遗传算法降维优化的BP模型及葡萄酒质量预测
2017-04-19孙文兵
孙文兵
(邵阳学院 理学与信息科学系,湖南 邵阳,422000)
遗传算法降维优化的BP模型及葡萄酒质量预测
孙文兵
(邵阳学院 理学与信息科学系,湖南 邵阳,422000)
针对BP神经网络模型输入自变量维数过高导致模型训练时间长、泛化能力低、效率不高的缺陷,提出一种基于遗传算法筛选降维的方法,并利用遗传算法优化降维过程中建立的BP网络的权值与阈值以提高筛选效率,最后建立用遗传算法优化的GA-BP网络预测模型,用于葡萄酒的质量预测。利用遗传算法从37个理化指标中筛选出18个作为自变量输入GA-BP预测模型并与未经优化的BP模型对比,经遗传算法降维优化的GA-BP模型建模时间由7.5625秒缩短为0.8623秒,预测平均相对误差由10.83%减少为2.85%。仿真实验表明降维优化的GA-BP网络模型效率更高、泛化能力更好。
遗传算法;降维;优化;神经网络;质量预测
目前国际上对葡萄酒质量评价没有一个统一的量化标准,一般是聘请一批有资质的评酒员进行品评。评酒员对葡萄酒进行品尝后根据分类指标打分,然后求和得到其总分,根据分数的高低以衡量葡萄酒的质量。而实际中请有资质的品酒师不是一件容易的事,而且评价结构受主观因素的影响较大。葡萄酒质量的好坏从生化角度来看与葡萄酒和酿酒葡萄的一些理化指标密切相关,如果能建立理化指标和葡萄酒质量间的合理关系,那么在没有合适品酒员时,也能预测葡萄酒的质量。目前常见的建模预测方法有多元回归、趋势预测等,然而有些复杂关系很难准确确定具体的函数关系式,因此建立的模型往往不准确。
人工神经网络具有良好的非线性逼近能力,理论上已证明一个三层BP网络可以满足一般函数映射的要求,可以任意精度逼近任意多变量函数,而且预测精度较高,因此在各种预测模型中有广泛应用[1-3 ]。而BP算法是基于梯度下降的,自身的缺陷也不可避免:网络权值阈值随机设定,当解空间有多个局部极小时容易陷入局部极小而无法跳出。另外当网络输入自变量很多,自变量之间又不是相互独立的时,BP网络易出现过拟合现象,导致模型泛化能力低建模时间长等缺陷。
遗传算法是模拟自然界优胜劣汰生物进化过程的全局优化搜索算法,采用群体进化的方式对目标函数空间进行并行式搜索,根据个体适应度大小选择个体,保留竞争力强的基因,是一种搜索效率高、鲁棒性强的优化方法。结合二者的特点,目前很多学者利用遗传算法优化神经网络取得不错的成效[ 4-5],比较广泛的是利用遗传算法优化网络权值和阈值[ 6-8]。也有通过不同的编码方式,优化BP网络的结构和系数以确定合适的网络结构[9]。
针对葡萄酒和酿酒葡萄的理化指标过多,导致自变量维数过高,很可能存在冗余信息,从而增加建模时间,造成精度不高,泛化能力下降的缺陷,本文先利用遗传算法优化筛选[10],去掉冗余信息,提取最能反映网络输入和输出关系的自变量参与建模。由于遗传算法筛选过程计算适应度函数时要建立BP网络,筛选的效率不高,筛选的时间往往很长[11],因此利用遗传算法优化BP神经网络的权值和阈值,减少筛选时间。并建立遗传算法优化的GA-BP模型用于对葡萄酒质量预测,优化后的模型有明显的效果。
1 模型数据的提取和归一化
结合2012年全国大学生数学建模竞赛A题—葡萄酒质量评价问题的附件数据[12],以其中白葡萄为例。提取所有可能对白葡萄酒质量影响的一级理化指标,包括酿酒葡萄29个指标和葡萄酒8个指标总共37个指标。葡萄酒的质量以10位品酒师对每个样品的评分平均值为衡量标准,样品个数为28个。
由于不同输入因子纲量和数值大小的差异,为了避免奇异因子影响网络的训练时间和收敛性,有必要对原始数据进行归一化处理,使归一化后的数据分布在[-1,1]之间。计算公式:
(1)
其中,xi是原始数据,yi是归一化后的数据,max(x),min(x)是输入数据的最大值和最小值.
2 基于改进遗传算法的自变量降维设计
2.1 遗传算法自变量降维
根据以上数据可用BP神经网络建模学习,以理化指标为输入自变量,葡萄酒质量评分为输出因变量。然而37个理化指标可能包含一些冗余信息,若全部作为输入自变量,必然降低学习性能,利用遗传算法对自变量进行不断迭代进化,最终筛选出具有代表性的自变量参与建模。
2.1.1 个体编码与初始种群
采用二进制的编码方法,染色体编码长度为37,将这些理化指标按顺序排列,染色体的每一位对应一个输入自变量,基因取值为“0”和“1”,取“0”时表示不选择该变量,取“1”时表示选择该变量。随机产生n个长度为37的串结构数据为一个个体,即为n个初始种群。
2.1.2 适应度函数
适应度函数是遗传算法中选择运算的依据,遗传算法朝着适应度函数增大的方向进化,即适应度函数值越大被选中的机率就越大。这里选取数据集误差平方和的倒数作为适应度函数:
(2)
其中,xi是第i个样本输出值,ti是第i个样本实际值,n为样本数目。每一个个体适应度函数的实现通过建立BP网络求均方误差,适应度函数取均方误差的倒数。
2.1.3 选择运算
选择运算采用基于排序的适应度分配,按适应度大小升序对个体排序,按线性排序确定染色体的选取概率:
Pi=c(1-c)i-1
(3)
其中i为个体排序序号,c为排序为1的个体的选择概率。
2.1.4 交叉运算
交叉操作采用单点交叉算子,对初始种群个体进行随机配对,这里初始种群大小设为20,共有10个相互配对的个体组,对每一对相互配对的个体,随机选取某一基因座之后的位置为交叉点,互换两个配对个体的部分染色体,产生两个新个体。
2.1.5 变异运算
采用单点变异算子,随机产生变异点,由变异点的位置改变对应基因座上的基因值,即变异点的基因值由“0”变成“1”或由“1”变成“0”。
2.2 遗传算法筛选降维主要步骤
Step 1 初始化种群,对种群进行二进制编码;
Step 2 计算适应度函数,适应度大遗传到下一代概率相对大,若满足终止条件便输出结果,即得到筛选出的自变量,算法终止;
Step 3 若适应度不满足条件,计算每一个个体选择概率,单点交叉和变异操作,产生新的个体;
Step 4 在新一代种群中,返回 step 2。
3 遗传算法优化BP网络权值和阈值算法设计
由于降维过程中个体适应度函数采用数据集误差平方和的倒数,而BP网络的学习特点是使网络输出层的误差平方和达到最小,故计算适应度函数时需要建立BP网络以求适应度函数。同时对葡萄酒质量预测时也建立BP网络模型,针对BP神经网络的初始权值和阈值的随机选取的缺陷,对于自变量筛选降维过程中个体适应度函数计算时所建立的BP网络和葡萄酒质量预测所建立的BP网络模型均用遗传算法对初始阈值和权值进行优化。
3.1 遗传算法优化BP网络权值和阈值
神经网络采用3层网络结构为:输入层—隐含层—输出层,遗传算法优化BP网络时其主要要素如下:
3.1.1 种群初始化
随机产生初始种群,种群数目N根据需要自己拟定,本文中选取N=20,初始种群编码采用实数编码,每个个体为一个实数串,由输入层与隐含层的连接权值、隐含层与输出层以及隐含层阈值和输出层阈值组成。若网络结构确定时便可以确定个体编码长度,比如2-3-1的网络结构,权值个数为2×3+3×1=9个,阈值为3+1=4个,所以个体编码长度为9+4=13。
3.1.2 适应度函数
根据随机产生的权值和阈值对应的神经网络,对给定的输入数据集和输出数据集计算每个神经网络的全局误差,遗传算法只能朝着使适应度增大的方向进化,因此适应度函数可按照(2) 式构造。
3.1.3 选择操作
采用旋转轮盘赌和最优保存策略相结合的混合选择算子。选择过程以旋转轮盘赌策略为基础,根据个体适应度,按某种规则挑选出好的个体进入下一代种群,即每个个体的选择概率
(4)
其中fi为个体i的适应度值,N为种群数目。
个体适应度越高, 被选中的概率就越大, 进入下一代的机会就越大。由于随机操作的原因, 这种选择误差比较大,有时甚至连适应度较高的个体也选择不上。为了提高遗传算法的收敛性,还采用最优保留策略,即将最大适应度的个体直接保留到下一代。每次新种群用上一代所记录的最优个体替换群体中的最差个体, 以防止当前种群中适应度较好的个体被淘汰。
3.1.4 交叉操作
交叉操作采用算术交叉算子:
c1=p1×a+p2×(1-a)
c2=p2×a+p1×(1-a)
(5)
其中,a为(0,1)间的随机数即为交叉概率,p1,p2为一组配对的两个父代个体,c1,c2为交叉后产生的两个子代个体。
3.1.5 变异操作
为提高搜索能力和算法的收敛速度,变异操作采用自适应调整:
(6)
其中,fmax是群体中最大适应度值,favg是每代群体的平均适应度值,f是要变异个体的适应度值,k1,k2为(0,1)中的值。
3.2 遗传算法优化BP网络权值和阈值的主要步骤
Step 1 根据创建的BP网络,按神经网络生成初始权值和阈值的方法对种群初始化,并且对其进行实数编码,确定种群数目;
Step 2 计算每一个个体的选择概率,并将其排序;
Step 3 按旋转轮盘赌和最优保存策略挑选出好的个体进入下一代种群中;
Step 4 在新一代种群中,按算术交叉算子和自适应变异率选择适应的个体进行交叉和变异操作,产生新的个体;
Step 5 将新个体插入到种群中,并计算其适应度;
Step 6 如果找到了满意的个体,则终止算法,否则转step 2。
Step 7 找到优化的权值与阈值后,将最终群体中的最优个体解码,即可得到优化后的网络权值和阈值用以训练BP网络。
4 BP网络模型
通过遗传算法降维优化后筛选出来的理化指标作为网络的输入变量,葡萄酒质量评分作为输出变量建立三层拓扑结构的BP网络模型。输入层到隐含层以Tansig为训练函数,隐含层到输出层以purelin为传递函数,为了克服标准BP算法固有的一些缺陷,训练算法采用基于数值优化方法的Levenberg-Marquardt法。隐含层节点数待确定输入单元后可通过反复试验来确定,学习速率为0.01,最大训练次数max_epochs=1000,目标误差err_goal=0.01。
5 葡萄酒质量预测及仿真分析
5.1 理化指标筛选降维结果
利用文中第2节介绍的遗传算法降维的方法对影响葡萄酒质量的37个理化指标做降维处理,染色体长度为37,种群大小设为20,最大进化代数设为100。降维过程中用到的BP网络用第3节中介绍的遗传算法对初始权值和阈值进行优化。利用遗传算法工具箱GAOT在Matlab软件上实现,得到的最优二进制编码(0010100011101110101101011010001110000)。由二进制编码方法可知筛选出来的理化指标分别是第3、5、9、10、11、13、14、15、17、19、20、22、24、25、27、31、32、33号,共18个自变量,对应为白葡萄中的VC含量(mg/L)、酒石酸、褐变度、DPPH自由基、总酚、葡萄总黄酮、白藜芦醇、黄酮醇、还原糖、PH值、可滴定酸、干物质含量、百粒质量、果梗比、果皮质量及白葡萄酒中的总酚、酒总黄酮、白藜芦醇。这说明其余19个没选择的自变量是冗余信息,可见筛选出来参与建模的自变量不到原来总数的一半。
遗传算法优化降维过程如图1 所示,从图可看到,当种群进化到第35代之后得到了最优个体,种群的平均适应度函数均值在稳定中有微小的波动,这是因为遗传算法中的一些随机性因素造成的。
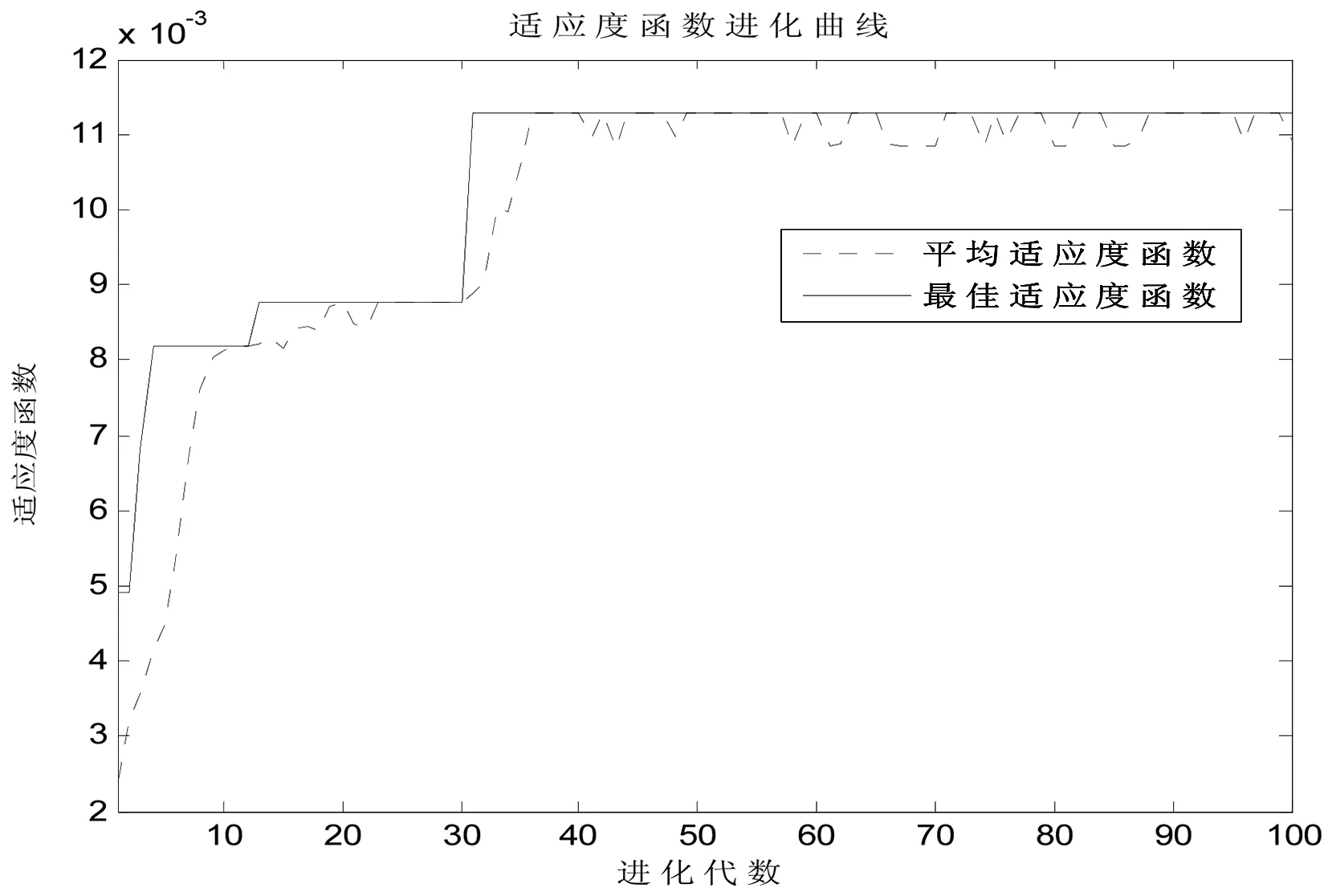
图1 种群适应度函数进化曲线Fig.1 The evolution curve of population fitness function
5.2 遗传算法优化的GA-BP模型预测结果及仿真
BP模型及参数设置采用第4节介绍BP网络,隐含层数通过反复试验方法确定。并利用第3节中介绍的遗传算法对BP预测模型的初始权值和阈值进行优化,种群大小设为20,最大进化代数设为100。
为了检验遗传算法优化的GA-BP模型的泛化能力,以1号至20号样本为训练样本,21号至28号样本为检测样本以检验模型的准确性。为了检验经遗传算法降维筛选以及优化后的GA-BP模型的合理性和优势,先将原37个自变量输入BP网络建模,经反复实验网络拓扑结构选定为37×50×1;再将经遗传算法优化筛选出来的18个自变量输入BP网络建模;最后将经遗传算法优化筛选出来的18个自变量输入用遗传算法优化后的GA-BP网络建模,同样经反复试验,后两种网络拓扑结构确定为18×35×1,三种模型对21至28号样本的预测结果如下表1:
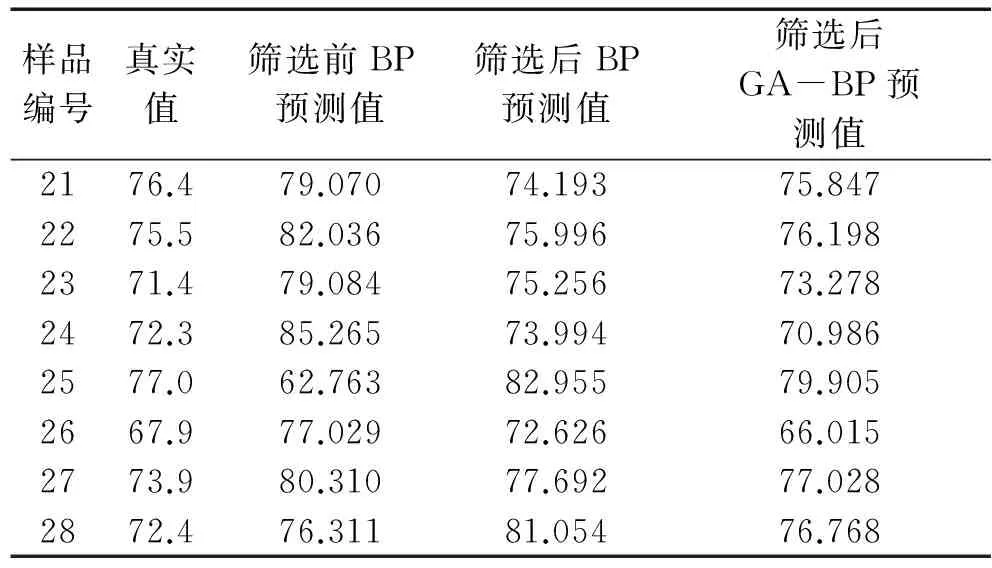
表1 遗传算法优化筛选的BP模型样本预测值Table 1 The sample prediction value of BP model optimized by genetic algorithm
为了比较三种模型对预测样本的泛化能力以及建模时间的长短,将三种模型预测结果的偏差以及三种模型训练时间做出对比,见表2。
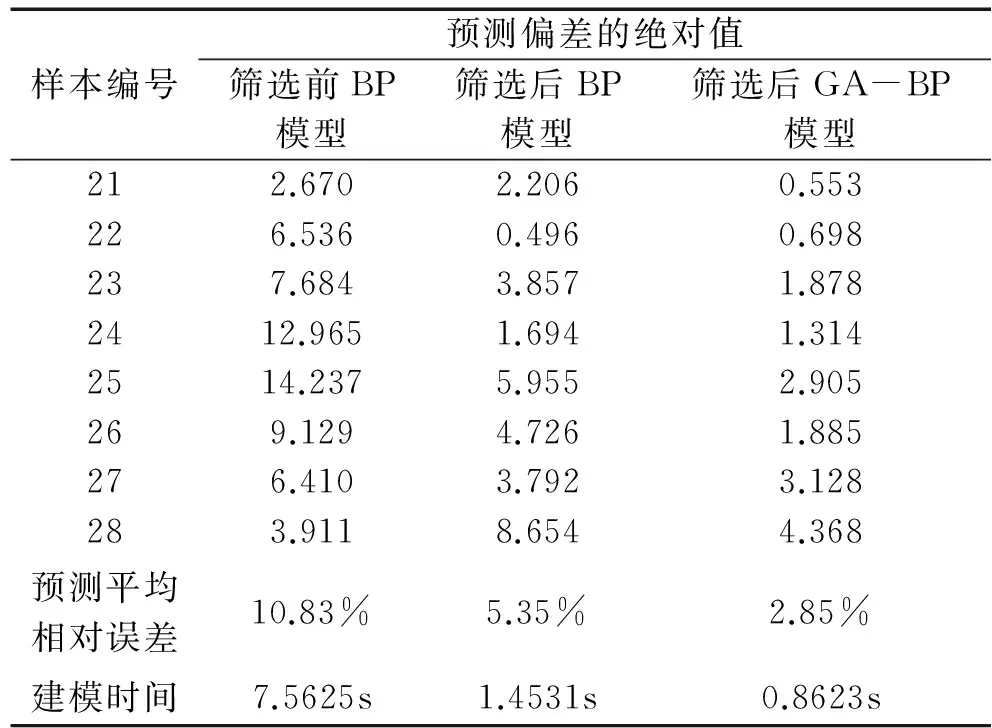
表2 三种BP模型泛化能力、建模时间对比Table 2 The comparison of generalization ability and modeling time about three kinds of BP model
由表2可以看出,用遗传算法筛选前对葡萄酒质量预测的平均相对误差为10.83%,建模时间为7.5625秒;用遗传算法筛选降维后再对葡萄酒质量预测的平均相对误差仅为5.35%,建模时间只有1.4531秒;而用遗传算法降维后再用遗传算法优化的GA-BP模型预测平均相对误差只有2.85%,而且建模时间缩短到0.8623秒。可见筛选降维后模型预测准确率大大提高,建模时间明显缩短。而经遗传算法降维再用遗传算法优化的BP模型预测最准确,建模时间最短。为了更直观地了解三种模型的泛化能力,作出预测仿真图如图2 。
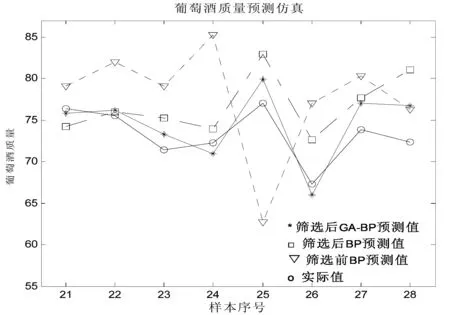
图2 葡萄酒质量预测仿真图Fig.2 The simulation diagram of wine quality prediction
6 结论
本文利用遗传算法降维方法,筛选BP网络建模输入因子,以降低自变量的维数,并针对筛选过程中计算适应度函数时所建立BP网络以及葡萄酒质量预测的BP网络模型的初始权值和阈值的随机性,用遗传算法对权值和阈值进行优化,减少筛选时间和建模时间,提高了准确度。建立了经遗传算法筛选优化以后的GA-BP网络模型,并用于葡萄酒质量预测,此模型比未经优化的BP模型具有更好的网络泛化能力,且节省了建模时间。
由于实际中评价葡萄酒质量对于小企业和个人而言聘请有资质的品酒师不是一件容易的事,而且由于品酒师主观原因造成评价结果有差异。因此,此模型为方便葡萄酒的质量预测提供一种参考方式,而且此模型可以推广到其他饮料的预测当中。
[1]李亚,刘丽平,李柏青,等.基于改进 K-Means 聚类和BP神经网络的台区线损率计算方法[J].中国电机工程学报,2016,36(17):4543-4551.
[2] 徐黎明,王清,陈剑平,等.基于BP神经网络的泥石流平均流速预测[J].吉林大学学报,2013,43(1):186-191.
[3]陈 啸,王红英,孔丹丹,等.基于粒子群参数优化和 BP 神经网络的颗粒饲料质量预测模型[J].农业工程学报,2016,32(14):306-314.
[4]王德明,王莉,张广明.基于遗传BP 神经网络的短期风速预测模型[J].浙江大学学报(工学版),2012,46(5):837-841.
[5]张立仿,张喜平.量子遗传算法优化BP神经网络的网络流量预测[J].计算机工程与科学,2016,38(1):114-119.
[6]杜文莉,周仁,赵亮.基于量子差分进化算法的神经网络优化方法[J].清华大学学报(自然科学版),2012,52(3):331-335.
[7]Leung H F,Lam H K,Ling S H,et al.Tuning of the structure and parameters of neural network using improved genetic algorithem[J].IEEE Transactions on Neural Network,2003,14(1):79-88.
[8]Tsai J,Chou J,Liu T.Tuning the structure and parameters of a neural network by using hybrid Taguchi-genetic algorithem[J].IEEE Transactions on Neural Network,2006,17(1):69-80.
[9]张伟栋,叶贞成,钱 锋.基于混合编码的遗传算法在神经网络优化中的应用[J].华东理工大学学报( 自然科学版),2008,34(1):108-111.
[10]汤 勃,孔建益,王兴东.基于遗传算法的带钢表面缺陷特征降维优化选择[J].钢铁研究学报,2011,23(9):59-62.
[11]MATLAB中文论坛编著.MATLAB神经网络30个案例分析[M].北京:北京航空航天大学出版社.2010.
[12]全国大学生数学建模竞赛网站[EB/OL].[2012-09-07].http://www.mcm.edu.cn/problem/2012/cumcm2012problems.rar.
BP model optimized by genetic algorithm reducing dimension and wine quality prediction
SUN Wenbing
(Department of Science and Information Science,Shaoyang University,Shaoyang 422000,China)
If BP neural network model has many input variables,this will reduce some defects:training time is too long,generalization ability is low,efficiency is not quick.In order to overcome these defects,this paper proposed a method based on genetic algorithm dimensions reduction.It used genetic algorithm to optimize weights and thresholds of BP neural network in the dimensionality reduction process,which improved the screening efficiency.Finally,the GA-BP network model of genetic algorithm optimization was established,and the model was used to predict wine quality.The 18 variables were chosen from the 37 physical and chemical indexes by genetic algorithm.The selected variables were independent variables to establish GA-BP model.In contrast,the modeling time of optimized GA-BP model was reduced from 7.5625 seconds to 0.8623 seconds,the average relative error was reduced from 10.83% to 2.85%.The simulation results show that the optimization GA-BP network model has more better efficiency and generalization ability than the BP network.
genetic algorithm;dimensions reduction;optimization;neural network;quality prediction.
1672-7010(2017)01-0023-07
2017-01-05
邵阳市科技计划项目(2016GX04)
孙文兵(1978-),男,湖南隆回人,副教授,硕士,从事智能算法及应用,解析不等式研究;E-mail:swb0520@163.com
TP183;O242.1 < class="emphasis_bold">文献标志码:A
A
