云环境下基于多目标优化的科学工作流数据布局策略
2017-04-14程慧敏李学俊朱二周
程慧敏 李学俊,* 吴 洋 朱二周
1(安徽大学计算机科学与技术学院 安徽 合肥 230601)2(安徽大学计算智能与信号处理重点实验室 安徽 合肥 230039)
云环境下基于多目标优化的科学工作流数据布局策略
程慧敏1李学俊1,2*吴 洋1朱二周2
1(安徽大学计算机科学与技术学院 安徽 合肥 230601)2(安徽大学计算智能与信号处理重点实验室 安徽 合肥 230039)
针对传统科学工作流数据布局策略在减少数据传输时间的同时,不能兼顾数据中心间的负载均衡,提出一种基于多目标优化的数据布局策略。首先生成固定数据集布局方案,然后利用多目标优化算法KnEA对非固定数据集进行布局,最终得到全局布局方案。KnEA算法利用knee points比普通非支配个体有着更好的收敛性特征,并综合考虑多个优化目标间的平衡,因而可以取得数据传输时间和负载均衡都很好的数据布局方案。通过对比实验证明了该数据布局策略的有效性。
云计算 科学工作流 数据布局 多目标优化 负载均衡
0 引 言
在现代科学应用领域中天文学[1]、高能物理学[2]、生物信息学[3]等通常都是计算密集型和数据密集型的应用,它们往往包含成千上万个任务,并且需要处理TB级或者PB量级的数据,因而需要大量的计算资源和存储资源。科学工作流作为一种重要的机制可以帮助科学家自动执行这些科学仿真和数据分析过程[4]。目前,许多科学家通常将科学工作流部署在网格和集群等分布式环境上。然而,建立这样的系统是非常昂贵的,而且申请访问这些系统也需要花费大量的时间[8]。云计算技术在2007年被提出[5],由于它拥有全球性的分布式数据中心,因而能够支持大规模的应用的快速发展[6]。云计算能够为用户提供大量的存储空间和高性能的计算资源,并以按量付费的方式收取费用。它的高效、灵活的特点为科学工作流的执行提供了一种全新的方式[7]。
云计算环境下的数据中心都有它独特的特征,例如存储空间和计算能力。由于这些特征的限制,将科学工作流中大量的数据集存放在某个数据中心是不合理的[10]。因此,将科学工作流部署在云计算平台上面临着数据布局方面的挑战。数据布局问题是在满足数据中心容量要求的前提下,将数据集布局到数据中心上。显然,它是NP难问题,因此可以简化成背包问题。目前存在的数据布局策略主要是基于聚类算法[8,11]和智能算法[10],包括k-means算法,数据集和任务协同调度算法,遗传算法GA(Genetic Algorithm)和PSO(Particle Swarm Optimization)算法等,其中k-means算法[8]是最具代表性的算法。k-means算法和GA算法可以将依赖关系强的数据集布置在同一个数据中心上,从而减少科学工作流执行过程中数据传输时间。但它们忽略了数据中心间负载均衡,导致数据集被布局在少量的数据中心上,从而影响了整个数据中心的计算能力,进而降低了科学工作流的执行效率。因此,一个高效的数据布局策略应同时兼顾到数据传输时间和数据中心间的负载均衡。
基于上述的分析,对数据集进行布局时,同时考虑数据传输时间和负载均衡是很困难的,传统的数据布局方法很难获取高效的数据布局方案。本文运用基于进化算法的多目标优化方法[9]对数据集进行布局。多目标优化方法即同时优化多个目标的算法,它综合考虑多个优化目标间的权衡,并能够最终获得一组最优解。故利用多目标优化方法可以兼顾数据布局策略中的数据传输时间和负载均衡。解决多目标优化问题通常采用的是基于进化算法的启发式方法,它有着自适应、避免局部最优、黑盒式求解等诸多优点[14],可以有效解决科学工作流中数据布局问题。
1 相关工作
科学工作流的数据布局是一个非常重要且富有挑战性的问题,它对于减少科学工作流的执行费用和提高科学工作流的执行效率有着重要的意义,因此,合理的数据布局策略至关重要。目前已有学者对此进行了探索和研究,主要包括聚类算法[8,11]和智能算法[10]的数据布局策略的相关研究。此外,我们将介绍基于进化算法的多目标优化方法。
在聚类算法方面,文献[8]提出了一种基于k-means算法的数据布局策略。该策略首先建立数据依赖矩阵,矩阵中每个元素表示两个数据集的公共任务个数。然后利用BEA算法对依赖矩阵进行聚类变换得到聚类矩阵,然后将聚类矩阵划分成若干个集合。最后将划分的集合布局至相应的数据中心,这样就尽可能将依赖度高的数据集布局在同一个数据中心,从而减少了数据传输时间。文献[11]提出了一种基于图切割的任务和数据集协同调度策略。它根据数据集的固定存储特征将数据起源图切割成子图,并不断重复这个过程直到该子图所包含的数据集能够满足数据中心的容量要求,最后将任务和数据集布局到合理的数据中心。在智能算法方面,文献[10]在能够反映负载均衡和数据传输时间两目标的适应值函数的基础上,使用遗传算法对科学工作流中数据集进行布局,该方法在负载均衡方面和负载均衡方面均取得了很好的效果。
上述的数据布局策略要么从单一目标(例如数据传输时间)来考虑科学工作流的数据布局问题,要么虽然考虑了数据传输时间和负载均衡两个目标,但不能够对数据传输时间和负载均衡两个目标同时进行优化,因而都不能够有效地提高科学工作流的执行效率。基于进化算法的多目标优化方法可同时优化多个目标,因而,可以有效解决数据布局中数据传输时间和负载均衡不能同时兼顾的难题。多目标优化问题在工程学,生物学和经济学等领域中非常普遍[12-15]。多目标优化问题中各个目标间通常是互相矛盾的,目标函数可能具有多峰、不连续、不可导甚至离散等特点,无法通过传统的最优化方法或算法来解决。作为一种启发式的智能搜索算法,进化算法能有效地解决多目标优化问题并已经得到了越来越多的研究证明[17]。
在多目标优化方法方面,文献[15]提出了一种基于非支配排序的多目标优化算法(NSGA-II),它利用非支配排序算法以及拥挤距离策略,从当前父子代的联合种群中选出参与下一代进化的种群,兼顾了种群的收敛性与分布性。文献[9]在NSGA-II 研究和分析的基础上,提出的一种基于knee points的多目标优化算法(KnEA)。knee points是前沿面上具有更好收敛性的一些个体。该算法通过一种自适应的方法识别出种群中的knee points,并在交配池选择和环境选择操作中优先考虑它们,从而加速种群的收敛和维护种群的多样性。与多个主流的多目标进化算法的实验对比说明,KnEA能在多目标优化问题上获得更好的性能表现。
本文在对数据集进行布局时,将综合考虑数据传输时间和负载均衡两个重要因素。运用基于进化算法的多目标优化方法(KnEA)对数据集进行布局,从数据传输时间和负载均衡两个方面对数据布局方案进行同时优化,取得了显著的效果。
2 科学工作流的描述和问题分析
首先介绍云计算环境下科学工作流数据布局问题的相关定义,具体包括云环境、科学工作流、数据集、任务。然后对数据布局中所面临的问题进行分析。
2.1 相关定义
定义1 云计算环境表示为多个分布式数据中心组成的集合DC={dc1,dc2,…,dcm}。单个数据中心dci可表示为dci={size,cap},其中size表示数据中心dci的容量,cap表示数据中心dci的计算能力,并用执行同一任务所需的时间的倒数来量化表示。
定义2 科学工作流定义为G={T,C,DS}。其中T={t1,t2,…,tn}表示工作流G的所有任务,C表示任务之间控制流的邻接矩阵,DS={d1,d2,…,dn}表示G中所有数据集的集合。
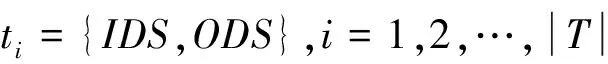
定义4 根据数据集存放位置是否受限,可以将数据集分为固定数据集和非固定数据集。将DS中所有固定数据集组成的集合记为DSfix。对∀di∈DSfix,记di指定存放的数据中心编号为fix_loc(di)。DS中所有非固定数据集组成的集合记为DSflex。
2.2 问题分析
下面给出一个简单的科学工作流的实例如图1所示,假设云计算平台有两个数据中心dc1、dc2,该科学工作流有6个数据集d1、d2、d3、d4、d5、d6,每个数据集大小均为1GB,其中d2是存放在数据中心dc1上的固定数据集,d6是存放在数据中心dc2上的固定数据集。
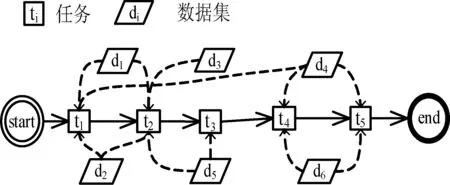
图1 科学工作流实例
对于图1中科学工作流,基于k-means算法的数据布局策略得到数据布局方案,如图2(a)所示。接着从优化数据传输时间和负载均衡的多目标优化角度出发,得到优化后的数据布局方案如图2(b)所示。
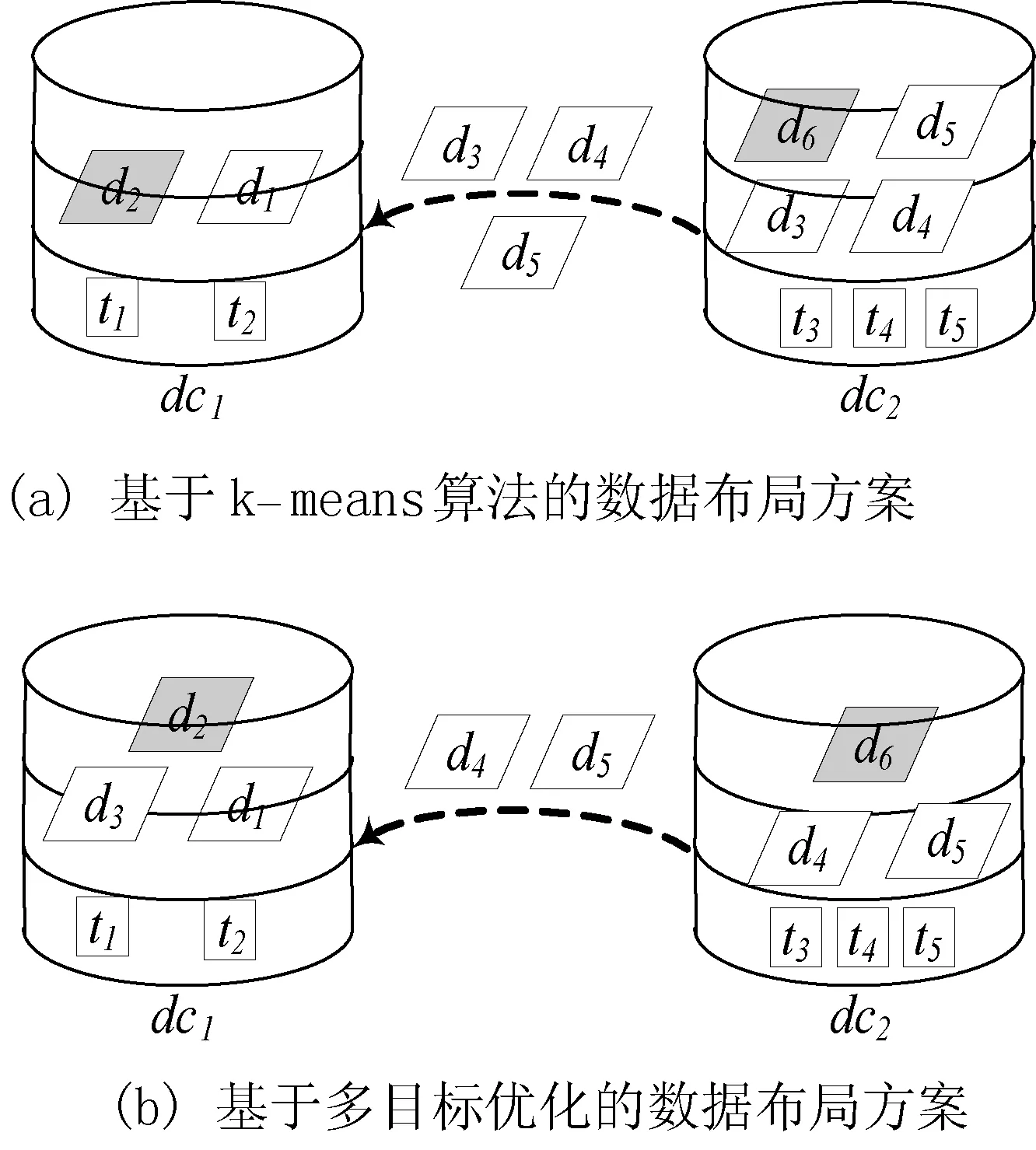
图2 两种数据布局方案
根据将数据集进行跨数据中心的传输代价比任务调度的代价大这一原则[8],在上述两种数据布局方案中,将任务t1、t2调度到数据中心dc1,任务t3、t4、t5调度到数据中心dc2。基于k-means算法的数据布局方案在科学工作流的执行过程中,数据集d3、d4、d5,从数据中心dc2传输到数据中心dc1,需要的传输量为3GB;数据中心dc1的负载量为2GB,dc2的负载量为4GB,因此数据中心间负载不能保持均衡。基于多目标优化的数据布局方案在科学工作流执行过程中,数据集d3、d4从数据中心dc2传输到数据中心dc1,需要的传输量为2GB,同比减少33%;数据中心dc1和dc2的负载量均为3GB,因此数据中心间负载保持均衡。因而,基于k-means算法的数据布局策略不能很好地解决数据布局问题。
3 基于多目标优化的数据布局算法
运用基于多目标优化的数据布局算法对科学工作流中数据集进行布局,它在减少数据传输时间的同时,兼顾了数据中心间负载均衡。下面将首先介绍数据布局方案的数据传输时间和负载均衡两种评价指标,然后给出数据布局算法。
3.1 数据布局评价指标
数据传输时间:采用将任务调度至执行该任务所需数据传输时间最小的数据中心的任务调度策略。如果每个任务需要的数据集不在该任务存放的数据中心,则需要从其它数据中心进行传输。数据传输时间即科学工作流全部执行时,所有任务需要的跨数据中心间数据集传输时间之和。
Time(dk,dci,dcj)表示dk从源数据中心dci传输到目标数据中心dcj所需要的时间,如式(1)所示。
Time(dk,dci,dcj)=dk·ds/bij
(1)
其中,bij表示数据中心dci和数据中心dcj间的带宽。Time(ti,dci)表示当任务ti调度到数据中心dci时,ti所需的输入数据集不在dci时,要从其他数据中心传输数据集所需的时间之和。如式(2)所示。
(2)
工作流执行过程中,数据中心计算能力动态变化,负载均衡是一个动态的均衡。然而本文研究静态数据布局方案,假设每个数据中心的计算能力相同,负载均衡仅和数据中心的存储情况有关。文献[10,11]采用数据中心使用率的标准差来描述数据中心间负载均衡,但数据中心的容量非常大,数据集大小对于数据中心的容量的比例很小,故计算结果并不准确,本文使用数据中心使用量的标准差来描述数据中心间负载均衡,如式(3)所示。
(3)
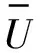
(4)
3.2 数据布局算法
下面首先对数据布局方案的编码规则进行介绍,然后给出本文的数据布局算法。
3.2.1 编码规则
常见的编码规则有二进制编码、格雷码编码、符号编码、浮点数编码和整数编码等[16]。本文采用整数编码规则,每个个体代表一个数据布局方案。通过整数编码规则,可以避免出现将数据集布局到编号不存在的数据中心上的无效个体。假设有m个数据中心和n个数据集,代表数据布局方案的个体由n个整数组成:(g1,g2,…,gn)1≤gj≤m(j=1,2,…,n)gj表示第j个数据集所在的数据中心编号。
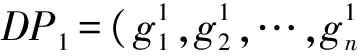
3.2.2 算法描述
本文的数据布局策略是首先将固定数据集布局到相应的数据中心得到固定数据集布局方案DPfix,然后运用多目标进化算法(KnEA)对非固定数据集进行布局得到非固定数据集布局方案DPflex,最后,对两者进行合并,得到全局数据布局方案DP。
算法 基于KnEA的数据布局算法
输入:数据中心集合DC,数据集合DS
输出:数据布局方案DP
主要步骤:
1.DPfix=[DPfix,fix_loc(di)]∀di∈DSfix;
2.P=random(DSflex,N);
//随机生成N个个体
3.whilenottermination()do
4.Q=mating_selection(P,K,N);
//交配池选择
5.Q=P∪variation(Q);
//子代交叉和变异处理
6.F=nondominated_sort(P);
//非支配排序
7. [K,r,t]=find_knee_point(F,T,r,t);
//查找kneepoints
8.P=environment_selection(F,K,N);
//自然选择
9.end
10.DPflex=getbest(P)
//选出最佳的个体
11.DP=DPfix+DPflex;
12.ReturnDP;
第1行将固定数据集布局到该数据集指定存放的数据中心,得到固定数据集布局方案DPfix。
第2~12行得到非固定数据集布局方案DPflex,具体的,第2行随机生成N个非固定数据集布局方案并记为P。第4~5行根据交配池选择原则的三个准则即个体间的支配关系、个体是否为kneepoint以及个体的加权距离,则从P中选出N个个体记为Q,并对Q中个体进行交叉变异,然后和P中个体进行合并。第6行将P中个体进行非支配排序,并将排序后结果记为F。第7行将F中每个前沿面里符合kneepoint条件的个体放入到K中,其中r和t是自适应参数,T是算法中预设参数。第8行综合F和K的结果,选出N个优秀的个体作为下一次迭代的输入。算法的细节步骤参见文献[9]。第10行表示从P中选出一个最佳的个体(即非固定数据集布局方案)DPflex。
第11行,将固定数据集布局方案DPfix和非固定数据布局方案DPflex进行合并,得到所有数据集的布局方案DP。
4 实 验
将本文提出的基于多目标优化的数据布局策略(KnEA)和基于聚类算法的数据布局策略(k-means)[8]、基于遗传算法的数据布局策略(GA)[10]进行对比试验。随机生成仿真科学工作流,然后使用本文策略、聚类策略和基于遗传算法的数据布局策略得到各自的数据布局方案,运行仿真的科学工作流,并记录该过程中数据传输时间和负载均衡。采用控制变量法给出数据集个数,数据中心个数,固定数据集比例变化时的数据传输时间和负载均衡如图3-图5所示。实验过程中,随机生成10个任务,数据集大小为10~1 000MB的科学工作流,数据中心间带宽为10MB/s。KnEA算法迭代次数为100次,种群初始个体为20个,自适应参数r初始值设为1,t的初始值设为0,预设参数T设为0.5。遗传算法的迭代次数为100次,种群初始个体为20个,变异概率为0.1。为了保证结果的可靠性,每一个科学工作流在保持实验环境配置不变的情况下运行100次后取平均值作为测试结果。
4.1 数据集个数
图3给出数据中心个数5个,固定数据集比例20%的情况下,随着数据集个数的增加,数据传输时间和负载均衡的变化趋势。在数据传输时间方面,本文的策略稍优于k-means策略;和GA策略比较,本文策略效果略差。但在负载均衡方面,当数据集个数大于30且不断增加时,本文的策略优于k-means策略和GA策略,且优势尤为明显。
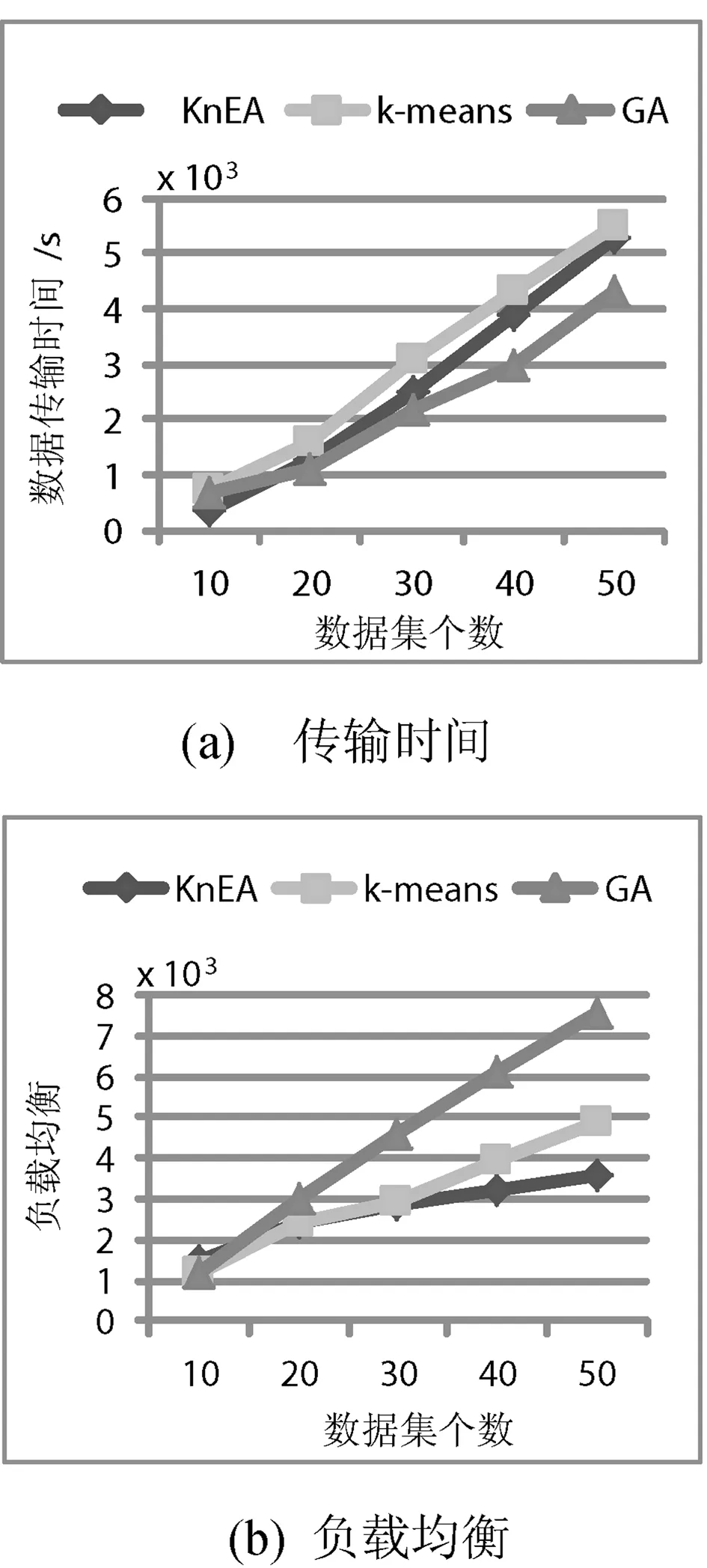
图3 数据集个数
4.2 数据中心个数
图4给出数据集个数40个,固定数据集比例20%的情况下,随着数据中心个数的增加,数据传输时间和负载均衡的变化趋势。本文的策略在数据传输时间方面介于k-means策略和GA策略之间。但在负载均衡方面,本文的策略要好于k-means策略,且相比GA策略,本文的策略优势十分明显。
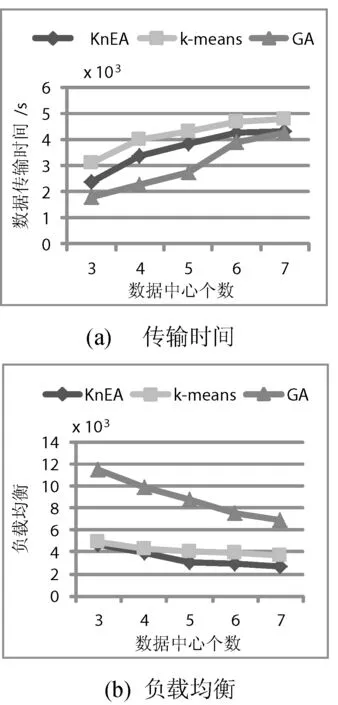
图4 数据中心个数
4.3 固定数据集比例
图5给出数据集个数40个,数据中心个数5个的情况下,随着固定数据集比例的增加,数据传输时间和负载均衡的变化趋势。在数据传输时间方面,本文的策略稍优于k-means策略,和GA策略基本持平。但在负载均衡方面,本文的策略要明显好于GA策略,但并不优于k-means策略,这主要是由于随着固定数据集比例的增大,更多的数据集存放在指定的数据中心,聚类的中心在增多,导致基于聚类的k-means数据布局策略更具优势。
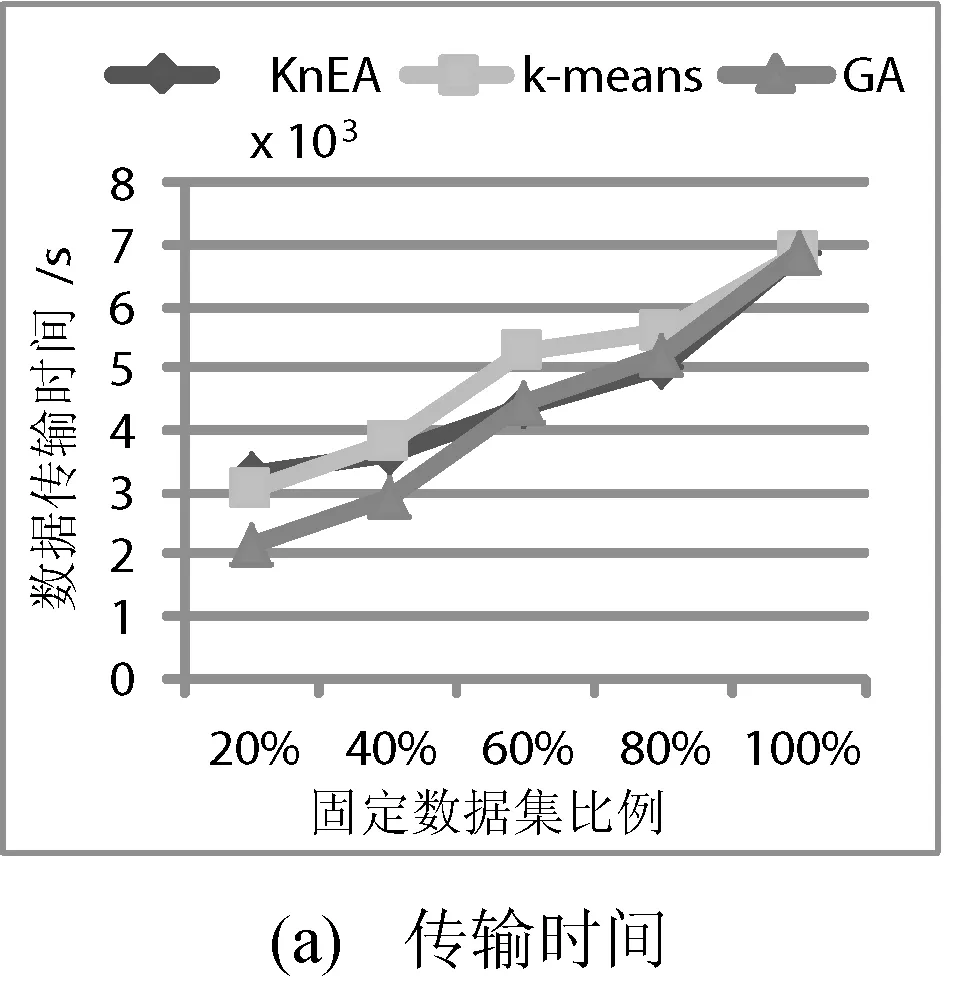
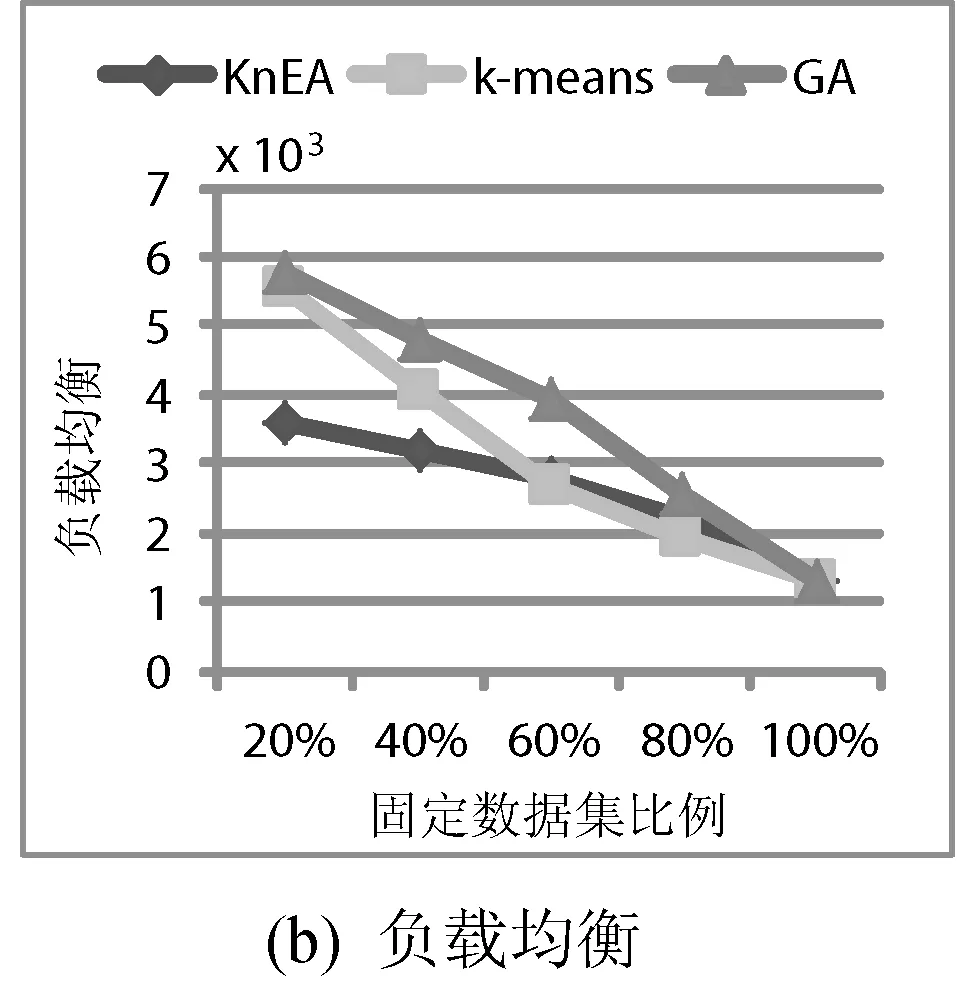
图5 固定数据集比例
综上,k-means策略和GA策略是能将依赖性较强的数据集布局在一起,使得数据集集中在较少的数据中心上。实验结果显示,它可以减少数据传输时间,但它导致更多的数据中心处于未利用状态,从而使数据中心间负载失去平衡。而本文的数据布局策略从多目标优化思想出发,在数据传输时间方面与k-means策略和GA策略基本持平,具有同等的优势,但在负载均衡方面明显优于k-means策略和GA策略。因此,本文的数据布局策略可以有效提高科学工作流的执行效率。
5 结 语
本文首先分析了科学工作流在云计算平台上运行时所面临的挑战,特别是对数据集进行布局时,不能在减少数据传输时间的同时保持数据中心间负载均衡。然后对该问题进行分析,并运用基于多目标优化的数据布局策略对数据集进行布局,并与聚类数据布局策略进行对比实验。实验结果表明,本文的策略不仅可以减少数据传输时间,而且在保持数据中心间负载均衡方面具有很大的优势。未来我们计划运用多目标进化算法对数据布局的同时,对任务进行调度。在减少数据传输时间和保持数据中心负载均衡的情况下,减少任务的执行时间,从而高效地提高科学工作流的执行效率。
[1]DeelmanE,BlytheJ,GilY,etal.Pegasus:Mappingscientificworkflowsontothegrid[C]//inEuropeanAcrossGridsConference.Nicosia,Cypurs,2004:11-20.
[2]LudascherB,AltintasI,BerkleyC,etal.ScientificworkflowmanagementandtheKeplersystem[J].ConcurrencyandComputation:PracticeandExperience,2005,18(10):1039-1065.
[3]OinnT,AddisM,FerrisJ,etal.Taverna:Atoolforthecompositionandenactmentofbioinformaticsworkflows[J].Bioinformatics,2004,20(17):3045-3054.
[4]RenK,ChenJ,XiaoN,etal.BuildingQuickServiceQuerylist(QSQL)tosupportautomatedservicediscoveryforscientificworkflow[J].Concurrency&ComputationPractice&Experience,2009,21(16):2099-2117.
[5]AaronWeiss.Computinginthecloud.net[J].Worker,2007,11(4):16-25.
[6]ZhangRui,WuK,WangJ.Onlineresourceschedulingunderconcavepricingforcloudcomputing[C]//QualityofService(IWQoS),22ndInternationalSymposiumofIEEE,2014:51-60.
[7]ZhaoY,LiYF,LuSY.Aserviceframeworkforscientificworkflowmanagementinthecloud[C]//IEEETransactionsonServicesComputing,2014:1-14.
[8]YuanD,YangY,LiuX,etal.Adataplacementstrategyinscientificcloudworkflows[J].FutureGenerationComputerSystems,2010,26(8):1200-1214.
[9]ZhangXY,TianY,JinY.AKneePointDrivenEvolutionaryAlgorithmforMany-ObjectiveOptimization[C].IEEETransactionsonEvolutionaryComputation,2014:1-17.
[10]ErDunZ,XingxingX,YiC.Adataplacementstrategybasedongeneticalgorithmforscientificworkflows[C]//ComputationalIntelligenceandSecurity(CIS), 2012EighthInternationalConference,Guangzhou,2012.IEEE,146-149.
[11]DengKF,SongJQ,RenKJ,etal.Graph-CutBasedCoschedulingStrategyTowardsEfficientExecutionofScientificWorkflowsinCollaborativeCloudEnvironments[C]//Proceedingsofthe2011IEEE/ACM12thInternationalConferenceonGridComputing,Lyon,2011:34-41.
[12]HerreroJG,BerlangaA,LopezJMM.EffectiveEvolutionaryAlgorithmsforMany-SpecificationsAttainment:ApplicationtoAirTrafficControlTrackingFilters[J].IEEETransactionsonEvolutionaryComputation,2009,13(1):151-168.
[13]PonsichA,JaimesAL,CoelloCAC.ASurveyonMultiobjectiveEvolutionaryAlgorithmsfortheSolutionofthePortfolioOptimizationProblemandOtherFinanceandEconomicsApplications[J].IEEETransactionsonEvolutionaryComputation,2013,17(3):321-344.
[14]HandlJ,KellDB,KnowlesJ.MultiobjectiveOptimizationinBioinformaticsandComputationalBiology[J].IEEE/ACMTransactionsonComputationalBiology&Bioinformatics,2007,4(2):279-292.
[15]DebK,PratapA,AgarwalS,etal.AFastAndElitistMultiobjectiveGeneticAlgorithm:NSGA-II[J].IEEETransactionsonEvolutionaryComputation,2002,6(2):182-197.
[16] 吉根林.遗传算法研究综述[J].计算机应用与软件,2004,21(2):69-73.
[17]ZhouA,QuBY,LiH,etal.Multiobjectiveevolutionaryalgorithms:Asurveyofthestateoftheart[J].SwarmandEvolutionaryComputation,2011,1(1):32-49.
DATA PLACEMENT STRATEGY BASED ON MULTI-OBJECTIVE OPTIMIZATION FORSCIENTIFIC WORKFLOWS IN CLOUD COMPUTING ENVIRONMENT
Cheng Huimin1Li Xuejun1,2*Wu Yang1Zhu Erzhou2
1(SchoolofComputerScienceandTechnology,AnhuiUniversity,Hefei230601,Anhui,China)2(IntelligentComputingandSignalProcessingLaboratory,AnhuiUniversity,Hefei230039,Anhui,China)
The traditional data placement strategies for scientific workflows fail to monitor the load balancing between data centers while reducing the data transfer time. Thus, a data placement strategy based on multi-objective optimization is proposed. Firstly, the strategy generates the placement scheme of fixed datasets. Then it uses multi-objective optimization-based algorithm KnEA(Knee Point Driven Evolutionary Algorithm) to place flexible datasets, and then obtain the placement scheme of all datasets. The algorithm KnEA takes advantage of characteristic of knee points which can get good convergence comparing to other non-dominated sorting individuals, and comprehensively deals with the balance between multiple objectives. That’s why the data placement strategy is able to perform well in data transferring time and load balancing. The effectiveness of the proposed method is tested by comparison with two other strategies.
Cloud computing Scientific workflows Data placement Multi-objective optimization Load balancing
2015-10-16。国家自然科学
61300169)。程慧敏,硕士生,主研领域:云计算和科学工作流。李学俊,副教授。吴洋,硕士生。朱二周,讲师。
TP393
A
10.3969/j.issn.1000-386x.2017.03.001
