基于Trace的CMinus语言即时编译技术
2017-04-14陶胜召廖湖声高红雨
陶胜召 廖湖声 苏 航 高红雨
1(北京工业大学计算机学院 北京 100124)2(北京工业大学软件学院 北京 100124)
基于Trace的CMinus语言即时编译技术
陶胜召1廖湖声2苏 航1高红雨1
1(北京工业大学计算机学院 北京 100124)2(北京工业大学软件学院 北京 100124)
即时编译技术是改进动态语言性能的有效手段。基于踪迹(Trace)的即时编译技术能够在运行时识别出频繁执行的程序片段(热踪)并进行编译优化,在相当多的场景下能够提高程序整体的执行效率。然而,这种涉及底层代码优化的即时编译系统开发难度较大,导致其应用范围受到一定限制。为此,一种针对C语言子集CMinus的热踪编译技术被提出。利用这种热踪编译技术及其支撑工具,任何能够翻译为CMinus的开发语言都可以使用该技术提高程序执行效率,任何采用CMinus语言实现的算法也都可以得到热踪编译的支持。实验结果表明这种即时编译技术能够有效地提高程序的执行效率。
CMinus 即时编译 基于踪迹 环境切换
0 引 言
为了提高虚拟机环境中程序解释执行的效率,各种即时编译技术已经得到了广泛的应用。和早期的热点编译(Hotspot[1])技术相比,基于Trace的即时编译技术按照控制流中频繁使用的执行路径作为即时编译的应用对象,能够完成细粒度的程序优化。这种热踪编译技术近年来已经成功地应用于Java、JavaScript、Python和Microsoft CIL等多种解释型语言的程序优化。
然而,基于Trace的即时编译系统具有较高的开发难度。对于特定的虚拟机及其机器语言,开发者必须充分了解虚拟机的工作原理,熟悉各种语言功能的实现方法,经过艰苦的底层软件开发才能实现这种即时编译。
为了扩展基于Trace的即时编译技术的应用范围,减轻开发难度,本文提出一种软件开发方法及其支撑工具。按照这种开发方法,开发者只要将开发语言翻译为C语言的一个子集CMinus[2],就可以利用本项目提供的CMinus即时编译系统,实现这种语言的即时编译。本文的主要贡献是:
1) 提出了一种即时编译系统的实现方法。基于Trace和基于函数的CMinus语言即时编译,这种方法可用于实现各种程序设计语言的即时编译。
2) 实现了从CMinus语言到Java字节码的即时编译,其他语言只要翻译为CMinus就可以通过即时编译技术得到程序优化。
3) 研制了一个CMinus执行引擎,采用解释执行和热踪编译执行的混合模式,实现运行时的CMinus程序动态优化。
1 基础概念
1.1 CMinus概述
CMinus是C语言的子集。作为一种命令式语言,CMinus支持一般的函数和递归函数的定义和调用,支持顺序、选择、循环等结构且支持基本数据类型和一维数组等数据结构,这使得它足以实现常用编程语言的主要程序设计功能。表1是CMinus文法的核心部分(其中*代表0或多个,[]代表0或1个)。
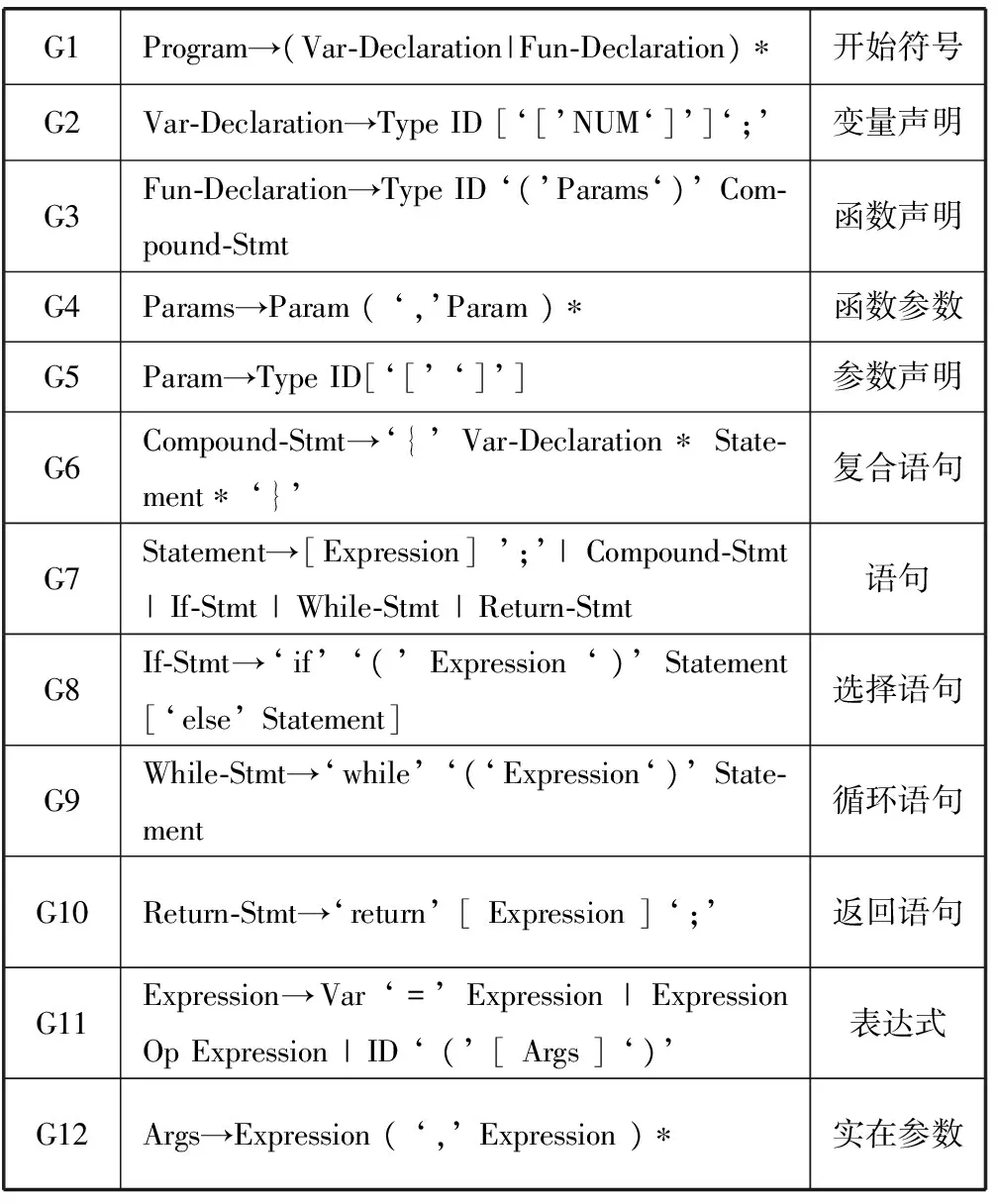
表1 CMinus语言核心文法
1.2 即时编译
JIT(Just-In-Time)编译是一种在解释执行时通过识别原有程序中频繁执行的代码并将其编译为目标代码,当再次执行到该段代码时直接调用已生成的目标代码以获得更高运行效率的动态优化技术。目前,按照编译的粒度可以将即时编译技术分为两种,一种是基于函数的,一种是基于Trace的。
基于函数的即时编译是对频繁执行的整个函数进行编译,利用生成的目标代码来代替函数的解释执行,以求获得效率的提升。然而,按照这种方法,函数中非频繁执行的片段也会被编译,因此增加了不必要的编译时间。
基于Trace的即时编译是将一段频繁执行的代码片段(路径)作为一个编译单元,并仅对该代码片段进行编译。该代码片段由一个线性且连续的指令序列组成,仅有一个入口,但有一个或多个出口。而且基于Trace的即时编译对热点的记录并不局限于一个函数中,一条Trace可能对应多个函数,如果在一个程序中有多个频繁执行的路径,这些路径可以分别被识别成不同的Trace。因此相比基于函数的即时编译,基于Trace的即时编译的识别精度更高且能通过避免编译不是频繁执行的代码,减少不必要的编译开销。
在CMinus程序中,Trace代表控制流图中遇到的一段循环路径,一条Trace可以表示为一个如下的二元组:
Trace= (Head, BlockLists)
其中:Head是Trace中的第一个基本块标识。BlockLists是Trace中的基本块顺序序列。控制流只能从基本块中第一个指令进入该块,并且除了基本块中最后一个指令,控制流在离开基本块之前不会停机或者跳转,因此一个基本块列表唯一的标识了一条Trace。
表2是一个简单的CMinus程序,该程序生成的基本块流图[3]如图1所示。执行引擎针对该基本块流图解释执行时,B2作为循环的开始块被称作一条Trace的起点,从该处开始记录一条Trace,并将之后遇到的普通块陆续加入到当前Trace中,当再次执行到B2时即完成当前Trace的记录。如果偶数个数较多时,则粗体箭头所组成的路径(B2→B3→B4→B6)首先被识别成热点路径并编译为Java字节码,再次执行到该路径时直接通过JVM调用生成的字节码。

表2 CMinus程序示例
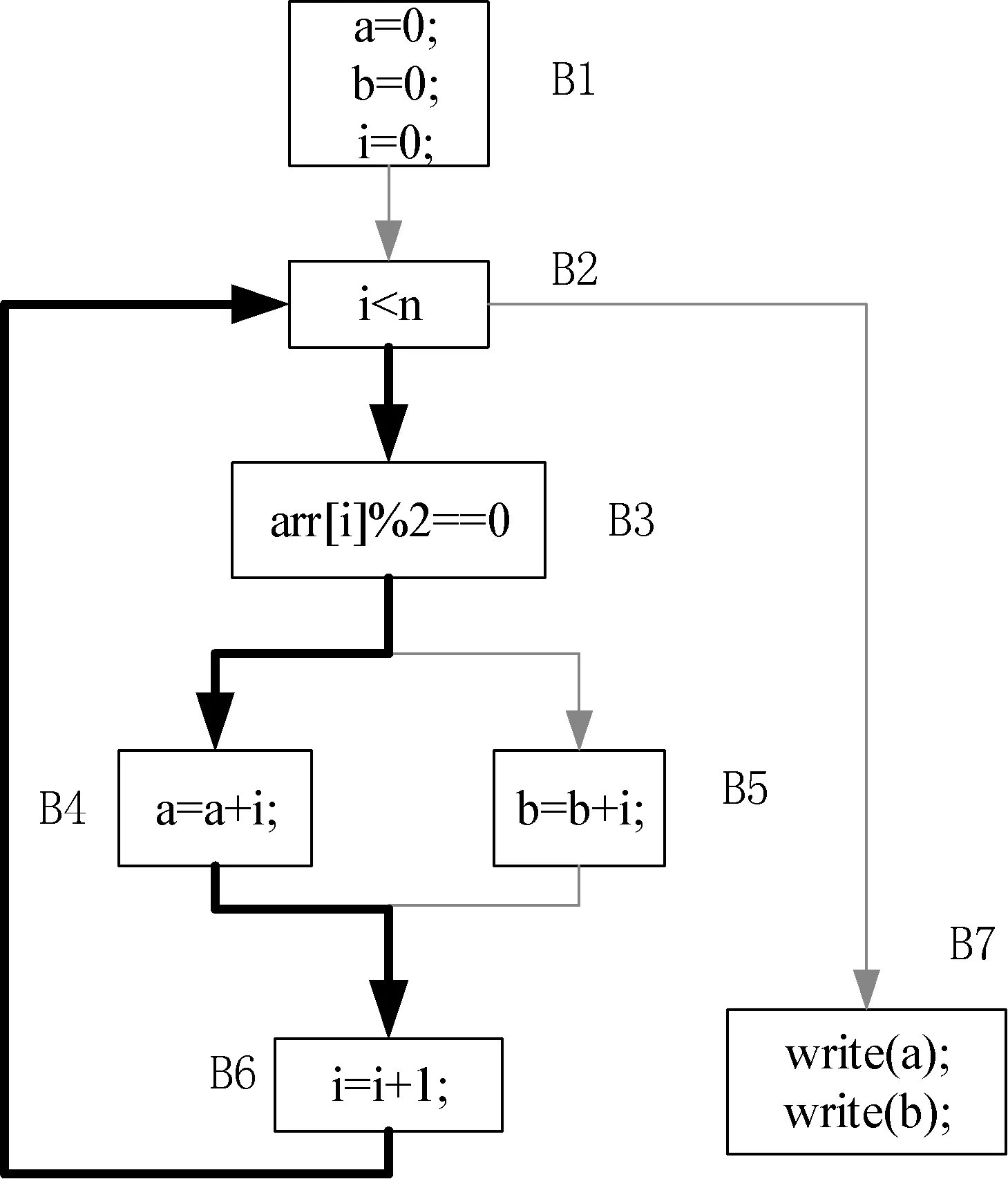
图1 fun函数基本块流图
1.3 JVM与Java栈帧
JVM用于执行生成的Java字节码,其中Java栈帧[4]主要用于方法调用和执行,每当调用一个方法就对应一个栈帧的入栈过程,而一个方法执行完成则对应一个栈帧的出栈过程。栈帧中存储了每个方法对应的局部变量表、操作数栈、动态链接和方法返回地址等信息。其中:
(1) 局部变量表:是一组变量值的存储空间,用于存储方法参数和方法内部定义的局部变量。
(2) 操作数栈:是一个后入先出栈,当JVM进行方法执行时,各种字节码指令通过出栈和入栈操作往操作数栈中写入和提取内容。
(3) 动态链接:指向该栈帧所属的方法的引用。
(4) 方法返回地址:指向一个该方法被调用的位置,方便该方法返回后继续执行。
2 基于Trace的即时编译技术
一般来说,基于Trace的即时编译划分为锚点识别、Trace探测、生成目标代码、执行目标代码四个阶段,执行引擎在对每个基本块进行解释执行时都会激活如图2所示Trace探测执行过程。
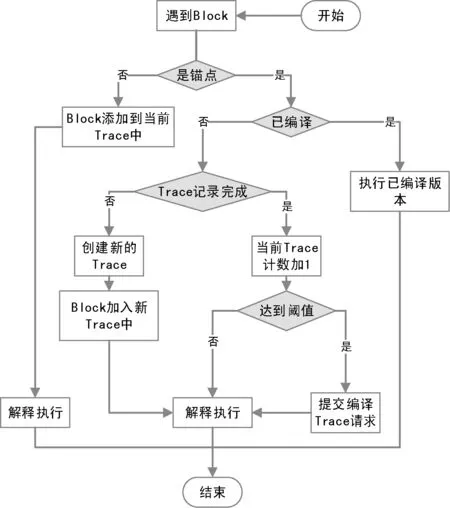
图2 热点Trace探测执行流程
2.1 锚点识别
在不同的基于Trace的探测技术中,锚点的定义并不完全相同,而且由于探测的代码一般都是底层的代码,缺乏翻译的高级信息,因此这些锚点无法预先进行标识,导致锚点识别耗费了一部分时间开销。为了省去这部分开销,在本文中,我们将CMinus程序中所有循环体的头部作为锚点,并从该位置进行Trace的记录。
2.2 Trace探测
解释执行过程中,需要通过判断一段代码块的执行次数是否达到阈值作为该段代码是否需要被编译的条件,此时需要借助Trace探测技术。
在进行Trace探测之前,先会创建一个映射表TraceCountMap
如图2所示,在解释执行过程中,将会针对遇到的基本块B是否是锚点进行判断。如果B为普通基本块,直接将该基本块B加到当前Trace中,并对B进行解释执行。如果B是锚点,则查找是否存在以B为锚点的目标代码,如果存在,直接调用目标代码执行;如果不存在,便以该锚点为起点记录一条新的Trace,并将后续的普通块加到当前Trace中,直到再次遇到该锚点即完成该Trace的记录。
2.3 生成目标代码
CMinus指令翻译成目标代码时可以对生成的控制流图进行遍历并根据控制流图对应的抽象语法树上的各运算节点的语义翻译成对应的Java字节码。如果该节点没有直接对应的字节码指令,可以定义一个实现该功能的Java静态方法,并将调用该静态方法的指令添加到该节点处生成的Java字节码中。
热点Trace翻译成Java字节码后,当需要执行热点Trace翻译成的Java字节码时,Trace此时仍处于解释环境中,需要将其中的变量值传递到编译环境。而解释环境和JVM的运行时环境中变量的索引位置并不一定相同,为了保证解释环境和编译环境中的变量值的顺利传递,在生成目标代码前需要先对该Trace中的变量进行一次遍历,生成一个<变量名,<解释环境索引,编译环境索引>>的映射表VarMap。如图3所示,根据映射表中变量的个数在生成的Java字节码类中定义一个同样大小的局部变量表,用于存放从解释环境中传递过来的变量值,并根据VarMap中保存的变量在编译环境中的索引来生成Java字节码中对应的loadn或storen等指令。其中环境指保存着多个变量名/变量值对应关系的列表,由于列表中变量的保存位置与名字存在一一对应关系,因此在实现中会用值的保存位置来替代变量名。

图3 局部变量的对应关系
如果对热点Trace进行翻译时遇到分支节点,可能一个分支在该Trace中而另一分支不在该Trace中,JVM在执行该分支处翻译的目标代码时可能导致执行引擎从编译环境切换到解释环境,因此需要在跳转到另一个分支处插入一个Guard指令进行标记。如图1中B3→B4和B3→B5各有一个路径,如果偶数个数较多,加粗的箭头所组成的路径(B2→B3→B4→B6)首先被识别为热点Trace,该Trace翻译生成的Java字节码如表3 所示。由于B5不在该Trace中,因此在B3→B5处应插入一个Guard标记(如表3中右侧Java字节码中GUARD部分所示),并将所有的Guard标记所在的位置进行记录,在字节码生成完成后在所有记录的Guard标记处插入从编译环境切换到解释环境的代码。
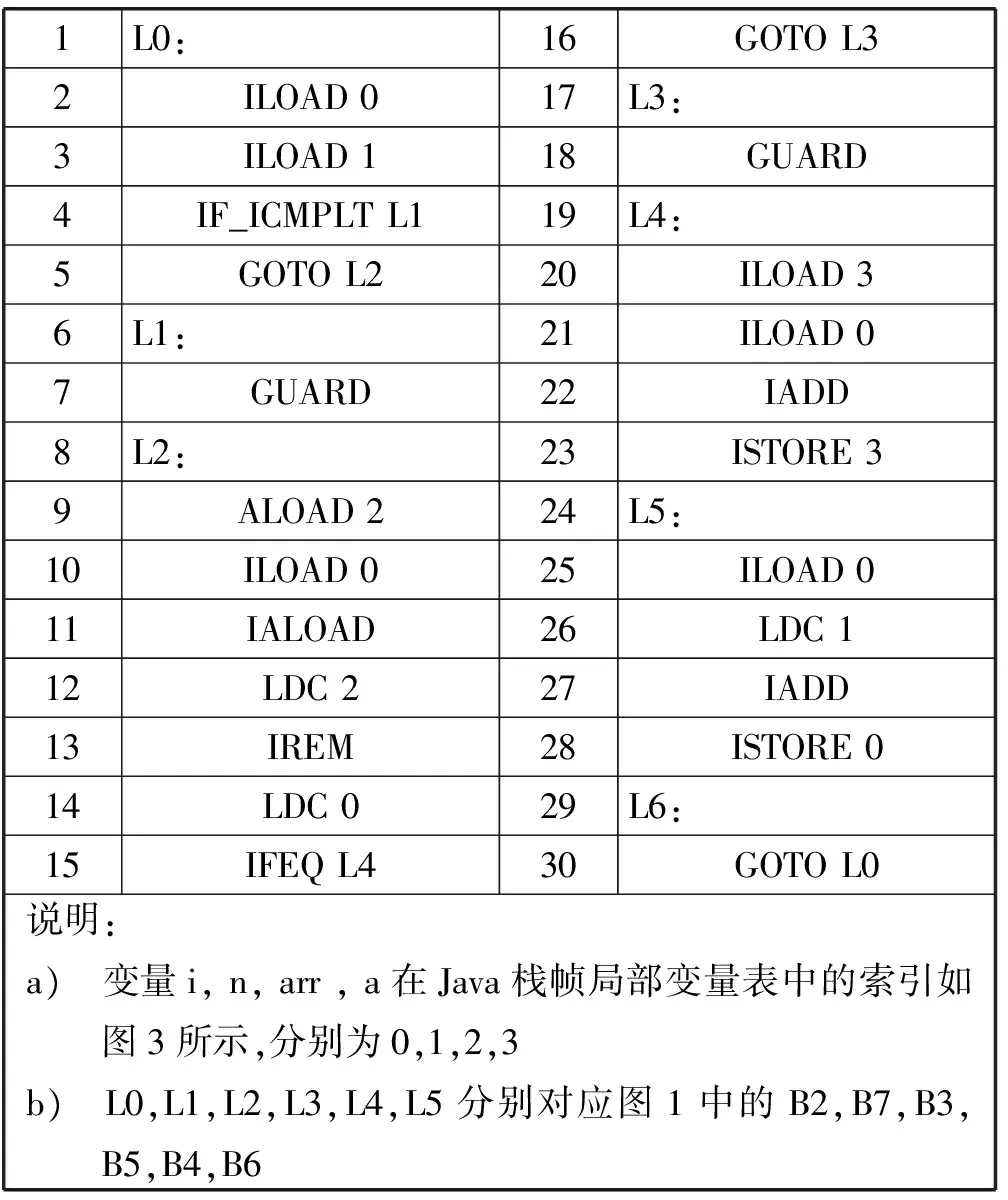
表3 翻译成目标代码
翻译生成的Java字节码是一个以该Trace的锚点名为函数名的静态方法,并保存在一个以该函数名为索引的映射表TraceMap
2.4 执行目标代码
解释执行时遇到锚点,首先从存放生成的Java字节码的映射表TraceMap中检索是否存在已编译好的以该锚点为起点的Trace,如果存在则将解释环境中的必要信息传递到编译环境,并直接通过JVM调用生成的Java字节码执行。
JVM执行热点Trace生成的Java字节码时,如果遇到未编译的分支,即遇到Guard指令,将导致执行环境从编译执行切换到解释执行,此时需要将编译环境中的变量值等信息传递到解释执行环境,这种现象被称作旁路退出。CMinus解释器将继续解释执行Guard所指向的基本块,并从该基本块继续进行Trace的探测。 如图1中,如果T1:{B2, (B2,B3,B4,B6)}首先被编译,在解释执行过程中如果遇到B2,将通过JVM执行该Trace对应的字节码,如果在B3处发生旁路退出进入B3→B5分支,将导致从编译环境切换到解释解释环境,并从B5处继续进行Trace的探测,同时将B5加入到当前Trace中。
2.5Trace合并
当一条路径识别为热点Trace且该Trace中包含其他Trace中的锚点或者其他热点Trace中包含当前Trace对应的锚点时,如果不进行Trace合并,将导致在执行这些热点Trace生成的字节码时在这些锚点处频繁的进行环境切换,增加执行开销。如图 4所示,以4为锚点的Trace:T1(4→5→6→8→9)首先被识别成热点Trace并被编译为目标代码,由于此时以5为分支的路径5→6在T1中而5→7不在T1中,因此将在T1的5→7处生成的字节码中插入Guard标记。如果另外一条以4为锚点的路径T2(4→5→7→8→9)也被识别为热点Trace, 若不进行Trace合并,将在T2的5→6处生成的字节码中也插入Guard标记。当执行T1生成的目标代码时,如果执行到分支节点5处的条件导致进入5→7分支,因为遇到Guard标记导致发生旁路退出。同理,当执行T2生成的目标代码时,如果执行到分支节点5处的条件导致进入5→6分支,将再次因为遇到Guard标记而发生旁路退出,从而由编译环境切换到解释环境,返回到4处时再次从解释环境进入编译环境。如果这种切换频繁发生,会造成一定的性能损耗。
为了解决上述问题,我们将分如下三种情况对热点Trace进行合并:
(1) 当前Trace的计数超过阈值时,如果其他已编译的Trace中包含了该Trace的锚点,则将当前Trace添加到其他Trace中进行合并。
(2) 当前Trace的计数超过阈值时,如果当前Trace中包含了其他已编译的Trace中对应的锚点,则将其他热踪中的节点去重后合并到当前Trace中。
(3) 当前Trace有部分基本块在其他Trace中,且锚点一致,则将当前Trace中的基本块去重后并入其他热踪中。
如图4所示,T1: ({4}, {4, 5, 6, 8, 9})首先被编译为目标代码,当T2 ({4}, {4, 5, 7, 8, 9})也被识别为热点Trace时。由于T1和T2包含了同一个锚点4且有部分基本块重合,对应Trace合并的第3种情况。因此在生成T2的目标代码时将利用T1中已生成的目标代码进行合并得到Trace:T1-2:( {4}, {4, 5, 6, 7, 8, 9}) 对应的目标代码。当T3最后被识别为热点Trace时,由于T3中包含锚点4并存在以4为锚点的Trace:T1-2的目标代码,符合Trace合并的第二种情况,因此在生成T3对应的目标代码时将利用T1-2已生成的目标代码生成合并后的Trace:T1-2-3:( ({2}, {2, 3, 4, 5, 6, 7, 8, 9,10})) 对应的目标代码。
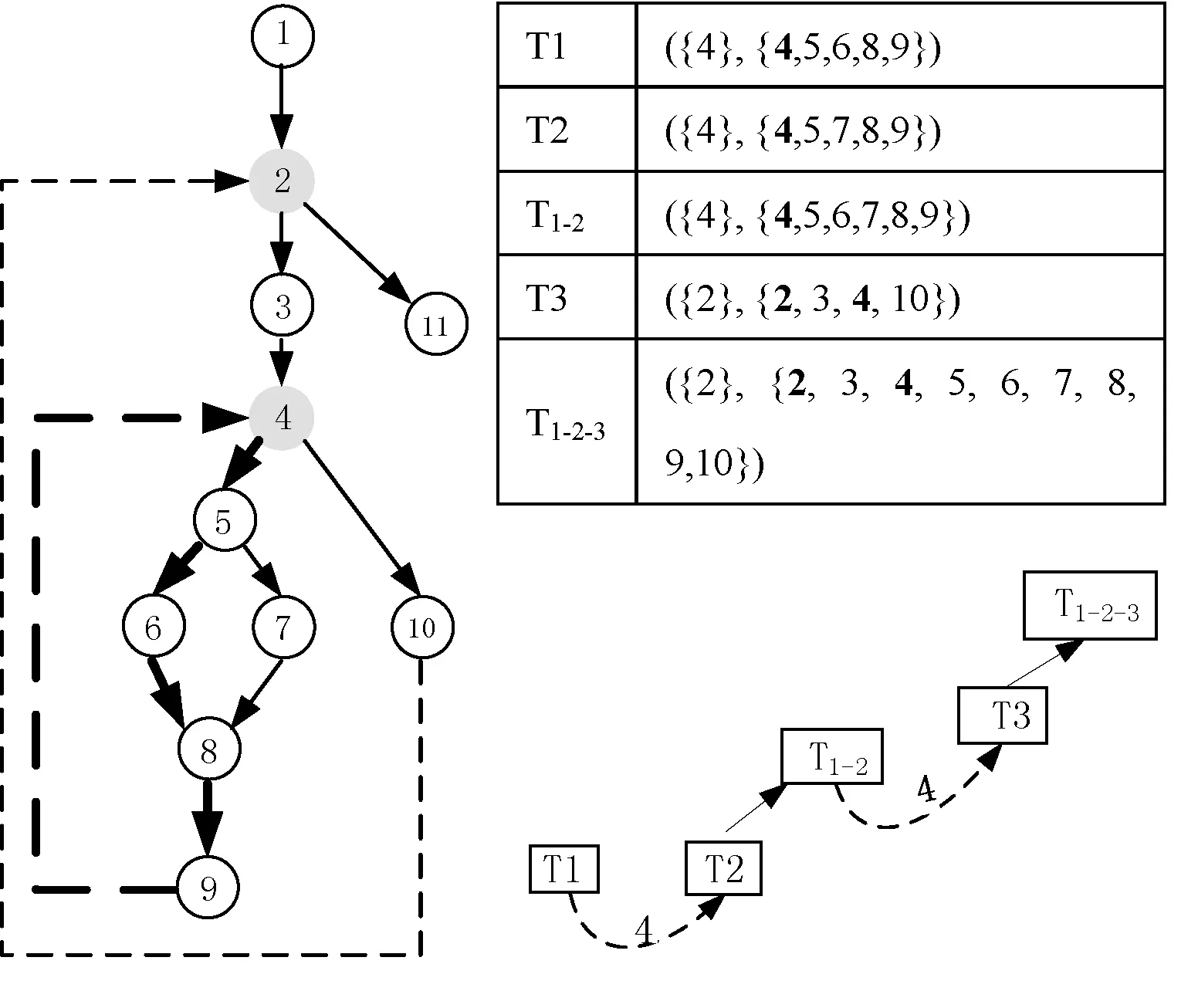
图4 Trace合并
2.6 环境切换
解释执行遇到锚点,如果该锚点已存在编译好的目标代码,需要从解释环境切换到编译环境,而从编译执行切换到解释执行时也需要将编译环境中的变量值等信息返回到解释执行环境。因此需要在Java字节码的开始位置生成调用代码序列,将解释执行环境中的变量值传递到编译环境的局部变量表中。并在热点Trace生成的Java字节码的Guard处插入从编译环境切换到解释环境的代码,JVM根据该Guard处插入的代码将编译环境中的变量值传递到解释环境。
如图5中所示,由于解释和编译环境各自需要维护一个保存其变量值的环境,为了方便环境的切换,我们在解释环境中定义了一个Environment对象,并在编译环境中定义了一个该对象的引用,用于在编译环境中使用解释环境中的Environment对象。同时在编译环境中维护一个Trace中所有变量在解释环境和编译环境中位置索引的映射表VarMap,以便实现变量值在解释和编译环境中的顺利切换。

图5 环境切换
(1) 解释执行到编译执行的切换
解释执行遇到已编译好的Trace,为了保证解释执行环境中的变量值准确地传递到编译环境,我们在生成Java字节码的类中设计了一个静态、公有的方法initFields,在生成Java字节码时(如表3中L0之前),先调用该静态方法。该方法根据之前得到的变量映射表VarMap以及编译环境中指向解释环境对象Environment的引用从解释环境中取变量值并赋给编译环境对应的局部变量表中,如图5中实线所示。
(2) 解释执行到编译执行的切换
在执行编译好的Java字节码的过程中,如果遇到了Guard指令引起控制流从该Trace进入未编译分支,为了保证编译执行环境中的变量值准确地传递到解释环境,我们定义了一个方法resetEnv用于在所有的Guard处插入从编译环境切换到解释环境的代码。该方法根据变量映射表VarMap以及指向解释环境中Environment对象的引用将当前JVM对应栈帧的局部变量表中的变量值更新到解释环境中,如图5中虚线所示。
3 即时编译的系统框架
本系统首先对CMinus程序进行分析生成控制流图,然后在对其进行解释执行时进行Trace探测,识别出其中的热点Trace,并将热点Trace送入JIT编译器翻译为Java字节码。当解释执行过程中遇到已编译的热点Trace时通过JVM调用已编译好的Java字节码编译执行,并将执行结果返回。未编译的分支仍然解释执行,同时继续进行热点Trace的记录。同时在CMinus执行引擎中考虑了解释执行和编译执行环境的切换,如图6所示。
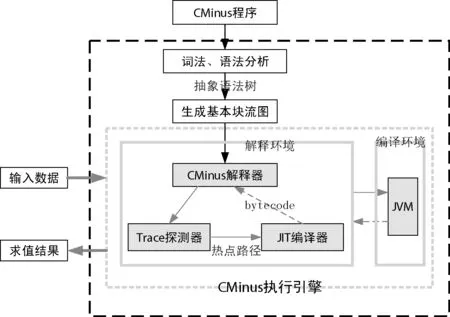
图6 整体框架
4 实 验
为了验证本文提到的基于Trace的即时编译执行引擎的性能,在Java平台下实现了图6所示的一个通用执行引擎,并设计了一组实验来比较CMinus程序在解释执行与基于Trace的即时编译执行下的效率。测试环境如下:Windows7操作系统,Intel(R)Xeon(R)CPUE5-1607 0 @ 3.00GHz(3 000MHz),内存:8.00GB,主硬盘1 000GB。开发环境为Eclipse+Java+jdk1.7。
本文的实验中使用的程序均为自定义用例,测试案例中包含了单重循环及多重循环,以及单分支与多分支的情况,并分别测试程序在解释执行、基于Trace的即时编译情况下的性能。如表4所示。
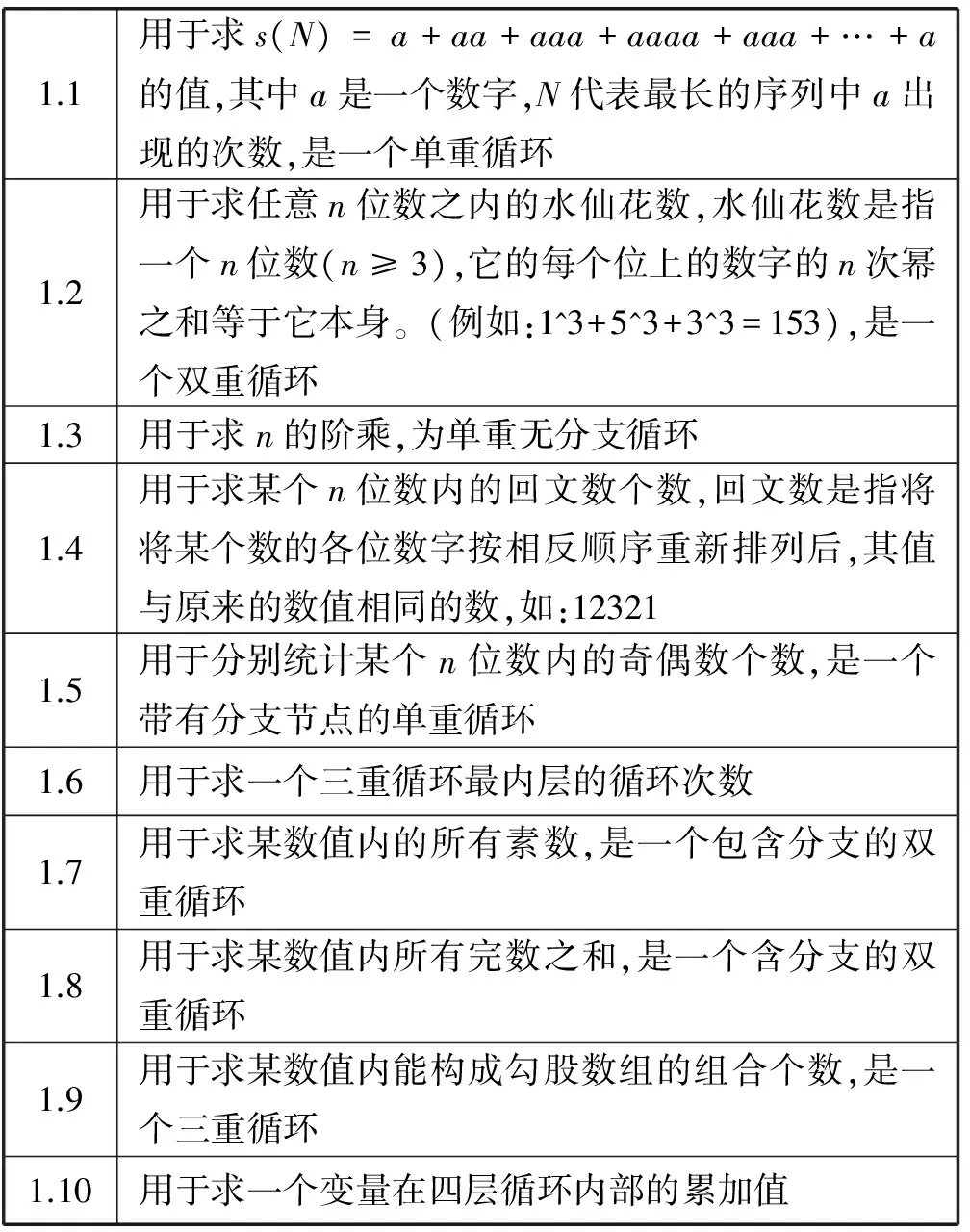
表4 测试案例
如图7所示,一般情况下,当执行次数足够多时,采用基于Trace的即时编译比单纯的解释执行效率都有一定程度的提高。案例1.4、1.6、1.7、1.10由于执行次数较多,采用即时编译技术相对于解释执行的时间开销减少了将近一半,但是案例1.1为单重循环且执行次数较少,由于Trace探测和编译的开销,其执行效率反而不如解释执行高。
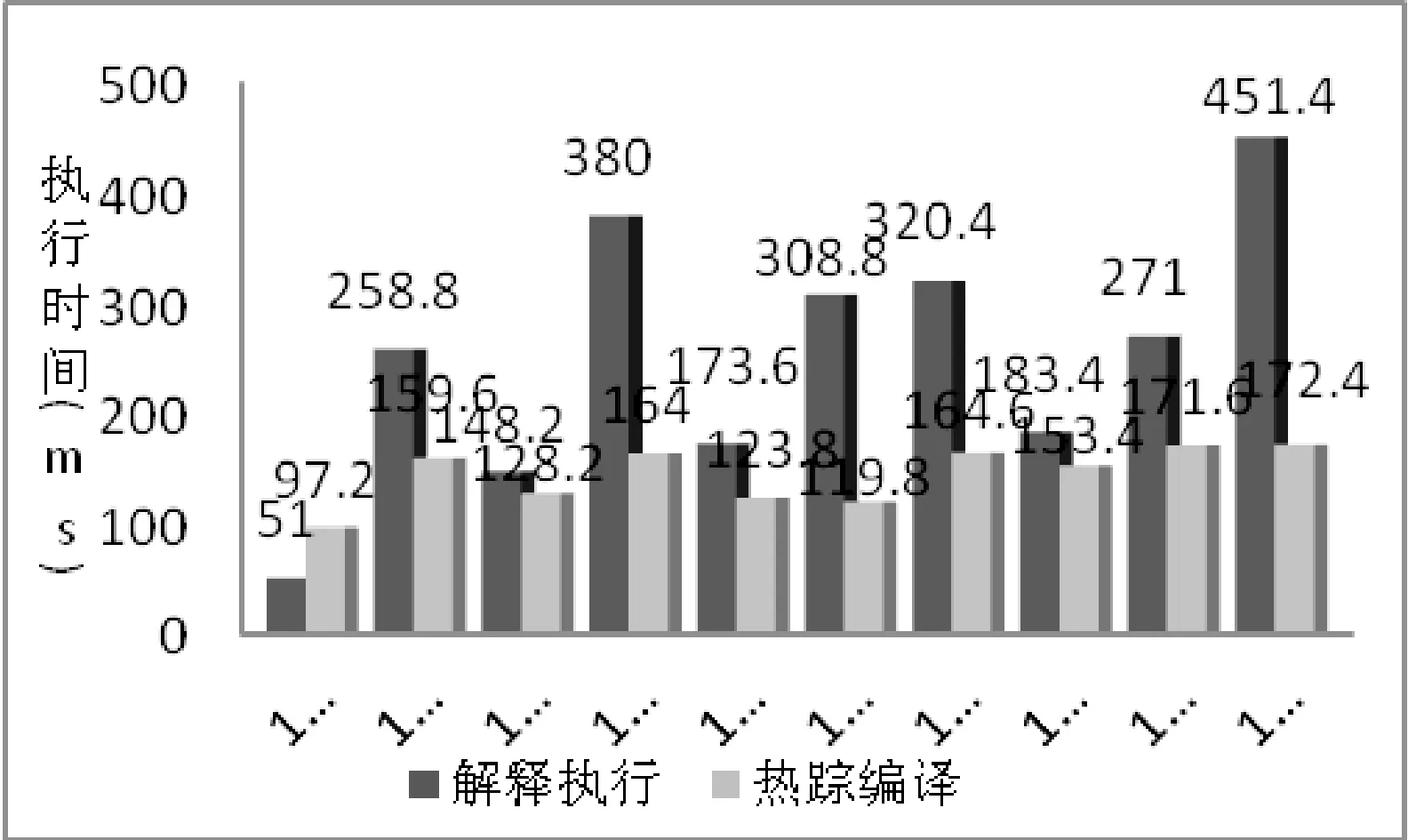
图7 解释执行与热踪编译比较
图8显示了不同案例的加速比(加速比= 解释执行时间/即时编译时间×100%),由于案例1.6和1.10分别为三重循环和四重循环且循环内无分支节点,而且内循环次数较多,所以加速比也比较高。
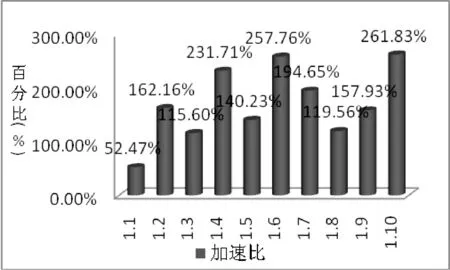
图8 加速比
如图9所示,不同案例在采用基于Trace的即时编译时其编译时间也有明显的特征, 其中案例1.1、1.3和1.5都是单重循环,因此编译时间较短。案例1.2、1.4、1.7、1.8和1.9由于包含双重或三重循环且包含分支节点,因此多个Trace之间包含重复节点,从而增加了Trace合并及编译的时间。案例1.10由于包含四重循环,尽管没有分支节点,但由于增加了Trace合并时间,因而编译时间也较长。
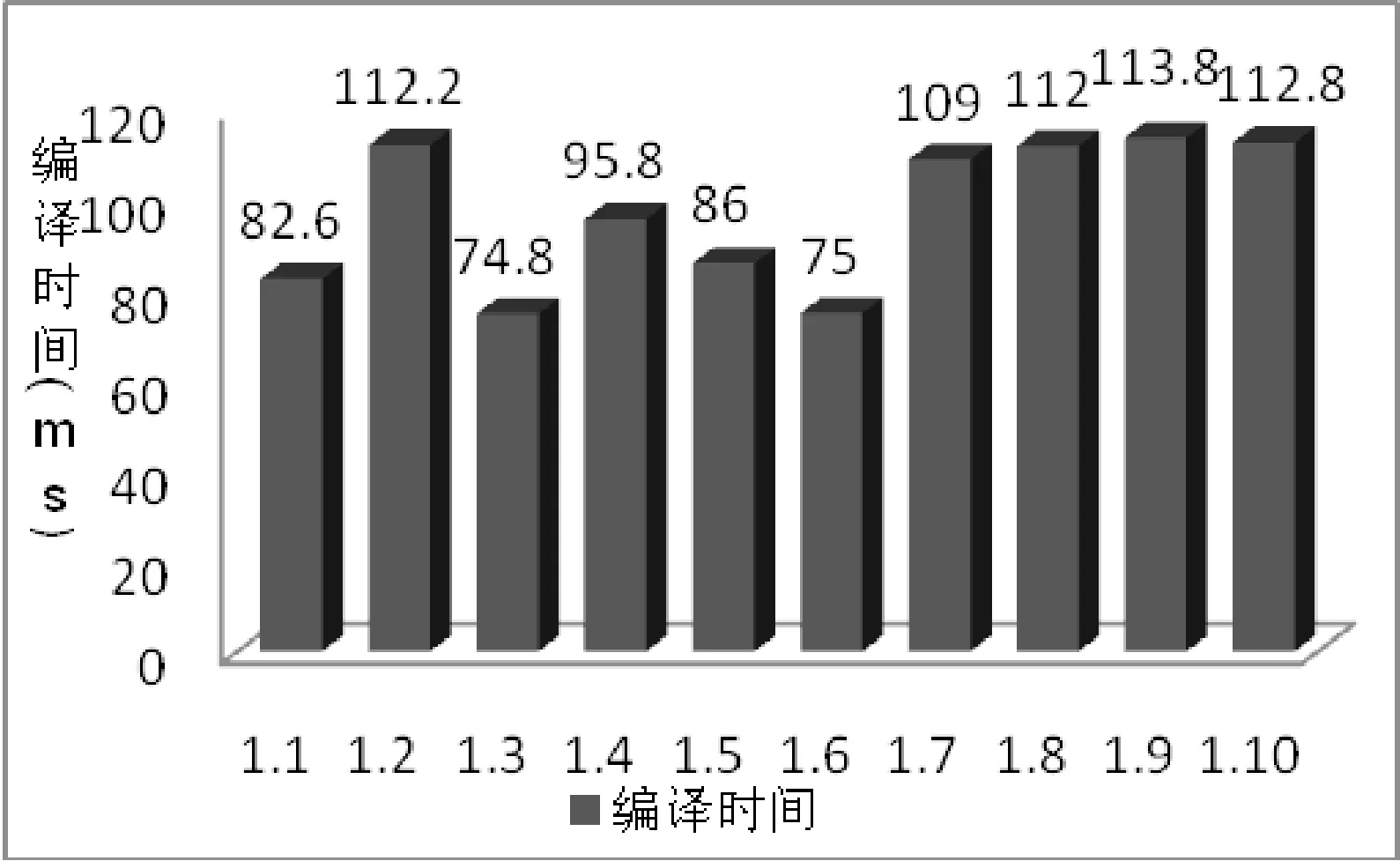
图9 编译时间
实验结果表明:当执行次数足够多时,使用基于Trace的即时编译,其执行效率相对于解释执行能有明显的提升。在包含多重循环或分支节点时,由于Trace探测及合并的开销,其总的编译时间也稍长,因此需要在较多的执行次数时才能超过解释执行效率。但是当执行次数较少时,如案例1.1中所示,由于Trace探测和编译的开销,其执行效率可能还不如解释执行效率高。
5 相关工作
1999年,Sun公司提出Hotspot[1]技术,从Java1.3开始,JVM默认支持该技术。它通过自适应优化技术,使Java应用程序的性能大步提升。该技术先对代码进行分析,以检测程序的关键热点,然后集中编译并优化这些热点代码。但是该方法以整个方法为单位进行即时编译,在这种情况下,方法内执行频率不高的代码也将参与到即时编译中,增加了编译开销。
为此,GalA等人提出了基于Trace的即时编译[5],在进行热点探测、即时编译时以trace为单位,每个trace仅仅包含程序中执行频繁的代码。因此,就编译粒度而言,基于trace的即时编译比基于方法的即时编译要精细得多。
Dynamo[6]是第一个基于Trace优化的编译器,但是由于Dynamo探测的对象是机器指令,记录的热点trace也停留在机器码层面,缺乏解释器层面的高级信息。
HotpathVM和TraceMonkey[7]都将字节码作为探测对象,动态识别出频繁执行的热点trace,并将其翻译为机器码。但是这两种技术中并没有考虑Trace的合并,可能会因为遇到旁路退出的情况而导致频繁地进行环境切换,增加了执行开销。而本文中由于对包含重复节点的Trace之间进行了合并,省去了频繁的进行环境切换的时间开销,可以更好地提高性能。
此外,基于Trace的即时编译广泛用于脚本语言的开发中,例如为Python开发的PyPy[8],为JavaScript开发的SPUR[9],以及为Lua开发的LuaJIT[10]。安卓Dalvik[11]虚拟机中也使用了基于Trace的热点探测技术。
但是目前实现的基于Trace的即时编译器通常是在字节码或机器码这种低层代码上进行Trace探测,缺乏解释器的高级信息,这使得Trace的探测需要增加大量的额外标注,而且这些代码的阅读难度较大。而本文直接针对CMinus这种较高级的语言进行Trace探测及编译,可以方便地对控制流信息进行跟踪且便于理解。
6 结 语
为了扩展基于Trace的即时编译技术的应用范围,本文针对CMinus语言设计了一个基于Trace的即时编译系统,介绍了基于Trace的热点探测技术,并将解释执行过程中识别的热点Trace翻译成Java字节码,通过JVM进行调用。同时为了避免多个Trace因包含重复节点而频繁的进行环境切换,引入了Trace之间的合并技术。由于该系统支持解释执行和编译执行两种模式,为了顺利地实现执行环境之间的相互切换,本文同时介绍了环境切换的设计及方法,实现了运行时的CMinus程序动态优化。
通过实验证明,与解释执行相比,当识别出的热点Trace执行次数足够多时,该技术切实有效地提高了程序的执行效率。在今后的工作中,我们将对识别出的Trace生成的字节码进行一些优化工作,以期进一步提高程序执行效率。
[1]KotzmannT,WimmerC,MossenbockH,etal.DesignoftheJavaHotSpotclientcompilerforJava6[J].TransactionsonArchitectureandCodeOptimization,2008,5(1):7-10.
[2] 劳顿(KennethCLouden).编译原理及实践[M].冯博琴,等译.北京:机械工业出版社,2000.
[3]AlfredvAho,RaviSethi,JeffreyDUllman.CompilersPrinciplesTechniquesandTools[M].3rded.Addision-WesleyPublishingCompany,1996.
[4]LindholmT,YellinF,BrachaG,etal.TheJavavirtualmachinespecification[M].3rded.AddisonWesley,2013.
[5]GalA,ProbstCW.HotpathVM:aneffectiveJITcompilerforresource-constraineddevices[C]//Proceedingsofthe2ndinternationalconferenceonVirtualexecutionenvironments.NewYorkUSA:ACMNewYork,2006:144-153.
[6]BalaV,DuesterwaldE,BanerjiaS.Dynamo:Atransparentdynamicoptimizationsystem[C]//Proceedingsofthe2000ACMSIGPLANConferenceonProgrammingLanguageDesignandImplementation.Canada:ACMSIGPLANNotices,2011:41-52.
[7]GalA,EichB,ShaverM,etal.Trace-basedjust-in-timetypespecializationfordynamiclanguages[C]//Proceedingsofthe2009ACMSIGPLANconferenceonProgramminglanguagedesignandimplementation.NewYorkUSA:ACMNewYork,2009:465-478.
[8]BolzFC,CuniA,FijalkowskiM,etal.Tracingthemeta-level:PyPy’stracingJITcompiler[C]//Proceedingsofthe4thworkshopontheImplementation,Compilation,OptimizationofObject-OrientedLanguagesandProgrammingSystems.NewYorkUSA:ACMNewYork,2009:18-25.
[9]BebenitaM,BrandnerF,FahndrichM,etal.SPUR:atrace-basedJITcompilerforCIL[C]//ProceedingsoftheACMinternationalconferenceonObjectorientedprogrammingsystemslanguagesandapplications.NewYorkUSA:ACMNewYork,2010:708-725.
[10]YermolovichA,WimmerC,FranzM.Optimizationofdynamiclanguagesusinghierarchicallayeringofvirtualmachines[C]//Proceedingsofthe5thSymposiumonDynamicLanguages.USA:Florida,2009:79-88.
[11]PerezGA,KaoCM,ChungYC,etal.Ahybridjust-in-timecompilerforandroid:comparingJITtypesandtheresultofcooperation[C]//Proceedingsofthe2012internationalconferenceonCompilers,architecturesandsynthesisforembeddedsystems.ACM,2012:41-50.
A TRACE-BASED JUST-IN-TIME COMPILATION TECHNIQUE OF CMINUS
Tao Shengzhao1Liao Husheng2Su Hang1Gao Hongyu1
1(CollegeofComputerSciences,BeijingUniversityofTechnology,Beijing100124,China)2(SchoolofSoftwareEngineering,BeijingUniversityofTechnology,Beijing100124,China)
JIT (Just-In-Time) compilation technique is an effective method to improve the performance of dynamic language; a Trace-based JIT compilation technique can detect the frequently executed parts of the program at runtime, and compiles it into target language or doing some optimization work. Moreover, it can improve the overall efficiency of the program in a considerable number of scenarios. However, it is difficult to develop a JIT Compiler, which involves the optimization of the underlying code, thus limited its application range. Therefore, we proposed a Trace-based JIT compilation technique used on CMinus which is a subset of C language for this purpose. Any language can be translated into CMinus can use this technique to improve the execution efficiency of the program. Any algorithm implemented by CMinus can be supported by this Trace-based compilation technique. The experimental results show that this method can effectively improve the efficiency of the program.
CMinus JIT compilation Trace-based Environment alternation
2016-01-10。国家自然科学基金青年
61202074);北京市自然科学
基金项目(4122011)。陶胜召,硕士生,主研领域:动态编译。廖湖声,教授。苏航,讲师。高红雨,副教授。
TP314
A
10.3969/j.issn.1000-386x.2017.03.010
