基于大规模网络语料的藏文音节拼写错误统计与分析
2017-06-01刘汇丹洪锦玲诺明花
刘汇丹,洪锦玲,诺明花,吴 健
(中国科学院 软件研究所,北京100190)
基于大规模网络语料的藏文音节拼写错误统计与分析
刘汇丹,洪锦玲,诺明花,吴 健
(中国科学院 软件研究所,北京100190)
针对从互联网获取的一份包含19万藏文网页,总计427万句、9 328万音节字的藏文文本语料,该文按照预定的规则对其中的藏文音节拼写错误情况进行了统计与分析。数据显示,在语料中出现的共计20 743个藏文音节中,含有拼写错误的音节共有9 700个,占藏文音节总数的46.762 8%,错误音节在语料中共出现27 427次,仅占0.030 8%,说明这份语料的文本质量是相当高的。文中还详细统计了各种不同表现形式的错误音节所占比重,并分析了导致拼写错误的四个主要原因: 一是输入了多余的元音符号;二是音节点或句尾空格缺失;三是同一字丁/字符存在多种表达形式;四是错误地使用了相似字符。
藏文拼写检查;拼写检查;语料;统计;藏文信息处理;中文信息处理
1 引言
文本校对是自然语言处理的主要应用领域之一,近些年来,已有学者在藏文文本校对或拼写检查方面做了一些研究,这些研究大多针对实现藏文文本校对工具,以及为实现校对工具而构建的藏文音节规则相关知识库等方面。针对真实文本语料库的藏文拼写错误情况的统计分析工作鲜有报道。本文将通过对大规模网络藏文文本语料库中拼写错误情况进行统计分析,一方面考察真实文本中藏文拼写错误的严重程度,为藏文文本校对的研究提供依据;另一方面考察网络语料的质量,判断将网络藏文文本作为构建高质量藏文文本语料库的可靠性。
本文接下来的部分首先介绍相关领域研究现状,其次介绍大规模网络藏文文本获取的方法及利用这种方法获取的语料情况,然后对这份语料中藏文音节的拼写错误情况进行统计与分析,最后对全文进行总结。
2 研究现状
有关藏文文本校对方面的研究可追溯到20世纪。1998年,扎西次仁归纳总结了藏文的拼写规则和虚词使用法则,根据藏文的拼写规则、虚词使用法则、音节库和词表,设计并开发了一个藏文拼写检查系统,并分析了由实词虚词兼类、词语组合型切分歧义等导致的难点问题[1]。之后,王维兰等将藏文自动校对应用于藏文文字识别,对单字进行校正[2]。才让卓玛提出了利用词语搭配关系表、语法规则库进行校对的方法[3],并对藏文语序错误、标点使用错误、词语搭配错误等情况进行了举例分析[4]。刘文香也对藏语音节的搭配规则等做了研究,创建了音节搭配规则知识库,探索了音节查错校对的原理、关键技术及可行的实现方法[5]。随后提出了一种将分词词表模式匹配、二元词词邻接矩阵和词间音势约束模型三种方法相结合的藏文词校对模型[6],并在Windows 8操作系统平台上实现了基于音节的现代藏文文本校对的试验系统[7]。多杰卓玛对藏文文本中的错误情况进行了分析,将藏文文本的错误形式归纳为音节错误、缺字和加字的错误、输入错误、人名错误、地名错误、江河名错误、知识性错误等类别,并提出了利用以字丁为单位的N元文法模型判断藏文音节是否错误的方法[8]。关白回顾了现代藏文自动校对的研究现状[9],分析了藏文音节字中的错误类型,并针对藏文音节字的特点,通过音节字预处理、字表匹配、混淆集匹配、二元接续关系、最小编辑距离法等方法对现代藏文音节字的自动校对进行了详细论述[10-11]。安见才让提出了一种根据构字规则进行藏字校对的方法,实验表明,在一段约130个字符的文本中,系统成功检测出了其中的六处错误[12]。珠杰等人构建了现代藏文音节规则库,并分析了其在拼写检查等方面的应用[13],在对实际文本的测试中发现该模型还需要增加对藏文数字、符号、特殊音节、梵音转写音节的特殊处理。洪锦玲等人综合藏文分词、音节拼写、格助词规则等多种藏文特性,提出了一种藏文词语拼写检查的方法,并提出了根据错误词语与词库词语的编辑距离给出纠错建议的方法,并将该方法在开源办公套件LibreOffice 中进行了实现[14]。陈小莹等人设计实现了一个包括藏文文本规范化处理模块、音节切分模块、黏着语的分离与还原模块和音节校对模块四个模块的藏文音节拼写自动校对系统[15]。
上述研究大多针对实现藏文文本校对工具及藏文音节规则等相关知识库的构建方面,只有多杰卓玛、关白等对藏文拼写错误情况进行了归纳,但也仅限于对个别情况的举例说明。针对真实文本语料库的藏文拼写错误情况的统计分析工作还未见有报道。本文将通过对大规模网络藏文文本语料库中拼写错误情况进行统计分析,一方面考察真实文本中藏文拼写错误的严重程度,为藏文文本校对的研究提供依据;另一方面考察网络语料的质量,确定将网络藏文文本作为构建高质量藏文文本语料库的可靠性。
3 语料获取与处理
本节介绍大规模藏文网络文本的获取、音节切分方法和音节拼写错误的判别依据等方面的内容。
3.1 语料来源
根据我们之前对互联网藏文文本资源分布情况的考察,我们选择了八个新闻广播类的藏文网站作为文本语料的来源,这八个网站的基本信息如表 1所示。八个网站中,中国西藏新闻网和新华网西藏频道藏文版使用国家标准藏文编码字符集扩充集,人民网藏文版使用同元编码,这三个网站的藏文文本需要做编码转换。其它五个网站均使用国际标准Unicode藏文基本集(小字符集)方案。在进行后续处理之前,我们将获取的语料统一转换为国家标准藏文编码字符集基本集形式(关于藏文编码转换技术请参考文献[16-17])。编码转换过程使用了与“藏码通”相同的编码对照表和转换算法[17]。“藏码通”软件在民族出版社、中国社科院民族所、西藏大学、西藏编译局等单位使用近十年,并根据用户反馈情况对编码对照表进行了反复修改,因此,转换正确率是可以保证的。同时,我们对语料来源所属的网站频道进行了限制,并通过网页文种识别限定只取藏文网页,并只抽取其中的标题、正文等关键信息。以上可以最大限度地避免语料因编码转换导致的问题。
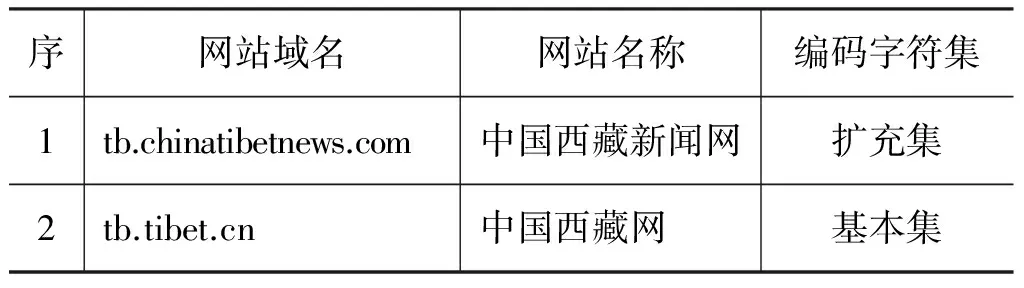
表1 八个新闻广播类藏文网站的基本信息
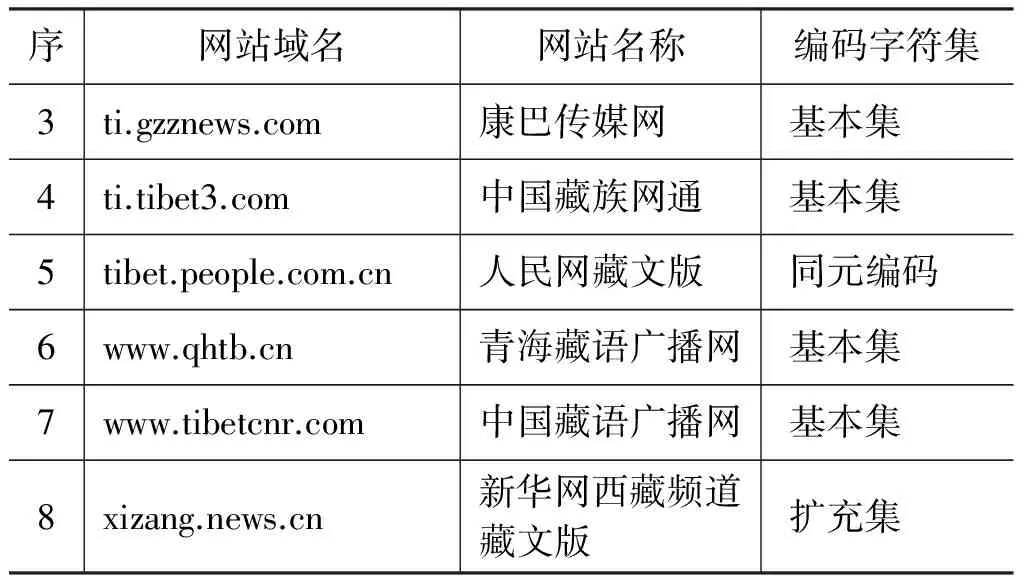
续表
3.2 语料获取方法
在本文中,我们采用基于正则表达式的方法从藏文网页中抽取文章主题相关的信息。我们通过分析各个网站的页面布局结构来抽取网页模板,根据之前相关的研究,分析藏文网页的板式结构,可以发现文章标题、作者、发布时间、文章正文等信息块与其他信息块之间的分隔标志,甚至可以利用HTML源文件中的一些注释信息进行抽取[18]。可以据此构造模板提取藏文篇章文本,举例如下:
• 中国西藏新闻网的页面模板为:
.*【文章正文】.*
• 中国西藏网的页面模板为:
3.3 音节切分方法
对藏文文本进行音节切分主要依据以下切分规则。
• 音节点作为音节分隔标记,切分之后附着在左边(前边)音节的结尾;
• 藏文数字和阿拉伯数字视为音节分隔标记,切分之后分别视同藏文音节参与数据统计;
• 藏文标点符号、英文标点符号和汉语标点符号视为音节分隔标记,切分之后分别视同藏文音节参与数据统计;
• 连续的英文字母视为音节分隔标记,切分之后视同藏文音节参与数据统计;
• 连续的汉字视为音节分隔标记,切分之后视同藏文音节参与数据统计。
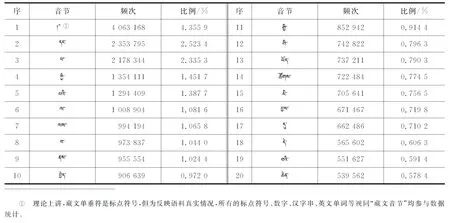
根据以上规则对获取到的网络藏文文本进行切分之后,可以统计各个藏文音节出现的频次。在上述语料中,出现频率最高的部分藏文音节如表2所示。
表2 网络语料中的藏文高频音节表
3.4 语料规模
使用上述方法获取网络藏文文本语料,并进行音节切分,统计数据显示,共计19万藏文网页,语料总计427万句、9 328万音节字(含藏文数字、汉字、英文字母、各种标点符号等)。详细的统计数字见表3。

表3 获取的网络藏文文本语料的规模
4 拼写错误的统计与分析
4.1 藏文音节拼写错误的判别依据
在藏文音节拼写检查的研究中,大家常用的方法是根据藏文文法中基字、前加字、上加字、下加字、元音、后加字和再后加字之间的约束关系构造藏文音节规则库来判断音节的合法性,然而,由于梵音转写和外来词音译的存在,采用这种方法构建的规则库总是不能完全覆盖真实文本中所有的情况。因此,在本文中,我们根据传统藏文文法构造一些规则来判别音节是否存在拼写错误,这些规则主要包括:
• 包含多个紧缩标志的音节视为拼写错误;
• 紧缩标志出现在第四字丁或更靠后位置的音节视为拼写错误;
• 包含五个或更多字丁的音节视为拼写错误;
• 包含在国家标准藏文基本集、扩充集A和扩充集B以外字丁的音节视为拼写错误。
• 前加字、上加字、基字、下加字、后加字和再后加字之间搭配不符合藏文文法约束关系的视为拼写错误;

为确保上述规则包容梵音转写和外来词音译形成的音节,达到对真实语料形成完全覆盖的目的,我们的检测规则中充分考虑了梵音转写和外来词音译的情况。由于约束关系检测方法不能保证百分之百的正确率,我们对被该规则判断为存在拼写错误的情况进行了人工确认。
4.2 对拼写错误的统计与分析
本文所用语料中,共有20 743个藏文音节,总出现频次89 059 463次,占语料总量的95.475 2%。藏文数字共出现130 808次,占语料总量的0.140 2%,两项合计占比95.615 4%,语料中另外4.384 6%是其他文种的字符串,其各自出现频次和比例如表4所示。
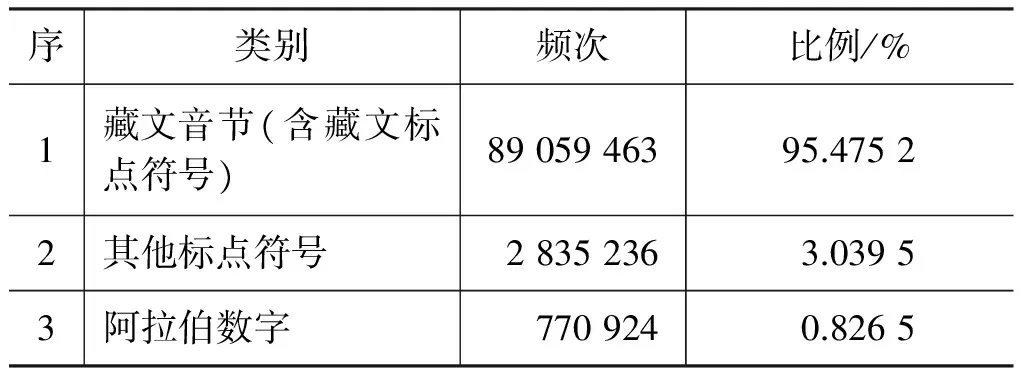
表4 语料中各种不同成分的频次和比例

续表
根据前述规则,对语料中出现的所有藏文音节进行拼写检查,获得的统计数据如表5所示。可以看出,在这些包含拼写错误的音节中,大部分具有两个或者两个以上的表现形式,这主要是由于拼写错误判别规则之间并不是严格互斥的。从表5中可以看出,在本文所用语料中,紧缩标志位置错误也同时意味着紧缩标志太多和元音太多,而紧缩标志太多,大部分情况下也意味着元音太多。在表5的前十行显示,很多实际上正确的音节,被各种规则判断为存在拼写错误,最终是靠人工判断为正确的,这说明传统藏文文法并没有覆盖实际文本中所有的情况。

表5 藏文音节拼写错误情况总表

续表
表6列出了各种不同类型的拼写错误音节的数量及其在语料中的比例。在所有的藏文音节中,拼写正确的藏文音节共有11 043个,占53.237 2%,共出现89 032 036次,占99.969 2%。其中,含有前述四个紧缩标志的音节共有1 421个,占6.850 5%,出现总次数为4 356 795,占4.892 0%。含有拼写错误的藏文音节共有9 700个,占46.762 8%,在语料中共出现27 427次,占0.030 8%。错误形式最多的是约束关系类错误,共有9 365个音节,占比45.147 8%,在语料中出现频次累计23 726次,占比0.026 6%。其次是元音太多类错误,共有5 014个音节,占比24.172 0%,在语料中出现频次累计11 830次,占比0.013 3%。再次是字丁太多类错误,共有2 565个音节,占比12.365 6%,在语料中出现频次累计4 451次,占比0.005 0%。包含非法字丁的音节共有1 359个,占比6.551 6%,在语料中共出现7 418次,占比0.008 3%。紧缩标志太多的音节共有21个,占比0.101 2%,出现频次为57,占比0.000 1%。紧缩标志位置错误的音节共有11个,占比0.053 0%,出现频次为16,占比不足0.000 1%。
表7和图1显示了不同错误形式在所有出错音节中的比例。

表6 藏文拼写错误类型及其在语料中的比例

表7 藏文拼写错误类型及其比重

续表
在所有的出错音节中,表现为约束关系错误的音节数量占比和频次占比分别达到了96.546 4%和86.506 0%,占据了出错音节的绝大部分。部分典型的拼写错误音节如表8所示。这些错误中大部分都是因音节点或句尾空格缺失导致。
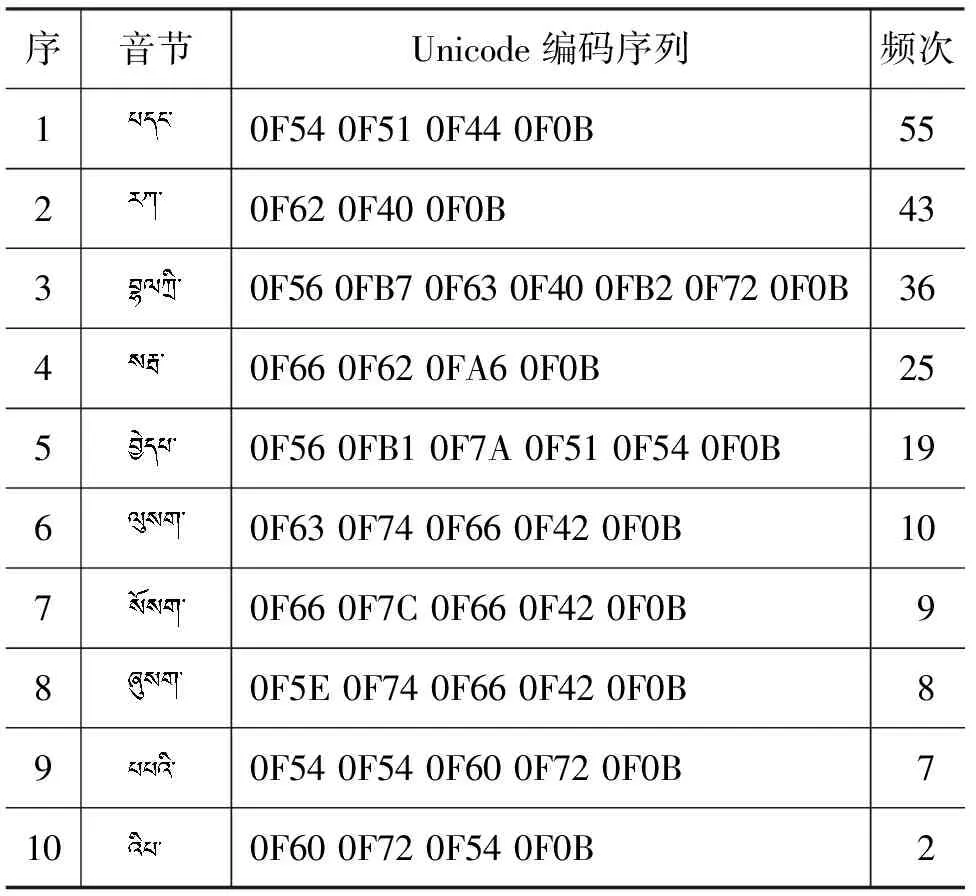
表8 约束关系错误音节典型实例
在所有的出错音节中,表现为元音太多的音节数量占比和频次占比分别达到了51.690 7%和43.132 7%,部分典型的拼写错误音节如表9所示。

表9 元音太多的错误音节典型实例
表现为字丁太多的音节数量占比和频次占比分别达到了26.443 3%和16.228 5%。部分典型的拼写错误音节如表10所示。这些错误中,几乎全部是因音节点和句尾空格缺失导致。

表10 字丁太多的错误音节典型实例


表11 含有非法字丁的错误音节典型实例

续表
含有多个紧缩标志的音节数量占比和频次占比分别达到了0.216 5%和0.207 8%。部分典型的拼写错误音节如表12所示。这部分错误基本都是因为音节点缺失导致。

表12 含多个紧缩标志的错误音节典型实例
紧缩标志出现在第四个字丁或者更靠后位置的错误音节数量占比和频次占比分别为0.113 4%和0.058 3%。部分典型的拼写错误音节如表13所示。这部分错误基本都是因为音节点和句尾空格缺失导致。

表13 紧缩标志位置错误的音节典型实例
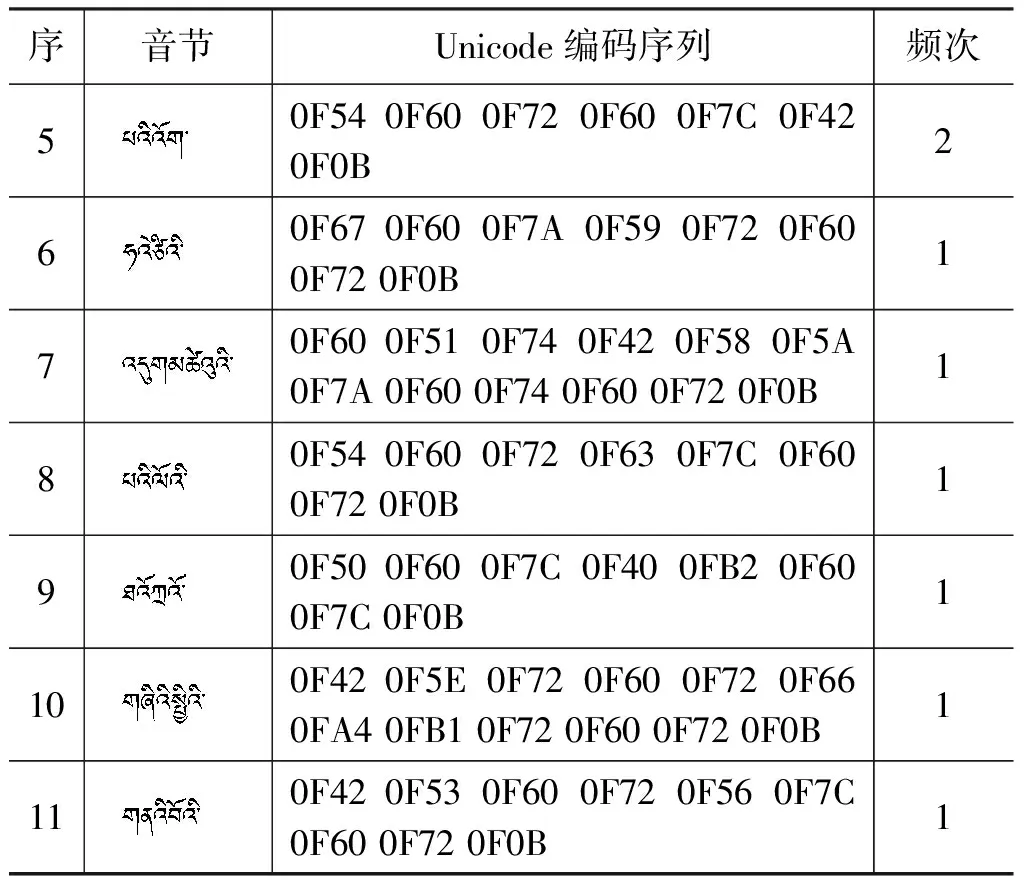
续表
综合上述拼写错误的各种情况,导致拼写错误的原因主要包括四个方面: 一是输入了多余的元音符号;二是音节点、单垂符或句尾空格缺失;三是同一字丁/字符存在多种表达形式;四是使用了错误的相似字符。
5 结束语
在本文中,我们从互联网获取了共计19万藏文网页,进行篇章抽取之后获得了一份总计427万句、9 328万音节字的藏文文本语料,按照预定的规则对其中的拼写错误情况进行了统计与分析。数据显示,在所有20 743个藏文音节中,拼写正确的藏文音节共有11 043个,占53.237 2%,在语料中共出现89 032 036次,占99.969 2%。含有拼写错误的藏文音节共有9 700个,占46.762 8%,在语料中共出现27 427次,占0.030 8%,这说明这份语料的文本质量是相当高的。导致拼写错误的原因主要包括四个方面: 一是输入了多余的元音符号;二是音节点和句尾空格缺失;三是同一字丁/字符存在多种表达形式;四是使用了错误的相似字符。
[1] 扎西次仁.一个藏文拼写检查系统的设计[C].1998中文信息处理国际会议论文集.1998: 371-376.
[2] 王维兰,丁晓青,戴玉刚等.藏文识别后处理研究[J].术语标准化与信息技术,2002,(2): 30-34.DOI: 10.3969/j.issn.1007-2489.2002.02.008.
[3] 才让卓玛.藏文字自动校对系统初探[C].第十届全国少数民族语言文字信息处理学术研讨会论文集.2005: 292-294.
[4] 才让卓玛,才智杰.藏文文本自动校对系统开发研究[J].西北民族大学学报(自然科学版),2009,30(1): 25 -28.DOI: 10.3969/j.issn.1009-2102.2009.01.007.
[5] 刘文香.藏文音节校对模型建设研究[J].西北民族大学学报(自然科学版),2009,30(2): 13-16,32. DOI: 10.3969/j.issn.1009-2102.2009.02.004.
[6] 刘文香.藏文文本词校对模型研究[J].西藏大学学报(自然科学版),2009,24(2): 70-74.
[7] 刘文香.现代藏文文本校对设计方案研究[J].西藏大学学报(自然科学版),2012,(2): 66-69.
[8] 多杰卓玛.N元模型在藏文文本局部查错中的应用研究[J].计算机工程与科学,2009,31(4): 117-119,123. DOI: 10.3969/j.issn.1007-130X.2009.04.035.
[9] 关白,洛藏,才科扎西等.现代藏文自动校对现状分析[J].西藏科技,2011,(8): 78-80.DOI: 10.3969/ j.issn.1004-3403.2011.08.035.
[10] 关白.自动校对中现代藏文音节字研究[J].西藏大学学报(自然科学版),2011,26(1): 69-75.
[11] 关白,才科扎西.现代藏文音节字自动校对研究[J].计算机工程与应用,2012,48(29): 151-156.DOI: 10. 3778/ j.issn.1002-8331.2012.29.031.
[12] 安见才让.基于分段的藏字校对算法研究[J].中文信息学报,2013,27(2): 58-64.DOI: 10.3969/j.issn.10 03-0077.2013.02.009.
[13] 珠杰,欧珠,格桑多吉等.藏文音节规则库的建立与应用分析[J].中文信息学报,2013,27(2): 103-112.
[14] 洪锦玲,刘汇丹,吴健.一种在办公套件中支持藏文拼写检查的方法[C].第14届中国少数民族语言文字信息处理学术研讨会论文集,2013: 116-122
[15] 陈小莹,艾金勇.藏文音节拼写自动校对系统的设计[J].语文学刊,2014,(5): 31-32.
[16] 刘汇丹,芮建武,吴健等.藏文网页的编码识别与转换[C].中文信息处理前沿进展——中国中文信息学会二十五周年学术会议.2006: 573-580.
[17] 刘汇丹,诺明花,赵维纳等.藏文编码转换软件“藏码通” 的设计与实现[C].第三届全国少数民族青年自然语言信息处理、第二届全国多语言知识库建设联合学术研讨会论文集.2010: 217-221.
[18] 刘汇丹,诺明花,高墨赤等.面向新闻广播网站的藏文文本采集和语料库构建[C].第14届中国少数民族语言文字信息处理学术研讨会论文集,2013: 85-94
[19] 周季文.藏文拼音教材(拉萨音)[M].北京: 民族出版社,1983.
[20] 胡书津.简明藏文文法[M].昆明: 云南民族出版社,2000.
[21] GB16959-1997 信息技术-信息交换用藏文编码字符集——基本集[S]. 中国标准出版社, 1998.
[22] GB/T 20542-2006 信息技术-藏文编码字符集——扩充集A [S]. 北京: 中国标准出版社, 2006.
[23] GB/T 22238-2008 信息技术-藏文编码字符集——扩充集B [S]. 北京: 中国标准出版社, 2008.
[24] ISO/IEC 10646: 2012 Information technology - Universal Coded Character Set (UCS) [S]. International Organization for Standardization, 2012.
[25] The Unicode Standard, Version 6.1 [S]. Mountain View, CA: The Unicode Consortium, ISBN 978-1- 936213-02-3, 2012.
Statistics and Analysis on Spell Errors of Tibetan SyllablesBased on a Large Scale Web Corpus
LIU Huidan, HONG Jinling, NUO Minghua, WU Jian
(Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)
A large scale Tibetan text corpus is built, which includes 4.27 million sentences in 190 thousand documents, totaling 93 million syllables. Some predefined rules are applied to check whether there are spelling errors, detecting altogether 9 700 misspelt syllable types out of the 20 743 types of Tibetan syllables occurred in the corpus (covering 46.762 8%). But at the token level, the corpus has a very high quality, with only 27 427 misspelt syllables, roughly 0.030 8% of the total 93 million syllable tokens. Further analysis shows that there are mainly four causes leading to those spell errors: extra vowel sign(s); absence of syllable delimiter or sentence delimiter; characters which can be written in different forms; similar characters.
Tibetan spell check; spell check; corpus; Tibetan information processing; Chinese information processing

刘汇丹(1982—),博士,副研究员,主要研究领域为操作系统中文信息处理、多语言信息处理。E⁃mail:huidan@iscas.ac.cn洪锦玲(1981—),硕士,工程师,主要研究领域为多语言信息处理。E⁃mail:jinling@iscas.ac.cn诺明花(1981—),博士,助理研究员,主要研究领域为多语言信息处理。E⁃mail:nuominghua@163.com
2014-04-23 定稿日期: 2014-11-21
国家自然科学基金(61202219,61303165);中国科学院信息化专项(XXH12504-1-10);新闻出版重大科技工程(0610-1041BJNF 2328/23)
1003-0077(2017)02-0061-10
TP391
A
