面向开源软件项目的软件知识图谱构建方法*
2017-06-15李文鹏王建彬林泽琦赵俊峰邹艳珍
李文鹏,王建彬,林泽琦,赵俊峰+,邹艳珍,谢 冰
1.北京大学 信息科学技术学院,北京 100871
2.高可信软件技术教育部重点实验室,北京 100871
3.北京大学(天津滨海)新一代信息技术研究院,天津 300450
面向开源软件项目的软件知识图谱构建方法*
李文鹏1,2,3,王建彬1,2,3,林泽琦1,2,3,赵俊峰1,2,3+,邹艳珍1,2,3,谢 冰1,2,3
1.北京大学 信息科学技术学院,北京 100871
2.高可信软件技术教育部重点实验室,北京 100871
3.北京大学(天津滨海)新一代信息技术研究院,天津 300450
LI Wenpeng,WANG Jianbin,LIN Zeqi,et al.Software knowledge graph building method for open source project.Journal of Frontiers of Computer Science and Technology,2017,11(6):851-862.
软件复用是软件开发中避免重复劳动的解决方案。开源软件的源代码、邮件列表、缺陷报告和问答文档等软件资源中蕴含了规模庞大、结构复杂、语义关联丰富的软件知识。如何获取知识、组织知识,以及如何在软件复用过程中方便地检索软件知识是亟待解决的问题。为了解决这些问题,面向开源软件项目,构建了软件知识图谱,并提供了基于软件知识图谱的软件知识检索。主要工作包括:针对4种不同类型的软件资源,提出了软件知识实体的提取原则与方法;提出了软件知识实体之间关联关系构建的方法;实现了两种软件知识检索机制,并以文字列表和图形可视化相结合的方式展现检索结果;设计了软件知识图谱构建框架。基于上述工作,设计并实现了一个面向开源软件项目的软件知识图谱构建工具。实例证明,所构建的软件知识图谱可以更好地帮助软件开发人员进行软件知识的检索与应用。
软件复用;开源软件;软件知识图谱;图数据库
1 引言
软件复用是软件开发中避免重复劳动的解决方案。通过软件复用,可以提高软件开发的效率和质量[1]。软件复用成功的基本前提是存在大量可复用的软件构件,并且复用者在复用之前可以方便、有效地找到合适的可复用构件[2]。开源软件是一种有效的软件复用模式[3]。开源软件的蓬勃发展,极大地丰富了可复用的软件构件。
开源软件的源代码、邮件列表、缺陷报告和问答文档等软件资源中蕴含了规模庞大、结构复杂、语义关联丰富的软件知识,这些知识能够帮助软件开发人员理解软件功能,进行软件复用。然而,如何组织、利用这些知识却面临诸多挑战:
(1)软件规模增长引发的软件知识爆炸问题。随着软件规模的增长和软件复杂度的提高,在软件的开发与复用过程中所需要理解与掌握的知识越来越多,使得复用者的学习成本越来越高。
(2)不同类型软件资源导致的软件理解问题。软件资源的类型多种多样,不同类型的软件资源中的软件知识的特征也各不相同。
(3)软件知识难以直观地服务于软件开发人员。从不同类型的软件资源中抽取出的软件知识实体数量庞多,而且知识实体之间关系错综复杂,需要提供一种方便用户检索和浏览知识的机制。
为了有效地组织软件资源,更好地进行软件复用,本文面向开源软件项目构建了软件知识图谱。软件知识图谱是指由不同类型的软件资源的软件知识图有机融合构成的用以描述某一软件的知识体系。软件知识图是指由同一类型软件资源的软件知识实体及其之间的关联关系所构成的图。软件知识实体指的是软件资源中可区分的、可辨识的且具有一定语义关系的单元体,而软件知识实体之间关联关系指的是两两软件知识实体之间具有某种类型的二元关系。本文工作主要包括:
(1)提出了软件知识实体的提取原则与方法。分别从软件源代码、缺陷报告、邮件列表和问答文档4种软件资源中提取了相应的软件知识实体。
(2)提出了软件知识实体之间关联关系构建的方法。分析了同一类型软件资源中的软件知识实体关联关系的构建方法与不同类型软件资源中软件知识实体之间的关联关系。
(3)设计了形式化检索和文本检索两种软件知识检索机制,并以文字列表和图形可视化相结合的方式展现检索结果。
(4)设计了软件知识图谱构建框架,该框架由软件知识提取模块、软件知识融合模块、软件知识图谱存储管理模块与软件知识检索模块构成。
基于上述工作,本文设计并实现了一个面向开源软件项目的软件知识图谱构建工具,并以Lucene-Core为例,通过应用实例展示了本文工作的有效性和合理性。
2 相关工作与技术
从软件资源中提取知识的相关研究有:Cubranic等人[4]开发了工具Hipikat来帮助复用者检索开源软件的各种资源,其中主要涉及缺陷、特征描述、开发者论坛中的帖子与其他项目相关的文档这4类资源。Hipikat为一个指定项目收集资源和挖掘各类资源之间的关联关系,建立了项目的资源数据库。复用者可以在该库中进行检索,系统将返回与之文本相似度较高的各种资源及其之间的关联关系,方便复用者学习。但是Hipikcat对于每类软件资源仅提取了对应的文本信息,未对软件资源做进一步的知识提取。Gopinath等人[5]从软件项目的代码中提取出包、类、接口和方法信息,定义了项目、包、类、接口、方法等本体,将所有项目的本体存储在同一个本体网里,以帮助开发者复用已有的软件。McMillan等人[6]构建了代码中函数之间的调用关系图,用于在代码搜索系统中帮助使用者检索函数以及使用示例。
DBPedia从维基百科(Wikipedia)的词条里撷取出结构化的知识(RDF格式),并以语义网的形式将撷取的知识整合在一起[7]。DBPedia支持用户进行语义化查询维基百科相关资源的属性和资源之间的关系。谷歌的知识图谱将谷歌索引的所有事物、人物和地点,例如地标性建筑、名人、球队、电影、艺术品等,刻画成实体,并建立这些实体之间的关联关系。早期的知识图谱建立在诸如Freebase、维基百科、维基数据以及美国中央情报局出版的《世界概况》等著名公开数据源上,其包括了5亿多个对象实体以及350亿条这些对象实体之间的关联关系。近期,谷歌又通过机器学习和数据挖掘方法[8-12],从索引的网页中自动发现新的实体和实体关系,从而扩大并完善了知识图谱[13]。这些研究主要涉及通用领域,较少涉及软件相关的知识。本文根据软件资源的特点研究软件资源中的软件知识提取和管理,并构建软件知识图谱。
有关代码和文档之间的可追踪性(traceability)的工作很多,本文关注这一研究方向中的代码元素识别和关联技术。Bacchelli等人[14]开发了Miler工具,用以从邮件列表中提取出包含的代码元素。该工具的主要思想是:先解析出软件项目的代码,再结合驼峰命名法(camel-case)和正则表达式匹配来识别代码元素。Miler区分大小写,可以较为准确地识别出组合词(如IndexReader)和单项词元素(如Index)。其中组合词的识别准确率最高,而单项词元素可能是自然语言中的单词,需要添加一定的规则进而准确地识别单项词元素。Dagenais等人[15]开发了Reco-Doc工具,用于对API的相关学习资料建模,并从中提取出包含的代码元素,进而建立API和相关学习资料之间的可追踪性。RecoDoc结合了部分程序分析和正则匹配技术提取代码元素;同时还制定了一些启发式规则,结合上下文环境提取代码元素。
3 问题分析
软件资源中的软件知识实体丰富多样,它们之间的关联关系也是错综复杂。为此需要采用合适的模型表达软件知识实体以及软件知识实体之间的关联关系。属性图模型能够很好地利用属性表达结点和关系丰富的信息,因此本文采用属性图模型进行软件知识图谱的构建。属性图模型的特征[16]如下:属性图模型是由结点、有向边和属性组成的;结点上包含属性,属性可以任何键值对的形式存在;每条边都拥有一个方向、一个标签、一个开始结点和一个结束结点;就像结点一样,边也是有属性的。
基于属性图模型,本文的软件知识图谱采用如下机制统一地表示从软件资源中提炼的结构化软件知识:图中每个结点对应一个软件知识实体;图中的每条有向边代表一个语义关联;每个软件知识实体中的键值对与实体所对应的结点属性一一对应;每个结点或边由全局标识符唯一标识。
属性图模型是很多图数据库的底层实现模型。DB-Engines排名前5的图数据库[17]依次分别是Neo4j(http://neo4j.com/)、OrientDB(http://orientdb.com/)、Titan(http://thinkaurelius.github.com/titan/)、Virtuoso(http://virtuoso.openlinksw.com/)和ArangoDB(https: //www.arangodb.com/)。考虑到存储模型、查询语言、图数据库成熟度等因素,由于Neo4j原生支持属性图模型,具有丰富的查询语言,使用用户多,成熟度高,本文选择Neo4j作为软件知识图谱的底层存储。
在构建面向开源项目软件知识图谱时,需要解决以下3个问题:
(1)软件知识实体提取。软件资源的类型是多种多样的,包括软件源代码、邮件列表、缺陷报告、相关问答文档等各种不同的资源类型。同一类型的软件资源、数据来源也可能不同,如缺陷报告可能来自JIRA、BugZilla或Lighthouse。不同的软件资源中,软件知识实体的形式与特点也各不相同。
(2)软件知识实体关联关系建立。同一类型的软件资源中所提取的软件知识实体之间存在各种关联关系,由软件资源自身特点决定;从不同类型的软件资源中提取的软件知识实体也存在关联关系,如邮件中可能引用一个缺陷报告。
(3)软件知识检索与展现。如何利用软件知识图谱向软件开发人员提供其所需的知识,并针对不同精度需求提供不同方式的检索。
4 解决方案
本文面向开源软件项目的软件知识图谱构建工具的总体框架如图1所示。
面向开源项目软件知识图谱构建工具的输入是开源项目的源代码、缺陷报告、邮件列表和问答文档等软件资源。首先从这些软件资源中提取出各自的软件知识图,称之为软件知识提取;然后建立软件知识实体关联关系,将来自不同类型软件资源独立的软件知识图有机地组织在一起,形成软件知识图谱;最后建立知识检索与展现机制,面对用户的精确检索和模糊检索需求,在软件知识图谱之上提供形式化检索和文本检索两种检索机制。
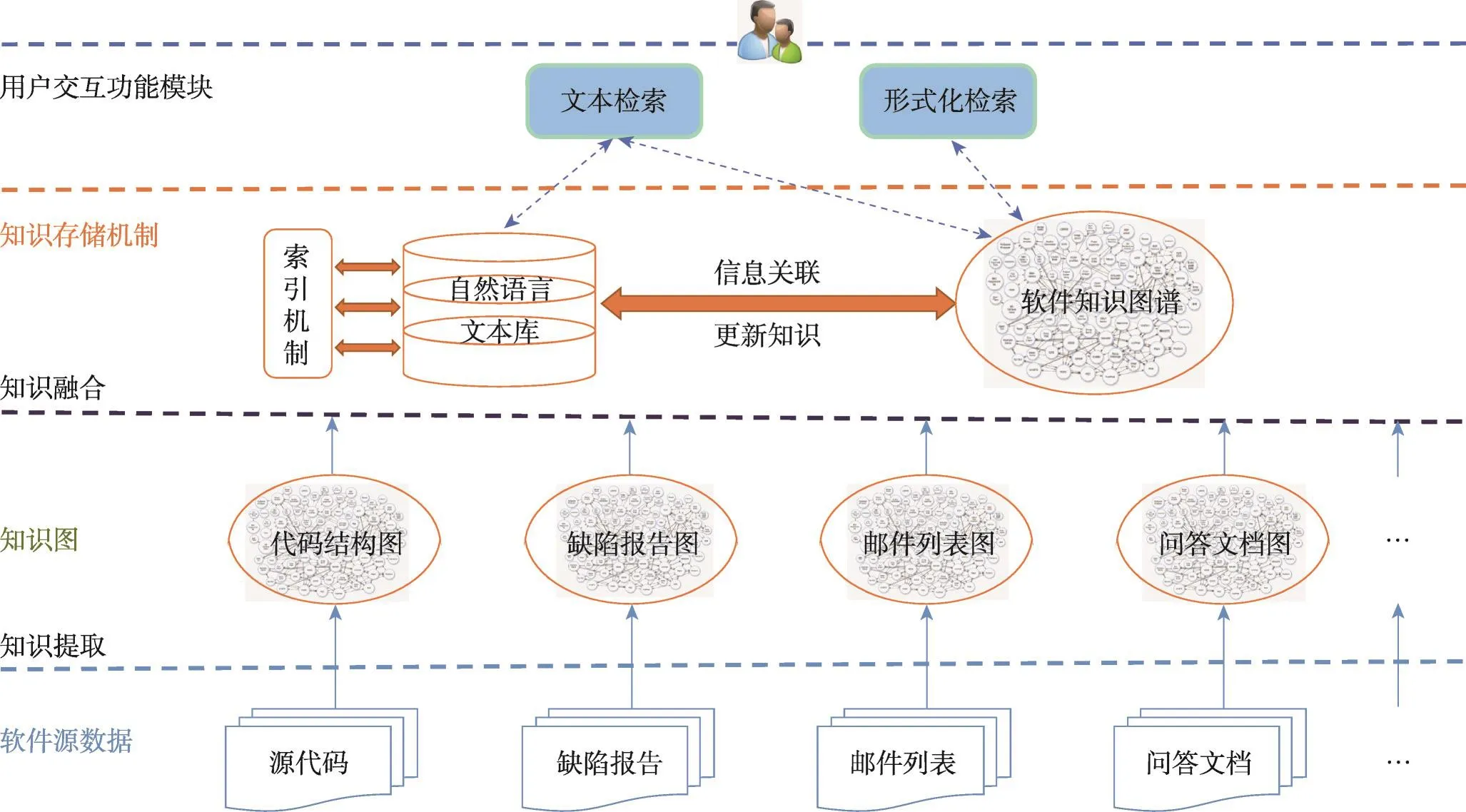
Fig.1 Framework diagram of software knowledge graph图1 软件知识图谱框架图
基于上述的总体解决方案,下面将对软件知识实体提取、软件知识实体关联关系建立和软件知识检索与展现3个问题进行详细的阐述。
4.1 软件知识实体提取
4.1.1 面向软件源代码的软件知识实体提取
本文主要面向Java开源项目,因此研究面向Java源代码的软件知识实体提取。根据Java语言规范,Java代码是由包、类、接口、域、方法、语句等代码元素构成。为了进一步丰富代码结构化的知识,本文将域和方法提取为软件知识实体,具体实体属性内容如表1所示。

Table 1 Information of software knowledge entities in code表1 代码中的软件知识实体信息表
本文使用Eclipse JDT的ASTParser将每个Java文件解析成一个抽象语法树(abstract syntax tree,AST)。AST使用树状结构表示代码的抽象语法结构,树上每个结点都对应代码中的一种结构。
代码中的每个元素都对应抽象语法上的一个结点,使用Visitor设计模式遍历所有结点提取如表1所示的包、类、接口、域和方法软件知识实体以及对应的属性信息,并将这些软件知识实体保存至代码实体池中。另外,ASTParser只能将块注释关联至对应的代码元素,而对于行注释信息则不能自动对应到相应的代码元素上。对于行注释信息,需单独处理,根据其在文件中的位置与相应的代码实体绑定。
4.1.2 面向缺陷报告的软件知识实体提取
开源软件项目中常用的缺陷报告系统有JIRA、 BugZilla和Lighehouse,它们的差异在于不同系统中信息的丰富程度不同,本文通过取这些缺陷报告系统信息的超集来解决这个问题。如JIRA的缺陷报告中有缺陷类型信息,而Bugzilla中没有该信息,那么超集为包含该信息,只是从Bugzilla中提取该信息时为null。
缺陷报告可以看作是“问题-解决方案-反馈-参与者”型的软件资源。对于这类资源,可以将每个问题、解决方案、反馈以及相应的参与者单独提取为一个软件知识实体。因此将“缺陷报告”、“补丁”、“缺陷报告评论”以及相应的参与者单独提取为软件知识实体,如表2所示。

Table 2 Information of software knowledge entities in issue表2 缺陷报告中的软件知识实体信息表
JIRA中每一个缺陷报告对应一个JSON(Java-Script object notation)和多个文本格式的补丁文件(如果有补丁文件)。其中JSON文件中包含了除补丁外所有与缺陷报告相关的信息。本文使用开源JSON解析工具GSON解析JSON文件,从每一个JSON文件中获取对应缺陷报告实体、补丁实体、缺陷报告评论实体和缺陷报告用户实体的信息,利用文件解析工具FileUtils解析相应的补丁文件设置补丁的“补丁内容”信息。
4.1.3 面向邮件列表的软件知识实体提取
开源软件项目的邮件列表归档通常使用Mbox格式。一封邮件天然就是可区分可辨识的且具有一定语义的单元体,可以将单独的一封邮件提取为软件知识实体。具体属性如表3所示。

Table 3 Information of software knowledge entities in mail表3 邮件列表中的软件知识实体信息表
开源软件提供的邮件列表归档的格式多样,本文考虑Mbox格式。每个Mbox文件由多封邮件构成,本文使用Mime4j解析出每一封邮件,以及每封邮件对应的标识符、主题、发送日期、发送者、接收者和邮件内容。
为了获取邮件“用户实体”的信息,本文通过正则匹配从发送者和接收者信息中解析出名称和邮件地址。但是,Mbox中的用户名称位置不尽相同,而且表示形式多样。针对这种情况,本文为发现的每一种特殊形式设计一个正则表达式,尽可能提高准确度。
4.1.4 面向问答文档的软件知识实体提取
问答文档是“问题-解决方案-反馈-参与者”型的软件资源,可以将问题、答案、评论以及相应的参与者单独提取为软件知识实体,如表4所示。
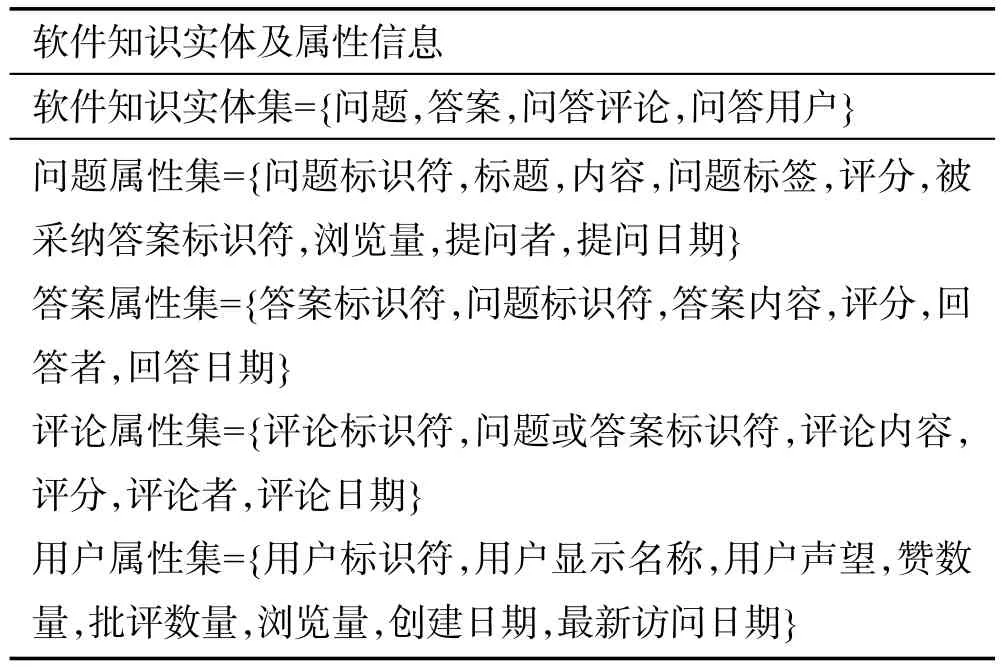
Table 4 Information of software knowledge entities in Q&Adocument表4 问答文档中的软件知识实体信息表
本文问答信息获取自问答网站Stack Overflow的数据Stack Overflow Dump,解析Dump得到Posts、Comments和Users等几个XML文件,利用XML解析器SARParser解析Posts提取出问题和答案实体;解析Comments提取出问答评论实体;解析Users提取出问答用户实体。
4.2 软件知识实体关联关系建立
软件知识实体之间具有大量语义丰富的关联关系:同一软件资源内部的软件知识实体之间的关联关系,这些关系往往是特有的、与类型相关的,需要针对具体的资源类型建立起这些语义关联关系;跨不同软件资源的软件知识实体之间的关联关系,本文考虑3类:(1)代码元素关联,一个软件知识实体所包含的信息中直接提及了同项目中的某一个代码元素;(2)引用关联,一个软件知识实体通过超链接或唯一标识符的形式引用另一个软件知识实体;(3)用户关联,同一用户在不同软件知识实体中扮演不同角色。
4.2.1 同一资源的软件知识实体关联关系建立
本文建立的软件知识实体之间的关联关系如表5~表8所示。其中关系均采用集合论表示,如“实现= {(类,接口)}”中实现关系集合包括类与接口之间的实现关系。

Table 5 Relationship information of code entities表5 软件代码实体之间的关联关系表
软件代码中多数关系蕴含在已提取出的软件知识实体属性中。对于“依赖”和“调用”关系,需要利用ASTParser将代码解析到每一个语句。

Table 6 Relationship information of issue entities表6 缺陷报告实体之间的关联关系表

Table 7 Relationship information of mail entities表7 邮件列表实体之间的关联关系表

Table 8 Relationship information of Q&Adocument entities表8 问答文档知识实体之间的关联关系表
“作者关系”蕴含在知识实体属性中,而对于“补丁关系”、“缺陷报告评论关系”、“重复关系”而言,需要在解析过程中,记录下对应关系类型的映射,根据每一条映射为实体添加关联关系。
“发送者”、“接收者”关系蕴含在邮件实体的“接收者”属性中;“回复”关系需要在解析Mbox时记录下包含“In-Reply-To”信息的邮件的标识符以及对应的“In-Reply-To”信息,通过标识符定位具体的邮件实体,并在两个邮件实体之间建立“回复”关系。
“答案关系”、“评论关系”、“作者关系”蕴含在知识实体属性中,对于“重复关系”,解析PostLinks得到重复关系对应的问题标识符对,在对应的问题实体间建立一条“重复关系”。
4.2.2 不同资源的软件知识实体关联关系建立
对于不同类型软件资源中的软件知识实体,本文主要建立3种不同的关联关系:代码元素关联、引用关联和用户关联。
4.2.2.1 代码元素关联
代码元素关联是指建立软件代码中的软件知识实体与其他类型软件资源中软件知识实体之间的关联关系。如果一个非代码软件知识实体的属性信息提及了同项目的一个代码元素(类、接口、域或方法),则在该软件知识实体与该代码元素对应的软件知识实体之间建立一条语义关联关系。本文称这种语义关联关系为“代码引用”关系,可以看作一种特殊的“引用”关联关系。代码元素关联识别方法根据RecoDoc[15]技术实现,具体方法如下:
(1)通过基于模式匹配的方法实现对自然语言文本中的词项进行分类。该工作将自然语言文本中的词项划分成两类:自然语言词项与代码词项。这一划分通过与若干自定义的词项模式进行自动比对(如驼峰命名模式、常量大写模式等),适应于对大部分常见代码风格的软件项目分析。
(2)通过上下文分析的方法实现对代码元素的歧义消除。该工作对代码元素的歧义消除利用了上下文分析技术,其基础是代码元素在文档中出现的局部性,即在相近的文档实体中被引用的代码实体亦多是相近的。
(3)通过基于注释分析的方法实现对识别结果的精化。对于上下文信息不足的代码词项,该工作利用待消除歧义的代码实体所涉及的注释,度量它与文档实体间的相似性,进而对识别结果进行精化。
4.2.2.2 引用关联
(1)识别出可被引用(超链接或全局唯一标识符引用)的软件知识实体。
(2)分析每一类可被引用的软件知识实体对应的超链接或全局唯一标识符的模式。
(3)对于每一个具体的、可被引用的软件知识实体ei,逐一分析每个软件知识实体ej,若ej包含符合ei超链接或全局唯一标识符模式的字符串,则建立一条从ej到ei的“引用”关系。
4.2.2.3 用户关联
用户关联是指同一用户在不同软件知识实体中扮演不同角色的关联关系。比如,某个邮件的发送者也是某个缺陷报告的创建者。本文根据邮件地址与用户名等信息,识别并关联不同类型软件资源中的同一用户,进而间接建立不同类型软件资源的软件知识实体之间的关联关系。本文称这种语义关联关系为“同一用户”关系。建立用户关联的方法如下:
(1)识别出包含用户的软件资源。
(2)按照是否包含邮件地址信息,将用户分成两类。
(3)对于包含邮件地址的用户,直接通过邮件地址关联不同类型软件资源中的用户。
(4)对于不包含邮件地址的用户,基于“在不同软件资源中讨论同一项目、用户名称相同且唯一的两个用户是同一个人”的假设,通过用户名称关联不同类型软件资源中的用户。
5 软件知识检索与展现
5.1 形式化检索与展现
本文软件知识图谱的底层存储支持系统为Neo4j。Neo4j提供了一个声明式的、易读的图查询语言Cypher,可直接使用Cypher检索软件知识。
Cypher语法对于自定义的关系、结点的标签和结点、关系的属性名是区分大小写的。当关系名称和结点的标签名称较长时,输入拼写正确的名称是困难的,对使用者是不友好的。本文借鉴Eclipse进行代码补全的思想,根据上下文环境实时推荐代码元素,开发了Cypher补全工具,使得用户输入查询语句时可以根据上下文推荐关系、结点的标签和属性名。
5.2 文本检索与展现
本文将所有软件知识实体的核心文本内容(表9)单独提取成一个个的文档,并建立起文档与软件知识实体之间的关联关系;然后为每个文档建立倒排索引。在用户进行检索时,返回TopK(本文K= 100)个与检索语句相关的文档,然后根据文档与软件知识实体之间的关联关系,得到TopK个与检索语句相关的软件知识实体。展示内容包含核心内容及相应上下文信息。

Table 9 Core attributes of software knowledge entities表9 软件知识实体核心内容属性表
6 应用实例
本章首先介绍以Lucene-Core项目为例构造的软件知识图谱的情况,接着展示Cypher自动补全的效果,最后展示软件知识检索效果。
6.1 实例展示
Lucene-Core软件知识图谱的软件知识实体和关联关系数量统计情况如表10、表11所示。
6.2 软件知识检索与展现
6.2.1 代码补全展示
图2和图3展示了本文Cypher补全工具对结点标签信息、结点属性信息补全的情况。
6.2.2 检索IndexReader类所有的子孙类

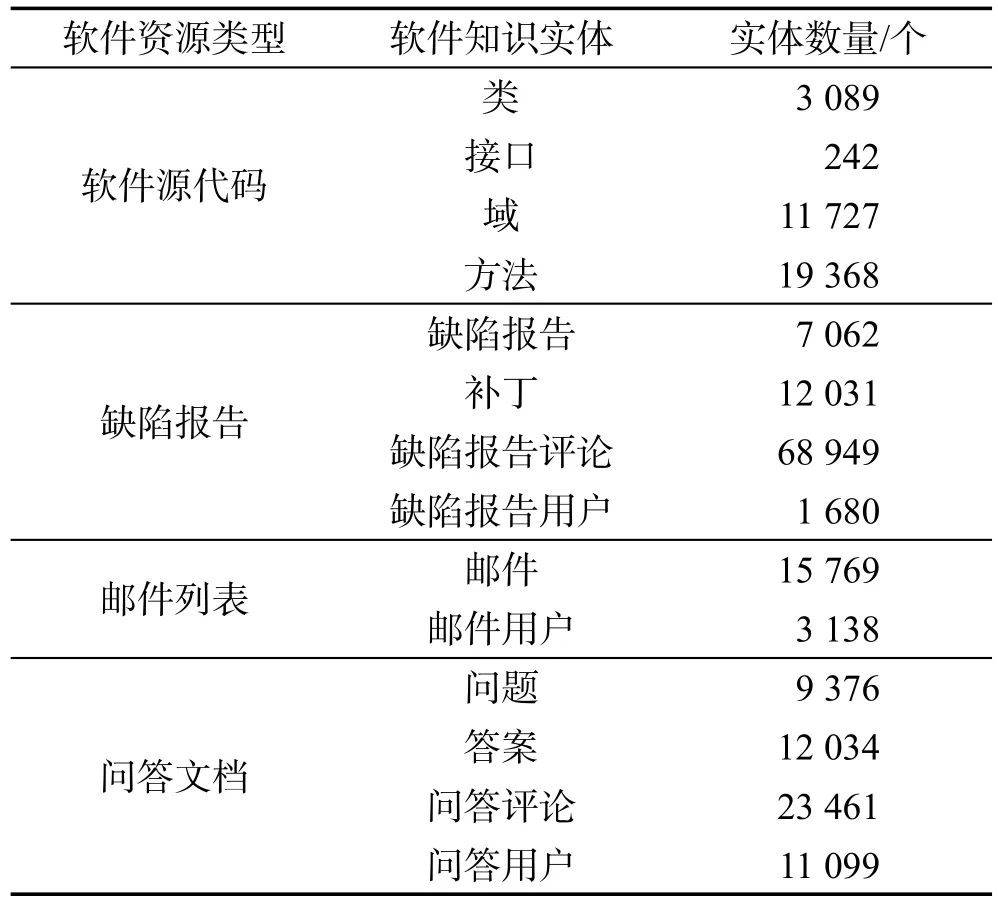
Table 10 Software knowledge entities in Lucene-Core表10 Lucene-Core软件知识实体统计表
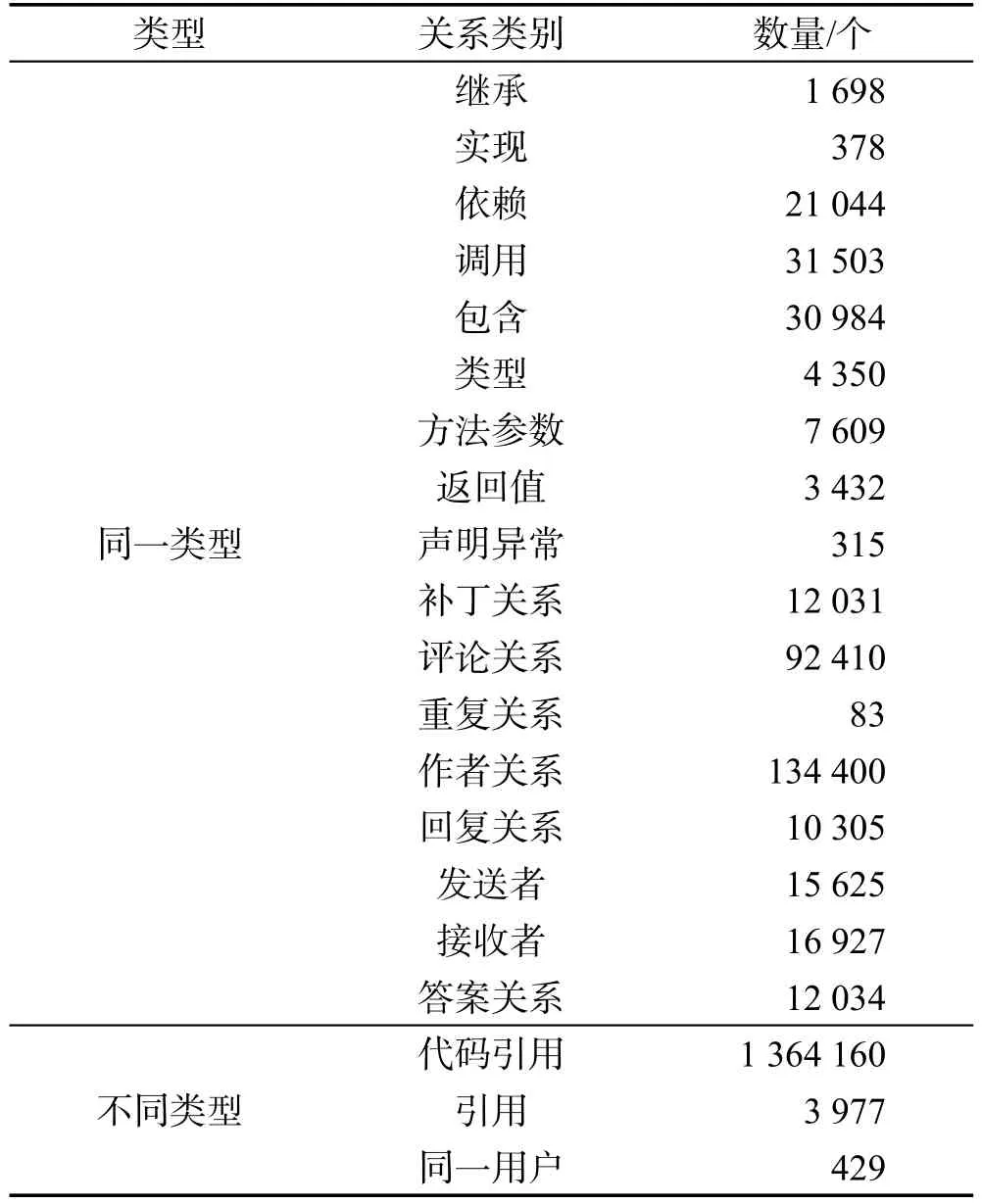
Table 11 Relationships of software knowledge entities in Lucene-Core表11 Lucene-Core软件知识实体关联关系统计表
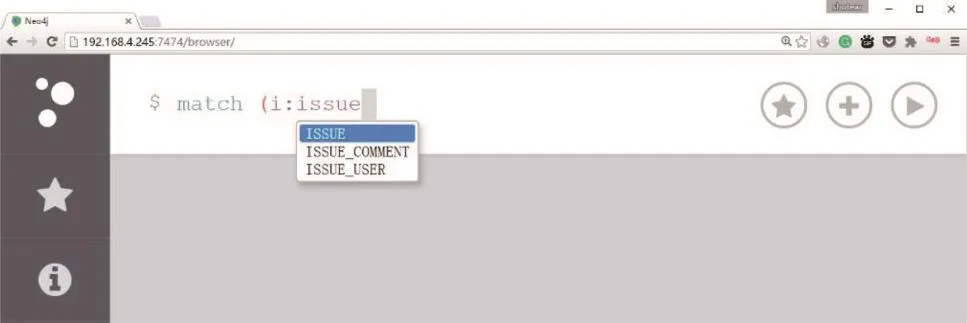
Fig.2 Auto-completion of node label图2 结点标签补全示意图
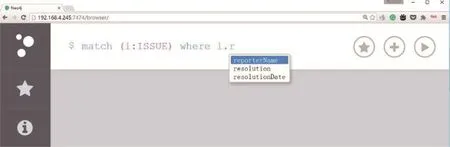
Fig.3 Auto-completion of node attribute图3 结点属性自动补全示例图
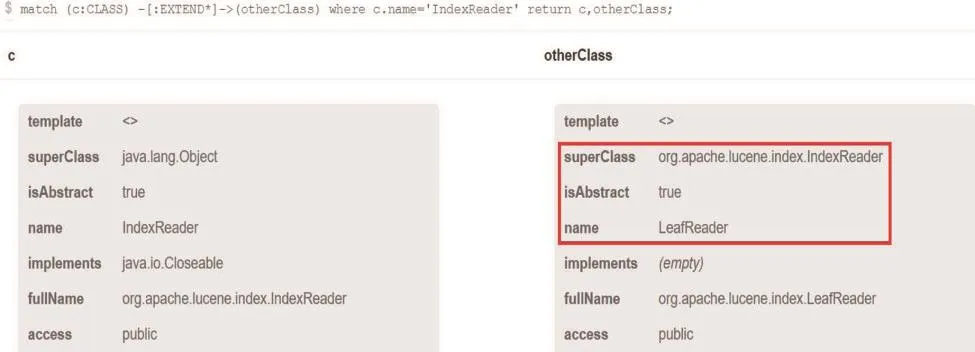
Fig.4 Search result in text list about“descendent classes of IndexReader”图4 “IndexReader类所有的子孙类”文字列表检索结果
文字列表检索结果(部分结果)、图形可视化检索结果分别如图4和图5所示。由图4中红框部分可知,LeafReader的父类是IndexReader。图5展示了所有直接或间接继承IndexReader的类,其中最上面的结点为IndexReader,向下每一行表示Index同一继承深度的子孙类,继承关系由边上的“EXTEND”表示。
6.2.3 检索与IndexReader类相关的重复Bug信息

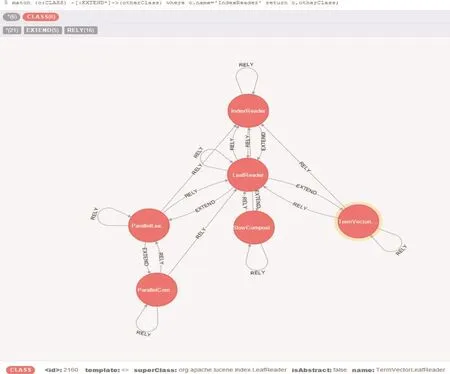
Fig.5 Search result in graph about“descendent classes of IndexReader”图5 “IndexReader类所有的子孙类”图形可视化检索结果
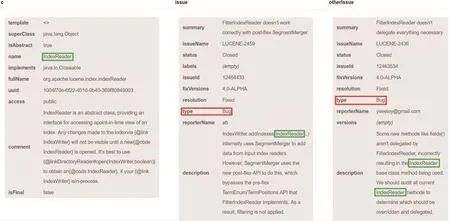
Fig.6 Search result in text list about“bug duplications of IndexReader”图6 “IndexReader类相关的重复Bug信息”文字列表结果
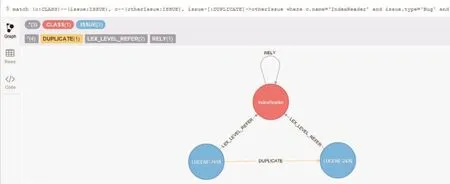
Fig.7 Search result in graph about“bug duplications of IndexReader”图7 “IndexReader类相关的重复Bug信息”图形可视化结果
文字列表检索结果、图形可视化检索结果分别如图6和图7所示。图6列出了IndexReader类和具有重复Bug信息的两个缺陷报告,其中蓝色高亮对应的是IndexReader类,红色高亮表示其类型是Bug,绿色高亮展示了检索结果Issue与“IndexReader”的相关性。图7边上LEX_LEVEL_REFER是由代码元素关联建立的“代码引用关系”,DUPLICATE表示缺陷报告之间的“重复关系”。
7 总结与未来工作
7.1 本文工作总结
本文的主要工作包括:
(1)提出了软件知识实体的提取原则与方法,并分别针对4种不同类型的软件资源提取了软件知识实体。
(2)提出了软件知识实体之间关联关系构建的方法,分析了同一类型软件资源中软件知识实体之间关联关系的类型及特点,给出了同一类型软件资源中的软件知识实体关联关系的构建方法;接着以代码结构为核心,引用关联和用户关联为辅助的方式,建立了不同类型软件资源中软件知识实体之间的关联关系。
(3)设计了两种软件知识检索机制,并以文字列表和图形可视化相结合的方式展现检索结果。本文利用Neo4j的声明式查询语言Cypher提供形式化检索,并通过开发Neo4j的服务器扩展程序提供了Cypher补全工具,以帮助用户方便地进行形式化检索;利用ElasticSearch对软件知识中的文本信息建立索引,并提供文本检索功能。
(4)设计了软件知识图谱构建框架,该框架由软件知识提取模块、软件知识融合模块、软件知识图谱存储管理模块与软件知识检索模块构成,分别提供软件知识实体提取、软件知识实体之间的关联关系建立、软件知识图融合、软件知识图谱存储以及基于软件知识图谱检索等功能。
本文设计并实现了一个面向开源软件项目的软件知识图谱构建工具,并以Lucene-Core为例,通过实例展示了本文工作的有效性和合理性。
7.2 未来工作展望
本文工作还需进一步的改进,主要包括:
(1)融合形式化检索和文本检索的接口。
(2)改善形式化检索的图形化展示。改善基于两个方面,一方面是检索结点之间的关联关系补全,另一方面是结点扩展。
(3)提供面向开发人员的API接口。
(4)研究软件知识图谱的内容更新机制。
(5)考虑软件知识的版本信息。
[1]Yang Fuqing,Mei Hong,Li Keqin.Software reuse and software component technology[J].Acta Electronica Sinica,1999, 27(2):68-75.
[2]Yang Fuqing.Software reuse and its correlated techniques[J]. Computer Science,1999,26(5):1-4.
[3]Brown A W,Booch G.Reusing open-source software and practices:the impact of open-source on commercial vendors [C]//LNCS 2319:Proceedings of the 7th International Conference on Software Reuse,Austin,USA,Apr 15-19,2002. Berlin,Heidelberg:Springer,2002:123-136.
[4]Čubranić D,Murphy G C.Hipikat:recommending pertinent software development artifacts[C]//Proceedings of the 25th International Conference on Software Engineering,Portland,USA,May 3-10,2003.Washington:IEEE Computer Society,2003:408-418.
[5]Gopinath G,Sagayaraj S.To generate the ontology from Java source code[J].International Journal of Advanced Computer Science andApplications,2011,2(2):111-116.
[6]McMillan C,Grechanik M,Poshyvanyk D,et al.Portfolio: finding relevant functions and their usage[C]//Proceedings of the 33rd International Conference on Software Engineering, Honolulu,USA,May 21-28,2011.New York:ACM,2011: 111-120.
[7]Lehmann J,Isele R,Jakob M,et al.DBpedia—a large-scale, multilingual knowledge base extracted from Wikipedia[J]. Semantic Web,2015,6(2):167-195.
[8]Bordes A,Gabrilovich E.Constructing and mining Webscale knowledge graphs:WWW 2015 tutorial[C]//Proceedings of the 24th International Conference on World Wide Web,Florence,Italy,May 18-22,2015.New York:ACM, 2015:1523.
[9]Dong X L,Gabrilovich E,Heitz G,et al.From data fusion to knowledge fusion[J].Proceedings of the VLDB Endowment,2014,7(10):881-892.
[10]Dong X,Gabrilovich E,Heitz G,et al.Knowledge vault:a Web-scale approach to probabilistic knowledge fusion[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,Aug 24-27,2014.New York:ACM,2014:601-610.
[11]Dong X L,Gabrilovich E,Murphy K,et al.Knowledgebased trust:estimating the trustworthiness of Web sources[J]. Proceedings of the VLDB Endowment,2015,8(9):938-949.
[12]West R,Gabrilovich E,Murphy K,et al.Knowledge base completion via search-based question answering[C]//Proceedings of the 23rd International Conference on World Wide Web,Seoul,Korea,Apr 7-11,2014.New York:ACM, 2014:515-526.
[13]Zhang Jing,Tang Jie.The focus of the next generation of search engine:knowledge map[J].The Chinese Society of Computer Communication,2013,9(4):64-88.
[14]Bacchelli A,Lanza M,Robbes R.Linking e-mails and source code artifacts[C]//Proceedings of the 32nd International Conference on Software Engineering,Cape Town,South Africa,May 1-8,2010.New York:ACM,2010:375-384.
[15]Dagenais B,Robillard M P.Recovering traceability links between an API and its learning resources[C]//Proceedings of the 34th International Conference on Software Engineering, Zurich,Switzerland,Jun 2-9,2012.Piscataway,USA:IEEE, 2012:47-57.
[16]Robinson I,Webber J.Eifrem E.Graph databases[M].Sebastopol,USA:O'Reilly Media Press,2013:26-27.
[17]DB-engines ranking of graph DBMS[EB/OL].(2016-04) [2016-06-27].http://db-engines.com/en/ranking/graph+dbms.
附中文参考文献:
[1]杨芙清,梅宏,李克勤.软件复用与软件构件技术[J].电子学报,1999,27(2):68-75.
[2]杨芙清.软件复用及相关技术[J].计算机科学,1999,26 (5):1-4.
[13]张静,唐杰.下一代搜索引擎的焦点:知识图谱[J].中国计算机学会通讯,2013,9(4):64-88.

LI Wenpeng was born in 1993.He is an M.S.candidate at Peking University.His research interest is software engineering.
李文鹏(1993—),男,山东莱芜人,北京大学硕士研究生,主要研究领域为软件工程。

WANG Jianbin was born in 1991.He is an M.S.candidate at Peking University.His research interest is software engineering.
王建彬(1991—),男,河北邯郸人,北京大学硕士研究生,主要研究领域为软件工程。

LIN Zeqi was born in 1992.He is a Ph.D.candidate at Peking University.His research interest includes software engineering,software reuse,knowledge engineering and data mining,etc.
林泽琦(1992—),男,福建莆田人,北京大学博士研究生,主要研究领域为软件工程,软件复用,知识工程,数据挖掘等。

赵俊峰(1974—),女,福建泉州人,2005年于北京大学软件与理论专业获得博士学位,现为北京大学信息科学技术学院副教授,CCF高级会员,主要研究领域为软件工程,知识工程,服务计算等。发表学术论文30余篇,主持或承担过国家自然科学基金项目、国家863项目、北京重大科技成果转换项目等近20项。

ZOU Yanzhen was born in 1976.She received the Ph.D.degree in software and software theory from Peking University in 2010.Now she is an associate professor at Peking University,and the member of CCF.Her research interests include software engineering,software reuse and information retrieval,etc.
邹艳珍(1976—),女,辽宁盖州人,2010年于北京大学软件与理论专业获得博士学位,现为北京大学信息科学技术学院副教授,CCF会员,主要研究领域为软件工程,软件复用,信息检索等。

XIE Bing was born in 1970.He received the Ph.D.degree from School of Computer,National University of Defense Technology in 1998.Now he is a professor and Ph.D.supervisor at Peking University,and the senior member of CCF.His research interests include software engineering and formal methods,etc.
谢冰(1970—),男,湖南湘潭人,1998年于国防科技大学计算机学院获得博士学位,现为北京大学信息科学技术学院软件所教授、博士生导师,CCF高级会员,主要研究领域为软件工程,形式化方法等。发表学术论文50余篇,主持国家863重点项目多项,获国家科技进步二等奖。
Software Knowledge Graph Building Method for Open Source Project*
LI Wenpeng1,2,3,WANG Jianbin1,2,3,LIN Zeqi1,2,3,ZHAO Junfeng1,2,3+,ZOU Yanzhen1,2,3,XIE Bing1,2,3
1.School of Electronics Engineering and Computer Science,Peking University,Beijing 100871,China
2.Key Laboratory of High Confidence Software Technologies,Ministry of Education,Beijing 100871,China
3.Peking University Information Technology Institute(Tianjin Binhai),Tianjin 300450,China
+Corresponding author:E-mail:zhaojf@pku.edu.cn
Software reuse is a solution to reduce the duplication of efforts during software development and improve the efficiency and quality of the process.Open source projects’source code,mailing lists,issue reports,Q&A documents and other software resources contain software knowledge with complex structure and rich semantic association on a large scale.How to obtain and organize software knowledge and retrieve it effectively in the process of software reuse have become urgent problems.In order to solve these problems,this paper constructs software knowledge graph,whose goal is to organize and manage the structural knowledge of a software project,and provides software knowledge graph based knowledge retrieval.The contributions of this paper are as follows:Providing the extraction principles and methods of software knowledge entities,and extracting software knowledge entities from four different kinds of software resources respectively;Providing the methods of building the relationships between software knowledge entities;Providing two software knowledge retrieval mechanisms,and displaying the retrievalresults by the combination of word list and graph visualization;Designing the implementation framework of software knowledge graph.On the basic of the work above,this paper designs and implements a software knowledge graph building tool for open source project.Instances prove that software knowledge graph can help developers to better retrieve and use knowledge.
software reuse;open source software;software knowledge graph;graph database
eng was born in 1974.She
the Ph.D.degree in software and software theory from Peking University in 2005.Now she is an associate professor at Peking University,and the senior member of CCF.Her research interests include software engineering,knowledge engineering and service computing,etc.
A
TP301
关联是指建立一个软件知识实体与其引用的软件知识实体之间的关联关系。如果一个软件知识实体包含的信息中包含另一个软件知识实体对应的超链接或全局唯一的标识符,则在该软件知识实体与包含的软件知识实体之间建立一条语义关联关系。本文称这种语义关联关系为“引用”关系。建立引用关联的步骤如下:
*The National Natural Science Foundation of China under Grant No.61472007(国家自然科学基金);the National Science Fund for Distinguished Young Scholars of China under Grant No.61525201(国家杰出青年科学基金).
Received 2016-08,Accepted 2016-10.
CNKI网络优先出版:2016-10-31,http://www.cnki.net/kcms/detail/11.5602.TP.20161031.1652.022.html
