云存储中基于二进制向量索引的密文云数据排序查询方法
2017-04-14陈兰香周书明
陈兰香 周书明
(福建师范大学数学与计算机科学学院 福建 福州 350108)(福建师范大学网络安全与密码技术重点实验室 福建 福州 350108)
云存储中基于二进制向量索引的密文云数据排序查询方法
陈兰香 周书明
(福建师范大学数学与计算机科学学院 福建 福州 350108)(福建师范大学网络安全与密码技术重点实验室 福建 福州 350108)
设计一种适用于公共云存储环境下的密文云数据排序查询方法,其核心思想是使用二进制向量索引,并且使用Hash函数计算向量元素为1的位置。这种方法使得建立索引向量非常方便,并且更易于建立查询向量以及进行后续数据更新操作。由用户对其文件集构建二进制向量索引,当用户要求访问包含某些关键词的文件时,首先根据查询关键词构建查询二进制向量,然后根据查询二进制向量与文件的索引二进制向量之间的内积判断该文件是否包含用户的查询关键词。根据内积计算结果可知哪些文件的相关性更强,并且内积计算效率高。实验表明,该方法的索引创建与查询效率都非常高。
云存储 密文检索 二进制向量索引 排序查询
0 引 言
在云存储环境下,要保护用户数据机密性和隐私性,加密是一种常用的方法,但是数据加密后,密文数据检索问题亟待解决。
目前主要有两种典型的方法来解决密文云数据检索问题:第一种是直接对密文进行线性搜索,第二种方法基于安全索引。线性搜索对密文中单词逐个进行比对,确认关键词是否存在以及出现的次数;安全索引先对文档建立关键词索引,然后将文档和索引加密后上传至云端,搜索时从索引中查询关键词是否存在于某个文档中。第一种方法缺点在于搜索效率不高,且无法应对海量数据的搜索场景。第二种方法是目前的研究主流,原因是其查询效率更好,安全性能更高,适用于大规模的云存储密文检索系统。
对于大型企业或组织,当其数据量很大时,可以构建私有云存储服务。但是对于一些中小企业或个人用户,为了节省成本及访问方便,更加需要公共云存储服务。
用户的主要数据存放在家用或办公台式机上,而平时主要使用手机与平板电脑等手持设备访问网络,这是目前很多用户的现实情况。让用户可以随时随地使用任意设备访问其数据是用户最迫切需要实现的功能,公共云存储服务即是一个最佳选择。
用户的数据类型很丰富,有文档、照片、视频等各种数据类型。有些文件,比如用户的一些私人照片,用户并不希望被别人看见,因此其文件存放到云端前,用户需要对数据进行加密处理。数据一旦加密,如果没有可用的检索机制,用户只有将文件全部下载到本地解密后才能找到当前需要访问的文件,这种方式显然不实用,会带来太大的网络与计算开销。因此,如果在将所有文件进行加密前,对其按关键词建立索引,查询文件时使用关键词进行搜索,只将符合查询关键词的文件下载到本地才是实用的。
本文的目标就在于设计一种适用于以上场景的密文云数据查询方法。
本文设计一种适用于公共云存储环境下的密文云数据排序查询方法,该方法基于二进制向量索引,使用向量内积计算判断某文件是否包含指定关键词。该方法的优点如下:(1) 完全基于对称密码技术,效率很高;(2) 支持多关键词查询;(3) 查询基于内积计算,计算效率高;(4) 该方法易于进行数据更新。最后用户的文件可以是任何类型,比如可以是压缩文件、多媒体文件等,只需事前建立二进制向量索引。
1 相关工作
2000年,Song等[1]第一次提出基于对称密码的可检索加密方法SSE(Searchable Symmetric Encryption),并提出一个非交互式的基于单关键词的检索方案。该方案主要是在加密结果中增加一种基于流密码的信息检索算法的验证机制,具有极强的抵抗统计分析的能力。但在海量数据环境下,复杂的验证过程会消耗大量的服务器资源。
为了改进效率,Goh[2]提出使用安全索引的方法实现对海量密文数据的快速检索,并基于Bloom Filters构建了一种适应性选择关键字攻击安全的称为Z-IDX的安全索引。在该索引上进行查询时处理每个文档的时间为O(1),并且能够处理任意长度单词。但是BloomFilters的引入使得该方法的检索结果具有一定的错误率。Chang等[3]构造了一个相似的查询时间为O(n)而没有误报的文件索引方案。
Curtmola等[4]提出第一个子线性搜索时间的方案SSE-1和SSE-2。所提方案为整个文档集关联一个加密的倒序索引,每个入口由关键词的门陷和相关文档标识符的加密集组成。方案的搜索时间是O(r),r是包含关键词的文件数量。他们利用广播加密实现多用户环境下的查询授权,并在Song[1]的基础上给出更严格的安全性定义。Kurosawa等[5]研究了可验证的通用可组合安全的SSE方案。
以上方案都没有考虑数据更新。
Wang等[6]考虑关键词词频信息,提出基于对称密码保序加密技术OPSE(OrderPreservingSymmetricEncryption)的单关键词分级密文排序检索方法RSSE(RankedSSE),利用信息检索中的统计排序方法,在建立索引的同时为每个文件嵌入权重信息,从而能够按用户的要求返回前N个符合要求的结果。由于服务器知道相关性得分信息,所以OPSE虽然可以提高效率但没有SSE安全。
Li等[7]针对关键词精确匹配的不足提出基于编辑距离的加密字符串模糊检索方案。所提方案使用编辑距离量化字符串的相似度,并为每个字符串附加一个基于通配符的模糊字符串组,用多个精确匹配来实现模糊检索。
Wang等[8]提出一个隐私保护的相似性检索机制,利用压缩技术建立存储高效的相似关键词集合,使用编辑距离作为相似性度量。通过建立基于遍历树的索引实现常量时间复杂度的相似检索功能,并且自然地支持模糊检索,用于容忍用户输入时的拼写错误或表示的不一致。
黄汝维等[9]设计了一个基于矩阵和向量运算的可计算加密方案CESVMC。该方案将云数据分为字符串和数值数据两大类,通过运用向量和矩阵的各种运算,实现了对数据的加密。支持对加密字符串的模糊检索和对加密数值数据的加、减、乘、除四种算术运算,并保证了数据存储、运算过程中的隐私安全性。
Liesdonk等[10]第一次明确地提出动态性的SSE方案,但他们的方案只支持有限次的更新。Kamara等[11]扩展Curtmola等[4]的倒排索引的方法,提出动态SSE的形式化的安全定义,并构造第一个动态的、CKA2安全的SSE方案。接下来,在文献[12]中,他们基于关键词红黑树KRB(keywordred-black)构造可并行并且支持更新的SSE方案。他们的研究结果表明使用KRB树可以建立文档索引,使得关键词检索可以在O(rlogn)串行时间和O(r/plogn)并行时间完成。
Hahn等[13]提出一个子线性检索时间的对称密码可搜索加密方案,实现了数据动态更新,其更新只泄露数据访问模式。Stefanov等[14]使用文档关键字对的对数级层次结构实现数据更新。Kurosawat等[15]提出一种可验证的更新方案。但该方案需要为每个关键词生成一个MAC,所以修改文件的效率比较低。Naveed等[16]引入一个新的元语:盲存储,允许用户存储一组文件在远程服务器上,但服务器并不知道存储了多少文件,也不知道单个文件的长度,当文件被检索时,服务器只是知道文件的存在,但不知道文件名及内容。
以上都是针对单关键词的方案,关于多关键词密文搜索也有一些方案。
Cao等[17]提出一个多关键词排序检索方案,扩展了Wang等[6]的工作以支持多关键词查询,并基于安全kNN(k-nearestneighbor)查询技术中索引向量与查询向量间“内积相似度”来实现排序查询并进行隐私保护增强。
Sun等[18]提出一种支持相似度排序的多关键词文本检索方案,基于词频和向量空间模型构建索引,并利用余弦相似性度量来实现更高的搜索精度。该方案基于树的索引结构及多维算法,从而得到比线性搜索更好的检索效率。Moatazt等[19]提出一种基于关键词域上的格拉姆-施密特正交化过程的布尔检索方案,检索时只需进行简单的内积计算,并且对查询进行随机化处理,从而隐藏搜索模式。
王尚平等[20]采用授权用户和存储服务器先后对关键词加密的方式提出了一个基于连接关键词的可搜索加密方案。该方案使授权用户能利用连接关键词的陷门搜索加密文档,并证明方案在确定性Diffie-Hellman问题假设下是安全的。
文献[21,22]围绕可搜索加密技术基本定义、典型构造和扩展研究,对可搜索加密相关工作进行了综述。
当用户数据丰富,平时习惯使用手机、平板电脑等手持设备访问其数据时,他们便需要使用公共云存储服务来实现随时随地任意设备来访问其数据。本文设计一种适用于此场景的密文云数据查询方法,该方法基于二进制向量索引,使用向量内积计算判断某文件是否包含指定关键词。该方法完全基于对称密码技术,效率很高;数据查询基于内积计算,计算效率高;支持多关键词查询,并且该方法易于进行数据更新。
2 二进制向量索引
2.1 符号定义
F={f1,f2,…,fm}:用户文件集合;
W={w1,w2,…,wn}:关键词集合;



R=Qt·I:内积运算,符号“·”表示求两个向量的内积;
g:{0,1}t×{0,1}l→{0,1}l,伪随机函数PRF(Pseudo-randomFunction),用作伪随机数生成器;
h:{0,1}k×{1,2,…,n}→{1,2,…,n},伪随机置换PRP(Pseudo-randomPermutation),用于确定关键词的位置。
其中,k是密钥长度,关键词wi在数组中的存放位置p=hk(wi) modq,q为比n略大的素数。
2.2 二进制向量索引构建方法
用户使用已有分词算法对其文件集提取关键词,构建关键词集合,并构建所有文件的二进制向量索引。然后对文件使用对称密码机制进行加密,如果是基于数据块,还要将文件按设定数据块大小进行分块,最后将加密的文件发送到云端。
二进制向量索引构建方法如下:用户根据每个文件中是否包含关键词集合中的对应关键词来构建二进制向量索引,将每个文件提取的关键词进行Hash计算,并模一个素数q作为存放该关键词的二进制向量的下标,即关键词wi在向量中的下标为p=hk(wi) modq(q为比n大的素数),将此位置1,其余所有位全部置0。
为了有效地实现数据更新,在有效关键词基础上增加20%的空余位,假设有1 000个关键词,每个二进制索引向量将占1 200bits。
查询某个关键词是否在关键词集合中时,只须将该关键词进行Hash计算并模一个素数以查询该下标的向量元素值,如果为1,表明该关键词存在关键词集合中,否则不存在。
举一个简单的例子,如图1所示,假设关键词集合为{云计算,云存储,加密,数据检索,二进制向量},关键词总数为5,那么增加20%的bit位,最接近的素数q可以设为7。文件1包含关键词{云计算,加密},则其索引二进制向量计算方法如下:
P11=hk(“云计算”) mod 7,P12=hk(“加密”) mod 7,假设计算结果P11=2,P12=4,则文件1的二进制索引向量为I1=(0,0,1,0,1,0,0),文件2包含关键词{云存储,加密,数据检索,二进制向量},则P21=hk(“云存储”) mod 7,P22=hk(“加密”) mod 7,P23=hk(“数据检索”) mod 7,P24=hk(“二进制向量”) mod 7,假设计算结果P21=3,P22=4,P23=1,P24=6,则文件2的索引二进制向量为I2=(0,1,0,1,1,0,1)。

图1 二进制向量索引图
对于有10 000个关键词的文件集,每个文件的二进制向量索引只占12Kbits,100个文件占150KB,相比于倒排索引,每个关键词一个索引表,10 000个关键词将产生10 000个索引表。
3 基于二进制向量索引的密文排序查询方案
3.1 方案设计
用户根据查询关键词与关键词集合构建查询二进制向量,并使用查询二进制向量与所有文件的索引二进制向量进行内积计算以判断文件是否包含查询关键词,然后向云端请求包含查询关键词的文件密文。
构建查询二进制向量方法如下:用户根据查询关键词是否在关键词集合中构建查询二进制向量,设Ii是文档Fi的二进制索引向量,其中Ii[j]∈{0, 1}表示关键词wj是否在文档中存在;Q是一个查询向量,其中Q[j]∈{0, 1}表示关键词wj是否在查询关键词集合中。文档Fi与查询关键词集合的相似性得分通过内积方式计算出来,即IQ。当内积计算结果为非0时,表明该文件包含查询关键词,当内积计算结果为0时,表明该文件不包含查询关键词。并且内积计算结果的值越大,表明包含的关键词越多。

可以将算法形式化地表示为一个五元算法(Setup,IndxStrc,Enc,Query,Dec),简单描述如下。
初始化阶段Setup():用户使用伪随机函数g生成随机数s∈{0, 1}l,并生成文件加密密钥。
索引构建IndxStrc():用于构建索引,对每个文件fj,用户为其生成二进制索引Ij,满足:如果文件fj包含关键词wi,则Ij[p]=1,否则为Ij[p]=0,其中p=hs(wi) modq,q为比n略大的素数。
加密Enc():使用文件加密密钥对文件F={f1,f2,…,fm}进行对称加密,得到密文C={c1,c2,…,cm},用户将加密文件集C存放于云存储服务器。

解密文件Dec():使用相应文件密钥解密返回的文件,就是按相关度排序后的文件。
用户只需将关键词集合、所有文件的二进制向量索引及文件密钥存于所使用的任何访问设备上便可实现随时随地访问。
3.2 数据更新
数据更新涉及到多种操作,包括修改、增加、删除等。
修改数据只需要对涉及到修改的文件进行更新,如果有增加新的关键词,将关键词加入关键词集合,然后重新对数据建立二进制向量索引,对数据重新加密,然后将加密的文件发送至云端,将以前的数据删除。
增加数据与修改数据类似,对增加的数据构建二进制向量索引,对数据加密,然后将加密的文件发送至云端。
添加文件时,因为在索引向量构建时预留了20%的空闲空间,因此只需要对新文件分词,将原有关键词集合中没有的关键词(假设有t个)加入关键词集合后面,对新文件构建二进制向量索引,而其他文件索引均无须修改。
删除数据时只需要将云端相应数据删除,而将本地的相应索引及文件密钥删除。
本方法具有以下的优势:
(1) 数据更新方便,建立索引的过程由用户完成,关键词集合信息由用户保管,当有文件需要更新时,用户只需要更新文件的二进制向量索引,并重新加密文件,然后将加密的文件发送至云端。
(2) 使用二进制向量内积计算非常高效,只需要在用户端增加少量的存储就可以实现高效的检索。
4 性能分析
因为数据的加解密及检索操作均在本地完成,所以不向云端服务器泄露任何信息,本方法适用于公共云存储环境下的密文云数据查询,主要优势在于其效率。
在访问效率上,通过以上过程可以发现使用密文查询机制给用户带来的方便性:首先,用户不需要为了没有包含关键字的文件浪费网络和存储资源,提高计算效率;其次,用户不必对不符合条件的文件进行解密操作,节省了本地的计算资源。
本文提出的二进制向量索引方案与已有方案在索引大小、查询时间复杂度等方面的对比见表1所示,二进制向量索引方案均是最优的。

表1 二进制向量索引方案与其它方案的比较
其中,m是文件集中包含的文件数,n是关键词的数量,|F|是文件集数据量的大小。
二进制向量索引方案的关键词与索引的存储空间需求见表2,为了便于更新,设置索引预留20%的空间,设一个汉字占2个字节,一个关键词设为最多5个汉字,占10个字节,假设有1 000个关键词,存储关键词集合只需要约10KB字节的存储空间。每个文件的二进制向量索引大小为1 200bits,为15B,1 000个文件,只需要15KB的索引存储空间。假设关键词总数为4 000个,那么每个文件的索引存储空间为600B,1 000个文件就是600KB。相比于倒排索引,每个关键词一个索引表,10 000个关键词将产生10 000个索引表。

表2 关键词与索引的存储空间
本实验在配置为Intel Core i5 CPU 1.6 GHz,4 GB RAM的机器上基于Java语言使用HMAC-SHA256算法创建索引。创建索引的主要开销在于计算关键词的向量下标,所以与每个文件包含的关键词平均数有关,假设平均每个文件包含5个关键词。实验时,我们假设关键词已经提取,当关键词总数为n=2 000,其索引创建时间与文件数的关系如图2所示,从图中可以看出创建索引的开销与文件数呈线性增长。设文件集中包含的文件数m=1 000,其索引创建时间与关键词数量的关系如图3所示。
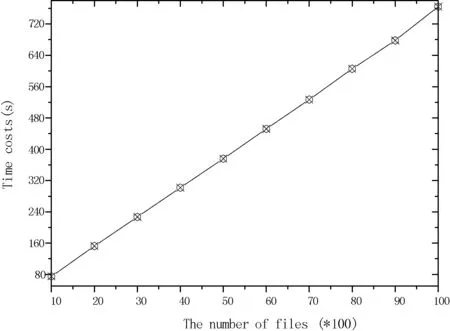
图2 索引创建时间与文件数的关系

图3 索引创建时间与关键词数量的关系
查询时间开销如图4和图5所示,设查询关键词总数为10个,查询时间开销与文件数的关系如图4所示,从图中可以看出查询时间开销与文件数呈线性增长。设文件集中包含的文件数m=1 000,查询时间开销与查询关键词总数的关系如图5所示。

图4 查询时间开销与文件数的关系

图5 查询时间开销与查询词数量的关系
5 结 语
本文提出一种基于二进制向量索引的密文云数据排序查询方法,由用户对其文件集构建二进制向量索引,并使用对称密码机制加密文件集,然后将加密文件集发送至公共云存储服务器上,将索引存放在本地或加密后存放在服务器上,因为二进制索引占用存储空间少,可存于本地。当用户要求访问包含某些关键词的文件时,根据查询关键词与关键词集合构建查询二进制向量,并将查询二进制向量与每个文件的索引二进制向量进行内积计算以判断该文件是否包含用户的查询关键词。该方法完全基于对称密码技术,效率很高,并且支持多关键词查询,用户的文件可以是任何类型,比如可以是压缩文件、多媒体文件等,只需事前建立二进制向量索引。本方法能实现比目前广泛使用的倒排索引更高效的查询。
[1]SongDX,WagnerD,PerrigA.Practicaltechniquesforsearchesonencrypteddata[C]//ProceedingofIEEESymposiumonSecurityandPrivacy,2000:44-55.
[2]GohEJ.Secureindexes[R/OL].CryptologyePrintArchive:Report2003/216.http://eprint.iacr.org/2003/216.
[3]ChangYC,MitzenmacherM.Privacypreservingkeywordsearchesonremoteencrypteddata[C]//ProceedingofAppliedCryptographyandNetworkSecurity(ACNS),2005:442-455.
[4]CurtmolaR,GarayJ,KamaraS,etal.Searchablesymmetricencryption:improveddefinitionsandefficientconstructions[C]//ProceedingofTheACMConferenceonComputerandCommunicationsSecurity(CCS),2006:79-88.
[5]KurosawaK,OhtakiY.UC-securesearchablesymmetricencryption[C]//ProceedingofFinancialCryptography,2012:285-298.
[6]WangC,CaoN,LiJ,etal.Enablingsecureandefficientrankedkeywordsearchoveroutsourcedclouddata[J].IEEETransactionsonParallelandDistributedSystems,2012,23(8):1467-1479.
[7]LiJ,WangQ,WangC,etal.Fuzzykeywordsearchoverencrypteddataincloudcomputing[C]//ProceedingofInternationalConferenceonComputerCommunications,2010:441-445.
[8]WangC,RenK,YuS,etal.Achievingusableandprivacy-assuredsimilaritysearchoveroutsourcedclouddata[C]//ProceedingofInternationalConferenceonComputerCommunications,2012:451-459.
[9] 黄汝维,桂小林,余思,等.云环境中支持隐私保护的可计算加密方法[J].计算机学报,2011,34(12):2391-2402.
[10]LiesdonkPV,SedghiS,DoumenJ,etal.Computationallyefficientsearchablesymmetricencryption[C]//ProceedingofSIAMInternationalConferenceonDataMining,2010:87-100.
[11]KamaraS,PapamanthouC,RoederT.Dynamicsearchablesymmetricencryption[C]//ProceedingofTheACMConferenceonComputerandCommunicationsSecurity(CCS),2012:965-976.
[12]KamaraS,PapamanthouC.Parallelanddynamicsearchablesymmetricencryption[C]//ProceedingofFinancialCryptography,2013:258-274.
[13]HahnF,KerschbaumF.Searchableencryptionwithsecureandefficientupdates[C]//ProceedingofTheACMConferenceonComputerandCommunicationsSecurity(CCS),2014:310-320.
[14]StefanovE,PapamanthouC,ShiE.Practicaldynamicsearchablesymmetricencryptionwithsmallleakage[C]//ProceedingofTheNetworkandDistributedSystemSecuritySymposium,2014:1-15.
[15]KurosawaK,OhtakiY.Howtoupdatedocumentsverifiablyinsearchablesymmetricencryption[C]//ProceedingofInternationalConferenceonCryptologyandNetworkSecurity,2013:309-328.
[16]NaveedM,PrabhakaranM,GunterCA.Dynamicsearchableencryptionviablindstorage[C]//ProceedingofIEEESymposiumonSecurityandPrivacy,2014:639-654.
[17]CaoN,WangC,LiM,etal.Privacy-preservingmulti-keywordrankedsearchoverencryptedclouddata[C]//ProceedingofInternationalConferenceonComputerCommunications,2011:829-837.
[18]SunW,WangB,CaoN,etal.Privacy-preservingmulti-keywordtextsearchinthecloudsupportingsimilarity-basedranking[C]//ProceedingofTheACMConferenceonComputerandCommunicationsSecurity(CCS),2013:71-82.
[19]MoatazT,ShikfaA.Booleansymmetricsearchableencryption[C]//ProceedingofTheACMSymposiumonInformation,ComputerandCommunicationsSecurity,2013:265-276.
[20] 王尚平,刘利军,张亚玲.一个高效的基于连接关键词的可搜索加密方案[J].电子与信息学报,2013,35(9):2266-2271.
[21] 沈志荣,薛巍,舒继武.可搜索加密机制研究与进展[J].软件学报,2014,25(4):880-895.
[22] 李经纬,贾春福,刘哲理,等.可搜索加密技术研究综述[J].软件学报,2015,26(1):109-128.
ORDERED ENCRYPTED DATA SEARCHING METHOD BASED ONBINARY-VECTOR INDEX IN CLOUD STORAGE
Chen Lanxiang Zhou Shuming
(SchoolofMathematicsandComputerScience,FujianNormalUniversity,Fuzhou350108,Fujian,China)(KeyLabofNetworkSecurityandCryptology,FujianNormalUniversity,Fuzhou350108,Fujian,China)
A ranking query method of ciphertext cloud data in cloud storage is designed. The basic idea is to build binary vector index, and use the Hash function to calculate the position of the vector in which is filled “1”. This method makes it easy to establish the index vector, and is easier to build the query vector and update the data. Binary vector index is constructed by the user. When the user requests access to a file containing some keywords, the query binary vector is built by the query keywords and the keyword set. Then the inner product of the query vector and index vector is calculated to determine whether the file contains the queried keywords. According to the inner product, it is able to know that which files are more relevant to the query and have higher computational efficiency. The experiments show that the efficiency of index creation and query are very high.
Cloud storage Ciphertext search Binary-vector index Ranked query
2016-01-06。国家自然科学基金面上项目(61572010);福建省自然科学
2015J01240);福建省教育厅科技项目(JK2014009);福州市科技计划项目(2014-G-80)。陈兰香,副教授,主研领域:云存储,存储安全。周书明,教授。
TP309.2
A
10.3969/j.issn.1000-386x.2017.03.002
