基于字符包络和笔画宽度的伪车牌判断方法
2017-04-14杨英仓
杨 英 仓
(贵州省道路交通事故鉴定工程技术研究中心 贵州 贵阳 550005)(贵州警官职业学院 贵州 贵阳 550005)
基于字符包络和笔画宽度的伪车牌判断方法
杨 英 仓
(贵州省道路交通事故鉴定工程技术研究中心 贵州 贵阳 550005)(贵州警官职业学院 贵州 贵阳 550005)
车牌定位结果中往往存在一些误检,为了减少车牌识别后续模块的计算负担,并提升最终识别结果准确率,提出一种基于字符包络分析和笔画宽度统计的伪车牌排除方法。该方法将车牌定位结果图像二值化和反色判断后,对二值图中字符前景的上下轮廓提取包络,统计上下包络线的间距,设定阈值排除一部分伪车牌;再对二值图像各行前景点进行笔画宽度统计,计算得到多个指标,进一步排除更多伪车牌。实验结果表明,该方法能排除复杂场景中的绝大多数伪车牌。
车牌定位 车牌误检 伪车牌 字符包络 笔画宽度
0 引 言
车牌识别在智能交通中发挥着巨大的作用,在道路卡口、收费站、停车场等地方都有着广泛的用途。车牌识别系统一般包括车牌定位、字符分割和字符识别三个模块,其中车牌定位是较为关键的一部。目前已有很多较为成熟的方法,采用了字符纹理、车牌边框、车牌区域颜色等各种特征。但无论采用什么方法,车牌定位得到检测结果中,总会存在一些不是真实车牌的检测区域,这些区域的颜色或纹理与真实车牌区域较为相似。由于所有车牌定位的检测结果都会送入字符分割和字符识别模块等后续模块分析,伪车牌的存在增加了计算负担,并且,如果后续模块不能有效排除这些伪车牌,最终会造成车牌识别结果的误检,对大部分车牌应用造成较大的干扰。
伪车牌常见于出租车、公交车的车身广告或字符串,部分伪车牌的二值图如图1所示。

图1 部分伪车牌的二值图
对伪车牌的排除,目前主要做法有两种,一种是在强化车牌定位中的筛选环节,另外一种是在字符分割或字符识别中进行处理。
文献[1-3]中提到利用车牌定位中使用的纹理信息,来进一步分析车牌区域的纹理是否合理,但由于伪车牌的多样性,仅使用纹理的方法不能有效排除伪车牌。
文献[4-6]对车牌区域二值图进行形状分析,考虑了面积、高宽比、占空比等特征,但真伪车牌的这些特征区分并不是特别明显,若要减少误检必定为增加漏检。
文献[7-8]根据字符分割得到的结果判断伪车牌,但某些场景下(如光照强或模糊)车牌二值化后字符间会存在粘连,因此该方法不能广泛适应各种场景。
文献[9-10]通过训练方式进行字符识别,统计字符识别的平均置信度,通过置信度来去除伪车牌,该方法理论上来说应该较为有效,但是限定了字符识别的方法,并且要完成字符识别后才能判伪增加了系统的负担。
1 伪车牌判断模块位置
本文提出一种基于字符包络分析和笔画宽度统计的伪车牌判断方法。该方法适用于车牌二值化及反色判断后、字符分割之前。相对在车牌定位阶段判伪的方法,利用了更多的车牌先验知识;相对在字符分割和字符识别后判伪的方法,显著减少了计算量。
本方法在车牌识别中的模块位置如图2所示。

图2 伪车牌判断模块在车牌识别流程中的位置
车牌识别中二值化及反色、字符分割有成熟的算法,本文不做介绍。本文提出的伪车牌判断方法包括字符包络分析和笔画宽度统计两个子模块,其中前者关注车牌字符区域的外轮廓特征,后者关注车牌字符区域的内纹理特征。
2 字符包络分析
字符包络是根据轮廓特征提取的,这里轮廓特征指二值图像的上轮廓和下轮廓特征,上轮廓是各列从上边界往下到第一个前景点的距离,下轮廓是各列下边界往上到第一个前景点的距离。
图3中,为了方便轮廓线将一个待判断的车牌区域复制为上下两份,灰色细线为轮廓线,黑色粗线为极值点获得的包络连线。可以看出,真车牌字符区域包络平整,每列上的上下包络高度差值变化不大(字符区域高度一致),而一些伪车牌的包络连线不够平整,高度差值变化也较大。

图3 部分伪车牌与真车牌的包络对比示意
2.1 标记极小值点
极小值点一般情况下是取数值同时小于左右邻近点的点作为极小值点。由于图像中上下边经常会出现横笔画,使得一段轮廓值整体局部极小而在该段得不到极小值点;另外,某些轮廓值较大的极小值点是不必要的。
设定车牌二值图像高度为H,宽度为W。按照图4所示方法来进行极小值点标记。
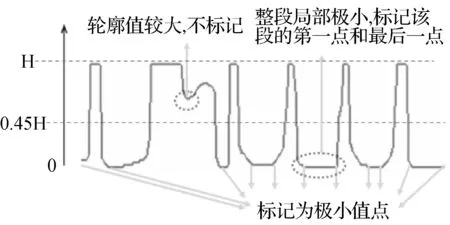
图4 极小值点标记示意
(1) 首先设定阈值maxValTh= 0.45×H,任何轮廓值大于maxValTh的点,都不标记为极小值点。
(2) 当轮廓值小于左侧和右侧时,作为极小值点,对于上图右下虚线框中的区段情况(该区段中最大与最小轮廓值相差不大于1),应将该段第一个点和最后一个点都作为极小值点,两点之间的点不做标记。
2.2 极值点间距分析与距离阈值计算
在车牌字符中,上轮廓极值点的最大间距为L和J之间的间距设为WidthLJ,当其中间存在小圆点时,是最为极端的情况,若设阈值maxWidthTh=WidthLJ,则极值点间距大于此阈值的情况最多只有一个,通过极值点间距分析也可以排除一些伪车牌。
下轮廓极值点的最大间距为F/P和1之间的间距,同理可设阈值maxWidthTH=WidthF1来排除伪车牌。
若直接对极值点进行连接获取包络,对于图5来说,会得到较为平整的包络,不能判定为伪车牌。观察可见两图中都存在有一个较大的间隙,因此可以根据车牌字符间距的先验知识,对这部分包络直接取原来的轮廓值使其保留包络陡峭的特性。这个间隙是否足够大需要通过设置一个极小值点连接距离阈值(ConnectTh)来判断。

图5 部分伪车牌中存在较大间隙导致包络凹陷
当存在一些特殊字符(J,F,P)等时,会存在一些不必要的极值点,使得连接起来的包络有凹陷,因此要对这些极值点做舍弃(改为连接),是否舍弃需要通过设置一个近邻极小值点查找距离阈值(FindTh)来判断。如图6所示。

图6 个别极值点的存在导致包络凹陷与包络修复示意
2.3 轮廓特定点连接为包络
N个极值点有N-1个极值点区间。对于序号为InterInd的区间,如果其宽度小于阈值ConnectTh(InterInd),则将两个极小值点之间用直线连接起来得到包络,两个点之间的其他点的包络值通过线性插值得到。
如果区间宽度小于FindTh(InterInd),则以区间左侧极小值点(记为A)的轮廓值为dotLine,并分别以点A为中心向左和向右各查找一个最近的轮廓值小于dotLine的极小值点Al和Ar,如果Al和Ar距离小于FindTh(InterInd),则将Al和Ar用直线连接起来作为新的包络值,忽略点A这个极小值点。
如图7所示,虽然A点也是一个极值点,但其附近的红色包络线是通过连接Al和Ar获得的。这样就可以避免车牌字符的包络出现凹陷。
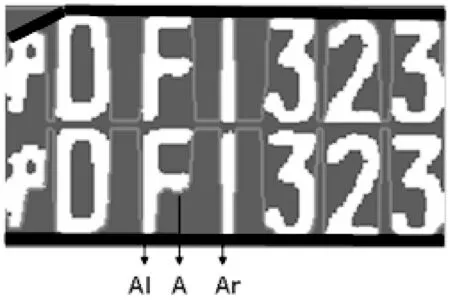
图7 放弃某些极小值点示意
如果Al和Ar之间的距离大于或等于FindTh(InterInd),则查找两侧与A点最近的轮廓值相等的极小值点Bl和Br,若Bl和Ar的距离小于FindTh(InterInd),则连接Bl和A;若AL和Br的距离小于FindTh(InterInd),则连接AL和Br。
若一个区间不能通过以上任意一种方法进行极值点连接,则该区间包络保持不变(为原来的轮廓值)。
2.4 使用包络来判断伪车牌
当提取到上下轮廓的包络后,就可以通过高度统计信息来判断伪车牌了,为了避免左右两侧区域可能存在缺失笔画汉字或其他噪声的影响,这里统计时忽略两侧宽度为0.11×W。
设上轮廓包络为EnvUp,下轮廓包络为EnvDown,则各列高度为EnvH=H-EnvUp-EnvDown。取EnvH(0.11×W:0.89×W)计算平均值和标准差,若平均值不大于0.8×H或者标准差大于0.06×H,则判断是伪车牌。
3 笔画宽度统计
本文中的笔画宽度是指每行前景点的游程长度。真实车牌的字符笔画(图像所有行都要进行统计)较多,且字母和数字的笔画宽度在一定的范围内(10~45mm,占车牌宽度的比例为0.0244~0.1100),而且笔画宽度主要为10和45mm两种。可利用这些特点,通过计算待判定图像的前景点笔画宽度统计直方图,可分别获得车牌的笔画数、窄笔画数、窄笔画宽度分布一致性、极窄笔画比例、主流笔画宽度(频次最大的笔画宽度)等特征,来判定是否为伪车牌。
图8显示了不同的图像及其笔画统计直方图如下。

图8 笔画宽度统计直方图示意
图8中曲线对应的横坐标表示笔画宽度(mm),纵坐标代表相应笔画宽度的数量。标准车牌从最左侧字符左边界到最右侧字符右边界的距离是409mm。可以看出,真车牌的笔画宽度统计直方图上只有一个明显峰值,且这个峰值在一定距离范围内,而且几乎不存在较宽的笔画(大于标准字符宽度的笔画)。
笔画特征分析判断算法分为笔画宽度统计直方图计算、特征提取和判决两个步骤,以下将详细介绍。
3.1 宽度统计直方图
理论最大的笔画宽度为车牌图像的宽度(N),设置一个长度为N的零数组SWSF用于不同的笔画宽度计数。遍历每一行,每个长度为x的白色像素行程意味着SWSF(x)的一次累加(加1)。
为了避免噪声干扰,不统计宽度为1的笔画;为了避免车牌左右两边较窄背景笔画和汉字细笔画的干扰,也不统计左右侧0.16×W范围内长度小于TH的行程,标准车牌宽度归一化为180像素时,字符笔画宽度大约为5像素,因此这里TH可以取值为4。
3.2 特征提取与判决
本算法需要提取以下特征,每个特征都可以进行独立判决。
(1) 总笔画数TNS(TotalNumberofStrokes):TNS等于直方图数值之和,若总笔画数TNS≤6×H,可认为是伪车牌。这是因为以字符数最少的普通车牌为例,由于含有7个字符,理论上笔画的最小数量为7×H,考虑到可能有粘连或者个别字符上下边界不靠边的情况,这里将阈值设置为6×H。
(2) 窄笔画数NNS(NumberofNarrowStrokes):NNS为笔画宽度大于0.015×W且小于0.15×W的笔画数量之和。若窄笔画数NNS≤5.7×H,可认为是伪车牌。
(3) 窄笔画比例RNS(RatioofNarrowStrokes):RNS=NNS/TNS,若RNS< 0.85,可认为是伪车牌。这是因为理想质量车牌的NNS应该等于TNS,所以RNS理想情况应为1,考虑到粘连、噪声等情况,较比例系数阈值设置较小。
(4) 窄笔画宽度分布一致性DNS(DistributionofNarrowStroke-Width):计算笔画宽度大于等于0.015×W且小于0.15×W的笔画数量平方之和,即为DNS。若DNS< 2.6×H×H,可认为是伪车牌。这是因为对于车牌字符,其笔画宽度主要集中在一个或两个值附近,因此DNS应该较大。
(5) 极窄笔画比例RSS(RatioofSlenderStrokes):RSS为小于0.015×W的笔画数量与NNS的比值。若RSS>0.05,可认为是伪车牌。这是因为理论上在车牌中非汉字区域是不存在细笔画的,RSS=0。但考虑到毛刺,这里将阈值设置为0.05。
(6) 主流笔画宽度MSW(MainStroke-Width):MSW为笔画宽度统计直方图中最大值点对应的横坐标上的笔画宽度。一般情况下,真车牌直方图上只存在一个主要峰值,这个峰值对应的主流笔画宽度反映的是真车牌笔画的宽度。因此当MSW<0.015×W或MSW>0.065×W时,可认为是伪车牌。
4 实验及结果分析
实验素材来源于图像或视频,都是来源于车牌定位结果,并进行了二值化和反色处理,伪车牌图像1 202幅,车牌图像7 080幅。该车牌定位算法基于边缘和颜色分析,得到的伪车牌是难通过边缘特征或颜色特征排除的。本文所用的实验素材源图像如图9所示。

图9 车牌定位源图像
伪车牌图像主要是公交车上的字符,以及行人、摩托车、自行车或者机动车的车灯车标等。车牌图像素材包含各种环境(强光、弱光、夜间、小雨、模糊、倾斜、变形、手机拍摄、视频截取等)下的车牌,均为单排车牌。
使用以上素材,统计算法可排除的伪车牌以及错判的真车牌数(将真实车牌错判为伪车牌的数量),相关数据如表1所示。从表1可以看出,本方法可排除绝大部分伪车牌(95.6%),降低了字符分割和字符识别模块的负担,对降低误检也有明显的促进作用。0.7%的错判率在可接受的范围。
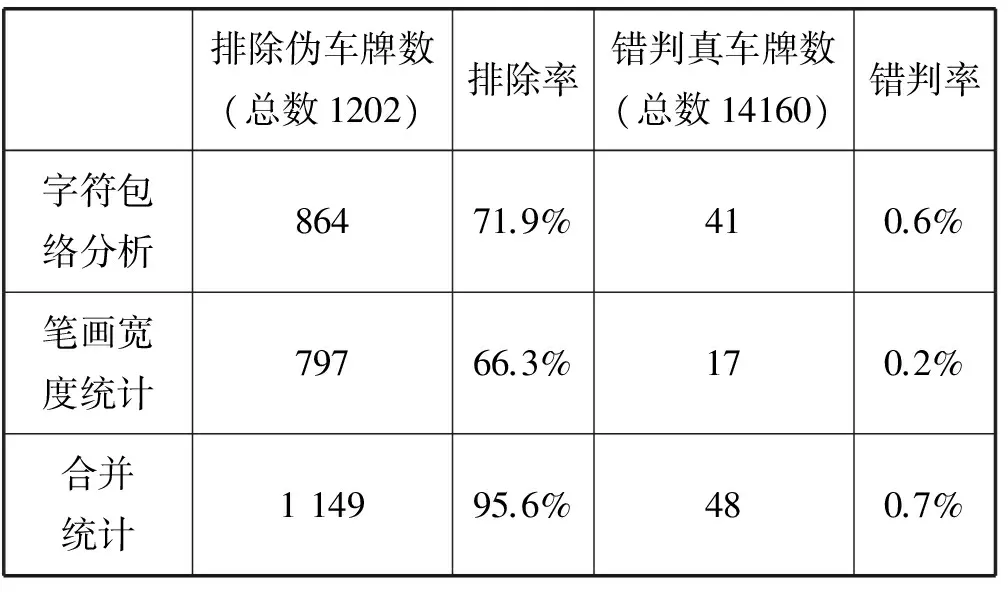
表1 本文方法伪车牌判断实验结果
若将本方法结合字符分割或字符识别中的判伪算法一起使用,则车牌识别整个系统的误检率可以降低到可忽略的水平。
本文方法与其他文献的方法对比如表2所示。其中多车牌是指一幅图像中包含多个车牌。

表2 字符识别前对伪车牌的判断结果数据比较
由于无法取得其他文献的测试素材和代码,不能在完全相同的条件下进行比较。从表2中可以看出,本文方法对伪车牌的实际排除率虽然略低于其他两篇文献报告的识别率,但适应性更强。
本方法不能排除的伪车牌主要是含有字符的车牌,且这些字符在轮廓、笔画特征上与真车牌具有一定的相似性,如图10所示。

图10 本方法不能排除的伪车牌示例图
本方法误判的真车牌,主要是车牌成像质量较差,二值化后有粘连或笔画缺失的情况,如图11所示。

图11 本方法误判的真车牌示例图
5 结 语
为了降低车牌识别中的误检率,降低字符分割和字符识别模块的负担,本文提出了一种同时基于车牌字符区域外部轮廓特征和内部纹理特征分析的伪车牌判断方法,该方法包含字符包络分析和笔画宽度统计两个步骤。
实验结果显示,对于使用边缘和颜色分析算法的车牌定位检测到的伪车牌,本方法能排除95.6%且错判率极低,表明本方法非常有效。但本方法较难排除轮廓、纹理特征上与真车牌相似的伪车牌,需要其他方法补充。
[1] 周欣,蒋欣荣,潘薇.基于分块投影和语义约束的车牌定位算法[J].计算机工程与应用,2014,50(9):141-144,149.
[2] 马爽,陈江宁,卢虎,等.边缘特性筛选与多判定机制下的车牌定位方法[J].计算机工程与应用,2014,50(9):145-149.
[3] 周小龙,张小洪,冯欣.基于视觉显著图的车牌定位算法[J].光电工程,2009,36(11):145-150.
[4] 郭航宇,景晓军,尚勇.基于小波变换和数学形态法的车牌定位方法研究[J].计算机技术与发展,2010,20(5):13-16.
[5] 朱春满,房斌,尚赵伟,等.复杂背景下的多车牌定位技术研究[J].公路交通科技,2010,27(7):147-153.
[6] 甘玲,孙博.基于分块投影和形态学处理的多车牌定位方法[J].计算机应用研究,2012,29(7):2730-2732.
[7] 王俊杰,付晓红,李俊杰.基于数学形态学和先验知识的车牌定位[J].软件导刊,2008,7(7):9-11.
[8] 郑伯川,崔屏,张征.一种基于粗细定位相结合的车牌定位方法[J].重庆邮电大学学报(自然科学版),2007,19(2):225-227.
[9] 朱秀峰.车牌字符识别算法研究与实现[D].华中科技大学,2012.
[10] 周明辉.运动车辆车牌识别算法的研究与实现[D].昆明理工大学,2013.
THE METHOD OF JUDGING FAKE LICENSE PLATE BASED ONCHARATER ENVELOPE AND STROKE WIDTH
Yang Yingcang
(GuizhouRoadTrafficAccidentIdentificationEngineeringTechnologyResearchCenter,Guiyang550005,Guizhou,China)(GuizhouPoliceOfficerVocationalCollege,Guiyang550005,Guizhou,China)
License plate location may be error detected. A method of eliminating fake license plate based on analyzing character envelope and calculating stroke length is proposed to reduce the computational burden of the license plate recognition module and improve the final accuracy results. In this method, after dealing license plate location results with image binaryzation and invert color judgment, the license binary image extracted envelope and distance between the upper and lower envelope, and then analyze the separation distance, so that the threshold is able to be set to exclude a part of fake license plates. Then, the stroke width of foreground points of the license binary image is count, and more fake license plate is excluded after calculating various indicators. Experimental results indicate that this method can eliminate most fake license plates in license plate location results.
License plate position License error detection Fake license plate Character envelope Stroke width
2015-10-30。贵州省道路交通事故鉴定工程技术研究中心开放
黔道交鉴合G字[2015]10012号)。杨英仓,副教授,主研领域:公安视听的教学,科研和司法鉴定。
TP3
A
10.3969/j.issn.1000-386x.2017.03.040
