基于Hadoop MapReduce的大规模线性有限元法并行实现
2017-04-14林海铭
林 海 铭
(广东省建筑科学研究院集团股份有限公司 广东 广州 510500)
基于Hadoop MapReduce的大规模线性有限元法并行实现
林 海 铭
(广东省建筑科学研究院集团股份有限公司 广东 广州 510500)
面对越来越复杂的工程问题,单机上的有限元计算不能达到完全解决问题的程度,可以考虑利用新兴云计算技术来解决。设计合适的杆单元数据结构,提出基于MapReduce框架的线性有限单元法并行算法,包括总体刚度阵组装和CG法求解线性方程组。在6节点Hadoop实验集群上,通过大规模空间桁架结构进行数值验证。结果表明采用该算法求解大规模空间桁架结构简洁、易用;在总刚组装阶段,网格模型越大,计算节点越多,计算性能越好;但求解方程组阶段,计算性能不理想,有待改善。
云计算 Hadoop MapReduce 线性有限元 空间桁架 并行计算
0 引 言
云计算[1]概念自2007年提出以来,引起了学术界和产业界的极大关注,许多学者、业内专家从自己关注的角度对云计算进行定义。结合维基百科、伯克利云计算白皮书和美国NIST的定义,本文认为云计算是以虚拟化技术为基础,以网络为载体,以用户为主体,以IaaS、PaaS、SaaS服务为形式,整合大规模、可扩展的分布式资源进行协同工作的超级计算范式。简单地说,云计算是传统分布式计算在商业模式上的发展,用户通过互联网提交计算任务,云计算将计算任务拆分成较小的任务,交给云平台上的众多虚拟资源处理,最后将结果返回给用户,用户只需缴纳相应的计算费用。
云计算的兴起,给IT界带来了巨大的改变,谷歌、IBM、亚马逊、微软、脸书等IT巨头纷纷提出自己的云计算计划项目,推动云计算技术的快速发展,为科学研究提供了新的计算工具,许多学者尝试在科学计算中使用这一新兴技术。Matsunaga等[2]提出了基于MapReduce的序列比对算法BLAST的并行实现——CloudBLAST,跟BLAST的主流并行算法mpi-BLAST进行比较,结果表明CloudBLAST在分配任务方面性能更好。Srirama等[3]建立了面向科学计算的云框架SciCloud,通过具体问题实例验证科学计算中的4类算法,结果表明Hadoop MapReduce框架实现高度并行的算法时计算效率很高,但实现迭代算法是不如另一个云计算框架Twister。Zhang等[4]提出了求解异步累计迭代计算的通用计算模型,包含单源最短路径算法SSSP、Jacobi算法、PageRank、Rooted PageRank、 Katz metric、 Adsorption和HITS算法等,设计分布式框架Maiter实现计算模型,在EC2上进行算例验证,结果显示相对于Hadoop,Maiter在求解迭代算法能获得60倍的加速比。Jorissen等[5]开发了一个能无缝控制EC2虚拟计算资源的云计算接口SC2IT,并实现了材料学中的FEFF9、WIEN2k、MEEP-mpi三个经典应用。Jakovits等[6]提出了完全适合科学计算的基于大量协同并行(BSP)模型的分布式框架Stratus,并用科学计算常用算法CG法进行性能验证,对于小规模问题,Stratus的求解时间跟MPI和mpijava接近,对于大规模问题,Stratus快很多。Hadoop框架的Map/Reduce任务必须序列化,这对于科学计算效率有限,Bai等[7]在Hadoop中加入MPI模块,使得Hadoop能更好地给任务分配合适的资源,提高其并行效率,并用分子动力学仿真算法RESTMD进行验证。
目前,云计算技术主要运用于数据统计学和生物信息学中的一些高度并行算法,还未运用到数据密集型、计算密集型的有限元算法中,与有限元计算相关的线性方程组求解也仅仅只是作为云计算的运用例子进行简单介绍。本文结合有限元计算分析和云计算各自的特点,以空间桁架系统的线性有限元方法为例,研究Hadoop MapReduce框架下的有限元网格模型生成计算文件,计算单元刚度阵,组装有限元系统总体刚度阵,施加位移边界条件和CG法求解大规模线性方程组等过程的具体实现细节。
1 有限元数据结构设计
参考主流有限元计算商业软件(如Abaqus、LS-dyna、Dytran等),将网格模型信息(包含节点坐标、单元、材料、边界约束、外力等)按一定格式写成计算文件,具体格式如下(*表示计算关键字,#表示注释行,I为整型数、R为浮点数):
*material
# mat-NO., E, Mu
I, R, R
*Node
# node-NO., x-Coords, y-Coords, z-Coords
I, R, R, R
*Element
# elem-NO., mat-NO., node-I, node-J, area
I, I, I, I, R
*Constraints
# node-NO., type
I, I
*Force
# node-NO., direction, force
I, I, R
*END
自定义数据结构trussElement描述三维杆单元,形式如下:
trussElement {
elemId;
//单元编号
xyz;
//单元节点坐标
E;
//杨氏模量
A;
//横截面积
locId;
//节点全局自由度
}
2 总体刚度阵组装
由文献[8]得到杆单元的刚度矩阵如下:

由上式计算出系统中所有单元刚度阵,通过全局自由度映射、组装成总体刚度阵。有限元系统的刚度阵通常是稀疏对称正定矩阵,本文采取COO格式压缩存储,对于非零元素,存储格式为(i,j,value),其中,i、j为矩阵元素行列号,value为矩阵元素。
单刚计算相互独立,适合并行处理,但在总刚组装时,传统并行方法对同一内存空间写数据时会有冲突,需要通过特殊的策略来解决。而在MapReduce过程中,Mapper阶段各个worker独立计算单元刚度阵并映射到总体刚度阵中,Reducer阶段对Mapper的输出进行规约即可完成总体刚度阵的组装,这个过程中不用显式存储总体刚度阵,且worker之间相互独立,不起读写冲突。基于MapReduce的线性有限单元法总体刚度阵组装的具体实现过程如图1所示。

图1 总体刚度阵组装的MapReduce实现过程
如图1所示,
Mapper类:计算单刚,并映射到总刚中。计算节点将数据块以key/value形式读入,key为单元的全局编号,value为单元信息trussElement。map()函数从trussElement中获取数据,计算单刚,得到一个6×6的矩阵。trussElement中单元节点自由度的全局编号跟单元刚度阵在总体刚度阵中的行列号相对应,这样就能实现单元刚度阵向总体刚度阵的映射。输出的key/value为:key<行编号,列编号>,value<单刚矩阵元素值>,其中key的类型需要自定义。
Combiner类:规约Mapper输出,减少数据交换量。在worker上规约合并本地节点的Mapper输出,输出合并后的结果,减少本地节点的数据输出量,从而减少Reducer准备阶段节点之间数据的交换,获得更好的网络性能,提高计算效率。
Reducer类:组装总体刚度阵,并进行COO格式压缩存储。Hadoop自动将Combiner输出结果中key相同的value合并为
3 CG法求解线性方程组的MapReduce实现
在有限元法的求解过程中,得到有限元系统的总体刚度阵后,接下来是施加外力和边界约束条件。对于杆单元,外力的处理比较简单,在读入网格模型数据时,只需将节点力映射到全局自由度上,即可形成载荷向量p。边界约束条件的引入有许多方法,结合MapReduce框架的特点,本文采用总体刚度阵对角元素乘大数法[8]:根据输入文件里的边界约束(零位移约束),将全局自由度j所对应的总刚元素kjj改为αkjj(α为一大数,通常为1010量级),载荷向量相应的元素pj改为0。到此,得到了系统方程组Ax=p,下面讨论CG法求解Ax=p的MapReduce实现。
由CG法的流程图(图2)可知,实现CG法的并行化,关键在于矩阵与向量乘法、向量内积与向量更新这三个子过程的并行实现,下面介绍MapReduce框架下的实现过程。

图2 CG法的串行流程图
3.1 稀疏矩阵与向量乘法的MapReduce实现
基于MapReduce的稀疏矩阵与向量的乘法计算y=Ax的流程如图3。通过COO压缩存储的总体刚度阵A作为输入文件,向量x通过Hadoop的分布式缓存机制DistributedCache[9]共享到各个计算节点上。在map阶段,采用TextInputFormat类[9]将输入数据块以键值对形式读入,TextInputFormat类默认“键”为数据在文件中的偏移量,“值”为一整行数据。map计算前,需要从DistributedCache中读取共享向量来初始化x。在map()函数中,计算Aijxj,输出键值对(i,Aijxj)。主节点对map输出进行整合,将“键”相同的键值对集合起来传给从节点执行Reducer过程。在reduce()函数中直接对输入键值对的“值”求和就能得到结果向量,输出并保持到HDFS上,供后续两个子过程使用。

图3 MapReduce框架下并行计算y=Ax
3.2 向量内积的MapReduce实现
向量内积b=α·β的MapReduce实现跟矩阵向量乘法相似,向量α作为输入文件,向量β通过DistributedCache共享到各个计算节点上,向量内积的MapReduce实现流程如图4所示。在map阶段,先从DistributedCache中读取共享向量,然后在map()函数中将输入向量元素跟共享变量对应的元素相乘,乘积作为map输出。在reduce阶段,直接求和即可完成b=α·β的计算。

图4 MapReduce框架下b=α·β的并行实现
3.3 向量更新的MapReduce实现
向量更新v=v+αp需要传递常数α到map()函数中,传统的编程习惯就是将其定义成全局变量或者全局常量。但在MapReduce框架下map和reduce是在不同节点上分布式计算,不能将α定义成全局变量,只能定义成全局常量,在配置Job时通过set()函数设置全局常量的值,然后在Mapper阶段通过get()函数获取。跟向量内积相同,向量v作为输入,向量p共享。map阶段,读取全局常量α并更新v中的每个元素;reduce阶段,输出key/value并保持到HDFS上。
3.4CG法的MapReduce实现
CG法3个子过程的MapReduce实现分别在3.1-3.3节中作了详细介绍,本文定义3个类SPMV、VecDot、VecUpdate分别实现这3个过程。在Hadoop平台上,必须将每个子过程看成一个单独的Job来处理,实现CG法的关键在于控制Job的启动、结束、清理和收敛判断,为此本文定义类CGSolver来完成这些控制。Job的启动参数包含输入矩阵文件名、结果文件名、输入向量文件名、中间数据文件名、map数和reduce数等,通过定义runSPMVjob()、runVecDotjob()、runVecUpdatejob()这三个驱动方法配置相应子类的启动参数。CG法的MapReduce实现算法如下:
算法1MRimplementationofCGmethod
1. set iterative errorε=1e-14,iterativevariablei=0,getmaxiterationfromvectorb;
2.executesub-stepSPMV,computep=Ax,outputtheresultfile;
3.executesub-stepVecUpdate,computep=r=b-Ax,outputtheresultfile;
4.executesub-stepVecDot,computeerror_norm= (r,r);
5.fori=1,2,…,n
5.1setr2 =error_norm;
5.2executesub-stepSPMV,computev=Ap;
5.3executesub-stepVecDot,computeα=r2/(p,v) ;
5.4executesub-stepVecUpdate,computex=x+αpandr=r-αvrespectively;
5.5executesub-stepVecDot,computeerror_norm= (r,r);
5.6if(error_norm<ε)exit;
5.7computeβ=error_norm/r2 ;
5.8executesub-stepVecUpdate,computep=r+βp;
endfor
end
4 算例验证
采用4个空间桁架结构(表1)验证总体刚度阵组装并行算法和CG法求解线性方程组并行算法的正确性、有效性和加速效率。

表1 空间桁架模型信息
4.1 总体刚度阵组装
在总体刚度阵组装阶段,4个计算模型在不同map数、不同task数下的执行时间如图5所示。
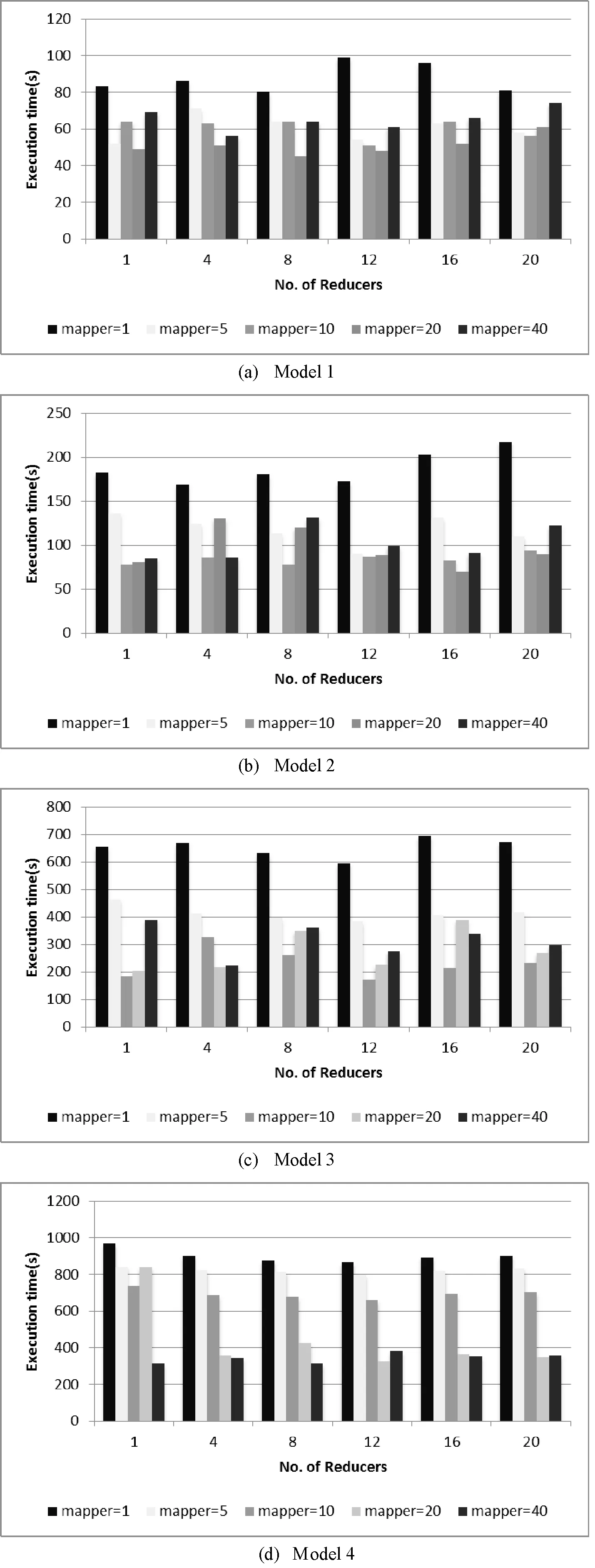
图5 执行时间随Mapper、Rducer变化图
从图5可以看出,当map数量足够多,即有更多计算节点参与计算时,reduce数目的增加并不能明显提高计算性能,在某些情况下甚至会因为计算节点将中间数据的交换分配和计算任务的排队等待而降低计算性能,如图(a)中mapper=40。本文搭建的Hadoop+Spark集群平台中每个节点上配置的map数和reduce数均为2,集群平台总的map数和reduce数均为12。当计算模型足够大,能满足map数等于或大于12时,集群系统处于饱和状态,这种情况下,如果reduce数设置为12,各个节点上map节点的计算结果直接进入reduce阶段,节点之间不需要交换计算结果,这样能降低通信开销,提升计算效率,如图(d)中mapper=20、reducer=12这种情形。但当reducer数目继续增多时会因为资源之间的竞争而使计算效率降低,如图(d)中reducer等于16和20的计算时间总体上都reducer=12的大。
测试4个计算模型在mapper=40、reducer=12和mapper=20、reducer=12两种情形下的执行时间,并跟mapper=1、reducer=1的比较,加速比如图6所示。加速比随着计算规模的增大而增大,由于任务等待时间更多,情形1的加速比小于情形2的。

图6 不同模型的加速比(reducer=12)
4.2CG法求解线性方程组
测试4个计算模型每一迭代步内1次SPMV、2次VecDot和3次VecUpdate的执行时间,结果如图7、图8所示。图7显示,计算时间明显地随模型规模的增大而增大,VecDot和VecUpdate的计算量远小于SPMV,却需要不少计算时间。这是由于无缝连接SPMV、VecDot、VecUpdate三个过程,将VecDot和VecUpdate的reducer设置为1,只有一个节点计算reduce任务,其他节点空闲,资源利用率不高,同时其他计算节点上的map结果都必须传送到该节点上执行reduce,节点之间的数据交换量较多,加大了网络负载,导致计算效率下降。图8显示,随着计算规模的增大,SPMV所需计算时间的比重也明显的增大,这是由于模型增大,计算量增加,用于节点间的通信和数据交换方面的开销所占比例减小;另一方面,随着计算规模的增大,SPMV比重的增大也说明reducer设置为1对计算性能的影响减小了,这是因为SPMV、VecDot和VecUpdate的计算量主要集中在map阶段,reduce阶段的计算量很小。

图7 3个子过程所需的执行时间

图8 3个子过程计算时间的饼状图
不同计算节点下Model1-Model3的加速比如图9所示,算法获得的最大加速比只有1.5,加速效率很低。主要两个原因:子过程以新的Job提交,HadoopJob的提交和结束需要花费一定的时间;每个计算过程都需要从HDFS上读写数据,HDFS的读写速度有限,而算法本身的中间数据就是可重复利用的,显然,MapReduce+HDFS没办法实现数据的可重复利用。
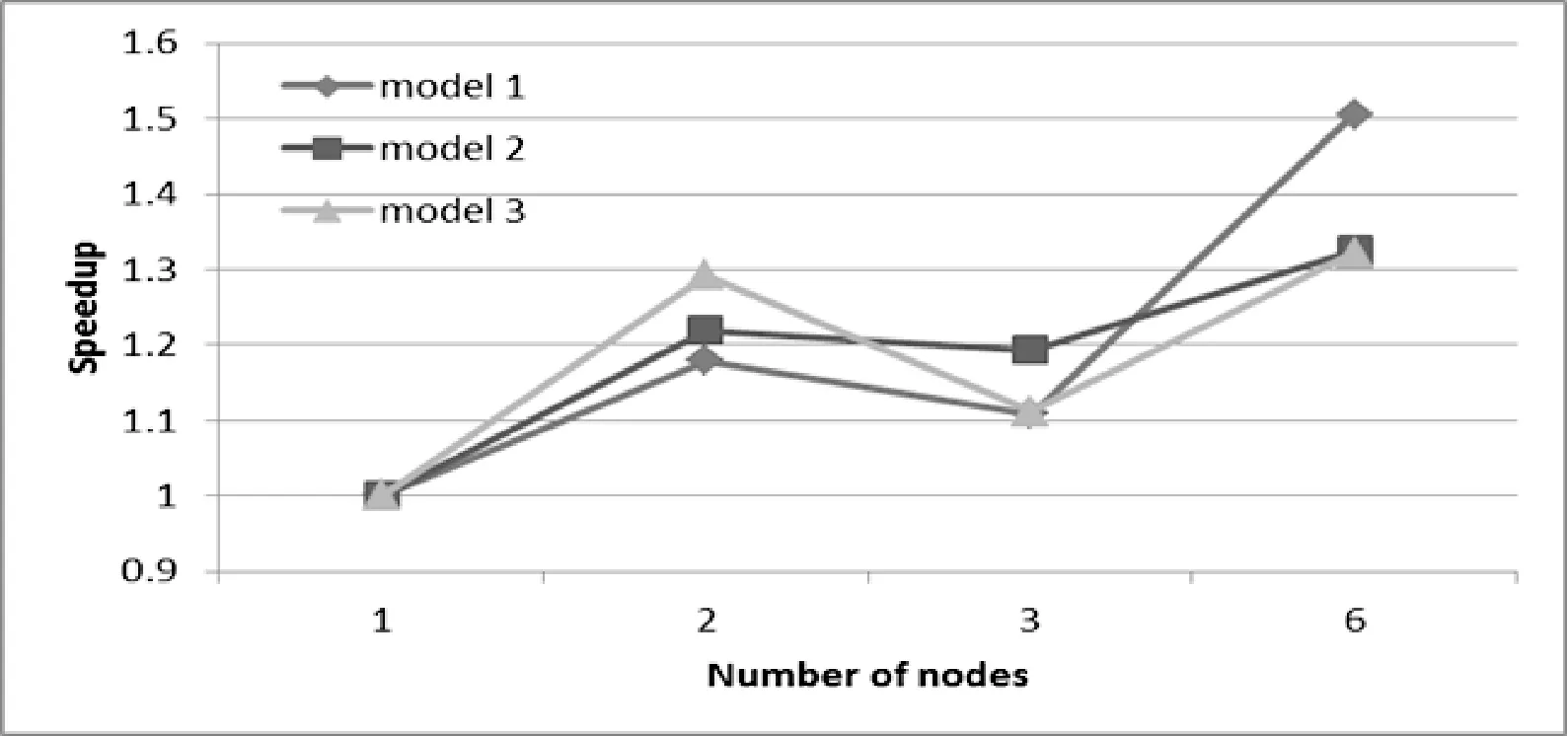
图9 加速比随节点数的变化图
5 结 语
本文设计了合适的杆单元数据结构,提出基于MapReduce框架的线性有限单元法并行算法,包括总体刚度阵组装和CG法求解线性方程组,在6节点Hadoop实验集群上,通过大规模空间桁架结构进行数值验证。结果表明采用本文所提的并行算法求解大规模空间桁架结构简洁、易用;在总刚组装阶段,计算模型越大,参与计算的节点越多,得到的计算性能越好。但求解方程组阶段,计算性能不理想,这是由于子过程以新的Job提交,HadoopJob的提交和结束需要花费一定的时间。同时,每个计算过程都需要从HDFS上读写数据,HDFS的读写速度有限,而算法本身的中间数据就是可重复利用的,但MapReduce+HDFS没办法实现数据的重复利用。
[1]ArmbrustMichael,FoxArmando,GriffithRean,etal.AviewofCloudComputing[J].Commun.ACM,2010,53(4):50-58.
[2]AndréaMatsunaga,MaurícioTsugawa,JoséFortes.CloudBLAST:CombiningMapReduceandvirtualizationondistributedresourcesforbioinformaticsapplications[C]//ProceedingsofIEEEFourthInternationalConferenceoneScience,2008,NewYork:IEEE,2008.
[3]SatishSrirama,OlegBatrashev,EeroVainikko.SciCloud:ScientificComputingontheCloud[C]//Proceedingsof2010 10thIEEE/ACMInternationalConferenceonCluster,CloudandGridComputing,2010,NewYork:IEEE,2010.
[4]YanfengZhang,QixinGao,LixinGao,etal.Acceleratelarge-scaleiterativecomputationthroughasynchronousaccumulativeupdates[C]//Proceedingsofthe3rdworkshoponScientificCloudComputingDate,2012,NewYork:ACM,2012.
[5]KevinJorissen,WilliamJohnson,FernandoDVila,etal.High-performancecomputingwithoutcommitment:SC2IT:Acloudcomputinginterfacethatmakescomputationalscienceavailabletonon-specialists[C]//Proceedingsof2012IEEE8thInternationalConferenceonE-Science,2012,NewYork:IEEE,2012.
[6]PelleJakovits,SatishNarayanaSrirama.IljaKromonov:Adistributedcomputingframeworkforscientificsimulationsonthecloud[C]//Proceedingsof2012IEEE14thInternationalConferenceonHighPerformanceComputingandCommunication,2012.NewYork:IEEE,2012.
[7]ShujuBai,EbrahimKhosravi,Seung-JongPark.AnMPI-enabledMapReduceframeworkformoleculardynamicssimulationapplications[C]//Proceedingsof2013IEEEInternationalConferenceonBioinformaticsandBiomedicine,2013.NewYork:IEEE,2013.
[8] 王勖成.有限单元法[M].北京:清华大学出版社,2003.
[9]LamChuck.Hadoopinaction[M].NewYork,America:ManningPublicationsCo.,2010.
PARALLEL IMPLEMENTATION OF LARGE-SCALE LINEAR FEM BASEDON HADOOP MAPREDUCE FRAMEWORK
Lin Haiming
(GuangdongProvincialAcademyofBuildingResearchGroupCo.Ltd.,Guangzhou510500,Guangdong,China)
In the face of increasingly complex engineering problems, we cannot completely solve these problems through finite element method(FEM) on a single machine, but we can consider using emerging cloud computing technology. In this paper, we design an appropriate data structure of truss element and propose a parallel algorithm of linear finite element method based on MapReduce framework, including assembling global stiffness matrix and conjugate gradient (CG) method for solving linear equation groups. On the six-node Hadoop experimental cluster, numerical verification is carried out through large-scale spatial truss structures. The results show that it is simple and easy to solve large-scale spatial truss structures by using the proposed algorithm. At the stage of assembling global stiffness matrix, as the size of the mesh model and the number of cluster’s nodes increase, the computing performance becomes better. However, at the stage of solving equation groups, the computing performance is not ideal and should be improved in the future.
Cloud computing Hadoop MapReduce Linear finite element Spatial truss Parallel computing
2015-12-03。林海铭,硕士,主研领域:计算机仿真,大规模计算。
TP3
A
10.3969/j.issn.1000-386x.2017.03.004
