一种新的微博社区发现算法
2017-04-14杨长春李雪佳
杨长春 刘 玲 李雪佳 吕 晨 顾 寰
(常州大学信息科学与工程学院 江苏 常州 213164)
一种新的微博社区发现算法
杨长春 刘 玲 李雪佳 吕 晨 顾 寰
(常州大学信息科学与工程学院 江苏 常州 213164)
在舆情分析、微博营销和个性化推荐等方面,微博社区发现的研究都具有重要的应用价值。为了准确而有效地发现微博社交网络中的社区,提出一种基于信任关联度的微博社区发现算法(TRKM算法)。该算法通过微博用户的评论、转发、原创微博等属性来构造节点间信任关联度,再利用微博社区的模块度对网络社区划分效果进行评价。在新浪微博明星和普通用户数据集上进行实验,并将TRKM算法与传统K-means算法作比较。实验表明,该算法能够更有效地发现微博用户关系网络中的社区结构。
微博网络 社区划分 TRKM算法 信任关联度 社区模块度
0 引 言
在Web 2.0时代的大环境下,社交型网站(SNS)也成为了应用热点。微博作为SNS的一种升级版社交网络交互模式,正逐渐成为众多研究者关注的热点[1-2]。社交网络和其他的复杂网络一样,都具有社区结构。不同属性、兴趣的社区结构组成了人类最复杂的网络之一即社交网络。
社区结构是社交网络具有的一个共同特性[3],满足不同社区间节点连接相对稀疏,同一社区内部节点连接相对紧密的特点。社区形成的原因多种多样,不管是微博还是微信社区,最重要的基础是信任关系[4]。兴趣和需求不同的用户会选择关注相关的、信任的社交圈、朋友圈来进行互动、交流。由于微博用户大部分是真实的人群,对微博用户的合理分群对广告投放、微博营销和准确定位目标用户群体都具有非常重要的意义。
目前,微博网络社区发现方面的研究大致分为两种:一种是基于文本的能发现在对同一主题感兴趣的人群的方法,主要通过定义文章相似的度量来构造节点之间的相似度,将相似度值比较接近的聚类成一组用户社区。另一种是基于行为联系的方法,在微博行为的基础上利用图模型进行建模来寻找出互相联系紧密的用户群体。
针对微博网络的社区发现在国内外已有一些研究成果。国内方面,曾王辉[5]利用微博网络的特殊性,提出了在微博网络中运用广度优先搜索和模块度相结合的社区发现方法,提高了社区划分的准确性和有效性,但是该算法对于微博网络的研究信息还仅限于用户之间的关注信息,没有转发、评论等重要信息。闫光辉等人[6]通过综合考虑用户关注关系和用户主题相关度来对微博用户社区进行划分,但是该算法没有考虑用户间的交互行为如发帖和回帖数对用户相关度的影响;蔡波斯等人[7]利用用户行为来建模,从而构造用户行为相似度来划分微博社区。但是,上述方法并不能反映用户隶属于多个社区的重叠问题,仅仅局限于用户之间的关联关系,事实上,用户在兴趣社区中,会隶属于多个兴趣社区。丁虹等人[8]提出了一种基于K-means算法的微博社区发现新方法,通过微博博主的评论、转发属性来定义节点间的关联度,从而一定程度上提高了社区划分的质量。国外方面,对于Twitter的社区发现研究,Naresh等人[9]通过用户所发表的内容、链接关系等来建相似度矩阵,从而在传统聚类方法的基础上来发掘微博社区;Deitrick等人[10]通过微博用户与用户之间所发送的tweets信息内容来逐步提高社区发现的有效性和准确性。
本文充分利用节点属性信息,提出一种基于信任关联度的微博社区发现算法(TRKM算法)。该算法引入信息群度的概念,将微博社区网络边权重的值不设为固定值1,而是动态设定。在模式归类的基础上,按最大信任关联度原则选取新的代表对象,直至划分节点的过程全部完成为止,最后根据模块度来确定理想的微博社区数目。该算法能够更贴近微博网络的特性并且较好地找到聚类中心,使得社区发现的质量大大提高,并且能够满足微博营销的目标用户群体发现的基本需求。
1 算法思路
1.1 微博网络结构
在目前基于复杂网络的研究中,一般是将网络结构分为无向图结构和单向有向图结构。在微博网络中,设定每个用户即博主为一个节点,用户有关注和粉丝两类信息,设定关注信息为节点的入度,粉丝信息为节点的出度,因此,网络中存在单向边和双向边两种类型的边。在微博网络中若单纯的从节点间的表面关系来考虑,微博网络结构就是一个混合有向图。
根据微博网络社区的概念,微博社区的存在只取决于用户之间的信息交流情况即用户之间互相转发帖、评论和互赞等的情况,与用户之间的关注方向无关。本文以用户为节点,提出节点对的信息群度的概念,即节点之间用户活跃值与博文质量值之和的倒数。信息群度可以很好的反应出微博网络中博主之间的互动情况,能更准确地对微博网络进行社区挖掘。本文根据节点对的信息群度的定义,将微博网络结构抽象为无向有权图。
设微博网络G有n个节点和m条边,节点对的信息群度为dij。设节点i和j之间的活跃值为aij,评论数为oij,微博转发数为rij;节点i和j之间的博文质量值为qij,节点之间的原创微博数为cij、赞数为lij,微博总数为n,其中权重因子β1、β2是用来调节评论数、转发数在节点间的活跃值中所占的比重,同样λ1、λ2是用来调整节点间的原创微博数和赞数在博文质量值中所占的权重。则aij、qij和dij分别表示为:
aij=(β1×oij+β2×rij)/n
(1)
qij=(λ1×cij+λ2×lij)/n
(2)
dij=1/(aij+qij)
(3)
将节点之间边权重wij的值设为节点对的信息群度,即:
wij=dij
(4)

1.2 节点间信任关联度
微博网络中通常用两个相邻节点所共享的边上的权重来衡量它们之间的信任关联度。两个相邻节点之间共享的边的权重越小,它们不是社区间传输信息的路径的概率就越大,则它们属于同一个社区的概率就越大,它们之间的联系就越紧密,信任关联度就越高。
通过分析可以得出,社区间的节点对的信息群度大于社区内部节点对的信息群度。显然,节点i与j之间的节点对的信息群度越小,它们之间交流、互动程度大,从而节点间的信任关联度就越大,属于同一个社区的概率就越大,则两个相邻节点vi、vj的信任关联度可定义如下:
nodeTrustRelation(vi,vj)=1-wij
(5)
一般情况,微博网络中除了相邻节点还有非相邻节点,非相邻节点之间可能没有路径或者有多条路径。一般的,两个节点之间的路径越长,它们的信任关联度就越小。将求最短路径问题作为计算两个非相邻节点之间的信任关联度的核心思想。经过两个非相邻节点之间最少边的那条路径决定了它们所求的最短路径。因此,可以利用广度优先搜索算法求得图中所有的非相邻节点之间的最短路径,然后再求出非相邻节点之间的最大信任关联度。
假设微博网络中非相邻节点vi和vj节点之间的最短路径为ShortPath(vi,vj)={(vi,vk),(vk,vm),…,(vn,vj)},通过分析可知,非相邻节点间的信任关联度是由它们之间所有最短路径上的节点对的信任关联度的乘积值来决定的。如果非相邻节点间的最短路径数为s,则选择其中乘积最大的作为非相邻节点的信任关联度,即:
nodeTrustRelation(vi,vj)
(6)
通过式(5)和式(6)可以构造微博网络的节点信任关联度矩阵R,即:
(7)
很明显,R是一个对称矩阵,由于节点与其自身的信任关联度,不对社区划分结果产生影响,故有nodeTrustRelation(vi,vi)=1,从而为了计算方便,将矩阵R主对角线上的元素值设为相应节点的度,因而有:
(8)
1.3 社区模块度
在社区结构发现的方法中,都缺乏一个量的定义来描述网络的社区结构。因而,不能直接从网络的拓扑结构去判断所求得的社区是否已经是实际网络中的社区结构。而且社区划分的合理程度取决于社区内部的连接是否紧密以及社区内部的连接数是否大于社区间的连接数。所以本文采用文献[12]所提出的社区模块度指标方法来评价微博社区划分的效果,它只与社区的内聚系数和连接密度相关,与社区的内部节点度值之和无关。
社区模块度可以分为两部分理解:(1) 社区内部节点连接的紧密程度,称为连接密度L(Si);(2) 社区内部节点的连接数是否大于社区间的节点连接数,称为内聚系数Coh(Si)。设定微博网络含有社区S1,S2,…,Sn,根据上述社区模块度的描述,则有如下定义:
(9)
其中,ni表示社区Si所包含的节点数;E(Si)表示社区Si内部所包含的边数。明显地,连接密度L(Si)描述了社区Si内部节点的连接密度。然后,计算社区Si的内聚系数Coh(Si),即:
(10)
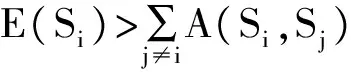
根据社区模块度的解释和上述L(Si)、Coh(Si)的描述,本文采用的社区模块度的定义如下,Q值越大说明社区结构越明显。
(11)
2 基于信任关联度微博社区发现算法
传统的K-means算法[13]是在使聚类准则函数最优原则的基础上,利用最接近于聚类中心的数据点作为类的中心以增强算法的鲁棒性。但其在处理过程中还存在着对初值敏感,对于不同的初始值会导致不同聚类结果的问题。
3.瘤组织凋亡相关分子Bcl-xl、Survivin、Bax、caspase3 mRNA表达的检测:提取各组移植瘤组织总RNA,检测RNA纯度及浓度,经逆转录后PCR扩增,以β-actin为内参。引物序列见表1,由金唯智公司合成。扩增产物经1.5%琼脂糖凝胶电泳分离,紫外成像系统观察、拍照并分析图像。
而基于节点信任关联度的微博社区发现算法(简称TRKM算法)是结合了微博网络的结构属性,并充分利用了用户的评论、转发、原创微博等属性来构造节点间信任关联度,通过将网络边权重的值进行动态设定,重新进行聚类分析。在所有节点都划分完之前,先以最大信任关联度原则选取新的代表对象,再在最小信任关联度原则的基础上进行模式归类,最后再通过初始聚类中心微调,将聚类中心轮换,具体步骤如下:
输入:微博网络节点的信任关联度邻接矩阵
输出:微博网络的社区结构
方法:
(1) 设center=∅(作为聚类中心的节点集合),V1=V0-center(除聚类中心以外的所有点的集合),初始j=2。根据式(5)和式(6)求出微博网络节点的信任关联度矩阵R。
(2) 选取信任关联度值最大的节点d1作为节点集合V1中第一个代表对象(聚类中心),以此类推,再选择节点集合V1中信任关联度值最小的节点d2作为第二个聚类中心,将这样的节点放在集合dx中,(x=1,2,…,n,n<|V1|,即先为每个类任意选择一个聚类中心,剩余节点根据其与聚类中心的信任关联度值大小分配给最近的一个类),其中:
center=center∪{dx},V1=V1-{dx}
(4) 初始聚类中心微调:以簇类各个节点轮换为相应的聚类中心,根据信任关联度矩阵R,计算出待划分节点集V1中各个节点vk(k=1,2,…,|V1|)与代表对象(簇类中心)节点集合center中各个节点di(i=1,2,…,|center|)之间节点的平均信任关联度的最小值rmin所对应的节点v∈V1,把它作为微调的簇类中心添加到center中。用rki表示节点vk与聚类中心di的节点信任关联度,rk表示节点vk与聚类中心center中各节点信任关联度的平均值,则:
center=center∪{v},V1=V1-{v}
转步骤(3)。
(5)V1≠∅,计算节点vk(k=1,2,…|V1|)与所有簇类中心节点之间的信任关联度值,哪个值越大,该节点就属于信任关联度最大值所对应的聚类。每个社区所属一个聚类,再将社区的划分结果输出出来。
(6) 求出当前社区划分结果下的社区模块度Q值。ifQj≥Qj-1thenj=j+1,转步骤(3);else结束(最大的社区模块度值就对应社区划分的最佳结果)。
3 实验分析
3.1 数据集
文中采用http://www.datatang.com/data/11819提供的新浪微博用户数据集进行实验。该数据集包含六万条新浪微博用户数据,包括用户ID、姓名、注册时间、数据采集时间、是否为认证用户、评论数、转发数、原创微博数、赞数等字段。
在文中提出的社区发现算法中用户之间的交互频率是一个很重要的影响因素。新浪微博中,用户类型主要可以分为两大类:明星用户和普通用户。由于两类用户的差异性会影响用户之间的交互频率值,文中在两类用户中各进行一组实验以验证本文算法的可行性和优化性。
分别从上述新浪微博用户数据包中采集两组测试用例,每组用例分别为深2度链接的用户数据组成,命名为A和B。A组用例是以加“V”用户“杨幂”为原始节点,她的粉丝及她所关注的人为深1度链接,他们的粉丝及所关注的人为深2度链接,共采集了551个用户的信息数据。B组用例是以普通用户“国舅爷”为原始节点,利用类似的方法同样采集了551个用户的信息数据。
3.2 实验结果分析
为了验证TRKM算法的性能,我们将该算法与传统K-means算法进行比较,随着K值不断增大,两种算法得到的社区结构也在不断变化。本实验记录了每个K值对应的两种算法在计算时得到的Q值。对比两种算法的Q值可以看出,K-means算法是在数据集中随意选择k个对象作为聚类中心,将所有节点聚类为k个社区,其Q值在达到一定值后趋于平稳。TRKM算法目的是获得一个最优社区划分结构,当Q值达到最大值,此时的社区划分结构为最佳结果。如图1和图2中描述了社区数从1到k情况下的Q值的变化趋势,TRKM算法的Q值几乎大于K-means算法,K-means算法得到的Q值达到一定数值时趋于平稳,而TRKM算法得到的Q值逐渐上升达到一个峰值,峰值对应的K值就是最优的社区结构数。根据社区模块度中Q值越大对应的社区结构越明显的原理,两组实验中,TRKM算法得到的社区结构相比于K-means算法更清晰、更准确。

图1 A组数据的社区模块度值趋势

图2 B组数据的社区模块度值趋势
为了将本实验结果进行可视化,可以利用社会网络分析工具Ucinet来形象的表示,图3和图4分别是两组实验利用TRKM算法得到的最终的社区划分结构,图3中共有16个社区并且社区数量比较多,图4中有40个社区,但其多为小团体结构。图3的社区结构比图4明显,零散节点也少于图4,因为A组数据的原始节点是领袖节点,她的影响力比较大,由她扩散出来的深2度链接用户间互动交流多,所以得到的社区划分结构比较明显。B组数据的原始节点是普通用户,影响力较小,以他扩散出来的深2度链接用户间交流也比较少,很明显,最终获得的社区划分结构不是很符合实际情况,会出现社团内部节点数量少而社团之间节点多的现象。原始网络被划分为社区后还存在零散的节点,这是因为有些用户只关注了其他用户,但他们之间的交流信息极少或者是没有。如何去除这些零散用户,得到一个比较纯粹的社区分布结构也是本文后期将要研究的内容。

图3 A组数据的社区划分结构

图4 B组数据的社区划分结构
总的来说,结合两组实验结果进行比较,K-means算法单纯将所有节点进行聚类分析,把每个节点进行分类,其对应的Q值只是一开始呈现上升趋势,直至聚类结束都没有得到Q值的峰值。而TRKM算法把用户间的互动交流情况作为社区划分的考虑因素进行节点聚类,随着K值的逐渐增大得到了Q值的峰值,聚类结束,同时得到了最优化的社区划分结构。通过对比两组实验最终的社区划分结构图可以发现,用户间的交流情况越频繁,社区结构越明显。从上述分析可知,微博社区结构的划分与用户间的交流情况以及交流频率相关。
4 结 语
本文提出了一种基于节点信任关联度的微博社区划分方法(TRKM算法),该算法提出了节点对的信息群度的概念,通过动态分配网络并计算边权重值,使划分结果更准确。通过微博用户之间的评论、转发等交互行为来刻画节点之间的动态连接关系,从而比较准确地描述微博用户之间的联系紧密程度(信任关联度),并最终提高微博网络社区划分的质量。微博网络中用户之间还存在兴趣相似度、用户交流度这些信息,如何将这种信息运用到社区发现的算法甚至推广到个性推荐系统中,将是本文接下来的研究目标。
[1] 刘大有,金弟,何东晓.复杂网络社区挖掘综述[J].计算机研究与发展,2015,50(10):2140-2154.
[2] 王林,戴冠中.基于复杂网络社区结构的论坛热点主题发现[J].计算机工程,2008,34(11):214-216.
[3] 张佳玉.基于节点相似度的社团发现算法研究[D].安徽工业大学,2014.
[4] 余紫丹,虞慧群.基于信任度的并行化社区发现算法[J].计算机工程,2015,41(4):81-86.
[5] 曾王辉.微博网络的社区发现研究[D].云南大学,2012.
[6] 闫光辉,舒昕,马志程,等.基于主题和链接分析的微博社区发现算法[J].计算机应用研究,2013,30(7):1953-1957.
[7] 蔡波斯,陈翔.基于行为相似度的微博社区发现研究[J].计算机工程,2013,39(8):55-59.
[8]YangC,DingH,YangJ,etal.ResearchofMicroblogCommunityDetectionBasedonClusteringAnalysis[J].AdvancesinInformationSciencesandServiceSciences,2013,5(3):25-31.
[9]NareshM,LramaniK.Communitydetectionintwitter[D].Baltimore:DepartmentofComputerScience,UniversityofMarylandBaltimoreCounty,2011:1-60.
[10] Deitrick W,Hu W.Mutually enhancing community detection and sentiment analysis on twitter networks[J].Journal of Data Analysis and Information Processing,2013,1(3):19-29.
[11] 杨长春,王天允,叶施仁.微博意见领袖影响力评价指标体系研究-基于媒介影响力视角[J].情报杂志,2014,33(8):178-183.
[12] 王林,戴冠中,赵焕成.一种新的评价社区结构的模块度研究[J].计算机工程,2010,36(14):227-232.
[13] 赵凤霞,谢福鼎.基于K-means聚类算法的复杂网络社团发现新方法[J].计算机应用研究,2009,26(6):2041-2043.
A NEW MICRO-BLOG COMMUNITY DETECTION ALGORITHM
Yang Changchun Liu Ling Li Xuejia Lü Chen Gu Huan
(SchoolofInformationScienceandEngineering,ChangzhouUniversity,Changzhou213164,Jiangsu,China)
The research on micro-blog community detection has important application value in public opinion analysis, microblog marketing and personalized recommendation, etc. In order to find communities in micro-blog social networks accurately and efficiently, this paper proposes a micro-blog community detection algorithm based on trust relation degree (TRKM algorithm). This algorithm constructs the trust relation degree between the nodes through user comments, forwarding number, original micro-blog article number and other attributes, and uses the module degree of micro-blog community to evaluate the effects of network community partition. Experiments are carried out respectively on the Sina micro-blog dataset of stars and ordinary users to compare TRKM algorithm with the traditional K-means algorithm. Experimental result indicates that TRKM algorithm can more effectively find the community structure in mirco-blog user relationship networks.
Micro-blog networks Community partition TRKM algorithm Trust relation degree Community module degree
2016-03-03。国家自然科学
61272367);江苏省产学研前瞻性联合研究项目(BY2014037-08)。杨长春,教授,主研领域:信息管理,数据挖掘。刘玲,硕士生。李雪佳,硕士生。吕晨,硕士生。顾寰,硕士生。
TP391
A
10.3969/j.issn.1000-386x.2017.03.035
