密度峰值优化初始中心的K-means算法
2017-04-14张桂珠
李 敏 张桂珠
(江南大学物联网工程学院 江苏 无锡 214122)
密度峰值优化初始中心的K-means算法
李 敏 张桂珠
(江南大学物联网工程学院 江苏 无锡 214122)
K-means算法随机选取初始聚类中心,容易导致聚类结果不稳定。为此,提出一种快速密度峰值搜索算法CFSFDP(clustering by fast search and find of density peaks)优化初始中心的K-means算法。首先针对CFSFDP算法中截断距离的选取影响局部密度的计算这一缺点,提出用动力学中的势能替换数据点的局部密度;在此基础上,利用改进的CFSFDP算法选取初始聚类中心,实现K-means聚类。在UCI数据集和人工模拟数据集上的测试结果表明,优化后的新算法具有更好的聚类结果。
K-means算法 CFSFDP算法 密度峰值 引力势能
0 引 言
聚类分析是一种无监督的分类方法,是数据挖掘中的重要研究方向之一[1]。聚类分析是通过一定的准则将一个数据集划分成不同的类或簇,使相同类或簇内的数据对象之间具有较高的相似性,而不同的类或簇之间的相异性则尽可能的大。目前在诸如模式识别、机器学习、图像分析、神经网络、客户细分以及生物医学等其他领域被广泛应用[2]。传统的聚类分析方法大致分为五类:基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法以及基于模型的方法[3]。
在聚类分析方法中, K-means算法是最著名和最常用的基于划分的聚类算法[4],K-means具有简单、速度快的优点,并且能够有效地处理大文本集。但K-means算法要求事先选取初始聚类中心,初始聚类中心的选取严重影响聚类结果的好坏和算法的迭代次数。为此,很多学者致力于K-means算法初始聚类中心优化研究。文献[5]提出一种确定性的方法,计算样本点的局部密度,以密度为根据选择K-means算法的K个初始聚类中心。文献[6]利用谱方法估计特征中心寻求初始聚类中心。文献[7]采用密度敏感度量样本相似性来计算对象密度,启发性地生成初始聚类中心。文献[8-10]使用不同的数据点密度计算方法,选择互相距离最远的K个位于高密度区域的数据点作为初始中心。上面所述的方法在一定程度上优化了K-means算法的性能,但这些算法都需要通过人工选取参数,缺少客观性。为此,本文基于数据点本身的密度大,且与比其密度大的其他点有相对更大的距离原理,提出利用密度峰值优化初始中心的K-means算法。
快速密度峰值搜索算法CFSFDP[11]是一种基于密度的聚类算法。该算法思想简单新颖,对于任意形状的数据集,该算法能够快速发现其密度峰值点。CFSFDP算法可以很好地剔除孤立点,并且能很好地处理大规模数据集。然而该算法也存在一些缺陷:该算法的成败在某种意义上依赖于用于计算局部密度的截断距离dc,文献[11]中对dc的选取只是提供了一个参考建议,没有给出一个计算方法;其次,对同一个类存在多密度峰值[12]的情况,该算法聚类并不理想。
综合上述问题,本文提出了优化方案。首先,利用势能[13]代替局部密度来优化CFSFDP算法,优化后的算法(P-CFSFDP)解决了算法的好坏取决于参数dc的问题,然后用P-CFSFDP算法来确定初始聚类中心,最后用K-means算法进行迭代聚类。KP-CFSFDP算法可以自主地确定合适的初始聚类中心,解决了K-means算法随机选取初始聚类中心而导致聚类结果不稳定[14]的问题,且避免了聚类结果严重依赖于参数的选取问题,同时有效减少迭代次数。测试结果证实,KP-CFSFDP算法有更好的聚类效果。
1 快速密度峰值搜索算法及其改进
1.1 快速密度峰值搜索算法(CFSFDP)
CFSFDP算法的核心思想在于对聚类中心的刻画上。聚类中心同时具有两个特点:一是数据点本身的密度大,即它被密度小于它的邻居包围;二是与比它本身密度更大的数据点之间有相对更大的距离。
在文献[5]中,对于数据集s={xi|xi∈Rn,i=1,2,…,n},Is={1,2,…,N}为相应的指标集。数据集s中的每个数据点xi,定义两个计算量:局部密度ρi和距离δi。
局部密度ρi有两种计算公式,包括Cut-offkernel和Gaussiankernel。
Cut-offkernel:
(1)
其中dij=dist(xi,xj)代表数据点xi与xj之间的(某种)距离。函数χ(x)定义为:
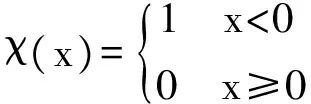
(2)
截断距离参数dc>0,需要通过人工选取。
Gaussiankernel:
(3)
对比式(1)和式(3)可知,Cut-offkernel为离散值,Gaussiankernel为连续值。
距离δi是通过计算数据点xi到任何比其密度大的点的最小距离得到的:
(4)


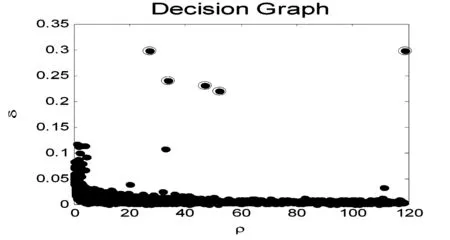
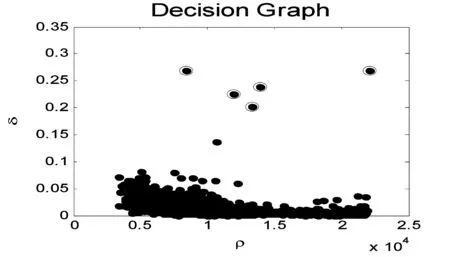
图1 数据点分布

图2 决策图
由图2可以发现,编号为1和10号的数据点由于同时具有较大的ρ值和δ值,于是脱颖而出,而这两个点恰巧是图1中的数据集的两个聚类中心。而编号为26、27、28数据点是离群点,它们有共同的特点是:ρ值很小、但δ值很大。
为了能自动确定聚类中心的个数,本文提出计算一个综合考虑ρ值和δ值的量γ。
γi=ρiδii∈IS
(5)
图3所示为γ值降序排列结果。其中,下标为横轴,γ值为纵轴。由图可知,非聚类中心的γ值比较平滑,而从非聚类中心过渡到聚类中心时γ值有一个明显的跳跃,这个跳跃可以明显判断出来。
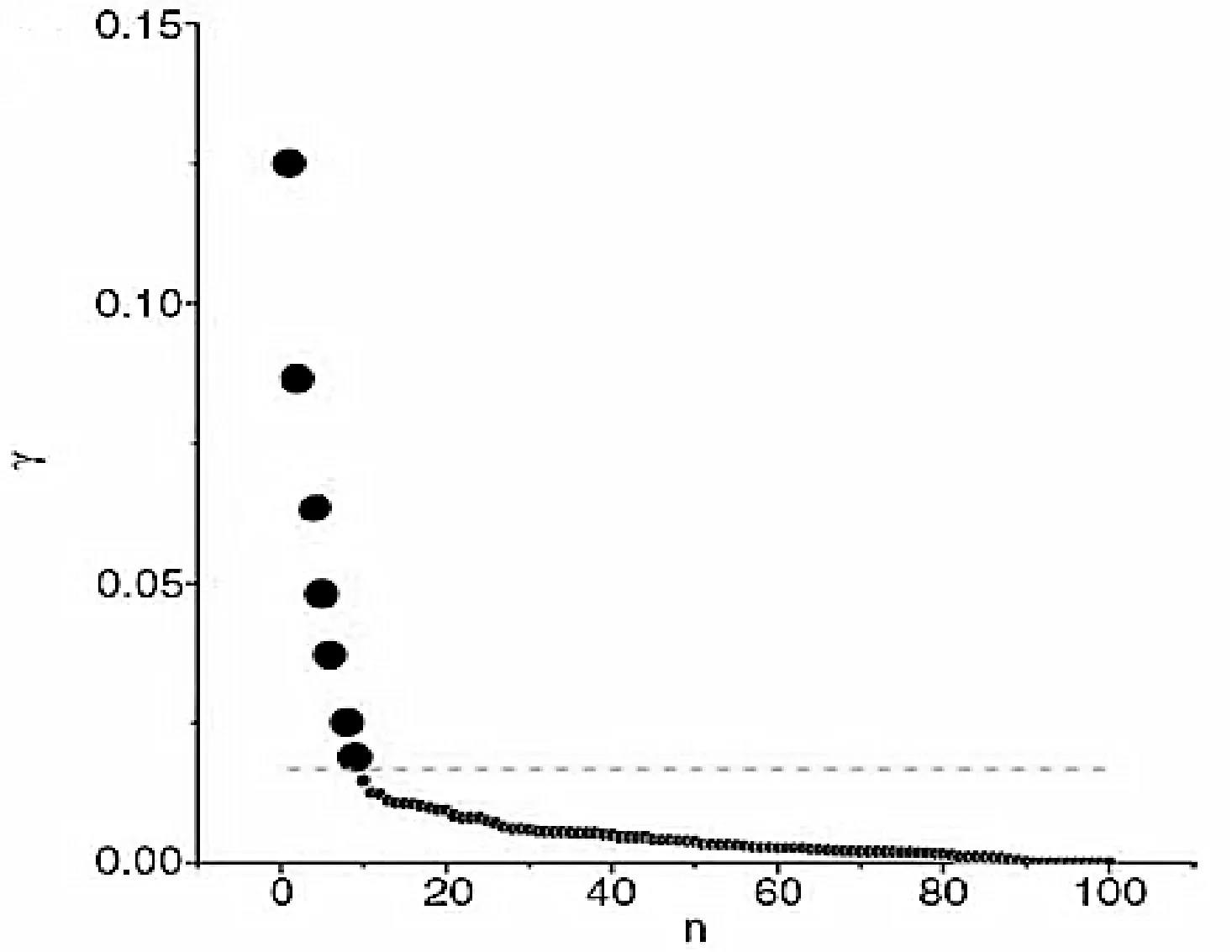
图3 γ值降序排列
1.2P-CFSFDP算法
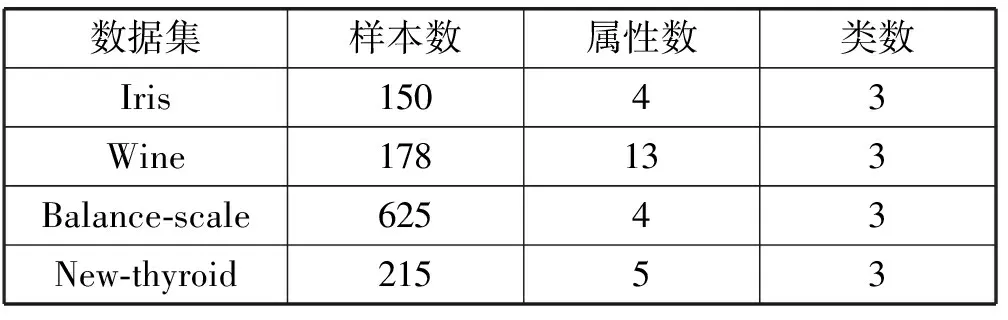
文献[5]中对于截断距离参数dc,在没有人工介入的情况下,对于如何选取dc值是不清楚的。然而,参数dc的选取对于局部密度的影响是很大的。例如,当dc取值过大时,ρi的值就会很接近而使区分度不高,极端情况是当dc>dmax时,数据集中的所有点被分为一个簇;而当dc取值过小时,同一个簇就可能被分成多个簇,极端情况是当dc 文献[5]中必须通过人工选取一个敏感参数的情况是遗憾的,我们更希望文中的算法对参数不敏感,甚至希望参数可以被一个不变的或者一个自动选取值来代替。因此本文使用引力势能代替数据点的局部密度,提出一种基于势能的优化的快速密度峰值搜索算法(P-CFSFDP算法)。在物理学中势能概念的基础上,将数据集假想为一个势能场,所有的数据点对其它任何一个数据点都会有影响,所以能够计算出每一个数据点的势能。 由万有引力定律,空间中的两点i和j之间的引力为: (6) 其中,G是万有引力常量,mi和mj分别是质点i和j的质量,rij为质点i和质点j之间的距离。 根据势能义可知,质点j对质点i产生的势能为: (7) 这里假设在欧氏空间中,每个数据点的质量都取1。为避免由于数据点i和数据点j之间的距离无限接近于零,使结果产生奇异值,这里通过设置阈值λ进行修正。则引力公式为: (8) 相应的,势能公式则变为: (9) 令G=1,则式(9)变为: (10) 那么在假想的这个势能场中,所有数据点对数据点i产生的势能总和为: (11) 通过大量选取不同的λ值尝试发现,在避免结果产生奇异值得情况下,阈值λ越小,找出初始聚类中心的能力越强。 (12) (13) 其中,MinDi是数据点i与其他数据点之间距离的最小值,通过式(12)和式(13)便能计算出阈值λ。 2.1KP-CFSFDP算法思想 本文KP-CFSFDP(密度峰值优化初始中心的K-means算法)算法,是为了解决快速密度峰值搜索算法和K-means存在的问题而提出的。其贡献是利用势能Wi代替CFSFDP算法中数据点xi的局部密度ρi,通过CFSFDP算法生成的决策图确定类个数k,以及初始聚类中心。然后使用K-means算法进行聚类。 2.2KP-CFSFDP算法描述 输入:具有N个对象的待分类的数据集 输出:满足目标函数最小化的k个簇 Step1 初始化及预处理 1) 计算距离dij,令dji=dij,i Step3 计算每个数据点和每个类的聚类中心的距离,将数据点归类到与其距离最小的类中。 Step4 重新计算每个簇的质心,并计算聚类误差平方和。 Step5 使用新的质心进行重新聚类,并计算聚类误差平方和。 Step6 当聚类误差平方和不再发生明显变化,则算法终止,否则转Step3。 为了验证本文算法的优越性,分别在UCI数据集和经典人工模拟数据集上进行测试,并对算法进行了对比试验。实验环境为Intel(R) Core(TM) i3 CPU M 380 @ 2.53 GHz 2.53 GHz,内存2.0 GB,操作系统为Windows 7,使用 MATLAB R2011a进行仿真试验。 3.1 P-CFSFDP算法实验结果与分析 本文提出的P-CFSFDP算法使用势能代替数据点的局部密度计算,下面将用Aggregation、Example和Flame这3个数据集对P-CFSFDP算法进行测试。Aggregation和Flame数据集为经典人工模拟数据集,Example数据集来自文献[5],数据集的构成描述如表1所示。将本文提出的P-CFSFDP算法与快速密度峰值搜索算法进行比较,验证本文提出的P-CFSFDP算法的优越性。 表1 数据集描述 图4到图9展示的上述三个数据集分别在快速密度峰值搜索算法(CFSFDP算法)和本文提出P-CFSFDP算法的实验生成的决策图。图4和图5对比,图6和图7对比,图8和图9对比。在CFSFDP算法中,截断距离dc的选取满足每个数据点的平均邻居个数约为数据点总数的2%。 图4 Aggregation数据集在CFSFDP算法中的决策图 图5 Aggregation数据集在P-CFSFDP算法中的决策图 图6 Example数据集在CFSFDP算法中的决策图 图7 Example数据集在P-CFSFDP算法中的决策图 图8 Flame数据集在CFSFDP算法中的决策图 图9 Flame数据集在P-CFSFDP算法中的决策图 通过对比,本文P-CFSFDP算法在不需要人工介入选取参数的情况下能很好地找到初始聚类中心及类簇个数。寻找聚类中心的能力并不比CFSFDP算法差。综合可知,本文P-CFSFDP算法能更好地选择初始聚类中心。 3.2KP-CFSFDP算法实验结果与分析 采用的实验数据为UCI机器学习数据库的Iris、Wine、Balance-scale和New-thyroid,并把本文算法与文献[9-10]以及传统K-means算法进行比较。 聚类评判结果使用聚类误差平方和、聚类准确率,以及Rand指数和Jaccard系数进行评价[15]。一个聚类j及与此相关的分类i的准确率定义为: 准确率:Precision(i,j)=Nij/Ni 其中,Nij是在聚类j中分类i的数目;Ni是分类i中所有对象的数目。 Rand指数和Jaccard系数定义如下:设U和V分别是基于数据集的两种划分,其中U是已知正确划分,而V是通过聚类算法得到的划分,对于数据集中的任一对数据点,计算下列项: SS:两个点在V中同一簇,且在U中同一簇; SD:两个点在V中同一簇,但U中不同簇; DS:两个点不在V中同一簇,但在U中同一簇; DD:两个点不在V中同一簇,且不在U中同一簇。 设a、b、c、d分别表示SS、SD、DS、DD的数目,则a+b+c+d=M是数据集中所有样本对的个数,即M=N(N-1)/2。其中,N为数据集的样本数。Rand指数和Jaccard系数的定义如下: Rand指数:R=(a+d)/M Jaccard系数:J=a/(a+b+c) 其中,R表示Rand指数;J表示Jaccard系数。 由上述定义可知,Rand指数表示聚类结果与原始数据样本分布的一致性;Jaccard系数表示正确聚类的样本对越多,聚类效果越好。 UCI数据集的描述如表2所示。 表2 UCI数据集描述 下面用本文算法以及其他优化初始中心的K-means算法进行测试,其他算法均使用最佳参数设置。其他算法对参数很敏感,本文使用其他算法的最佳结果与本文算法比较。表3为每个算法在UCI数据集上运行100次后的平均聚类误差平方和。 表3 各算法在UCI数据集的聚类误差平方和 由表3可知,本文算法在自动确定所给数据集的类簇个数和初始聚类中心的情况下,聚类误差平方和明显优于传统K-means算法、文献[10]和文献[9]算法。文献[9]通过密度参数计算数据点所在区域的密度,选择互相距离最远的K个位于高密度区域的数据点作为K-means算法的初始聚类中心。文献[10]以数据点为中心,计算以某一正数为半径的球形域内数据点的个数,作为数据点密度,选择互相距离最远的K个位于高密度区域的数据点作为K-means算法的初始聚类中心。 图10-图12分别是每个算法的聚类准确率、聚类结果的RandIndex参数和Jaccard系数。 图10 聚类准确率 图11 聚类结果的Rand Index参数 图12 聚类结果的Jaccard系数 由图10可知,本文算法在New-thyroid数据集上尽管与文献[9]有一样的聚类效果,但在其他数据集上的聚类效果明显优于其他算法。图11是关于数据集在四种算法上的聚类结果的Rand参数,由图可知,本文算法在各个测试数据集上都有更好的聚类结果,在Balance-scale数据集上的聚类结果尤为突出。图12是关于数据集在不同算法上的聚类结果的Jaccard系数,由图可知,本文算法在每个测试数据集上的聚类结果都是较好的。通过分析可知,本文算法在没有人工参与确定参数的情况下,能够取得更好的聚类效果。 针对K-means算法随机选取初始聚类中心导致聚类结果不好,且已有的对K-means优化初始聚类中心的算法须要设置参数,且算法严重依赖参数的选取。本文利用快速密度峰值搜索算法对聚类中心刻画的原理,将势能的概念引入,避免了快速密度峰值搜索算法的聚类结果取决于截断距离参数的选取问题。使用优化的快速密度峰值搜索算法对数据集预处理,得到初始聚类中心,提出了基于密度峰值优化的K-means算法。在UCI机器学习数据库数据集和经典人工模拟数据集上的实验结果证明,优化后的新算法在不需要人为确定参数的情况下,不但能更好地确定类簇数和初始聚类中心,且比已有优化初始中心K-means算法聚类结果更加精确。 [1]DattaSouptik,GiannellaChris,KarguptaHillol,etal.ApproximateDistributedK-MeansClusteringoveraPeer-to-PeerNetwork[J].IEEETransactionsonKnowledgeandDataEngineering,2009,21(10):1372-1388. [2]ZhouTao,LuHuiling.Clusteringalgorithmresearchadvancesondatamining[J].ComputerEngineeringandApplications,2012,48(12):100-111. [3]WangJun,WangShitong,DengZhaohong,etal.Surveyonchallengesinclusteringanalysisresearch[J].ControlandDecision,2012,27(3):321-328. [4] 杨小兵.聚类分析中若干关键技术的研究[D].杭州:浙江大学,2005. [5]KaufmanL,RousseeuwPJ.FindingGroupsinData:AnIntroductiontoClusterAnalysis[M].NewYork,USA:JohnWiley&Sons,Inc.,1990. [6] 钱线,黄萱菁,吴立德.初始化K-means的谱方法[J].自动化学报,2007,33(4):342-346. [7] 汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-304. [8] 赖玉霞,刘建平.K-means算法的初始聚类中心的优化[J].计算机工程与应用,2008,44(10):147-149. [9] 袁方,周志勇,宋鑫.初始聚类中心优化的K-means算法[J].计算机工程,2007,33(3):65-66. [10] 王塞芳,戴芳,王万斌,等.基于初始聚类中心优化的K-均值算法[J].计算机工程与科学,2010,32(10):105-107. [11]Rodriguez,Alex,AlessandroLaio.Clusteringbyfastsearchandfindofdensitypeaks[J].Science,2014,344(6191):1492-1496. [12] 谭颖,胡瑞飞,殷国富.多密度阈值的DBSCAN改进算法[J].计算机应用,2008,28(3):745-748. [13] 廖礼.一种新的基于密度的聚类算法研究[D].兰州:兰州大学,2013. [14]PenaJM,LozanoJA,LarranagaP.AnEmpiricalComparisonofFourInitializationMethodsfortheK-MeansAlgorithm[J].PatternRecognitionLetters,1999,20(10):1027-1040. [15] 杨燕,靳蕃,KamelM.聚类有效性评价综述[J].计算机应用研究,2008,41(6):1631-1632. K-MEANS ALGORITHM OF OPTIMIZED INITIAL CENTER BY DENSITY PEAKS Li Min Zhang Guizhu (SchoolofIOTEngineering,JiangnanUniversity,Wuxi214122,Jiangsu,China) K-means algorithm randomly selects the initial cluster centers, which can easily lead to the instability of clustering results. To overcome this deficiency, a K-means algorithm named clustering by fast search and find of density peaks (CFSFDP) is proposed to optimize the initial center. Firstly, aiming at the disadvantage that the selection of truncated distance in CFSFDP algorithm affects the local density, it is proposed that the local density of each point can be replaced by gravitational potential energy. Based on this, K-means clustering can be implemented by using the optimized CFSFDP algorithm to select initial cluster centers. The proposed algorithm is tested on UCI data sets and synthetic data sets. Experimental results show that the new algorithm can achieve better clustering. K-means algorithm CFSFDP algorithm Density peak Gravitational potential energy 2016-04-06。江苏省自然科学 BK20140165)。李敏,硕士生,主研领域:数据挖掘。张桂珠,副教授。 TP18 A 10.3969/j.issn.1000-386x.2017.03.0382 改进的K-means算法
3 实验结果与分析









4 结 语
