n2m)+O(n2k)。如果考虑商品标签-商品-用户算法,根据评分表和商品标签分别计算商品相似度矩阵的时间复杂度为O(nm2)和O(rm2),计算整合相似度的时间复杂度为O(m2),而预测评分的复杂度为O(nm2)+O(mn),因此总的时间复杂度为O(nm2)+O(rm2)。10种算法的时间复杂度如表5所示。
从表5中可以看出,对于同样是基于用户或者同样基于商品的算法来说,虽然同时考虑了评分和标签信息的算法的时间复杂度更高,但也只呈线性增长,如表5中第三和第一个算法。此外,只考虑了标签信息的算法和只考虑了评分信息的算法在时间复杂度上的差距不大,比如表5中第二和第十个算法。在实际实验中某些标签的数量可能远远小于用户或者商品的数量,因此某些考虑了标签信息的算法可能会由于标签类型的不同而在时间复杂度上有明显的差距。
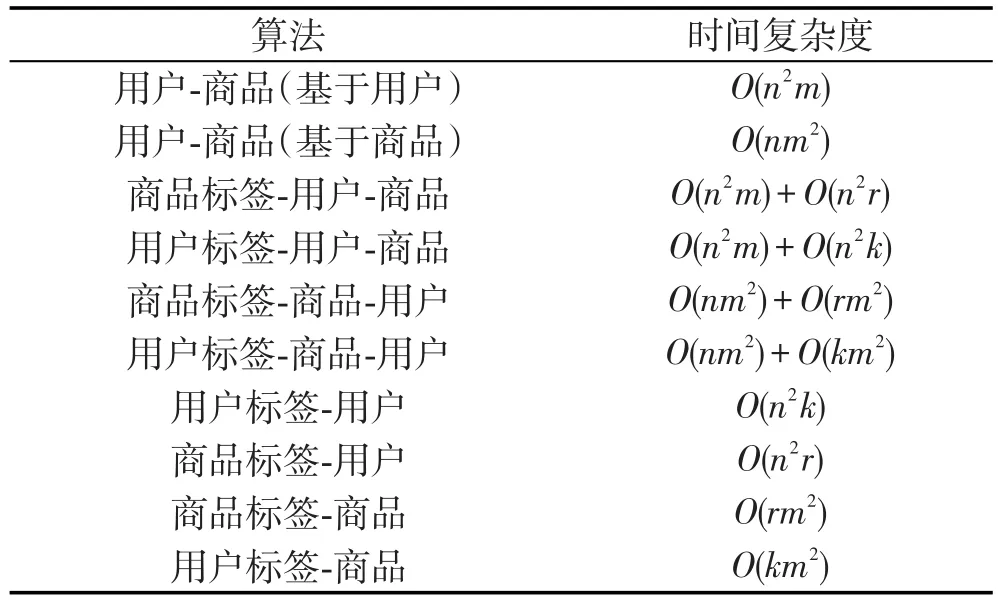
Table 5 Time complexity of 10 algorithms表5 10种算法的时间复杂度
6 实验结果与分析
下面通过实验回答以下4个问题:
(1)哪种算法效果更好?
(2)用户标签与商品标签哪个更有用?
(3)用户相似度与商品相似度哪个可靠?
(4)不同信息的简单线性整合方法是不是有用?
本实验运行在两个MovieLens数据集上:数据集1包含943个用户和1 682个电影,数据集2包含6 040个用户和3 952个电影。实验中的标签信息来源于用户描述、商品信息以及从中提取出来的复合标签信息。实验使用leave-one-out的交叉验证方法来预测评分,也就是说从原始数据集中抽取一个评分作为测试集,而剩下的部分全部作为训练集。实验采用MAE和RMSE评价了文中的10种算法,并通过调整参数λ的值找出了不同算法的最优值。
从表6中可以看出,在943×1 682的MovieLens数据集上,基于商品标签-商品-用户关系的算法表现最好,此算法在参数λ等于0.4时具有全局最优MAE,在λ等于0.5时具有全局最优RMSE,这说明在引入商品标签信息后,推荐算法的预测准确度得到了很好的提高。而对于表6中第三、第四和第六个算法,它们的MAE和RMSE最优值都在λ等于1时取得,也就是说在没有引入标签信息时预测效果反而更好,这说明了不同信息的简单线性整合方式并不一定能够提高预测评分的准确度。
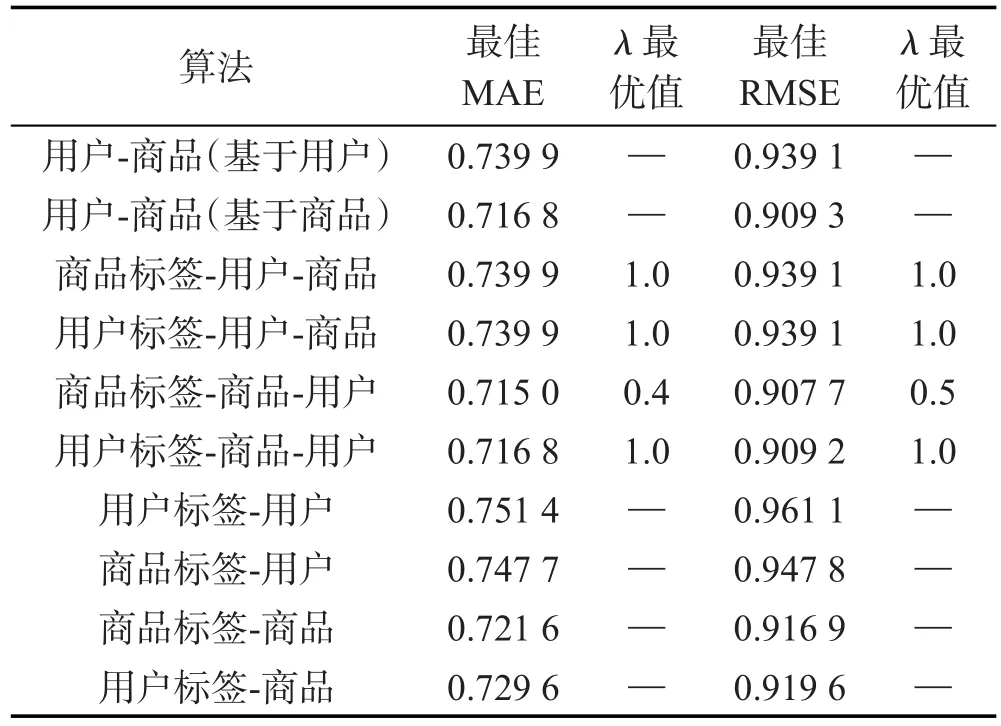
Table 6 Optimal MAE and RMSE of 10 algorithms on data set 1表610种算法在数据集1上的最佳MAE和RMSE
表7的结果说明在6 040×3 952的数据集2上,同样是基于商品标签-商品-用户关系的算法表现最好,其最优MAE和RMSE分别在λ等于0.5和0.6时取得。此外还可以发现,10种算法在数据集2上的表现都要优于其在数据集1上的表现。

Table 7 Optimal MAE and RMSE of 10 algorithms on data set 2表710种算法在数据集2上的最佳MAE和RMSE
表6和表7的前两种以及最后4种算法都没有最优的λ,因为这些算法都只考虑了一组关系,没有进行不同信息的整合,更没有相似度的整合。
综合两个表可以看出,基于商品的推荐算法要明显优于基于用户的推荐算法,而且商品标签要比用户标签更有用,商品之间相似度也要比用户之间相似度更可靠。
为了进一步说明中间4种算法MAE和RMSE随参数λ的变化趋势,给出了图6~图13。
图6~图9说明了不同算法在数据集1上的表现,从这4个图可以看出:随着λ的增大,基于商品标签-商品-用户关系算法的MAE和RMSE值都会先减小再增大,由此可以得到一个最小值,而其他3个算法的MAE和RMSE值则会一直减小,并在λ等于1.0时取得最小值。此时这3个算法实际上并没有考虑标签信息而仅仅考虑了评分信息。
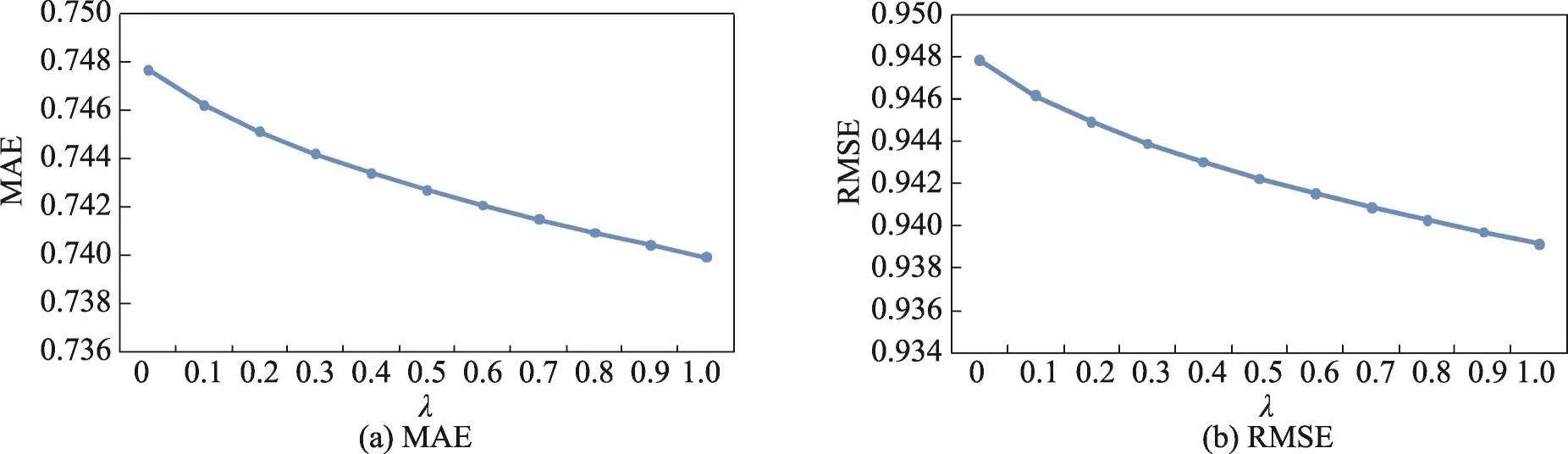
Fig.6 MAE and RMSE of item tag-user-item algorithm on data set 1图6 基于商品标签-用户-商品关系的算法在数据集1上的MAE和RMSE
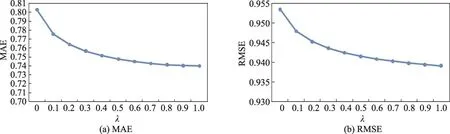
Fig.7 MAE and RMSE of user tag-user-item algorithm on data set 1图7 基于用户标签-用户-商品关系的算法在数据集1上的MAE和RMSE
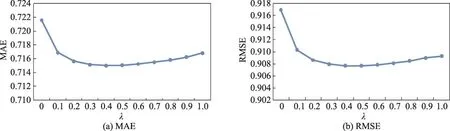
Fig.8 MAE and RMSE of item tag-item-user algorithm on data set 1图8 基于商品标签-商品-用户关系的算法在数据集1上的MAE和RMSE
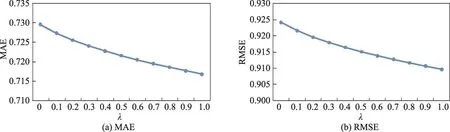
Fig.9 MAE and RMSE of user tag-item-user algorithm on data set 1图9 基于用户标签-商品-用户关系的算法在数据集1上的MAE和RMSE
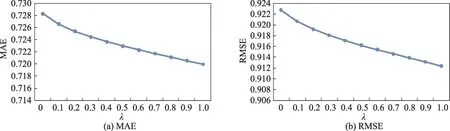
Fig.10 MAE and RMSE of item tag-user-item algorithm on data set 2图10 基于商品标签-用户-商品关系的算法在数据集2上的MAE和RMSE
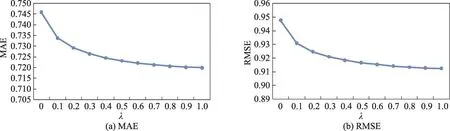
Fig.11 MAE and RMSE of user tag-user-item algorithm on data set 2图11 基于用户标签-用户-商品关系的算法在数据集2上的MAE和RMSE
图10~图13是算法在数据集2上的结果,从这几个图中可以看出,不同算法的MAE和RMSE曲线与其在数据集1上的曲线的变化趋势基本吻合,除了基于商品标签-商品-用户关系算法的MAE和RMSE随着λ的增大出现先减小再增大的趋势外,其他3个算法的MAE和RMSE都呈现出递减的趋势。
7 结束语
本文构造了关于用户评分和标签信息的四部图,根据四部图中不同部分的组合获得了10种推荐算法,并分析了不同算法的时间复杂度。本文使用MAE和RMSE指标评价不同算法的表现,在两个MovieLens数据集上的实验结果表明:基于商品标签-商品-用户关系的算法在两个数据集上的表现都优于其他算法,商品相似度比用户相似度更可靠,商品标签比用户标签更有用,而且不同信息的简单线性整合可以提高预测评分的准确度。
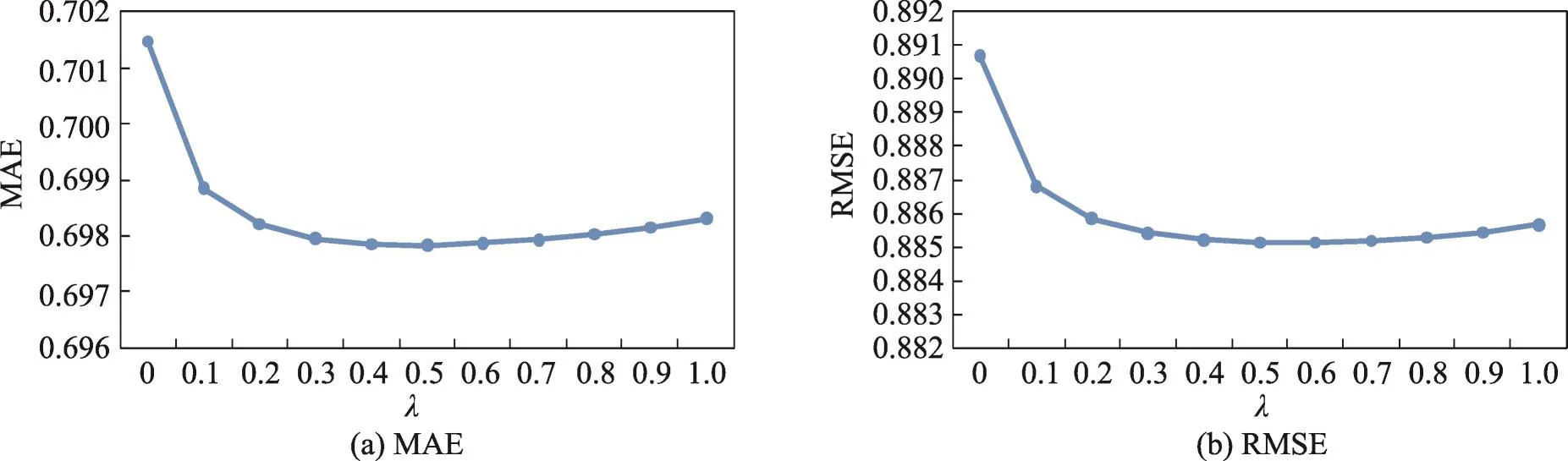
Fig.12 MAE and RMSE of item tag-item-user algorithm on data set 2图12 基于商品标签-商品-用户关系的算法在数据集2上的MAE和RMSE
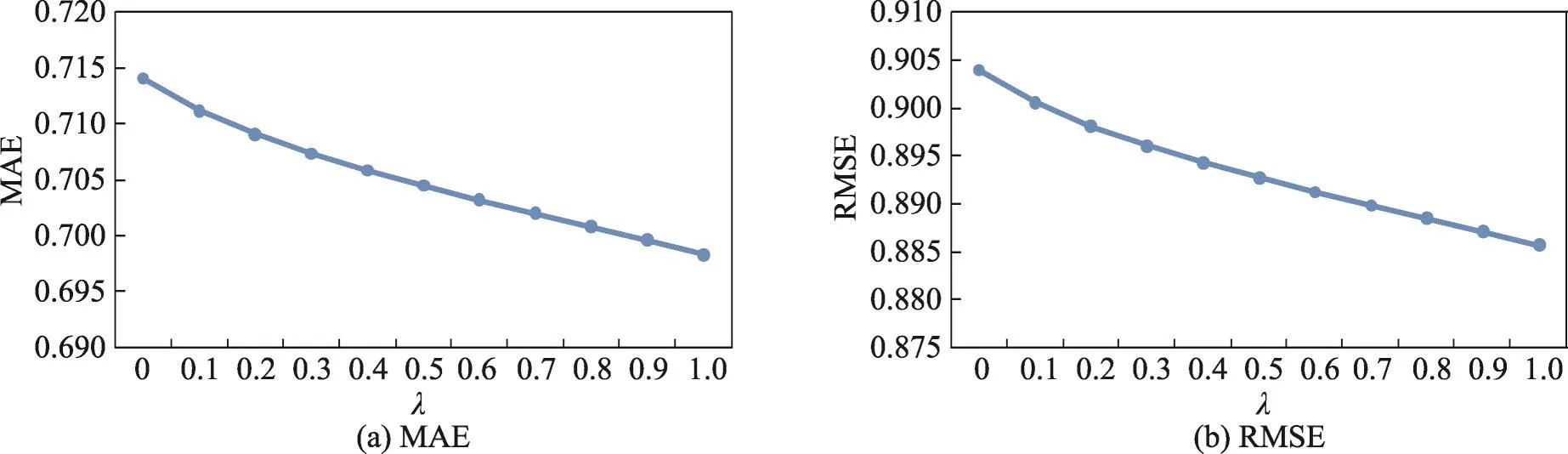
Fig.13 MAE and RMSE of user tag-item-user algorithm on data set 2图13 基于用户标签-商品-用户关系的算法在数据集2上的MAE和RMSE
[1]Bobadilla J,Ortega F,Hernando A,et al.Recommender systems survey[J].Knowledge-Based Systems,2013,46(1): 109-132.
[2]Schafer J B,Frankowski D,Herlocker J,et al.Collaborative filtering recommender systems[M]//The Adaptive Web. Berlin,Heidelberg:Springer,2007:291-324.
[3]Li Yao,Zhang Zhihen,Chen Wenbin,et al.TDUP:an approach to incremental mining of frequent itemsets with threeway-decision pattern updating[J].International Journal of Machine Learning and Cybernetics,2015:1-13.
[4]Zhou Tao,Ren Jie,Medo M,et al.Bipartite network projection and personal recommendation[J].Physical Review E, 2007,76(4):046115.
[5]Hofmann T.Latent semantic models for collaborative filtering [J].ACM Transactions on Information Systems,2004,22 (1):89-115.
[6]Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,Madison,USA,Jul 24-26,1998.San Francisco,USA:Morgan Kaufmann Publishers Inc,1998:43-52.
[7]Shi Yue,Larson M,Hanjalic A.Exploiting user similarity based on rated-item pools for improved user-based collaborative filtering[C]//Proceedings of the 3rd ACM Conference on Recommender Systems,New York,Oct 23-25,2009. New York:ACM,2009:125-132.
[8]Jin Rong,Chai J Y,Si Luo.An automatic weighting scheme for collaborative filtering[C]//Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Sheffield,UK,Jul 25-29,2004.New York:ACM,2004:337-344.
[9]Zhao Zhidan,Shang Mingsheng.User-based collaborativefiltering recommendation algorithms on Hadoop[C]//Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining,Phuket,Thailand,Jan 9-10,2010.Washington:IEEE Computer Society,2010:478-481.
[10]Mobasher B,Burke R,Bhaumik R,et al.Effective attack models for shilling item-based collaborative filtering systems[C]//Proceedings of the 2005 Web KDD Workshop, Chicago,USA,Aug 21,2005.New York:ACM,2005.
[11]Karypis G.Evaluation of item-based top-nrecommendation algorithms[C]//Proceedings of the 10th International Conference on Information and Knowledge Management,Atlanta, USA,Nov 5-10,2001.New York:ACM,2001:247-254.
[12]Shang Mingsheng,Zhang Zike.Diffusion-based recommendation in collaborative tagging systems[J].Chinese Physics Letters,2009,26(11):250-253.
[13]Hotho A,Jäschke R,Schmitz C,et al.Information retrieval in folksonomies:search and ranking[C]//LNCS 4011:Proceedings of the 3rd European Semantic Web Conference, Budva,Montenegro,Jun 11-14,2006.Berlin,Heidelberg: Springer,2006:411-426.
[14]Wang Jun,De Vries A P,Reinders M J T.Unifying userbased and item-based collaborative filtering approaches by similarity fusion[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Seattle,USA,Aug 6-11, 2006.New York:ACM,2006:501-508.
[15]Ou Qing,Jin Yingdi,Zhou Tao,et al.Power-law strengthdegree correlation from a resource-allocation dynamics on weighted networks[J].Physical Review E,2007,75(2): 021102.
[16]Tso-Sutter K H L,Marinho L B,Schmidt-Thieme L.Tagaware recommender systems by fusion of collaborative filtering algorithms[C]//Proceedings of the 2008 ACM Symposium on Applied Computing,Fortaleza,Brazil,Mar 16-20,2008.New York:ACM,2008:1995-1999.
[17]Zhang Zike,Zhou Tao,Zhang Yicheng.Personalized recommendation via integrated diffusion on user-item-tag tripartite graphs[J].Physica A:Statistical Mechanics and Its Applications,2010,389(1):179-186.

MOU Binhao was born in 1992.He is an M.S candidate at Southwest Petroleum University.His research interests include data mining and machine learning.
牟斌皓(1992—),男,四川泸州人,西南石油大学硕士研究生,主要研究领域为数据挖掘,机器学习。

ZHANG Zhiheng was born in 1990.He is a Ph.D.candidate at Southwest Petroleum University.His research interests include data mining and machine learning.
张智恒(1990—),男,重庆梁平人,西南石油大学博士研究生,主要研究领域为数据挖掘,机器学习。

张林(1963—),男,四川乐山人,1999年于日本山口大学获得博士学位,现为西南石油大学教授,主要研究领域为计算机图像处理,网络安全。完成国际合作项目5项,省部级项目2项,其中1项获国家科学技术进步三等奖,1项获航空航天部重大科技成果二等奖,在国际学术期刊和会议上发表论文10余篇。

MIN Fan was born in 1973.He received the Ph.D.degree from University of Electronic Science and Technology of China in 2003.Now he is a professor and Ph.D.supervisor at Southwest Petroleum University.His research interests include machine learning and cost sensitive research.He has authored over 110 papers in various journals and conferences.
闵帆(1973—),男,重庆人,2003年于四川电子科技大学获得博士学位,现为西南石油大学教授、博士生导师,主要研究领域为机器学习,代价敏感研究。发表学术论文110余篇,其中SCI/EI检索70余篇,主持国家自然科学基金等多项科研项目。
Comparison Study of Collaborative Filtering Algorithms Based on Quadripartite Graph*
MOU Binhao1,ZHANG Zhiheng2,ZHANG Lin1,MIN Fan1+
1.School of Computer Science,Southwest Petroleum University,Chengdu 610500,China
2.School of Sciences,Southwest Petroleum University,Chengdu 610500,China
+Corresponding author:E-mail:minfanphd@163.com
A recommender system often collects information about user profiles,item attributes and explicit ratings of users to items,which are further used to make predictions about unknown ratings.This paper constructs a quadripartite graph about the information and acquires ten algorithms from different parts of the graph.The first two algorithms are the classical user-and item-based collaborative filtering and only take into account the rating information. Four more algorithms take user or item as center and use relevant tags to compute user or item similarity.To extend the previous four algorithms,four more algorithms take into account the user-item relationship along with tag information.This paper compares the time complexity of different algorithms on two MovieLens data sets,and uses MAE(mean absolute error)and RMSE(root-mean-square error)metrics to evaluate the performance of different algorithms.The experimental results demonstrate that the similarity of items is more reliable than that of users,and item tags are more useful than user tags.Besides,some simple linear integrations of different information are capable of enhancing recommendation performance.
was born in 1963.He
the Ph.D.degree from Yamaguchi University in 1999.Now he is a professor at Southwest Petroleum University.His research interests include image processing and network security.
A
TP181
*The National Natural Science Foundation of China under Grant No.61379089(国家自然科学基金);the Natural Science Foundation of Department of Education of Sichuan Province under Grant No.16ZA0060(四川省教育厅自然科学基金).
Received 2016-04,Accepted 2016-06.
CNKI网络优先出版:2016-06-23,http://www.cnki.net/kcms/detail/11.5602.TP.20160623.1139.012.html
Key words:recommender system;collaborative filtering;quadripartite graph;collaborative filtering tag
