基于改进Co-Forest的主机故障预警方法
2017-03-23邹保平戚伟强
邹保平,戚伟强
(1.国网信通亿力科技有限责任公司 福建 福州350001;2.国网浙江省电力有限公司信息通信分公司浙江 杭州310000)
基于改进Co-Forest的主机故障预警方法
邹保平1,戚伟强2
(1.国网信通亿力科技有限责任公司 福建 福州350001;2.国网浙江省电力有限公司信息通信分公司浙江 杭州310000)
针对数据中心中主机故障数据的标记稀缺的问题,提出一种改进的Co-Forest方法,结合少量标记和大量未标记的IT运维数据,实现硬件的故障预警。方法使用评估函数对Co-Forest算法的每轮训练需要加入的未标记数据进行过滤,避免半监督学习的性能恶化问题。对比实验结果表明,相比只使用了标记数据的分类模型和传统Co-Forest,方法能显著提高分类器的准确度。
半监督学习;Co-Forest;评估函数;故障预警;分类模型
随着各行业信息化建设的发展,数据中心规模逐渐庞大,其内部主机的软硬件故障成为影响业务系统可靠性和可用性的关键因素。由关键节点的硬件损坏、信息系统漏洞、数据库中断、并发请求过大等导致的故障可能会使整个集群发生瘫痪。对数据中心的硬件设备、操作系统、数据库和中间件等IT资源的故障运维由传统分散的人工式巡查发展为集中统一的监测。传统的故障监测方式比较简单,即通过运维管理平台对各软硬件资源的性能指标 (如CPU利用率、内存使用率、数据库运行时长、IO数等)进行判断,当某个指标超过阈值时就将该资源判定为异常,并发出告警。但是,该方法有3个缺点:1)阈值需要运维专家根据经验设置;2)未挖掘各资源各指标间的关联关系;3)经常在故障出现后才能捕捉指标异常。采用机器学习对海量的运维数据进行分析,能够智能地、及时地实现故障预测,克服以上问题,保证业务正常运行[1]。
传统的监督学习方法是在有限的标记样本集上进行训练来得到分类模型,这需要专家判断大量样本的类型并人工标记。在数据中心的IT运维中,主机故障数据的标记过程极为耗时耗力,标记数据的稀缺性为提高故障分类的准确性造成了阻碍。半监督学习[2]是将标记样本与未标记样本合并起来进行训练,以期望在少量标记的基础上,改善模型的泛化能力。较为常用的半监督学习方法包括协同训练(Co-Training)[3]、 转导支持向量机(Transductive Support Vector Machine,TSVM)[4]、基于图论的方法[5]等。协同训练方法比较简单且运行效率高,文中使用它来解决主机故障分类问题。
然而,故障分类具有一定的特殊性:1)IT运维数据量大,这是因为数据中心的资源规模庞大,且性能数据的采集频度高;2)特征维度高,各软硬件资源需要采集的指标种类繁多,且资源的指标之间的关系复杂;3)类别比例不平衡,故障数据相比正常数据少得多。在有限样本上训练得到的故障分类器通常就具有较强的拟合度和较高的准确度(80%以上)。传统的协同训练算法,如Co-Training[6]、Tri-Training[7]、Co-Forest[8]等在扩充训练集时使用可信度评估无标记样本,而未考虑样本的“质量”,使其难以显著地改善这种强拟合的分类器。本文认为改进这种分类器的关键不在于新加入样本的数量,而在于其是否能改进分类器的决策边界。此外,分类错误的噪声数据反而会导致性能恶化。故本文基于Co-Forest算法,使用评估函数对无标记样本进行过滤,筛选出少量靠近决策边界(高信息量)的数据,同时使用半监督学习所依赖的假设惩罚值以避免加入噪声点和离群点。
1 Co-Forest算法简述
Co-Forest算法的本质是将协同训练与集成学习结合。其中,集成学习是对多个子分类器进行训练,并且通过对每个分类器引入随机性,使它们具有不同的决策边界,最终的分类结果是通过各子分类器的投票决定。相比单分类器,组合分类器能够改进准确度,但其前提条件在于:1)每个子分类器都是弱分类器;2)各个子分类器之间的差异性足够大。产生差异性方法包括:对训练样本集的随机化 (如Bagging[9]和AdaBoost[10],每个分类器只基于部分样本进行训练)、对特征集合(如Random Subspace[11],每个分类器只基于特征子集进行训练)的随机化、以及上述两种方式的结合 (如Random Forest[12]、Bagging &Random Subspace[13])。
而协同训练则是基于标记数据建立分类器,使用模型对无标记数据进行标记,并将高可信度的伪标记数据加入用于扩充训练集。其难点在于在每轮迭代时对可信度的评估、最早的Co-Training只使用两个分类器,这需要使用复杂的十折交叉法计算可信度。Tri-Training使用三个分类器投票来方便地评价样本可信度。Co-Forest则扩展了Tri-Training,使用Random Forest作为基分类器。该算法使得即使在任意两个子分类器的训练集相似的情况下,也能通过特征随机化使它们之间具有差异性,并且使子分类器在每轮迭代中都保持差异性。对于某个子分类器,使用其余多个子分类器的投票数来衡量可信度,提高了新样本伪标记的准确率。
2 算法改进
2.1 评估函数
Co-Forest在每轮迭代中未对无标记样本进行过滤,这样会加入大量无效数据。它们既无法改善分类能力,反而增加了算法运行时间。根据文献[14-15]的结论,对分类器改进效果明显的是那些靠近决策边界的样本,即对于当前分类器分歧较大的样本。它们具有较大的信息量,能够尽可能地缩小假设空间。评估函数的一个重要作用是将这些高“质量”的样本筛选出来,使得Co-Forest能够快速地收敛。
假定无标记样本集为U,包含n个样本为x1,x2,…,xn;标记样本集为L,包含m个样本为z1,z2,…,zm;标记类别集合为Q,包含q个类别为y1,y2,…,yq。
某个无标记数据x的信息量为:
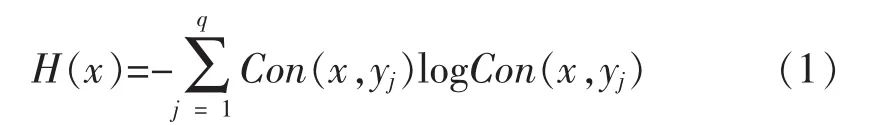
其中Con(x,y)表示组合分类器C(包含N个子分类器)对x的标记分类为y的可信度:

假定C中的某个子分类器Ck的分类结果为Ck(x),其权值为wk,则

另一方面,分类器对高信息度样本的分类能力也较差,对其进行标记往往很容易出错,产生的噪声点会在每一轮训练过程中将错误累积,从而恶化分类器的性能。文中考虑半监督学习的两个基本假设[2]:
1)平滑假设。在多维空间中,处于密集区域的任意两个距离相近样本点应大概率具有相同的标记类别;处于稀疏区域的两个样本应具有不同的标记类别。
2)聚类假设。处于相同聚类簇内的任意两个样本应大概率具有相同的标记类别。
文中对噪声样本的解决方案是,基于上述假设引入样本的不一致罚值 (Inconsistent Penalty,IP)[16]来尽量过滤可能由当前分类器误判而产生的噪声点。为了避免不同属性取值区间的不同而使样本邻近度的计算产生偏差,需要先将各个特征值归一化。然后,将所有样本映射为多维空间中的点,并使用距离函数度量任意两点间的邻近度。对于一个无标记样本x,与任意一个样本点z的不一致罚值用它们对各个类别的可信度差值来度量,且罚值与两点间距离成反比,定义为

令dx,z表示x和z的距离,权值wx,z表示为

x的总罚值由已标记集合L中与其最邻近的k个点计算而得

最后,对于无标记样本集中的离群点,分类器不具有很好的泛化能力。虽然它们可能具有较大的信息量,但由于与标记样本的整体距离较大,会使得不一致罚值很小。这些孤立点的加入会极大可能引入噪声,需要使用距离罚值(Distance Penalty,DP)来过滤它们:
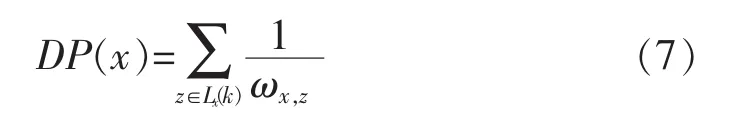
综合(1)、(6)、(7)式,对x的评估函数定义为

2.2 改进的Co-Forest算法流程描述
令初始标记样本集为L,初始无标记样本集为U;评估阈值为F,总轮数为T;集成分类器为H,子分类器个数为N,其中第i个子分类器为hi,其在第t轮拥有的标记样本集为Li,t,拥有的无标记样本集为Ui,t,另外N-1个子分类器组成的集成分类器为Hi。算法流程描述如表1所示。

表1 改进的Co-Forest算法流程
3 算法性能仿真与评测
3.1 实验环境搭建与数据获取
文中实验数据来源于福建省电力数据中心,使用国家电网已有的数据采集平台对集群内主机系统的性能指标进行采集和入库。采集的软硬件目标资源包括硬件、操作系统 (Windows、Linux)、数据库(Oracle、DB2、Sql Server)、中间件(Tomcat、Weblogic)和信息系统五大类。样本的特征集是从指标集中筛选出与故障相关的部分,共计51个特征,各类资源的特征明细如表2所示。标记类别包括正常与故障,其中故障数据细分为5类,分别对应各类资源的故障。不同种类资源的特征以及故障之间存在着相互联系 (如操作系统的存储空间超负荷导致信息系统崩溃),因此将所有特征集合为一个分类问题。

表2 各类资源的特征
实验样本集是通过对10台web服务器在一个月内的定期监测数据抽取获得。在客户端随机使用正常访问、安全攻击和压力测试等方式访问服务器,并去除各属性值都较为接近的重复正常样本,以适当提高各类故障的样本所占比例。总共提取86427条,不同标记的样本比例如表3所示。分类器需要识别监测数据是否正常,如果是故障数据还需要辨别是由哪类资源引起的故障。

表3 各类标记的样本比例
将其中50%作为训练样本,50%作为测试样本。每组实验结果使用不同的标记比例,并通过10次算法训练得到,每次训练对各类样本分别进行随机采样,防止类别比例失衡。使用分类错误率来评价模型的性能。实验对Random Forest、Co-Forest(CF)与改进的Co-Forest(Improved Co-Forest,ICF)进行比较。文中算法的参数设置为:α=3.6,β=3.6,F=0.8,k=8。算法集成分类器个数均为40,子分类器的算法为C45决策树。
3.2 算法对比结果分析
图1、2、3分别给出3种算法在标记比例为5%、10%、20%时的分类错误率。
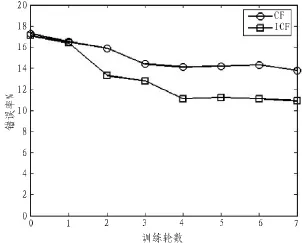
图1 标记比例为5%

图2 标记比例为10%
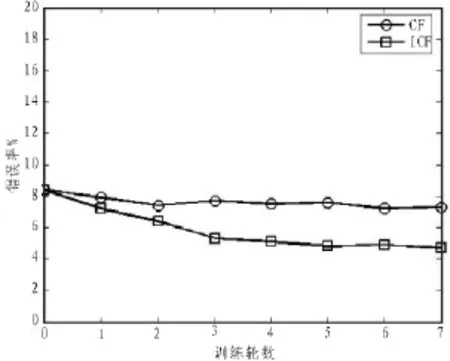
图3 标记比例为20%
结果表明,在不同标记比例的情况下,CF与ICF均能通过挖掘无标记样本的价值,在每轮训练中加入无标记数据及其伪标记,以扩大训练样本集合,从而降低Random Forest的错误率。当标记比例为5%时,ICF的结果错误率(10.9%)优于标记比例为10%时的Random Forest(13.1%),表明当达到相同分类性能的情况下,ICF能够节省一倍的人工标记量。此外,ICF的结果在训练轮数很小时 (一般小于4),就能快速收敛,且迭代后的分类能力明显优于CF。表4统计了二者相较初始分类器Random Forest的错误率改进幅度、二者的算法运行时长以及最终标记样本量(训练结束后,各子分类器的标记样本平均数量)。

表4 CF与ICF的改进幅度
ICF的改进幅度优于CF的原因在于其通过评估函数给予噪声样本和离群样本一定的罚值,提高新加入样本的伪标记可信度。表4说明,ICF通过筛选位于决策边界的高信息量样本,达到快速收敛的效果,算法效率优于CF。由于在第一轮的监督学习训练中,获得的Random Forest分类器为强拟合模型,从而使得CF在每一轮迭代中会加入大量远离决策边界并位于聚类簇内部的无标记样本。这些样本虽然具有高可信度的伪标记,但难以优化模型的泛化能力,还会增加算法运行时间。此外,CF的改进幅度随着标记比例提高而降低,这也说明当初始分类器的拟合度越强时(准确度越高),无标记样本越难以使之改善。但是,ICF的效果则与标记比例无关,这表明算法具有稳定性。
4 结束语
文中对数据中心主机的故障预警分类问题进行了研究,对与各类资源故障关联的指标进行了筛选。针对运维数据的标记难以获得的问题,使用半监督学习中的协同训练方法,将少量标记样本和大量无标记样本结合,降低故障分类的错误率。具体地,本文分析了故障分类时的强拟合分类器难以改善问题,提出一种改进的Co-Forest方法。通过建立评估函数,方法在Co-Forest训练的每一轮,筛选出能有效改善分类能力的高信息度样本,加速算法迭代。同时,设置不一致罚值和距离罚值用于过滤可能的噪声点和离群点,避免分类性能恶化。通过对比实验表明评估函数在Co-Forest算法中应用的有效性。
[1]Yuan S F,Chu F L.Support vector machines-based fault diagnosis for turbo-pump rotor[J].Mechanical Systems&Signal Processing,2006,20(4):939-952.
[2]刘建伟,刘媛,罗雄麟.半监督学习方法[J].计算机学报,2015(8):1592-1617.
[3]Blum A,Mitchell T.Combining Labeled and Unlabeled Data with Co-Training[C]//In COLT:Proceedings of the Workshop on Computational Learning Theory.1998:92-100.
[4]Joachims T.Transductive Inference for Text Classification using Support Vector Machines[C]//Sixteenth International Conference on Machine Learning.Morgan Kaufmann Publishers Inc.,1999:200-209.
[5]Blum A,Chawla S.Learning from Labeled and Unlabeled Data using Graph Mincuts[C]//Proceedings oftheEighteenthInternationalConferenceonMachine Learning.Morgan Kaufmann Publishers Inc.,2001:19-26.
[6]Zhang Y,Wen J,Wang X,et al.Semi-supervised learning combining co-training with active learning [J].Expert Systems with Applications,2014,41(5):2372-2378.
[7]Zhou Z H,Li M.Tri-training:exploiting unlabeled data using three classifiers[J].IEEE Transactions on Knowledge&Data Engineering,2005,17(11):1529-1541.
[8]Li M,Zhou Z H.Improve Computer-Aided Diagnosis With Machine Learning Techniques Using Undiagnosed Samples[J].Systems Man&Cybernetics Part A Systems&Humans IEEE Transactions on,2007,37(6):1088-1098.
[9]Breiman L,Breiman L.Bagging predictors"Machine Learning[J].Lecturenotes in Computer Science Ai,1996,volume 20(1-2):35-61(27).
[10]Kim S Y,Upneja A.Predicting restaurant financial distress using decision tree and AdaBoosted decision tree models [J].Economic Modelling,2014,36(1):354-362.
[11]Li H,Wen G,Yu Z,et al.Random subspace evidence classifier[J].Neurocomputing,2013,110(8):62-69.
[12]Mogensen U B,Gerds T A.A random forest approach for competing risks based on pseudo-values[J].Statistics in Medicine,2013,32(18):3102-3114.
[13]Panov P,D eroski S.Combining Bagging and Random Subspaces to Create Better Ensembles[M] //Advances in Intelligent Data Analysis VII.Springer Berlin Heidelberg,2007:118-129.
[14]FreundY,SeungHS,ShamirE,etal.SelectiveSampling Using the Query by Committee Algorithm[J].MachineLearning,2001,volume28(2-3):133-168(36).
[15]Abe N,Mamitsuka H.Query Learning Strategies Using Boosting and Bagging.[C]//Proceedings of the Fifteenth International Conference on Machine Learning.Morgan Kaufmann Publishers Inc.,1998:1-9.
[16]Belkin M,Niyogi P,Sindhwani V.Manifold Regularization:A Geometric Framework for Lear-ning from Labeled and Unlabeled Examples.[J].Journal ofMachineLearningResearch,2006,7(3):2399-2434.
Fault alarming method for host hardware based on improved Co-Forest
ZOU Bao-ping1,QI Wei-qiang2
(1.State Grid Info-Telecom Great Power Science and Technology Co.,LTD,Fuzhou 350001,China;2.Information Communication Branch of(State Grid)Zhejiang Electric Power Co.,Ltd,Zhejiang 310000,China)
Aiming at the problem of sparse labeled data of host faults in data centers,we present an improved co-forest method,combining a few labeled data and mass of unlabeled data,to achieve hardware fault alarming.The method adopts an evaluating function to filter the unlabeled data which need to be joined at each iteration of Co-Forest algorithm,and to avoid the performance degradation of semi-supervised learning.The comparative experiments show that our method can improve the accuracy of the classifier markedly comparing with the classification model which only uses labeled data and the traditional co-forest.
semi-supervised learning;Co-Forest;evaluating function;fault alarming;classification models
TN78
:A
:1674-6236(2017)05-0065-05
2016-03-17稿件编号:201603216
邹保平(1971—),男,福建龙岩人,高级工程师。研究方向:数据中心,大数据。
