基于协同过滤的个性化食材推荐算法研究
2017-05-05林泽聪王玉山甘嘉颖柯懿倍
林泽聪+王玉山+甘嘉颖+柯懿倍

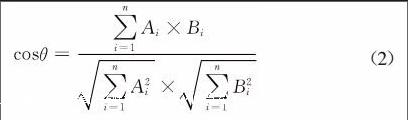
(广东外语外贸大学 信息学院, 广州 510006)
[摘 要] 保持个人的膳食结构合理是保证个人健康的关键因素之一。因此一款个性化的推荐系统显得非常必要。为此研究、设计了一个个性化食材推荐系统,该系统采用基于用户的协同过滤算法,针对用户的饮食习惯进行推荐。
[关键词] 协同过滤算法;推荐系统;饮食推荐
doi : 10 . 3969 / j . issn . 1673 - 0194 . 2017. 07. 071
[中图分类号] TP311 [文献标识码] A [文章编号] 1673 - 0194(2017)07- 0150- 03
1 引 言
1.1 项目背景
人们获取信息的互联网“信息过载”问题越来越严重。不得不花大量时间阅读和分析这些信息。为此个性化推荐系統应运而生,它是对用户的历史数据进行挖掘,建立用户关于兴趣的数学模型,并预测用户将来的行为和喜好、给用户推荐可能需要的服务。
美食与健康是现代社会的热点问题之一,能随时找出自己需要的食材是用户的需求之一。
1.2 个性化推荐发展国内外现状
个性化推荐系统1990年代被提出。准确,高效的推荐算法不仅给用户提供较好的个性化服务,还可以找到用户潜在的消费倾向。但大多数关注的是音乐 [1 ]、微博 [2 ]等应用。针对食材的个性化推荐的研究相对较少。EuiHH 在文献[3 ]中提出了一个基于特征的个性化推荐算法、能根据历史数据向用户推荐商品。Reid A在文献 [4 ]中对基于信任的推荐系统进行了研究。
2 协同过滤推荐算法概述
协同过滤推荐算法分为两类:基于用户的协同过滤算法和基于物品的协同过滤算法。还有基于模型的协同过滤,包括Aspect Model,pLSA,LDA,聚类,SVD,Matrix Factorization等,这种方法训练过程比较长,但是训练完成后,推荐过程比较快。本文将采用协同过滤技术,与饮食数据相结合,设计并实现一种食材推荐算法。
3 根据饮食习惯的食材推荐
收集用户的历史饮食数据,通过协同过滤算法筛选出用户最喜欢或偏好的几种食材进行推荐。这里采用基于用户的协同过滤算法。该算法是通过用户的历史数据发现用户对商品喜欢的内容,并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。将该算法分为3个步骤。
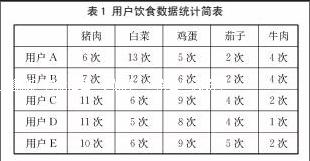
第一步,收集所有用户的历史饮食数据。用户在不同时间段想吃的食材不同,因此我们可以规定数据收集的时间段,收集5个用户一个月的饮食数据,统计如表1所示。
第二步,计算用户距离。方法有欧几里得距离和皮尔逊相关系数等。皮尔逊相关系数计算虽然复杂,但对于评分数据不规范或由于用户使用频率较少,次数相差过大时,能够给出更好的结果。采用皮尔逊相关系数公式(见公式1)。该计算结果是一个在-1和1之间的系数。该系数数值越大,两个用户的相关性就越高。系数为负时,表明用户间无相关。
通过计算5个用户对五种食材的使用次数的相关度系数,可以看到,用户A&B,C&D,C&E和D&E之间相似度较高,如表1所示。
第三步,选取k个近邻,加权并筛选和推荐。
假设我们需要对用户C推荐食材,先对相似度进行排序,发现用户C和D与E的相似度最高。或者说这三个用户是一个群体,拥有相同的偏好。因此可以给C推荐D和E食用过的食材。提取用户D与E食用过的所有食材次数,并用皮尔逊相似度系数进行加权计算,得到一个推荐系数表如表3所示。
用户可能不会每天都记录自己的饮食情况、导致每日的推荐结果都相同。为了得到推荐结果的多样性,采用轮盘赌选择法。把计算得到的结果用饼状图表示(见图1),要做的就是旋转这个轮子,直到轮盘停止,看指针停止在哪一块上,就选中哪个食材。
假设要推荐3种食材,就将轮盘旋转三次。每次选中的食材存表后从轮盘中剔除,为了健康把与该次选中相克的食材剔除,把选中食材相生的食材加权提高,提升被选中的概率,重新生成轮盘。
4 系统测试
设计了一款应用软件,已在360软件、百度软件、应用宝等应用市场上架。采集到了近百名用户在30天内的饮食数据情况。将前20天作为数据集,后10天作为验证集。这里测试根据习惯推荐的准确度,以用户Missyezzy的午餐情况为例,首先统计百名用户20天的饮食数据情况得到数据如表4所示。由于数据量的原因,表4中只列举出部分用户的若干个食材。
接下来计算皮尔逊相似度,这里只列举与用户Missyezzy相关的若干个用户的系数,如表5所示。
我们将k值设为3,提取出与Missyezzy最相近的三个用户,并把该三个用户食用过的所有食材进行加权计算,得到表如表6所示。
接下来采用轮盘法,从中随机选取3种食材,并进行10次重复生成,以模拟后10天的饮食情况,如表7所示。
通过统计Missyezzy用户后10天的实际饮食数据,和推荐得到的10天的饮食数据,生成两个n维向量,通过比较两个的余弦相似性来判断推荐系统的好坏。在这里以Missyezzy为例得到两个向量,一个是实际饮食数据得到的向量,一个是上表得到的向量,如表8所示。
在评估推荐结果的准确性上,采用余弦相似度,又称余弦相似性。是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越趋近于0,他们的方向更加一致。相应的相似度也越高。公式如下:
将上述算法重复若干次以去除偶然性,然后统计了十名用户的余弦相似度的平均值得到表9,推荐结果的准确度达80%。
本文根据用户历史饮食数据,采用基于用户的协同过滤算法,找出与用户有相似爱好的用户数据、生成推荐食材。采用轮盘推荐法,使推荐系统推荐准确、多样。采用余弦相似度对本系统做出了验证。该系统仍有不足之处,如数据量较大时,算法的效率较低、寻找相似用户时容易陷入局部寻找等。
主要参考文献
[1]Lee SK,Cho YH,Kim SH. Collaborative Filtering with Ordinal Scale-Based Implicit Ratings for Mobile Music Recommendations[J]. Information Sciences, 2010,180(11):2142-2155.
[2]Chiu PH,Kao GYM,Lo CC. Personalized Blog Content Recomender System for Mobile Phone Users[J]. Intl Journal of Human- Computer Studies,2010,68(8):496-507.
[3]Han E H S,Karypis G. Feature-Based Recommendation System[C]∥Proceedings of the 14th ACM International Conference on Information and Knowledge Management,2005:446-452.
[4]Andersen R,Borgs C,Chayes J T, et al. Trust-Based Recommendation Systems: an Axionmatic Approach[C]∥Proceedings of the 17th International Conference on WWW.ACM,2008:199-208.
[收稿日期]2017-03-09
[基金项目]2016年广东团省委和科技厅项目(pdjh2016b0168)。
