问答中的问句意图识别和约束条件分析
2017-03-12王厚峰
孙 鑫,王厚峰
(北京大学 计算语言学教育部重点实验室,北京 100871)
0 引言
口语对话系统、语音助手、自动客服等是当前自然语言处理研究的热点。这些应用的成功不仅取决于语音内容的识别,更在于对句子含义的理解。和自动语音识别(automatic speech recognizer, ASR)是将说话人的语音转化为文字序列不同,口语理解(spoken language understanding, SLU)侧重于确定口语问句包含的意图[1],并提取出相应的约束条件,再交给对话或任务管理器(dialog or task manager, DM)[2],就可以满足用户的特殊需求。ASR、SLU和DM顺序连接构成了典型的面向实际目标的会话理解系统[2],是自动客户服务等应用的关键构成部分。本文研究SLU中的意图识别和约束条件分析,为口语理解提供帮助。
意图识别(intent determination, ID)旨在确定一句话的意图,可以看成分类问题。事先在该领域定义各种可能的意图类别,再用分类方法将问句分到某类之中。约束条件分析(slot filling, SF)则是提取出达成意图的关键信息,可以看成序列标注问题,即将关键词标注为特定标签,其他词被标注为普通标签。
表1中,我们采用In/Out/Begin(IOB)标签来标注“西安到拉萨8月1号到5号有没有打折的飞机票”这句话。“西安”被标注为起点,“拉萨”为终点,“8月1号到5号”被标注为出发时间,“打折”是票价要求。这句话的意图是“查机票”。
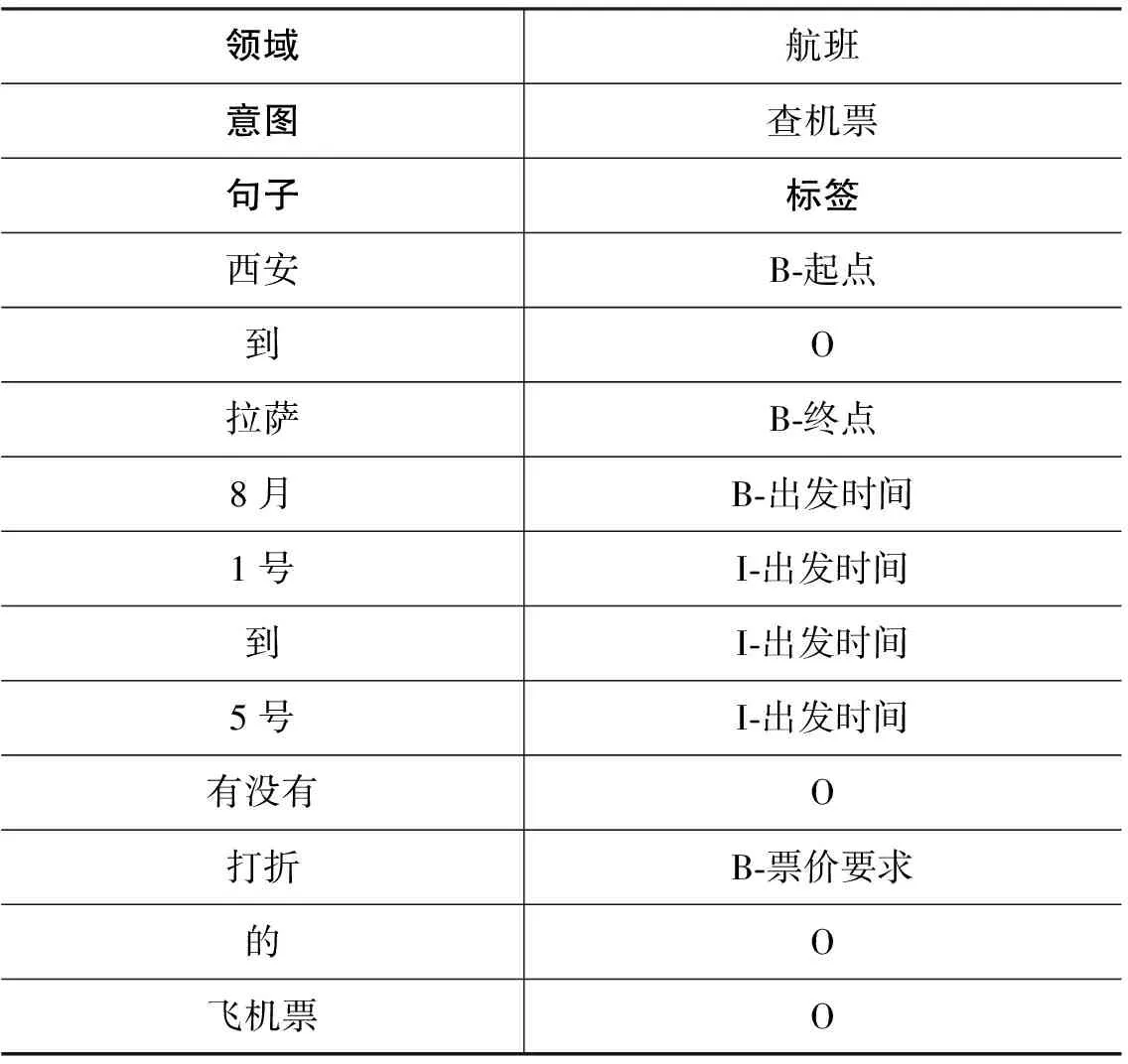
表1 ID和SF问题样例
意图和约束条件这两个问题通常被当作独立的两个问题处理, 前者可以用各种机器学习的分类方法,如支持向量机(support vector machine, SVM)、逻辑回归等解决;后者可以用序列标注模型实现,如条件随机场(conditional random field, CRF)、循环神经网络(recurrent neural networks, RNN)等。但这两个问题是相关的,两种信息可以相互帮助、相互影响[3],例如,“查机票”类型的问句,很可能出现“起点”“终点”“时间”这类标签;反过来,这些标签的出现也很可能意味着问句的意图是“查机票”。目前已有研究采用联合模型,同时识别意图和提取出关键信息。
1 相关工作
单一模型将意图识别和约束条件分析作为两个独立的问题。
意图识别是分类问题,可以使用分类方法求解,如SVM模型[4]、Adaboost方法[5]等。这类传统分类方法的一般步骤是,提取特征作为问句的输入,再用训练好的分类模型进行多分类;缺点是需要人工设定特征。当数据集发生变化时,需要重新设计特征。这往往会演变成特征设计、特征选取等问题,失去了对课题本质的关注。
约束条件分析一般被视为序列标注问题,条件随机场[6]是解决这类问题的经典方法。这类方法一般步骤是,将训练数据中的被标注序列和标签看作很多节点,设计两个或多个节点之间的关系作为特征,训练出这些特征的权重。最后在测试数据集上,将更能反映这些特征的标签序列作为结果;缺点同样是需要人工设定特征模板。
深度学习方法可以避免人工构建特征,例如,RNN方法[7]及各种改进模型如LSTM、GRU等。这类方法在计算每个词标签的概率时,是在局部进行归一的,而局部归一容易出现偏置[8]。CRF方法是全局归一,关注整个标签序列占所有可能标签序列的概率。结合CRF的RNN模型[8]可以提高约束条件分析的效果。不过,这种方法只关注单个问题,没有解决意图识别问题,忽略了意图识别模块带来的额外信息。
文献[3]提出了基于RNN的联合模型,以GRU作为基本单元,同时借鉴CRF的思想,在目标函数中加入了标签状态转移的评估。缺点是在解决意图识别问题时,只是取样了GRU每次输出的最大值,有信息损失。其次,虽然加入了标签之间的转移评估,但是仍然没有在全局考虑序列的概率。文献[9]在处理意图识别问题时,使用了注意力机制,能较好地区分哪些词对分类起到了更大的作用,缺点仍然是约束条件分析时,简单地使用softmax计算概率,没有考虑整体序列的概率分布,有标注偏置的隐患。
综上所述,当前RNN联合模型没有很好地兼顾意图识别和约束条件分析两个方面,前者需要给有用的词汇更大的权重,提取更有用的信息,简单取最大值的操作会损失信息;后者需要在整体标签序列上计算概率,可以避免标注偏置问题。
2 模型
2.1 常规处理
基于LSTM的联合模型的基本框架如图1所示。
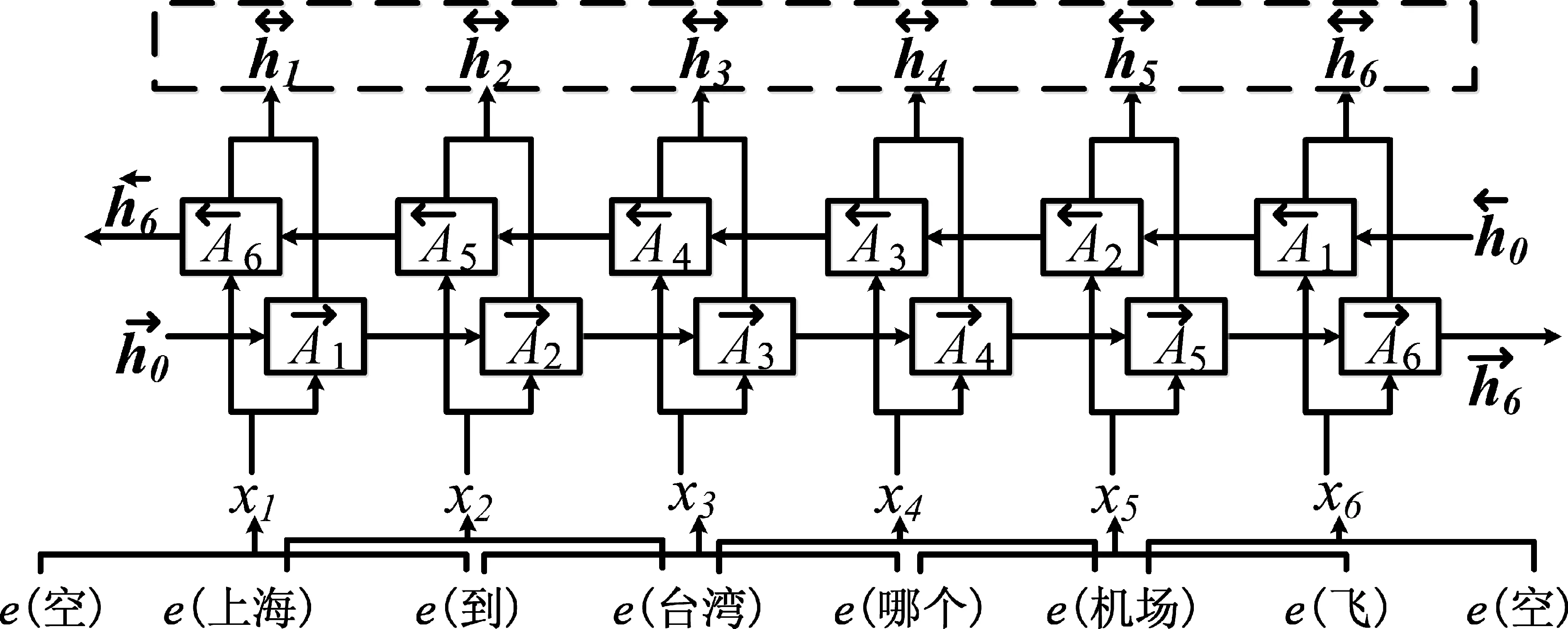
图1 常规处理模型
设置词向量矩阵Eemb∈(|V|+1)*|e|,|e|表示词向量维数,|V|表示总词数,增加一行作为取上下文窗口时空白词的词向量。采用词向量和上下文窗口,将当前词与窗口内的词的词向量连接,作为当前xt,输入到LSTM单元,设置取样前后各d个词汇,如式(1)所示。
其中,e(wt)表示当前词wt的词向量,相当于在词向量表Eemb中查询到这个词对应的那一行向量。向量e(wt)∈|e|,向量xt∈(2d+1)|e|,“[]”表式向量的简单拼接。将xt输入到正反LSTM模块中,正反两个模块分别使用各自的一套参数。参数参数正向LSTM的公式[10]如式(2)~(7)所示。
本文引入注意力机制实现意图分析,通过增加CRF识别约束条件。
2.2 CRF机制
图2所示的框架不再和其他模型一样直接用softmax函数计算每个标签的概率,而是借鉴链式CRF[6]的方法考虑标签之间的转移和整体上标签序列的概率。从单个时刻看,当前词对应的标签都有相应分数, 分数越大, 对应标签越有可能;从标签序列的整体来看,前后标签有转移分数,分数越高,越可能出现这种标签的转移。将这两个分数相加,分数最高的标签序列就是预测结果。先对隐藏层输出做预处理,如式(9)所示。
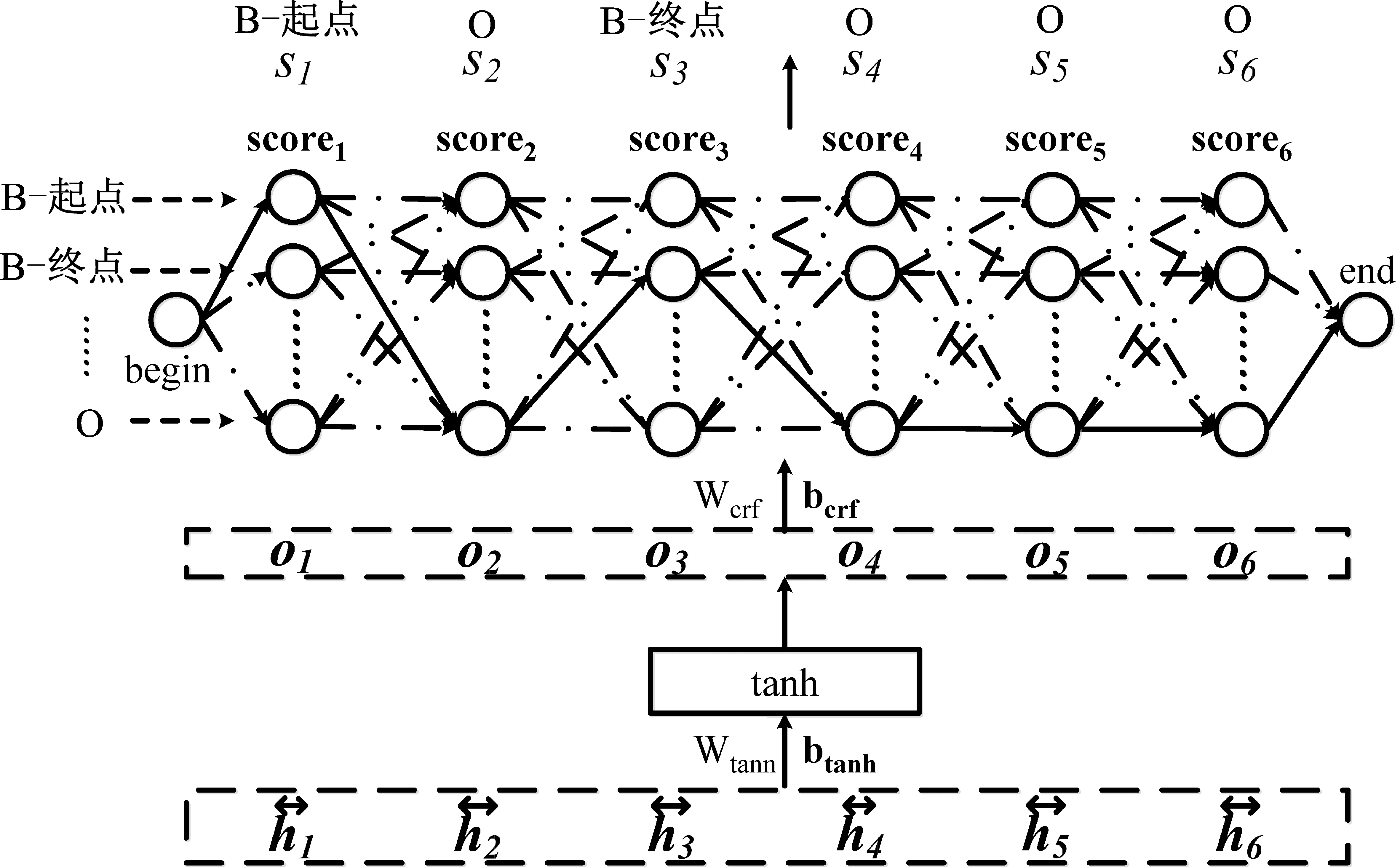
图2 CRF机制
其中,Wcrf∈|S|*|h|,scorest,bcrf∈|S|,|S|表示标签个数。向量scorest每个元素表示对应标签的分数,分数越大越有可能。同时设置转移矩阵Etrans∈(|S|+2)*(|S|+2),表示标签之间的转移分数,在|S|个标签的基础上增加了“开始”和“结束”两个标签。一个标签序列的总分数是由每个标签的分数和它们之间的转移来决定的,如式(11)所示。
其中,s1:T表示标签序列,时刻总个数T等于|L|,也就是该词语序列的长度。scoretotal(s1:T)是对该标签序列的总分数的衡量。Etrans(st-1,st)表示转移矩阵Etrans第st-1行,第st列的值,即t-1时刻的标签到t时刻标签的转移分数。scorest(st)表示scorest的第st个元素,即当前标签是st时的分数。s0和sT+1分别为“开始”和“结束”标签,它们对应的scorest(s0)和scorest(sT+1)取零。为了对标签序列的整体进行概率归一,本文借用softmax对总分数进行概率转换,如式(12)所示。
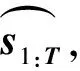
训练时,约束条件分析部分的损失函数如式(14)所示。
即对正确标注该序列的概率的对数值取反,化简之后是两个对数值的差值。该模块增加了参数Etrans、Wtanh、btanh、Wcrf、bcrf。
2.3 注意力机制(attention)
Attention机制如图3所示。
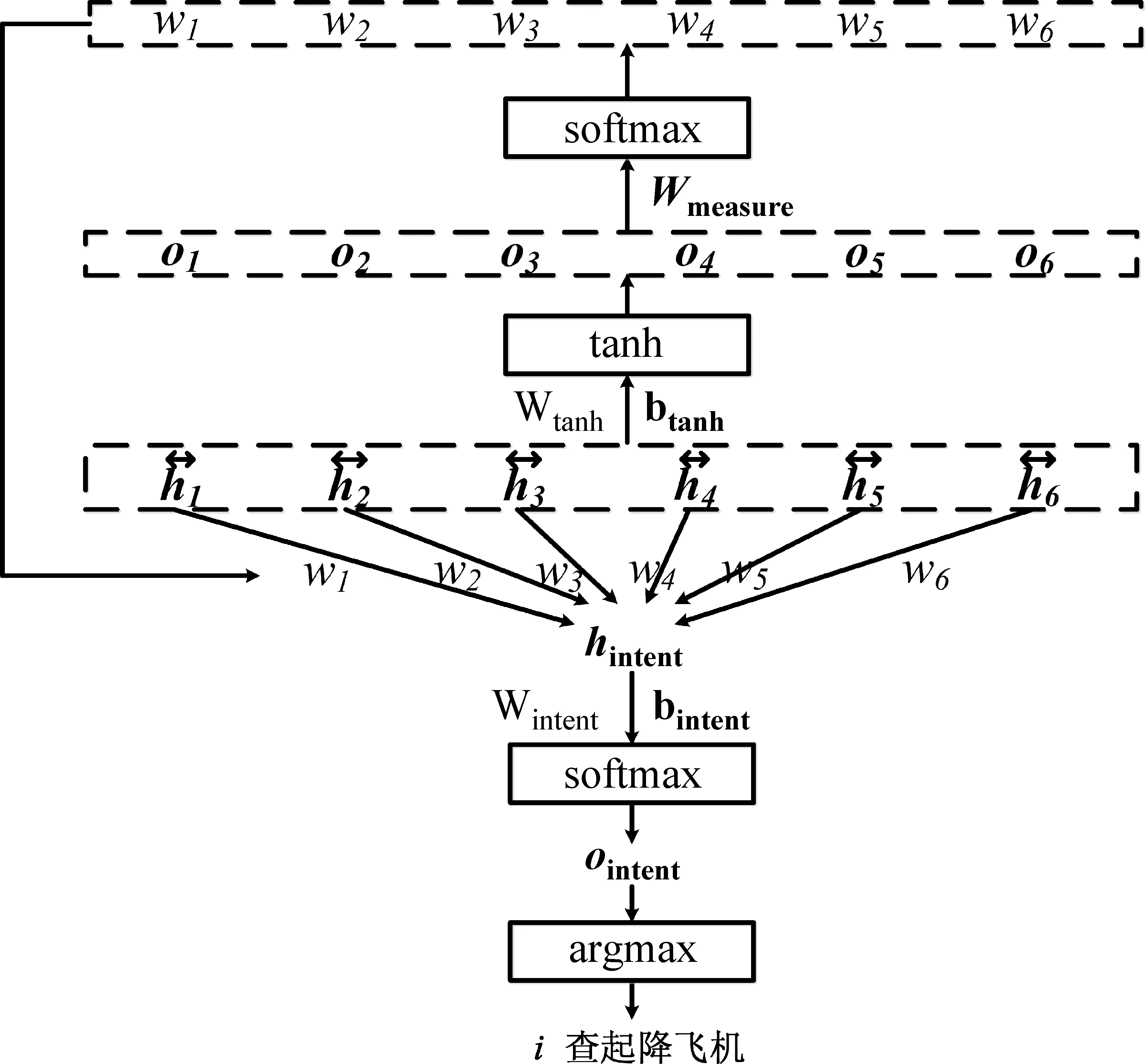
图3 Attention机制
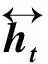
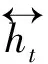
接下来对这个向量表示hintent进行处理,如式(17)、式(18)所示。
其中,ointent的每个元素代表对应意图类别的概率,取其中概率最大的类别作为预测类别。Wintent∈|I|*|h|,ointent、bintent∈|I|,|I|表示意图类别个数,ointent(i)表示向量ointent的第i个元素,即该句意图为i的预测概率。意图识别模块的损失函数如式(19)所示。
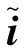
CRF-attention-LSTM模型训练的目标函数也是把所有句子的损失相加,如式(20)所示。
式(20)就是在当前参数为θ的情况下,将所有训练集句子的损失按权重求和。该模块的参数是Wmeasure。
3 实验
3.1 数据集
本文在两个数据集上进行实验,分别是中文数据集(表2)和英文数据集(表3)。
中文数据集的相关情况如表2所示,是从“百度知道”中爬取后加工得到的,包括三个领域,即航班、天气和快递相关的问题。
英文数据集是口语理解问题中最常用的ATIS数据集,如表3所示。该数据集还包含词语的类型信息。有研究[12]认为,类型信息在SLU问题中是不常见的,所以本文不使用这种额外的信息。

表2 中文数据

表3 英文数据
3.2 评价标准
本文使用准确率来评估意图识别。在ATIS数据集中,有些数据可能有不止一个意图,本文按照文献[2]的方法,只要预测意图在正确意图之列就算作预测正确。
实验使用了F1-分数来衡量约束条件分析结果,一个约束条件提取正确表示它的范围和类型都是正确的。F1-分数由通用的CoNLL评价脚本*http://www.cnts.ua.ac.be/conll2000/chunking/output.html.获得。
3.3 对比方法
3.3.1 中文数据集中的baseline
SVM用于意图识别,提取的特征主要是一系列关键字是否存在的二元特征;CRF方法用于约束条件分析。另外,本文也同几种不同的RNN模型比较了实验效果,其中,RNN-ID和RNN-SF分别为普通RNN模型单独解决这两个问题时的方法,RNN-joint为普通RNN联合模型,bi-RNN-joint为双向RNN联合模型,bi-LSTM为双向LSTM联合模型,它们在SF问题上直接用softmax处理取最大概率的标签,在ID问题上用最大池取样作为整句的代表向量。CRF-attention-LSTM为本文方法,结合了CRF和attention的双向LSTM联合模型。
3.3.2 英文数据集中的baseline
SVM: 文献[6]使用前后向移动序列化SVM分类器,用于约束条件分析。
CRF: 文献[7]提供的baseline。
RNN: 文献[7]提供的RNN约束条件分析方法。
Boosting: 文献[2]使用了AdaBoost.MH方法处理意图识别方法。
Sentence simplification: 文献[13]使用AdaBoost.MH方法处理意图识别,用CRF处理SF。
RecNN: 文献[14]使用的递归神经网络联合模型,后加入了Viterbi算法优化对标签序列整体的评估,模型使用了额外的语义信息。
GRU-joint: 文献[3]使用的GRU联合模型,在意图识别部分使用最大池,在约束条件分析部分考虑了标签之间的转移。
3.4 训练细节
中文数据集的实验中,本文采用10-折交叉验证,不使用字标注,而是将句子分词后处理;英文数据集,使用划分好的训练集和测试集。模型的词向量维数均设置为100,隐藏层维数为100,上下文窗口大小设置为1。中文数据集使用梯度下降方法更新参数,初始学习率设计为0.062 7;英文数据集使用AdaDelta方法[15]更新参数。代码使用theano进行编写,实验结果表明,分别使用这两种参数更新方式,效果更好。
3.5 实验结果与分析
3.5.1 中文数据集实验结果与分析
中文语料实验结果如表4所示。
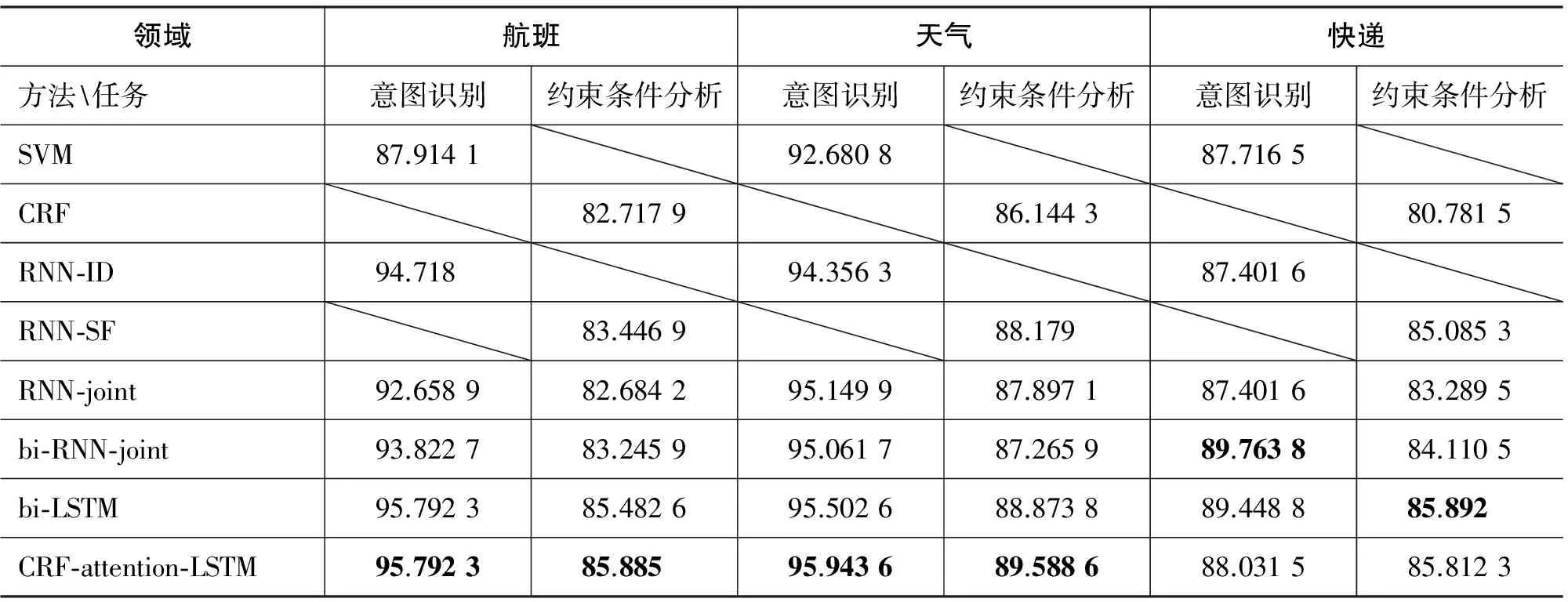
表4 中文语料实验结果
从表4可以看出,在中文数据集上,先采用了经典的分类方法SVM和序列标注方法CRF。最简单的RNN模型分别独立处理意图识别和约束条件分析,均超过了SVM和CRF的效果,只是数据量较少的“快递”领域在意图识别上稍有下降。RNN能捕获长距离的依赖关系,在数据量充足时更加明显。
RNN联合模型相比较RNN单一模型,效果有所下降,只是在“天气”领域的意图识别任务上有提高。双向的RNN联合模型在普通RNN联合模型基础上有了一定的提升,说明后向的信息包括了一些有用的内容,只是在“天气”领域效果略有下降。这可能是因为天气领域的标签最少而类别最多,它的局限不在于前后向的信息,而在于模型本身处理、记忆信息的能力。双向的LSTM联合模型基本提高了各个领域的效果,因为LSTM相较普通RNN更能甄别、保留有用信息,分辨能力更强大。
最终的CRF-attention-LSTM模型,基本达到了最好的结果,只是在第三个领域稍低于之前的方法,因为第三个领域的数据量较少,不同标签的数量分布不均,之前的简单模型更适合它的复杂度,即便如此,最终模型在约束条件识别上的效果也与它们基本持平。
Attention模块的效果示例如图4所示。在这两个例子中,模型能够较好地聚焦在关键词上,颜色越深、数值越大,说明这个词越重要。
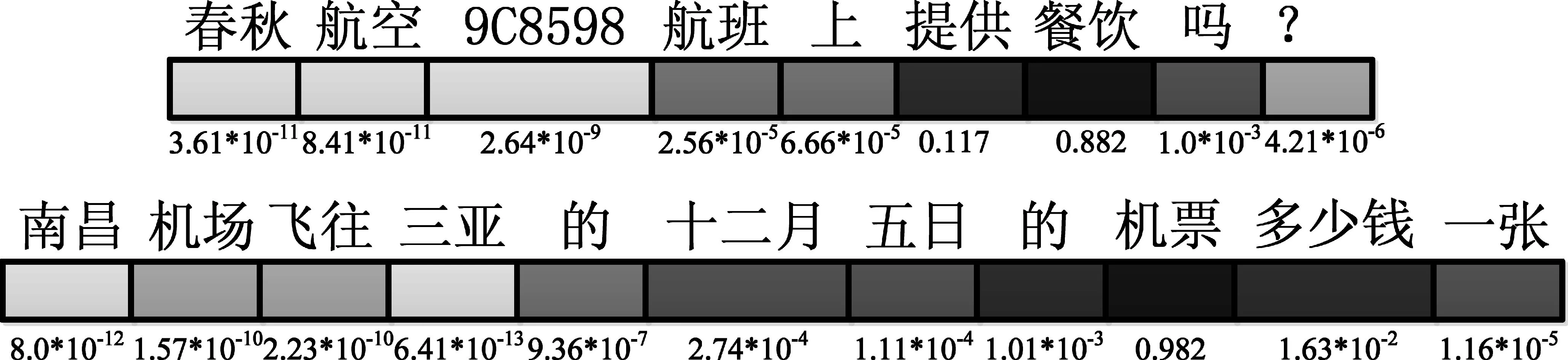
图4 attention结果示例
在中文数据集的实验表明,RNN模型能够较好地解决意图识别和约束条件分析问题;当改为双向LSTM模块之后,效果更佳;而引入CRF和attention的LSTM联合模型,能够在两个问题上更好地利用信息进行分类和标注,达到最优的效果。
3.5.2 英文数据集实验结果与分析
为了验证所提模型CRF-attention-LSTM的有效性,本文使用英文数据集ATIS进行了实验。有些工作使用了ATIS中的额外信息,比如词的类型信息、语义信息等,本文挑选了一些没有使用词的类型信息的相关结果作为比较,结果如表5所示。
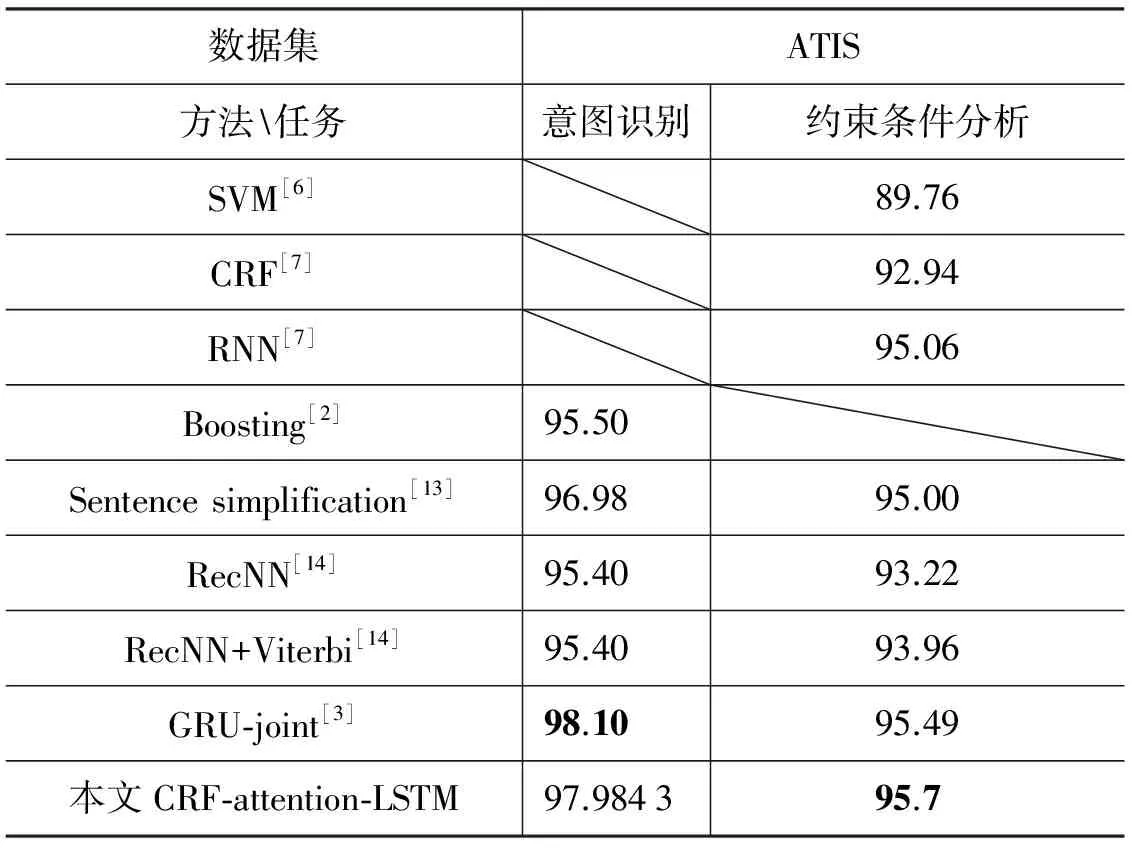
表5 英文语料实验结果
对于单一模型而言,CRF能比SVM更好地处理序列标注问题,RNN因为更能捕获长距离依赖,效果更好。Sentence simplification不是严格意义上的联合模型,它使用了不同的分类器处理两个问题,取得了较好的结果。RecNN结合了语法信息和深度学习,但不适合这个数据集,效果不佳。本文提出的CRF-attention-LSTM在约束条件的分析上好于各种baseline,在意图识别上略低于GRU-joint模型。这表明,本文所提方法在解决意图识别和约束条件分析上是有效的。
4 总结与展望
本文提出了结合CRF和attention机制的LSTM联合模型,在意图识别部分通过attention提取和筛选有用的词语用于分类任务,在约束条件分析部分利用CRF方法,对标签序列整体上进行归一化。通过在中文和英文数据集上进行实验比较,验证了方法的有效性。结合CRF能提升模型整体评估标签序列的能力,attention可以提高信息筛选能力,在词语中选择更重要的词汇用于分类。
本文将中文数据集分为三个领域进行实验,主要是考虑到了SLU任务中本身就有区分领域这一模块,意图识别和约束条件分析就是在领域确定的情况下进行处理的,也可以合在一起进行实验,这样数据量充足,也便于比较,只是和现实中SLU任务的真实情况不太相符。在后续工作中,可以加入ATIS数据集中的词语类型信息,和更多利用了这些额外信息的模型进行对比,以更好地验证模型效果。
[1] Wang YY, Deng L, Acero A. Spoken language understanding[J]. IEEE Signal Processing Magazine, 2005, 22(5):16-31.
[2] Tur G,Hakkani-Tür D, Heck L. What is left to be understood in ATIS?[J]. Spoken Language Technology Workshop, 2011,29(2):19-24.
[3] Zhang X, Wang H. A joint model of intent determination and slot filling for spoken language understanding[C]//Proceedings of the 25th International Joint Conference on Artifical Intelligence, 2016.
[4] Haffner P, Tur G, Wright J H. Optimizing SVMs for complex call classification[C]//IEEE International Conference on Acoustics. CiteSeer, 2003:I-632-I-635 vol.1.
[5] Schapire R E, Singer Y. BoosTexter: a boosting-based system for text categorization[J]. Machine Learning,2000,39(2-3): 135-168.
[6] Raymond C, Riccardi G. Generative and discriminative algorithms for spoken language understanding[C]//Proceedings of INTERSPEECH-2007,2007: 1605-1608.
[7] Mesnil G, Dauphin Y, Yao K, et al. Using recurrent neural networks for slot filling in spoken language understanding[J].IEEE/ACM Transactions on Audio Speech & Language Processing, 2015, 23(3):530-539.
[8] Yao K, Peng B, Zweig G, et al. Recurrent conditional random field for language understanding[C]//Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2014:4077-4081.
[9] Liu B, Lane I. Attention-based recurrent neural network models for joint intent detection and slotfilling[J]. arXiv preprint arXiv:1609.01454, 2016.
[10] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735.
[11] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[12] Mesnil G, He X, Deng L, et al. Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding[C]//Proceedings of Interspeech 2013. 2013: 3771-3775.
[13] Tur G,Hakkani-Tur D, Heck L, et al. Sentence simplification for spoken language understanding[J]. 2011, 125(3):5628-5631.
[14] Guo D, Tur G, Yih W T, et al. Joint semantic utterance classification and slot filling with recursive neural networks[C]//Proceedings of Spoken Language Technology Workshop (SLT), 2014 IEEE. IEEE, 2015:554-559.
[15] Zeiler M D. Adadelta: an adaptive learning rate method[J]. arXiv preprint arXiv:1212.5701, 2012.
