基于协同过滤的图书馆个性化推荐系统研究
2017-03-24陈新张楠王洪信
陈新+张楠+王洪信
摘 要:分析了基于用户的协同过滤系统的原理和优缺点,针对图书馆系统的特殊性,采取对图书进行分类和对读者进行分类想结合的方法,寻找用户的相似最近邻居,可有效克服协同过滤系统的稀疏性、可扩展性问题。
关键词:协同过滤;个性化推荐;稀疏性;分类
Abstract:This paper analyzes the principle and advantages and disadvantages of user-based collaborative filtering system. According to the particularity of the library system, the method of classifying the books and classifying the readers to find the similar neighbors of the users can effectively overcome the collaborative filtering system Sparsity and scalability issues.
Key words:Collaborative filtering; Personalized recommendations; Sparseness; classification
1 引言
在社会科技发展变化的驱动下,为了适应时代发展,图书馆从最初的纸质图书收藏地,不断地发展进化。过去,图书馆是人们获取知识、资源的的最主要途径,而如今网络技术迅猛发展,信息呈爆炸式增长,人们正在倾向从网络获取知识,图书馆的作用正在不断弱化。
面对大数据时代的挑战,图书馆领域需要变革,改变传统图书馆的被动式服务方式,采取更加积极的主动式服务方式[1],以提高图书馆利用率,强化图书馆的作用和职能。其中对读者进行个性化推荐就是主动服务的一种。
个性化推荐技术,是对用户的个人信息和浏览历史进行分析,从而找到用户的兴趣偏好,对用户进行针对性的个性化推荐服务。
目前主流的推算算法主要有:协同过滤推荐算法、基于内容的推荐算法、基于知识的推荐算法、混合推荐算法等[2]。其中协同过滤推荐算法是应用最广泛的一种算法。
2 基于用户的协同过滤推荐系统
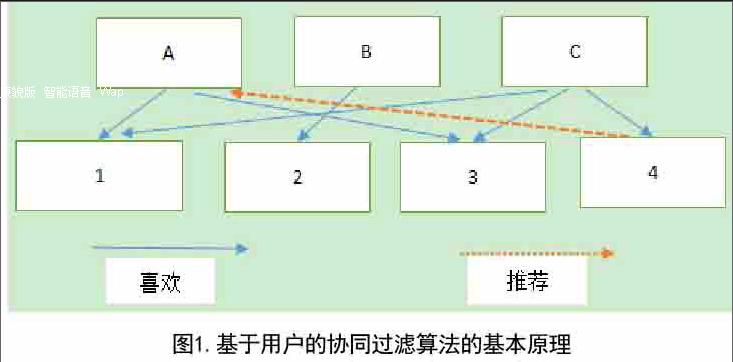
2.1 基于用户的协同过滤系统基本原理
基于用户的协同过滤推荐系统的基本原理是,根据所有用户对物品或者信息的偏好,找出与当前用户有相似兴趣或偏好的“邻居”用户群,记为“K邻居”,然后基于这K个邻居用户的兴趣偏好信息,对当前用户进行推荐[4]。
图1为基于用户的协同推荐系统的基本原理,用户A喜欢物品1和物品3,用户B喜欢物品2,用户C喜欢物品1、物品3和物品4,可以看出用户A和用户C共同喜欢物品1和物品3,可判断用户A与用户C有相似的兴趣,那么用户C喜欢物品4,用户A可能也会对物品4感兴趣,于是把物品4推荐用户A。
如果把A看做当前用户,那么C便是A的相似K邻居用户。基于用户的协同过滤的基础是评价数据库[3],
2.2 计算过程。
基于用户的协同过滤的关键问题,是如何找到与当前用户相似度高的“K-邻居”用户。余弦距离相似性是应用广泛的方法[5]。
公式(1)通过计算向量、夹角的余弦作用衡量用户a与用户b的相似度。如果两个向量方向一致,夹角接近零,那么这两个向量就相近。
例如:经过计算,用户A与用户B的夹角余弦接近1时,则可以认为用户A与用户B是相似的。
2.3 协同过滤算法的缺点
协同过滤算法能够过滤难以进行机器自动基于内容分析的信息,能够对于一些复杂的、难以表述的概念进行过滤,但是也存在一些缺点和不足[6]。
1)稀疏性问题。当系统中数据量大的情况下,用户对商品的评价非常稀疏,通过评分矩阵,难以找出用户之间的相似性。
2)冷启动问题。当资源进入系统中时,资源的评分为空,系统就无法进行推荐。
3)可扩展性问题。当数据库中资源不断增长,用户不断增多,评分矩阵会变得十分复杂,计算效率下降。
3 基于分类的协同过滤图书馆个性化推荐系统
3.1 以图书分类号为基础进行分类。
对于图书馆系统来说,读者的兴趣相对固定,尤其是高校图书馆,学生除了对一些比较热门的社会学书籍感兴趣外,就只对自己本专业的书籍资料有兴趣,跨专业借阅图书的现象极少出现。而图书馆系统中的图书都有明确的分类,以中文图书为例,依据中图分类法,图书可分为5大部类,22个大类,大量的小类。对于图书推荐系统的协同过滤,在相同的图书分类内查找有相同兴趣的用户,成功几率会有较大的提升。
3.2 以读者特征进行分类
对于读者也可以进行分类,高校图书馆读者信息完善,有明确的院系分类,在同学院、同专业中寻找最近邻,成功几率可以提升很多。此方法可以有效解决算法的稀疏性问题和可扩展性问题。对于公共图书馆,可以采用平均值聚类算法对读者进行聚类划分。
3.3 算法流程
以图书分类号为基础进行分类为例,流程如下:
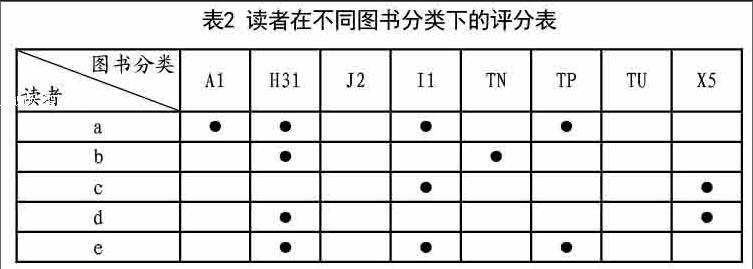
1)通过读者的历史评分记录,建立读者在不同图书分类下的评分矩阵,表2是一个评分矩阵的例子。
2)对读者进行分类,降低矩阵维度。
表2 中读者d对H31、X5两个分类的图书进行了评分,表明d對这两个分类的图书感兴趣,从表2中可以看出,只有读者b、c、e同d存在交集,这样就可以把缩小矩阵的维度,提高计算效率。
可以看出b、e与d的交集是H31,而H31是英语类,属于工具学科,在高校中,是绝大多数学生都会学习的,有广泛通用性,在推荐系统中,可以看做是一个干扰项,去掉H31这个干扰项,就只有c与d有交集,从而将矩阵维度进一步降低。
3)计算推荐结果
使用公式(1)的余弦距离相似性算法,找到最近邻,得出推荐结果。
4 结语
协同过滤推荐系统在电子商务领域应用广泛,在图书馆领域,需要根据图书馆的特点,设计更加优秀的算法,克服稀疏性、可扩展性的问题,使图书馆个性化推荐系统达到更好的推荐效果,更好地为读者服务。
参考文献
[1]黄红梅.数字图书馆主动服务模式优化研究[J].图书馆学刊,2009,26(9):61-63.
[2]陈洁敏.个性化推荐算法研究[J].华南师范大学学报(自然科学版),2014,46(5):8-15.
[3]黄创光.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[4]马宏伟.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7):1282-1288.
[5]基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
[6]基于用户兴趣分类的协同过滤推荐算法[J].计算机系统应用,2011,20(5):55-59.
