基于混沌粒子群算法的云计算调度研究
2017-03-23张少茹
战 非,张少茹
(1.西安航空学院 计算机学院,陕西 西安 710077;2.西安交通大学 医学院护理系,陕西 西安 710049)
基于混沌粒子群算法的云计算调度研究
战 非1,张少茹2
(1.西安航空学院 计算机学院,陕西 西安 710077;2.西安交通大学 医学院护理系,陕西 西安 710049)
基于云计算环境下资源调度算法的优化为目的,讨论了粒子群算法基本原理和该算法在云计算下应用的缺点。采用引入混沌理论的方法,提出一种适合云计算的混沌粒子群优化算法。改进算法通过Logistic映射产生随机混沌量,通过混沌遍历性对初始粒子群进行混沌初始化,然后在个体粒子更新过程中加入混沌扰动,有效地提高了算法性能。最后通过CloudSim搭建仿真云环境进行实验,通过横向对比蚁群算法和传统Dijkstra算法等,得出混沌粒子群算法在执行效率和相对标准差等方面优于其他算法的结论,更加适合于云计算环境。
云计算;云仿真;粒子群算法;混沌理论
云计算作为一种新兴的计算模式,主要应用于互联网中,将基础资源设施、应用系统、软件平台等作为服务提供给用户[1]。云计算也是一种以虚拟化为基础的架构方式,能够将资源虚拟化并构建规模较大的资源池,对外以服务方式进行管理。
随着云计算的发展,海量的用户数据和大型数据被放入云计算系统中。云计算中因其自身的特点,需要对异构基础资源的支持,以分布式计算为基础,需要计算处理的数据也分布于不同的节点[2]。为了提高云计算的效率,资源调度问题显得至关重要,一个适合于云计算并且高效的资源调度算法是提高云服务响应时间的核心。
文中从已被广泛应用于求解最优问题和调度问题的粒子群算法出发,讨论了算法在云环境下应用存在的缺陷,进而通过混沌理论提出了一种混沌粒子群的优化算法进行改进。算法通过Logistic映射产生随机混沌信号对粒子群进行混沌初始化,在个体粒子更新过程中加入混沌扰动,证明混沌粒子群算法能有效地加快收敛速度和跳出局部最优解。最后通过CloudSim云仿真软件进行实验,证明了混沌粒子群算法更加适合于云计算。
1 粒子群算法分析
1.1 粒子群算法原理
粒子群算法(Particle Swarm Optimization,PSO)的提出源于自然界鸟类群体觅食行为。一群鸟随机在某个区域内寻找食物,食物存在于区域中的某一位置,但是每个个体不知道食物的具体位置,但可以感知出当前位置和目标食物的距离[3-4]。虽然开始鸟群个体较分散,但经过一段时间之后会逐渐汇聚,最终找到食物。
粒子群算法将此现象归结为数学问题进行优化问题求解。每个鸟类个体我们将其当做一个“粒子”,它拥有位置和速度两个属性。每个“粒子”通过自身个体找到距食物最近的解和参考整个群体中找到的最近解改变自己的位置和方向,虽然每个鸟个体仅根据有限的邻居鸟决定自己的位置和方向,但是宏观上看整个鸟群仿佛在统一控制下汇聚到离食物最近的区域。
1.2 数学模型
粒子群算法初始阶段为随机解,然后通过算法中每一轮迭代追踪和更新个体极值pbest和全局极值gbest得到最优解。个体极值指粒子本身找到的最优解,全局极值指整个粒子群当前最优解。
当个体粒子找到pbest和gbest时,通过以下公式更新自己的速度和位置:
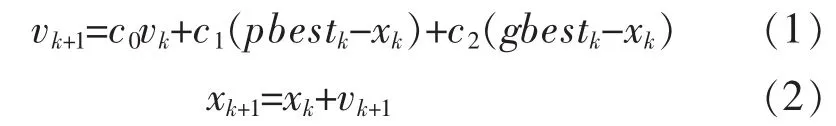
vk代表粒子速度;xk代表当前粒子位置;pbestk代表个体粒子最优解位置;gbestk代表当前粒子群最优解位置;c0,c1,c2为随机数,代表群体认知系数,c0∈(0,1),c1∈(0,2),c2∈(0,2);vk+1为 vk、pbestk-xk和gbestk-xk之矢量和。示意图如图1所示。

图1 可移动3种方向的带权值组合
1.3 粒子群算法流程
粒子群算法对优化问题求解算法流程为:
1)确定粒子群个数n,初随机产生n个初始解和n个初始速度;
2)初始化每个粒子的适应值;
3)若迭代次数小于规定迭代次数,则转至(4),否则转至(8);
4)重新计算个体粒子的适应值,若其优于原来个体极值pbest,则重置pbest为当前适应值;
5)从每个粒子的个体极值pbest中求出全局极值gbest;
6)设定最大速度vmax(vmax>0),通过式(1)更新速度vk,若vk>vmax,则vk=vmax。
7)通过式(2)更新粒子当前位置,转至3);
8)结束算法。
1.4 粒子群算法的缺陷
粒子群算法若应用在云计算调度中,存在一定的不足:
1)初始化过程表现为随机性,随机过程多数情况虽能够保证初始解群均匀分布,但个体的粒子质量不能保证,若解群中有一部分远离最优解,可能造成算法收敛速度较慢。云计算中对服务响应时间要求较高,算法执行效率较低会大大降低响应时间。
2)粒子算法在处理搜索问题过程中,易出现过早收敛的现象。算法根据个体信息、个体极值和全局极值决定每一轮迭代位置,当本身信息和个体极值占优势,容易陷入局部最优解[5]。
2 混沌粒子群算法研究
混沌是一种典型的非线性现象,能够按照自己规律,在一定范围内无重复遍历全部状态。本文讨论的混沌主要指一种对初始条件非常敏感的时间演化行为,通过混沌运动的特性完成搜索的优化。混沌通常指由确定性方程得到的随机运动状态,常见的混沌系统有Logistic系统、Chen系统、Lorenz系统等[6-7]。文中的研究和实验都基于Logistic映射,其迭代公式为:
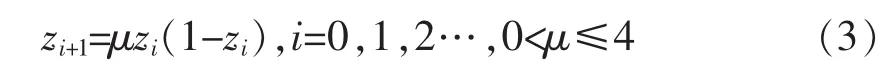
其中μ为控制参数,zi+1∈(0,1)。当3.5699456<μ≤4时,Logistic映射表现出混沌状态;当μ=4时,呈现典型混沌特征,具有随机性、规律性、遍历性和对初值敏感性等。文中将取μ=4,以Logistic映射作为混沌信号发生器。
2.2 混沌理论对粒子群算法的改进
将混沌理论引入粒子群算法可以有效的改进上节讨论的粒子群算法的不足,这里提出一种混沌粒子群算法(CPSO),其改进核心思想为:利用混沌运动的遍历性进行初始化,选择出较优初始群体,加快算法收敛速度;通过Logistic映射产生混沌量,每一轮迭代个体粒子更新时,对当前粒子加入混沌扰动,避免算法早熟收敛,跳出局部最优解。
这里以求解n维优化问题minf(x1,x2,…,xn),s.t.ai≤xi≤bi为说明,混沌粒子群优化算法流程如下:
1)根据式(2)变化可得 zi+1j=μzij(1-zij),i=1,2…,N-1;j=1,2…,n;0<μ≤4。由此产生N个n维的向量,n维中每个分量为产生的0-1之间的混沌量。如z1=(z11,z12,…,z1n),产生N个 z1,z2,…,zN;
2)将各分量载波到优化变量的取值范围:xij=aj+(bj-aj)zij(i=1,2,…,N;j=1,2,…,n)。计算目标函数,从N个初始群体中选择m个较优解,随机产生m个初始速度,完成混沌初始化;
(2)沥青拌和的设备必须进行防尘设备的安装,另外沥青蒸汽的加温装置中,蒸汽管道应该与其进行牢固的连接,由于高温的因素,在需要人员接触的部位应该使用高温材料进行保护。
3)根据当前位置和速度更新粒子个体的位置;
4)产生一个 n维向量 u0=(u01,u02,…,u0n),每个分量为0到1之间的随机数;
5)While(迭代次数K<规定迭代次次数nmax)do
For i=1:m
由式(1)更新粒子速度且小于Vmax;
由式(2)代入 u0,取 μ=4,u1j=4u0j(1-u0j)(j= 1,2,…,n)产生混沌向量 ui=(u11,u12,…,u1n)。 将 u1中每个分量载波至混沌扰动范围[-β,β]中,扰动量Δx=(Δx1,Δx2,…,Δxn)为,计算这两个位置适应值f和f′,若f′<f则;
End For
k=k+1,计算粒子i的适应值fi,若fi优于原先个体极值则个体极值
pfbestik=fi,设置当前个体极值位置pxbestik;
从所有粒子的pfbestk(i=1,2,…,m)中得到全局极值gfbestk和gxbestk;
End While
6)算法结束,输出结果gfbestk和gxbestk。
3 仿真实验
本次实验采用云计算仿真软件CloudSim进行,其基本流程包括:首先模拟云环境,创建计算节点和分发云任务数及资源;其次设定服务参数,根据目前常规硬件配置和网络带宽创建虚拟机;再次通过混沌蚁粒子群算法进行资源调度,当算法找到符合服务要求的最优路径,提供资源并进行绑定;最后输出仿真结果。
3.1 仿真实验核心过程
CloudSim仿真经过的步骤包括:首先新建数据中心,然后确定模拟资源参数,通过DatacenterBroker类的对象建立代理,由此代理负责信息的交互,然后创建虚拟机开始执行云任务,最终获取结果。
以下步骤为仿真过程中核心类的主要方法,调用方法中的一些仿真参数如带宽(bw),内存(ram),PE数(pesNumber)等等的定义语句,由于篇幅限制这里省略不写,这些参数的取值根据常规虚拟机硬件水平设置[8-10]。
1)通过CloudSim.init()进行初始化,新建数据中心 Datacenter对象类 dt1及数据中心代理DatacenterBroker类对象broker,通过broker.get_id()获得ID;
2)新建虚拟机列表,根据Vm类和要仿真的虚拟机规格参数(id、PE数量、MIPS速率、内存、带宽等等 ) 创 建 虚 拟 机 vm 对 象 , 并 通 过 broker.submitVmList()提交代理;
3)根据Cloudlet类创建对象,建立云任务列表,根据仿真参数(ID、PE数量、文件大小等)新建一个云任务并添加进列表;
4)通过broker.submitCloudletList()将云任务列表提交给代理broker,用startSimulation()方法启动仿真过程,stopSimulation()方法结束后输出结果。
3.2 实验结果
通过在CloudSim中进行实验,设定执行的任务数为20~100,计算节点数为20个。为了更好的说明混沌粒子群算法在云计算中优势,选取了标准粒子群算法、传统Dijkstra算法及标准蚁群算法,在相同实验参数情况下执行并进行对比。每种算法执行10次取平均值,算法效率对比情况如图2所示。
通过图2得出,当模拟任务数量较少时,4种算法完成任务时间差别不大,但是随着任务量的增加,混沌粒子群算法的执行效率要优于其他几种算法。由于仿真模拟任务数和计算节点较少,在实际云环境应用中,混沌粒子群算法的执行效率优势会进一步提高。为了更进一步的展示几种算法的区别,对任务分配的结果的相对标准差值进行计算,如图3所示。
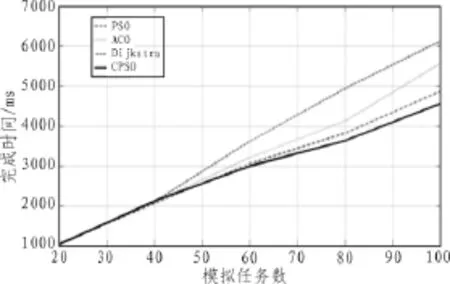
图2 任务执行时间结果图

图3 相对标准差结果图
通过图3显示,当任务数增加,混沌粒子群算法的偏差值越来越小并趋于线性渐进,同样优于其他几种算法。
通过以上分析,云计算的特点就是并行处理大量任务,通过混沌粒子群算法进行资源调度可以有效的改进粒子群算法的缺陷,更加适应常规云计算的要求。
4 结束语
云计算作为一种蓬勃发展商业计算模式,建立在将大量资源虚拟化的基础上,可以统一对海量数据进行管理,根据用户对作业量的需求提供服务,云计算中要保证客户端的响应时间,资源调度问题尤为重要,本文主要对云计算中调度算法进行研究。粒子群算法作为目前被广泛应用于调度问题和求解最优问题的算法,在云计算应用中具有一定的缺陷。本文引入混沌理论,提出一种适合于云计算的混沌粒子群算法进行改进,通过CloudSim云仿真软件进行实验,证明了混沌粒子群算法能够有效改善粒子群算法中的不足,更加适合应用在云计算中。
[1]刘鹏.云计算[M].北京:电子工业出版社,2010.
[2]陈全,邓倩妮.云计算及其关键技术[J].计算机应用,2009(9):2563-2564.
[3]李剑锋,彭舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用,2011,31(1):184-186.
[4]孟湘来.基于云计算的数据中心构建探析[J].中国企业教育,2012(22):240-241.
[5]华夏渝,郑骏,胡文心.基于云计算环境的一群优化计算资源分配算法[J].华东师范大学学报,2010(1):127-134.
[6]田文洪,赵勇.云计算—资源调度管理[M].国防工业出版社,2011:27-29.
[7]鲁宇明,陈殊,黎明.自适应调整选择压力的灾变元胞遗传算法[J].系统仿真学报,2013,25(3):436-444.
[8]王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].软件学报,2012,23(4):962-986.
[9]赵欣.不同一维混沌映射的优化性能比较研究[J].计算机应用研究,2012,29(3):913-915.
[10]Buyya R,Yeo CS,Venugopal S.Cloud computing and emerging IT platforms:Vision,hype and reality for delivering computing as the 5th utility[J].Future Generation Computer Systems,2009(25):599-616.
[11]Didier L I,López D E,Redundancy.Allocation problemsconsidering systemswith imperfectrepairs using multiobjectivegenetic algorithms and discrete event simulation[J].Simulation Modelling Practice and Theory,2011,19(1):362-381.
[12]LI Jing-wei,JIA Chun-fu,LI Jin,et al.Outsourcing encryption of attribute-based encryption with Map-Reduce[C]//Information and Communications Security-14th International Conference,ICICS 2012:191-201.
[13]Sudha G,Sadasivam,Baktavachalam G.A novel approach to mutiple sequence alignment using hadoop data grids[C]//Proceedings ofthe 2010 WorkshoponMassiveDataAnalyticson the Cloud,2010:472-483.
A research on cloud computing scheduling based on chaos particle swarm optimization algorithm
ZHAN Fei1,ZHANG Shao-ru2
(1.School of Computer Science,Xi'an Aeronautical Universities,Xi'an 710077,China;2.Health Science Center,Xian Jiaotong University,Xi'an 710049,China)
This paper discusses the basic principle of Particle Swarm Optimization algorithm and the shortcomings of the algorithm in cloud computing,from the point of view of resource scheduling algorithm in Cloud Computing environment.Based on the introduction of chaos theory,a new Chaotic Particle Swarm Optimization algorithm is proposed.the improved algorithm random chaotic volume generated by logistic map,through the chaos ergodicity of the initial particle swarm chaos initialization,then add chaotic disturbance in individual particle update process to improve the performance.Finally build cloud simulation platform through the CloudSim and experiments are conducted.Through the horizontal comparison of Particle Swarm Optimization algorithm and the traditional Dijkstra algorithm,it is proved that Chaotic Particle Swarm Optimization algorithm is better than other algorithms in execution efficiency and the relative standard deviation,and thus more suitable for in the cloud computing environment.
cloud computing;cloud simulation;PSO;chaos theory
TN919
:A
:1674-6236(2017)05-0013-04
2016-05-16稿件编号:201605150
国家自然科学基金项目(71373203)
战 非(1981—),男,陕西西安人,硕士,讲师。研究方向:软件工程、云计算、通信工程,软件开发、移动互联网应用。
