基于Spark平台的电信行业用户流失预警
2017-05-06侯兴政
侯兴政
摘要:电信行业用户数据量呈现指数型增加,传统分析挖掘技术已经不能胜任如此庞大的工作。为此,引入大数据平台组件Spark进行大数据分析,进而提升分析挖掘的效率。电信用户的流失造成了运营商经济利润严重下滑,利用随机森林算法构建预警模型,挽留可能流失用户,保证运营商的市场份额。
关键词:流失预警;Spark技术;随机森林算法
中图分类号:TPl81
文献识别码:A
文章编号:1001-828X(2016)036-000369-01
随着通信技术的迅猛发展和手机的普及应用,电信行业应用系统的规模迅速扩大,行业内应用所产生的数据量则呈现爆炸性增长趋势,因此寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。中国移动一个省的电话通联记录数据每月可达0.5PB~1PB,不少专家预测全世界数据量未来10年将增长40余倍,年均增长保持在40%左右。
电信行业的海量数据为数据挖掘技术提供了发挥自己独特作用的机会,目前也已经存在广泛的场景应用,尤其是对于行业客户流失的预警分析。如何减少客户流失,提高客户的挽留率,已经是电信业的当务之急。客户流失预测是基于历史数据,对已流失的用户进行分析,找出这些流失用户的行为特征,对现有用户挖掘预测出可能流失的部分,并有针对性地采取相应的挽流政策。为提高海量数据进行分类预测的运行效率,我们引入大数据平台的spark组件。spark是基于内存计算的大数据并行计算框架,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储层,融入Hadoop的生态系统,并弥补MapReduce的不足。如今,Spark分析技术已经被腾讯、雅虎、淘宝、优酷土豆等大型互联网公司广泛使用。
首先,我们将流失用户定义为上一月分出账缴费,而本月未出账缴费的用户。构建用户流失预警模型,需要结合业务知识进行字段的选取,并加大时间跨度,捕捉更加细节的变化,分析用户的使用情况的细微波动。选取的字段有标识用户唯一性的用户编号、分类类型的标志是否流失、是否为融合业务用户、VIP会员级别编号、在网时长、资费产品、是否参与合约计划、发展渠道的类型、每月费用均值、费用波动、本地语音通话均值、本地语音通话波动情况长途语音通话均值、长途语音通话波动、漫游语音通话均值、漫游通话波动、通话次数均值、通话次数波动、流量使用均值、流量使用波动、缴费金额均值、缴费金额波动、近三月是否有过欠费行为、语音饱和度、流量饱和度;同时,通过不断改变模型的参数,调优分类预测模型效果,以达到最高的精确率。最终,将预测数据分配给客户服务部门,整合销售服务资源,根据客户的需求,设计个性化的营销策略,快速反应,以此达到召回流失客户,挽留流失概率高的客户,实现对客户的守护。
构建模型选用的分类预测算法为随机森林,它是组合分类器(ensemble)的一种,组合分类器作为一种复合模型,由多个分类器组合而成。首先,个体分类器进行投票。然后,组合分类器基于投票返回类标号预测结果,进行最终判别,因此组合分类器往往比个体分类器更加准确。随机森林内的每个个体分类器都是一颗决策树,构造决策树时,每个结点随机选择F个属性作为该结点划分的候选属性。每一棵树都依赖于独立抽样,并在森林中所有树具有相同分布的随机向量的值。分类时,每棵树都进行投票,随机森林返回最终得票数最多的预测类别。对于每次迭代使用有放回抽样,这样使得某些元组在抽取的样本中重复出现或者未出现,这样就保证了树的多样性。随机森林算法对错误和离群点的表现出很好的鲁棒性。随着森林中决策树的数目增长,森林的泛化误差会收敛,这样就不存在过拟合问题。在数据处理过程中,往往会遇到数据不平衡问题,即感兴趣的一类只有少量数据。提高类不平衡数据分类准确率的方法有过抽样和欠抽样。其中,过抽样是复制稀有类的元组,而欠抽样则是随机地删除多数类别。
对于分类模型所构建的结果,我们可以通过几个评价度量指标进行衡量。首先,引入混淆矩阵,真正例TP是正确分类的正元组,真负例TN是正确分类的负元组,假正例FP是错误标记为正元组的负元组,假负例FN是错误标记为负元组的正元组。分类的准确率是被正确分类的元组所占的百分比,但是准确率存在着弊端,在处理不平衡数据时,往往会给出错误的效果,为此,我们使用召回率和精确率:
召回率,也称覆盖率:被正确预测的正例在整个正例的比例;
精确率,也称命中率:被预测为正例中真正是正例的比例;
并且,精确率与召回率是一对逆关系,往往需要降低一个为代价而提高另一个。
实例数据结果如下:
原始数据
训练集:2月份数据总数:244.2082万(不流失=229.7690万;流失=14.5563万)
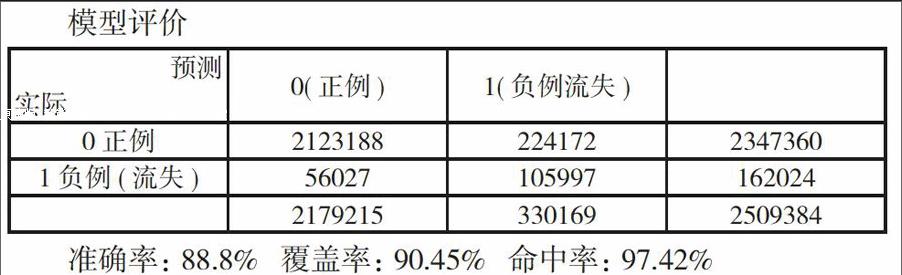
测试集:3月份数据总数:250.9384万(不流失=234.7360万;流失=16.2024万)
准确率:88.8%覆盖率:90.45%命中率:97.42%
结合电信行业的业务知识,应用挖掘理论建立起来一套科学的、完整的客户流失指标体系,有较高的预警效果,希望能将流失预测技术实际应用于电信行业,分析和预测客户的消费行为特征,从而为建立用户离网和欠费预警机制提供客觀的、可靠的数据支撑,为制定更好的客户服务策略提供决策支持。
