各城市消费水平差异层次聚类及因子分析
2017-05-13凌标灿魏洪霞
凌标灿,魏洪霞
(华北科技学院 研究生院,北京 东燕郊 101601)
各城市消费水平差异层次聚类及因子分析
凌标灿,魏洪霞
(华北科技学院 研究生院,北京 东燕郊 101601)
随着经济的快速发展,我国各城市消费水平存在明显差异,且差异一直在发生变化。消费水平涉及到多个因素,为了便于比较,使分析简洁直观,本文先后采用聚类分析和因子分析的方法进行研究。本文首先介绍聚类分析和因子分析的基本知识,其次将分析数据全国各地区的人均消费支出录入到spss,进行聚类分析,将31个地区分为三类;再次进行因子分析对其消费水平进行排名。最后对运行结果进行分析。分析各城市消费水平差异的主要影响因素以及差异的变化趋势。
人均消费水平;聚类分析;因子分析
1 聚类及因子分析理论
聚类分析的实质是建立一种分类方法,它能够将一批样本数据按照他们在性质上的亲密程度在没有先验知识的情况下自动进行分类。聚类分析包括对对个案的聚类分析和对变量的聚类分析。聚类分析的方法,主要有两种,一种是“快速聚类分析方法”,另一种是“层次聚类分析方法”[1]。
层次聚类分析是根据观察值或变量之间的亲疏程度,将最相似的对象结合在一起,以逐次聚合的方式,它将观察值分类,直到最后所有样本都聚成一类。层次聚类分析有两种形式,一种是对样本(个案)进行分类,称为Q型聚类,它使具有共同特点的样本聚齐在一起,以便对不同类的样本进行分析;另一种是对研究对象的观察变量进行分类,称为R型聚类。它使具有共同特征的变量聚在一起,以便从不同类中分别选出具有代表性的变量作分析,从而减少分析变量的个数[2]。
本论文采用层次聚类的Q型聚类,对个案进行聚类分析。
因子分析的基本思想是根据相关性大小把原始变量分组,使得同组内的变量之间相关性较高,而不同组的变量间的相关性则较低。每组变量代表一个基本结构,并用一个不可观测的综合变量表示,这个基本结构就称为公共因子[3]。
因子分析模型在形式上和多元回归模型相似,每个观测变量由一组因子的线性组合来表示。设有p观测变量,其可观测随机向量X=(X1,X2,…,Xp)为零均值、单位方差的标准化向量,即均值向量E(X)=0,协方差阵Cov(X)=∑,且协方差阵∑与相关矩阵R相等。因子分析模型的一般表达形式为[4]
X=AF+E
(1)
xi=ai1fi1+ai2fi2+…+aimfum+ei
(2)
因子分析可以分为确定因子载荷,因子旋转及计算因子得分三个步骤。
2 分析资料
本论文分析的资料如下表1,2014年全国各地区人均消费支出情况,根据对此表的分析观察各地区的消费水平差异。

表1 2014年全国居民分地区人均消费支出 单位:元
数据来源国家统计局2015年。
分析资料中有八个消费因子,x1——食品烟酒,x2——衣着,x3——居住,x4——生活用品,x5——交通通信,x6——教育文化娱乐,x7——医疗保健,x8——其他用品及服务。将数据录入到spss。
3 分析过程
3.1 聚类分析
在主菜单栏中选择分析—分类—系统聚类命令,打开对话框,将x1,x2…x8作为变量,因为本论文选择分层聚类中Q型聚类分析的方法,所以在对话框中选择个案,其余为默认值;计划将31个地区分为三类,所以在统计量对话框中选择单一方案,聚类数为3;在绘制对话框中选中树形图,其余为默认值;在方法对话框中,选择组间连接,区间选择平方Euclidean距离;在保存对话框中单一方案聚类数也为3。
3.2 运行结果分析
根据表2,本论文将案例分为三组,第二列表示每个案例所属于的组数。案例1和9即北京和上海属于第一类,消费水平高;案例2,10,11,13,19,即天津,江苏,浙江,福建,广东属于第二类,消费水平相对中等;3,4,5,,6,7,8,12,14,15,16,17,18,20-31,即河北山西,内蒙古,辽宁,吉林,黑龙江,安徽,江西,山东,河南,湖北,湖南,广西,海南,重庆,四川,贵州,云南,西藏,陕西,甘肃,青海,宁夏,新疆属于第三类,消费水平相对较低。
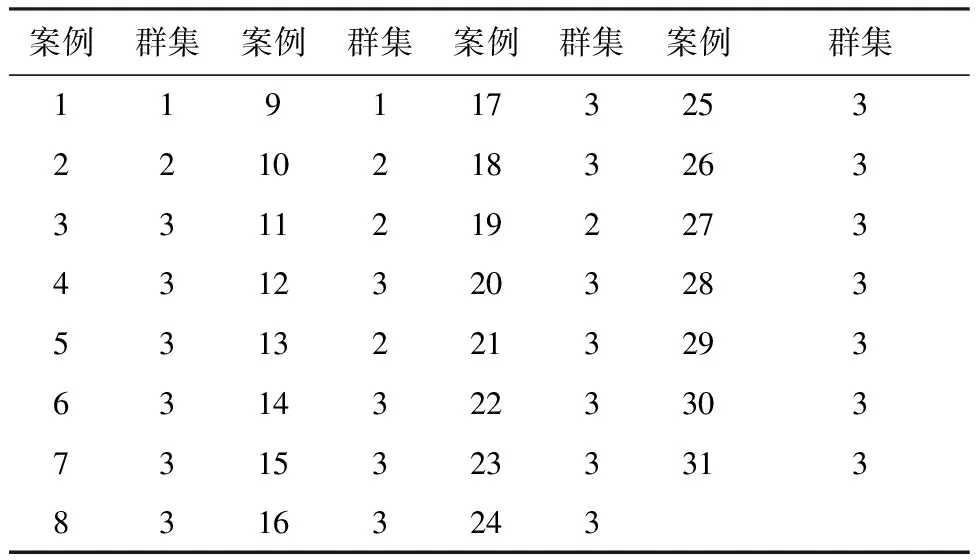
表2 群集成员
图1为分层聚类分析的冰柱图,观察冰柱图从最后一行开始。当聚成30类时,7和8为一类,即吉林和黑龙江为一类,其他自成一类;当聚成25类时,25和28为一类,14和12为一类,18和17为一类,27、8和7 为一类,其他的各为一类。以此类推,直至所有观察个案全部聚成一类。当聚成三类时,如图中的虚线所示,案例1和9即北京和上海属于第一类;案例2,10,11,13,19,即天津,江苏,浙江,福建,广东属于第二类;3,4,5,,6,7,8,12,14,15,16,17,18,20-31,即河北山西,内蒙古,辽宁,吉林,黑龙江,安徽,江西,山东,河南,湖北,湖南,广西,海南,重庆,四川,贵州,云南,西藏,陕西,甘肃,青海,宁夏,新疆属于第三类。同上表结论一致。
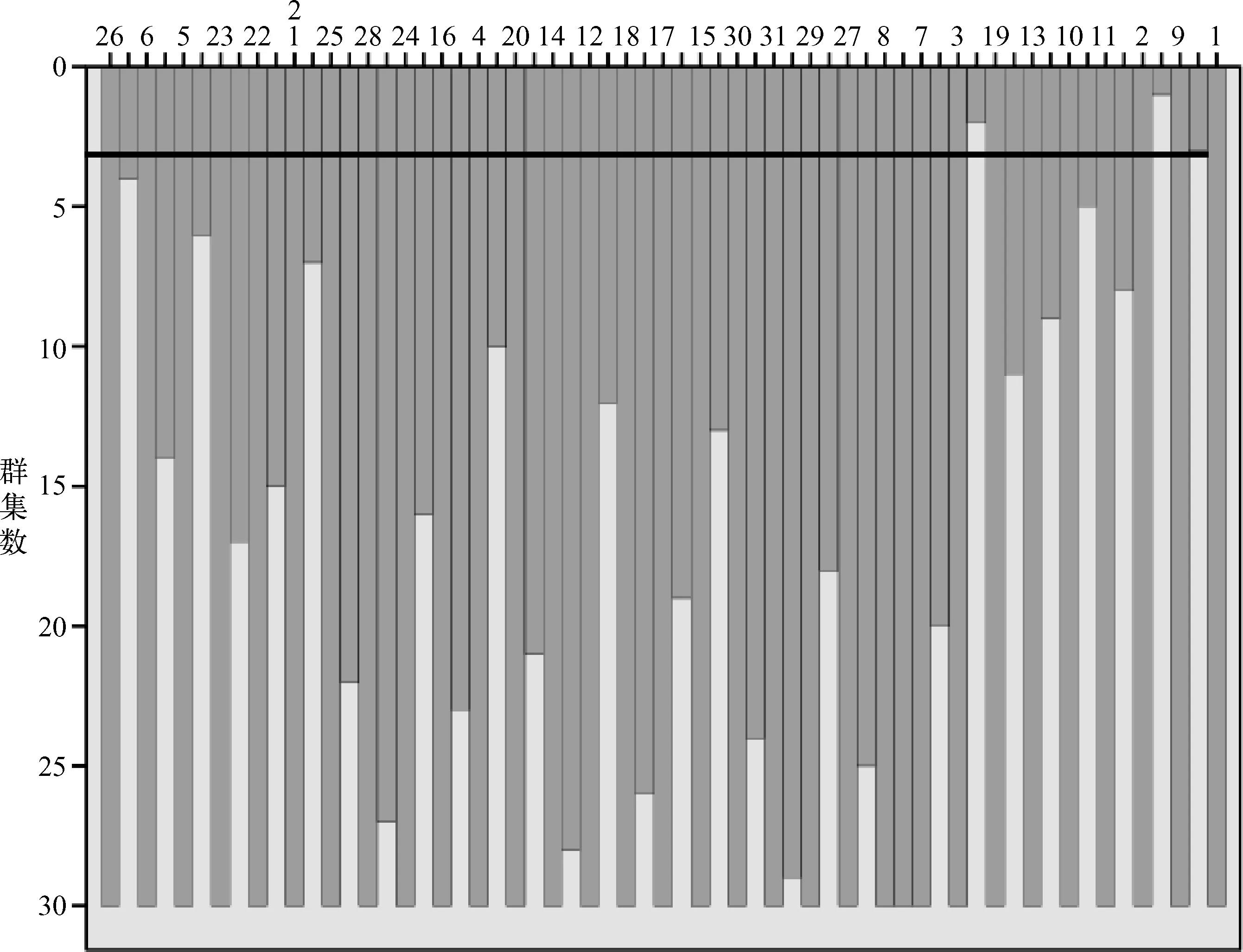
图1 冰柱图
图2树形图以躺倒树的形式展现了聚类分析中的每一次类合并的情况。SPSS自动将各类间的距离映射在0~25之间,并将聚类过程近似地表示在图上[5]。观察树状图,当分为两类时,1和9一类,剩下的为一类。如图2中虚线所示,将其分为三类时,案例1和9即北京和上海属于第一类;案例2,10,11,13,19即天津,江苏,浙江,福建,广东属于第二类;3,4,5, 6,7,8,12,14,15,16,17,18,20-31即河北山西,内蒙古,辽宁,吉林,黑龙江,安徽,江西,山东,河南,湖北,湖南,广西,海南,重庆,四川,贵州,云南,西藏,陕西,甘肃,青海,宁夏,新疆属于第三类。同上结论一致。

图2 树状图
3.3 因子分析
在主菜单栏中选择分析—降维—因子分析命令,打开对话框,将x1,x2...x8作为变量,在描述统计对话框中选择系数,显著性水平,KMO和Bartlett的球形度检验;在抽取对话框中方法选择主成份,选中碎石图,特征值设为0.4,其余为默认值;在旋转对话框中选择最大方差法;在得分对话框中选中保存为变量,显示因子得分系数矩阵。
3.4 运行结果分析
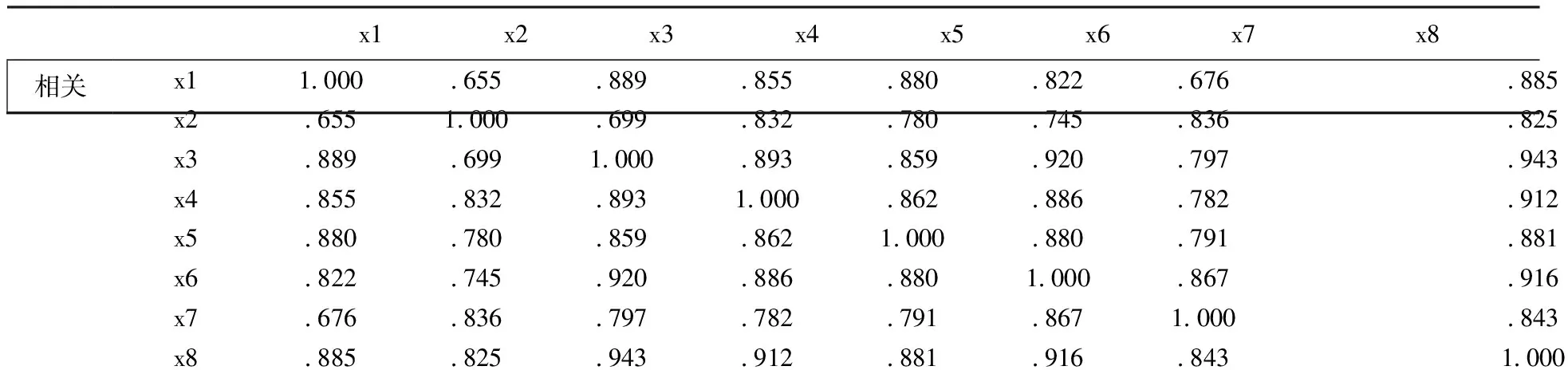
表3 相关矩阵
变量之间的相关系数较大,都在0.655以上,说明这变量存在较为显著的相关性,也说明有进行因子分析的必要。

表4 KMO和Bartlett的检验
KMO(Kaiser-Meyer-Olkin)检验统计量是用于比较变量间简单相关系数和偏相关系数的。
KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。
Kaiser给出了常用的KMO度量标准: 0.9 以上表示非常适合;0.8 表示适合;0.7 表示一般;0.6表示不太适合;0.5 以下表示极不适合。
Bartlett球度检验:巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析[6]。
本论文KMO值文为0.848,所以适合作因子分子;球形度检验显著性值为0,也说明适合作因子分析。

表5 解释的总方差
表5中,合计表示特征值,特征值的大小反应公因子方差贡献,方差的%为特征值占方差的百分数,累计%为特征值占方差百分数的累加值,根据特征值大于0.4的原则提取2个因子的特征值、占方差百分数及其累加值。这两个因子解释的方差占总方差的91.774%,能比较全面的反映所有信息,旋转平方和载入栏为旋转因子矩阵后的2个因子的特征值、占方差百分数及其累加值。
图3为碎石图,横坐标为因子序号,纵坐标为各因子对应的特征值。在图中根据因子序号和对应特征值描点,然后用直线连接,即为碎石图。根据点间连接坡度的陡缓程度,从碎石图中可以比较清楚地看出因子的重要程度。比较陡的直线说明直线断点对应的因子的特征值较大,比较缓的直线则对应较小的特征值差值[7]。从图中可以看出,因子1和2之间连线的坡度相对较陡,说明前2个因子是主要因子,这和表中的结论是一致的。
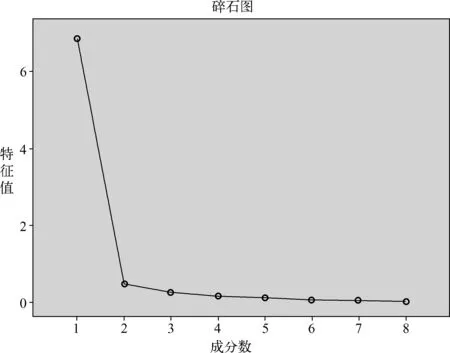
图3 碎石图
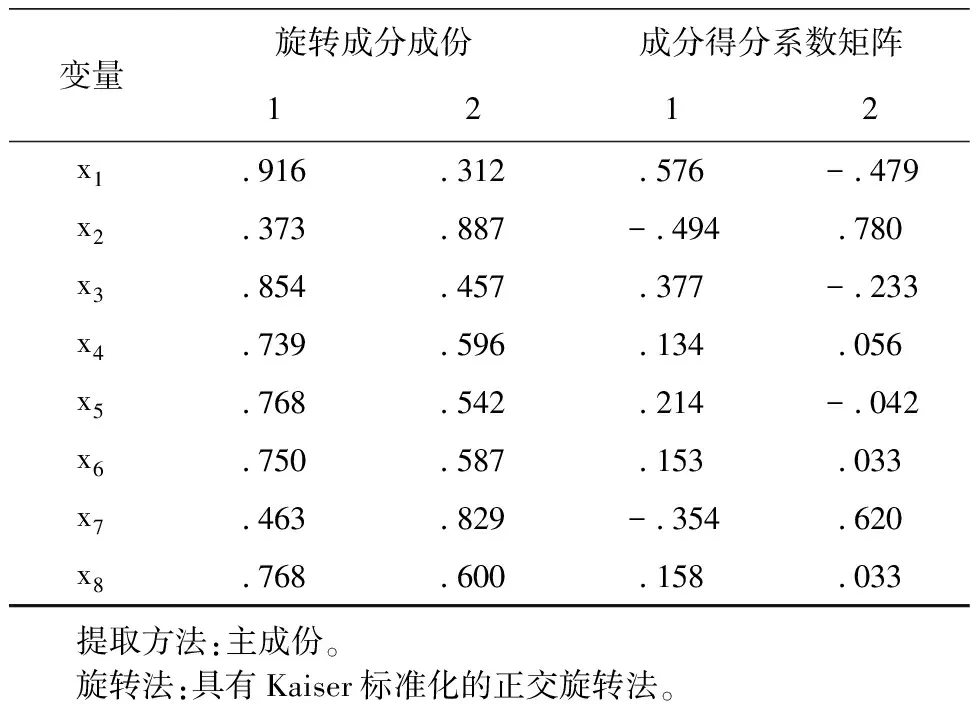
变量旋转成分成份成分得分系数矩阵1212x1916312576-479x2373887-494780x3854457377-233x4739596134056x5768542214-042x6750587153033x7463829-354620x8768600158033提取方法:主成份。旋转法:具有Kaiser标准化的正交旋转法。
旋转后的成份矩阵与成份矩阵相比,更好地对主因子进行解释。旋转后的因子负荷矩阵两端集中,能更好地解释主因子。从表中可以看出,第一个因子与x1,x3关系紧密,第二个因子与x2,x7关系密切。
根据成分得分系数矩阵,
F1=0.576x1-0.494x2+0.377x3+0.134x4+0.153x6-0.354x7+0.158x8
F2=-0.479x1+0.78x2-0.233x3+0.056x4-0.042x5+0.033x6+0.62x7+0.033x8
由此可计算得到公共因子得分F1、F2。
使用因子分析法计算综合得分,以旋转后各公共因子的方差贡献率作为权数,与各公共因子相乘得到综合评价分数。该计算公式为[8]
F=(52.599F1+39.175F2)/91.774
(3)
根据公式(3),算出综合得分,在进行排名,结果如下表7。
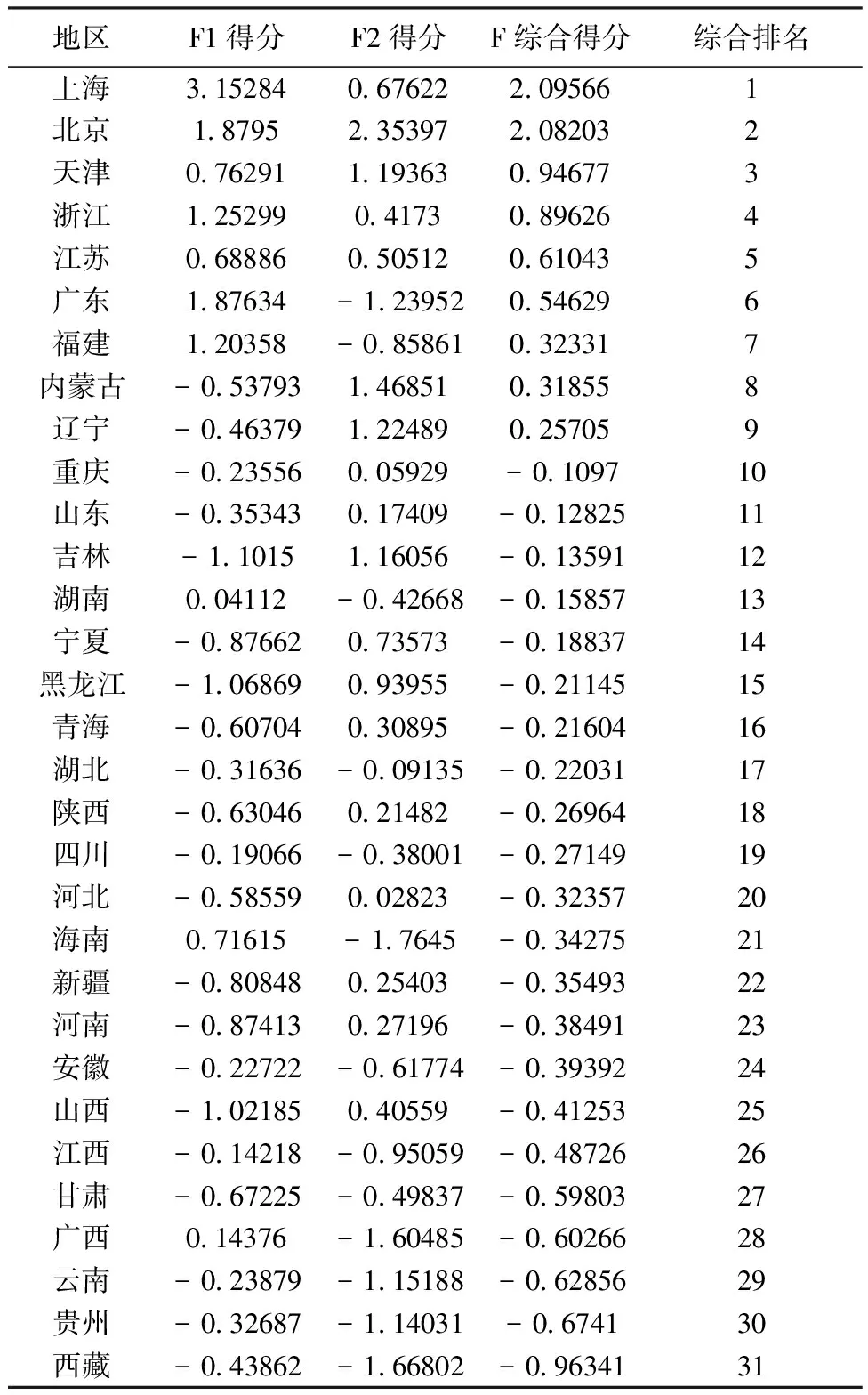
表7 各地区消费水平综合得分和排名
排在前两名的是上海和北京,然后是天津,浙江,江苏,广东,福建,再其次是其他城市。因子分析所得各地区消费水平排名结果与上文聚类分析分类结果一致。但聚类分析只能分成几种类别,而因子分析更加精确,将消费水平进行综合排名,结果清晰一目了然。
4 结论
从因子成分旋转矩阵表6可见,第一公共因子在食品烟酒,居住,生活用品及服务,交通通信,教育文化娱乐和其他几个方面有较大的载荷,我们可以把因子命名为综合消费因子,因为其综合反映了五个消费项目的情况,从载荷系数的绝对值大小来看,我国各地区消费水平差异从大到小为食品烟酒,居住,交通通信,其他用品及服务,教育文化娱乐,生活用品及服务。而从因子载荷系数符号来看,均大于零,说明各城市之间差异趋于上升趋势,说明我国各地区消费水平差异越来越大。
第二公因子在衣着和医疗保健有较大的载荷,我们可以将其命名为衣着及医疗消费因子,衣着消费水平差异较大,医疗保健消费水平差异较小,且差异越来越大。
第一个公因子(综合消费因子)对原始变量的方差贡献率为52.599%,是造成各地区消费水平的差异的主要因素,第二个公因子(衣着及医疗消费因子)对原始变量的方差贡献率为39.175%,是造成各城市消费水平差异的次要因素。
从各地区消费水平综合得分和排名表中可以看出上海,北京,天津,浙江,江苏,广东,福建,内蒙古,辽宁综合得分大于零,其余的城市综合得分小于零,说明上海,北京,天津,浙江,江苏,广东,福建,内蒙古,辽宁消费水平相对较高,其余的城市的消费水平较低。且按排名消费水平呈越来越低的趋势。
从分析结果可以得到,地区消费存在较大的差异,且差异依然呈增长趋势,所以国家应通过相关政策缩小消费差距,而消费水平的差异与收入有很大关系,应避免贫富差距太大,以免对经济及社会造成不良影响。
因此,从长期看,国家各省市的收入差异应呈缩小趋势。
[1] 宋志刚,等. spss16实用教程[M]. 人民邮电出版社,2008:209-210.
[2] 李玉光,等. spss19.0统计分析入门与提高[M]. 北京:清华大学出版社,2014:261-318.
[3] 白云杰. 山西煤矿安全因子分析评价及对策研究[D]. 太原理工大学,2010.
[4] 李圣梅. 因子分析在企业综合经济效益评价中的应用[J]. 企业管理,2005.
[5] 陶晓华. 聚类分析在企业固定资产管理中的应用[D]. 山东师范大学,2008.
[6] 邓菲. 因子分析在我国城镇居民消费结构变动的应用[J]. 科技经济市场,2008:45-46.
[7] 方集. 基于因子分析法的品牌定位测评模型构建及实证研究[D]. 重庆:重庆大学,2005.
[8] 姜永明,等. 基于因子分析法的管道外腐蚀因素分析与评价[J]. 油气储运,2010(8):605-608 .
Hierarchical cluster analysis and factor analysis of difference ofthe consumptive level in different cities
LING Biao-can,WEI Hong-xia
(GraduateSchool,NorthChinaInstituteofScienceandTechnology,Yanjiao, 101601,China)
With the rapid development of economy, there are obvious differences in the consumption level of all cities in China, and the difference is always changing. Consumption level involves many factors, in order to facilitate comparison, so that the analysis is simple and intuitive, this paper has used the method of cluster analysis and factor analysis.This paper first introduces the basic knowledge of cluster analysis and factor analysis, the analysis of the per capita consumption expenditure data of various regions of the country to SPSS, the first cluster analysis, 31 regions will be divided into three categories; then the factor analysis to rank their consumption level. Finally the operation results are analyzed.The main influencing factors and the changing trend of the difference of consumption level.
Per capita consumption level; cluster analysis; factor analysis
2017-01-09
魏洪霞(1993-),女,河北秦皇岛人,华北科技学院在读硕士研究生,研究方向:安全工程。E-mail:386294494@qq.com
F126.1
A
1672-7169(2017)01-0110-07
