数据挖掘在选课推荐中的研究
2017-01-20胡健王理江
胡健 王理江
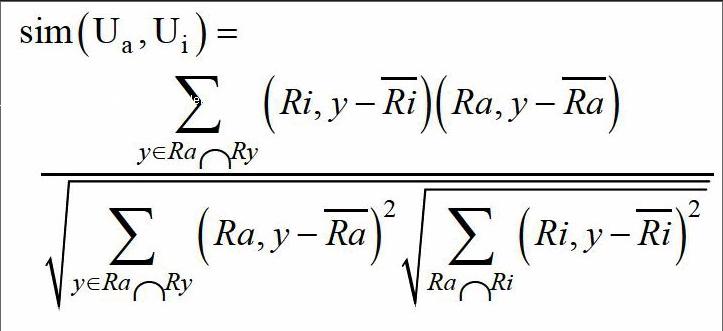

摘要:在当代大学教育中,学生选课系统中存在的缺乏个性化课程推荐、选课效率较低的问题,本文针对这个问题结合数据挖掘技术对选课建立了选课推荐系统模型,使得学生在选课中有更多的参考,在一定程度上减少了学生选课的盲目性。
关键词:选课;数据挖掘;推荐系统
中图分类号:TP391 文献标识码:A DOI:10.3969/j.issn.1003-6970.2016.04.028
0 引言
随着教育改革的推进选课制度已在高校普及多年,为了满足学生的个性化需求,根据上课时间、学习兴趣、任课老师以及学习进程等各方面的需求选择适合自己的课程,课程的自选使得学生的自由空间更大且学习效率明显提升。选课制度作为高校教学管理制度改革内容的一部分同时也是学分制的重要内容,选课制度的设计及实施过程都需结合大学生教育理念。改革开放的到来更是为教育吹来了春风,教育体制也突破了传统模式,开始实行选课制和学分制。然而多数高校在选课制度实施过程中普遍存在课程结构设置不合理、选课方式不完善、选课指导体系不健全等问题。学生不能结合自身的专业和兴趣进行选课,选课缺乏目的性和针对性;选课制度不利于学生的个性发展,也不能为学生以后的工作带来良好的指导,从而出现了专业与职位不对口的现象。有鉴于此,本文将数据挖掘中的个性化推荐技术应用于选课系统中,根据学生自身的状况、学习需求以及兴趣偏好等,为学生提供个性化课程推荐平台,从而避免学生选课的盲目性和跟风现象,提高了课程资源的利用率和选课质量。
1 我国高校选课制度的现状
随着选课制在高校的普及,教育也逐渐走向网络化和信息化,在这样一个计算机网络普及的时代自然选课过程也趋于网络化。受到传统观念及学年制的影响,选课制度在运行过程中还存在一定的缺陷,另外在新教学观念的实施和高素质人才的培养中选课制也没有体现其优势,具体原因有下几个方面:
1.1 目前实施的选课制不利于学生的个性发展
随着社会对人才专业需求的多样化,传统的人才培养模式已无法满足社会发展需求,同时也抑制了学生的个性化发展。选课制的实行使得学生可根据自身的兴趣爱好选择合适的课程、任课教师以及学习时间,各种自由的选择使得的个性特征得到满足,从而提高了学生的学习积极性。
1.2 没有实现真正的选课
尽管有部分学校允许学生选择跨专业、跨年级的课程,但在教师资源、上课时间以及场地资源等影响下,学生仍无法选择自己喜欢的课程,时间及资源上的冲突使得学生在自主选课上受到了一定的限制,对于比较热门的课程,当选课人数较多资源有限时,课程就会被删除,自主选课无法充分发挥其作用。随着高校不断扩招,教师资源越来越匮乏,学生的选择范围有限。
1.3 选课工作实施不到位
选课指导也是一个很重要的环节,特别是新生由于对课程了解不深,因此很容易出现盲目选课现象。部分学生了为了选择简单易学的知识而不顾自身发展,随意性的选课对教学质量造成了很大的影响,同时也脱离了选课制实行的初衷。针对这个问题本文提出了利用数据挖掘技术筛选历史选课数据中隐藏的、有用的知识,作为指导学生选课的依据,该课题的提出对高校教学管理改革有着重要的现实意义。
2 数据挖掘与个性化推荐系统
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。它是一门交叉学科,集成了许多学科中成熟的工具和技术,包括统计学、数据库技术、机器学习、模型识别、人工智能等。数据挖掘技术已经有了很好的应用,例如销售、银行、电信、保险、交通等领域。数据挖掘所能解决的典型商业问题包括:数据库营销、客户群体划分、背景分析、交叉销售等市场分析行为,以及客户流失性分析、客户信用记分、欺诈发现等。将数据挖掘技术应用于教育中,也是这些技术发展的必然。个性化推荐是数据挖掘中一项非常有用的技术,它是20世纪90年代被作为一个独立的概念提出来,近些年有了迅速的发展,得益于Web2.0技术的成熟。有了这个技术,用户不再是被动的获取信息,而是成为获取信息这个过程中的主动参与者。它在商业领域大获成功,在一个实际的推荐系统中需要推荐的产品可能会有上万种,甚至更多,例如Amazon,eBay,YouTube等,用户的数目也会非常巨大。准确、高效的推荐系统可以挖掘用户潜在的消费倾向,为众多的用户提供个性化服务。协同过滤系统是目前应用最为广泛,也是效果最好的个性化推荐系统。协同过滤(Colaborative Filtering)这个概念由Goldberg等在1992年提出,并应用于Tapestry系统。目前主要有两类协同过滤推荐算法:基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法。
3 学生个性化选课推荐系统的研究
本文采用的是基于用户的协同过滤算法,在高校选课系统中融入该算法可帮助学生根据自身的兴趣爱好选择与自身发展最为贴近的课程、学习量及任课教师,个性化选课推荐系统的运用使得高校选课机制更为完善。在推荐系统内建立评价矩阵,对学生在选课过程中的主要因素进行描述,如兴趣爱好、专业、学习程度、选课记录和老师评价等,算法根据学生这些信息对其行为进行分析,并建立相应的学生项,通过与评价矩阵中的项进行对比找出相似度最高的选课记录,并向该学生进行课程推荐。由此可见,个性化高校选课推荐系统模型主要分为评价矩阵、搜索最近邻居和课程推荐三个部分。
3.1 建立评价矩阵
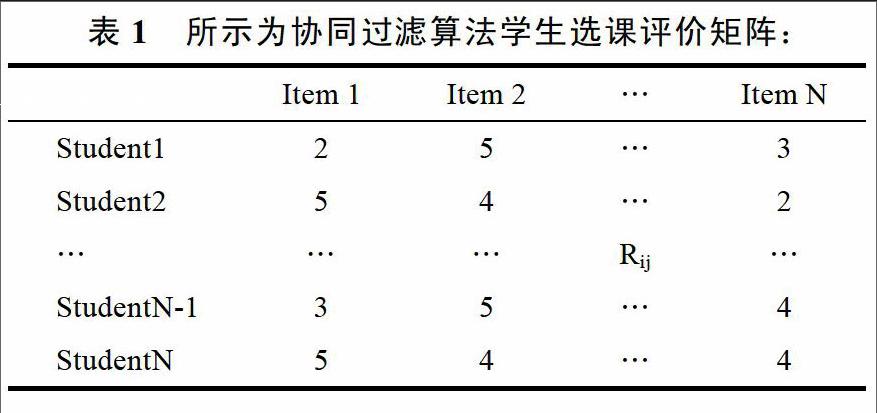
根据专业、爱好、选课记录、学习程度等信息收集历史选课数据,若直接从教务系统中选取,则需对数据进行清洗和转化,从而形成协同过滤算法学生选课评价矩阵。
在上述矩阵中Rij的中的i代表的是学生,j代表的是项目,R代表的是评价。Rij的取值范围通常在[0,5]这个区间范围内,分值的大小与评价的高低成正比。
3.2 搜索最近邻居
将目标学生与评价举证中所有学生的相似度进行对比,找出相似度最高的一组并建立相应的最近邻居集合,在基于用户的写通过率算法中这步是很难关键的,相似度的具体算法如下所示:
在上述公式中sim(Um,Ui),代表目标学生与矩阵学生的相似度,y代表两者共同评价过的项目,Ra,y,和Ri,y表示a学生和i学生对y项目的评价,Ra和Ri表示项目评价平均值。
3.3 产生推荐
根据评价结果和推荐算法产生推荐,具体推荐算法如下所示:
sim(a,n)表示相似度,Rn,i表示项目评分Ra和Rn表示项目评价平均值。该算法主要是针对用户评价项目较多的情况,对于个别评价,结果可能就没那么准确。
4 结束语
本文基于协同过滤算法的个性化高校选课推荐系统是根据学生的兴趣爱好、学习程度和专业等信息进行相似度计算,然后再根据相似度的高低推荐相应的课程。但是该算法存在“冷启动”问题,即在没有学生的历史数据作为参考和分析的基础下是无法实现选课推荐的。高校个性化选课推荐系统的使用可有效提高学生的学习兴趣以及学校的教学质量,帮助学生科学合理的选择合适的课程,为学生的个性化发展提供有效的学习方式。
